Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2026-06-11 Iceberg Trinoログ基盤の 設計ポイント - Design P...
Search
kamijin_fanta
June 11, 2026
Programming
8
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2026-06-11 Iceberg Trinoログ基盤の 設計ポイント - Design Points for an Iceberg + Trino Log Platform
https://findy.connpass.com/event/394026/
kamijin_fanta
June 11, 2026
More Decks by kamijin_fanta
See All by kamijin_fanta
2025-09-22 Iceberg, Trinoでのログ基盤構築と パフォーマンス最適化
kamijin_fanta
1
860
2025-04-14 Data & Analytics 井戸端会議 Multi tenant log platform with Iceberg
kamijin_fanta
1
770
IoT向けストレージにTiKVを採用したときの話 / 2024-10-25 TiUG Meetup 3 Using TiKV as IoT storage
kamijin_fanta
0
180
TrinoとIcebergで ログ基盤の構築 / 2023-10-05 Trino Presto Meetup
kamijin_fanta
1
2.6k
Unicodeと符号化形式
kamijin_fanta
0
1.2k
Reactとフォームとスキーマバリデーション / React forms with Schema Validation
kamijin_fanta
0
2.7k
2020/05/25 さくらのクラウド向けツールを使いこなす
kamijin_fanta
3
380
2019-01-24 業務でのOSSとの関わり方
kamijin_fanta
7
5k
関数型言語で始めるネットワークプログラミング
kamijin_fanta
0
1.2k
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
150
komatsuna「分散システムにおけるバグ分析手法」
komatsunaqa
0
150
これって Effect でできたのでは? / TSKaigi Mashup Kansai #2
susisu
0
130
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
260
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
3
720
生成AIで帳票OCRが「簡単に」作れる時代になった?
kon_shou
0
190
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
4
1.8k
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
570
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
160
その節約、円になってますか?
isamumumu
0
630
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
630
AWS DevOps AgentのAzure接続機能を検証して見えた活用法/Use Cases Verified for the AWS DevOps Agent's Azure Connectivity Feature
masakiokuda
0
180
Featured
See All Featured
How to Talk to Developers About Accessibility
jct
2
460
The Spectacular Lies of Maps
axbom
PRO
1
880
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
670
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
280
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
420
30 Presentation Tips
portentint
PRO
1
360
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
250
Optimizing for Happiness
mojombo
378
71k
Unsuck your backbone
ammeep
672
58k
Transcript
Iceberg Trinoログ基盤の 設計ポイント 2026-06-11 Tadahisa Kamijo Apache Iceberg実践 ! ベストプラクティス
Meetup
自己紹介 上條 忠久 Kamijo Tadahisa • さくらインターネット株式会社 サービス統括本部 • ソフトウェアエンジニアとしてサービス開発・運用
◦ Go, TypeScript, Python, Kotlin ◦ Linux, Nomad, Ansible, Prometheus, React • 今日は大阪から参加
ログ基盤概要 • 今まで社内各チームで監視基盤が個別に構築運用されている状況だった ◦ Prometheus, Elastic Stack, Loki, etc… ◦
社内向けログ基盤を提供することで、運用レベルの底上げ・運用コスト削減を目的 ◦ OSS運用なども行ったが、マルチテナント提供・ライセンス体系の問題 ◦ Trino+Icebergの構成で開発を開始 • 2023年からパブリックサービス化を目指して開発開始 ◦ アプリケーション・OS・ミドルウェアから出力される、システムログの保管場所として開発 ◦ Trino, Iceberg, 社内のオブジェクトストレージ等を組み合わせてスクラッチ開発 ◦ デジタル庁のガバメントクラウドの要件に含まれ、 2025年度末までの完成を目指していた
None
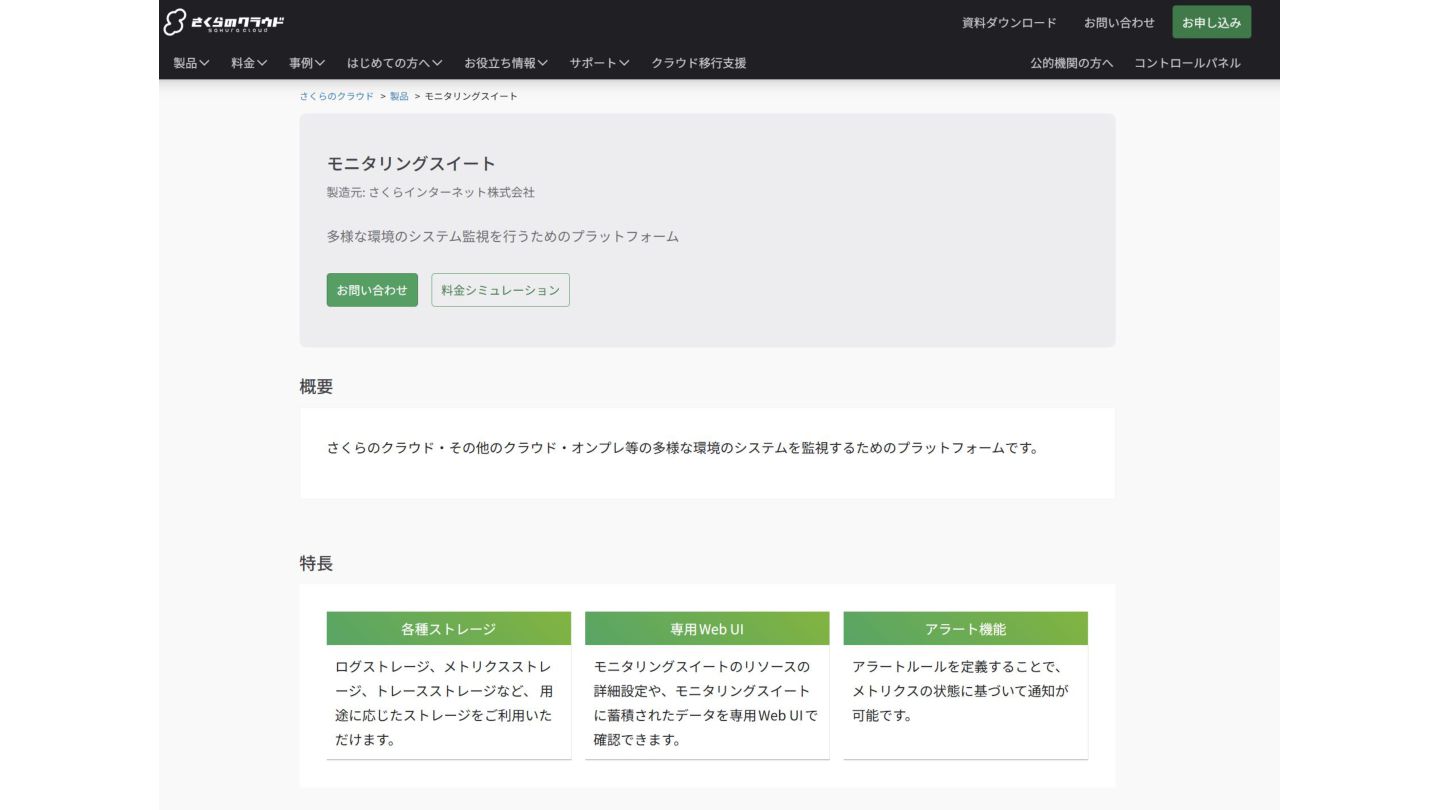
さくらのクラウド モニタリングスイート • ログ・トレースストレージ ◦ fluent-bit, OtelCollectorなどからシステムログ・トレースを受け取る ◦ データの保管・Web UIのクエリ画面を提供
• メトリクスストレージ ◦ Prometheus, OtelCollectorなどから、メトリクスを受け取る ◦ データの保管・Web UIのクエリ画面/クエリAPIを提供 • アラートプロジェクト ◦ ログ・メトリクスに対して、クエリ・しきい値を設定 ◦ アラートはメール・Slack等で受け取り可能 • さくらのクラウド連携 ◦ LB, コンテナ実行基盤等と連携し、ログ・メトリクスなどを設定のみで収集可能 ログ・トレースストレージストレージは、IcebergとTrinoをベースに構築
ADR風に ADR • Architecture Decision Record アーキテクチャ決定記録 • 意思決定を短い文書で記録する モニタリングスイートの中で行った
アーキテクチャ意志決定をいくつか紹介します https://learn.microsoft.com/en-us/azure/well-architected/architect-role/architecture-decision-record
Icebergテーブル構造 ログ・トレースはIcebergテーブルへ記録 • テナント毎にテーブルを分ける ◦ データ削除の容易さ ◦ 性能分離・メンテナンスの容易さ ◦ 暗号化の要求が有った際、顧客毎に異なる暗
号化キーを利用したい • 時間でパーティション・ソート ◦ 検索対象のファイルを減らす ◦ パーティション毎に課金メトリクスを取りたい • ネスト型(struct,list,map)を使わない ◦ Trino, ORM等のサポートを考えると 使いにくいのでフラットな構造とする CREATE TABLE log_tenant_1234 ( timestamp TIMESTAMP(6), insert_id VARCHAR, labels MAP(VARCHAR, VARCHAR ), level VARCHAR, -- DEBUG, INFO, WARN, ERROR message VARCHAR ) WITH ( partitioning = ARRAY[ 'day(timestamp)' ], sorted_by = ARRAY[ 'timestamp' ] ); (実際は大量のフィールドが定義されています )
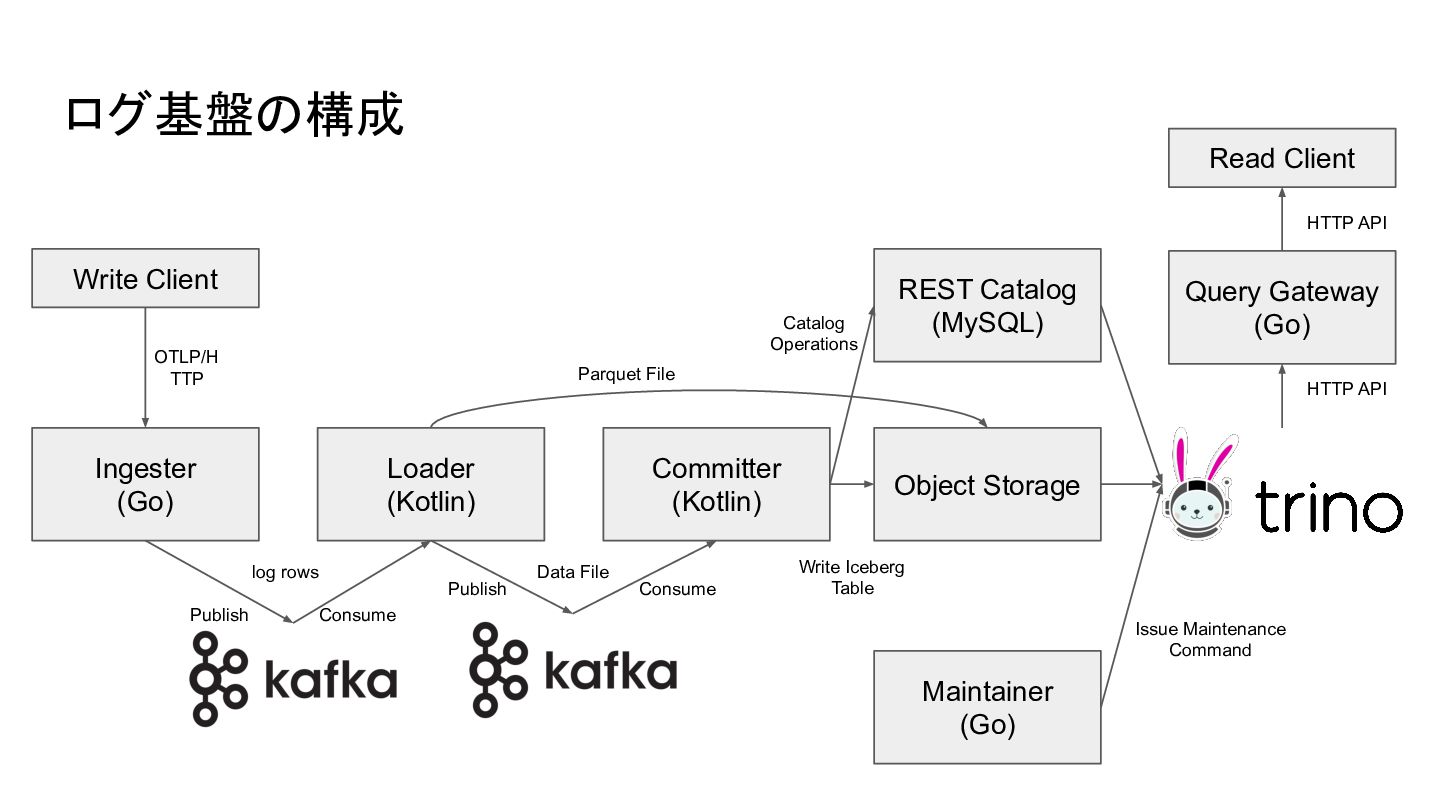
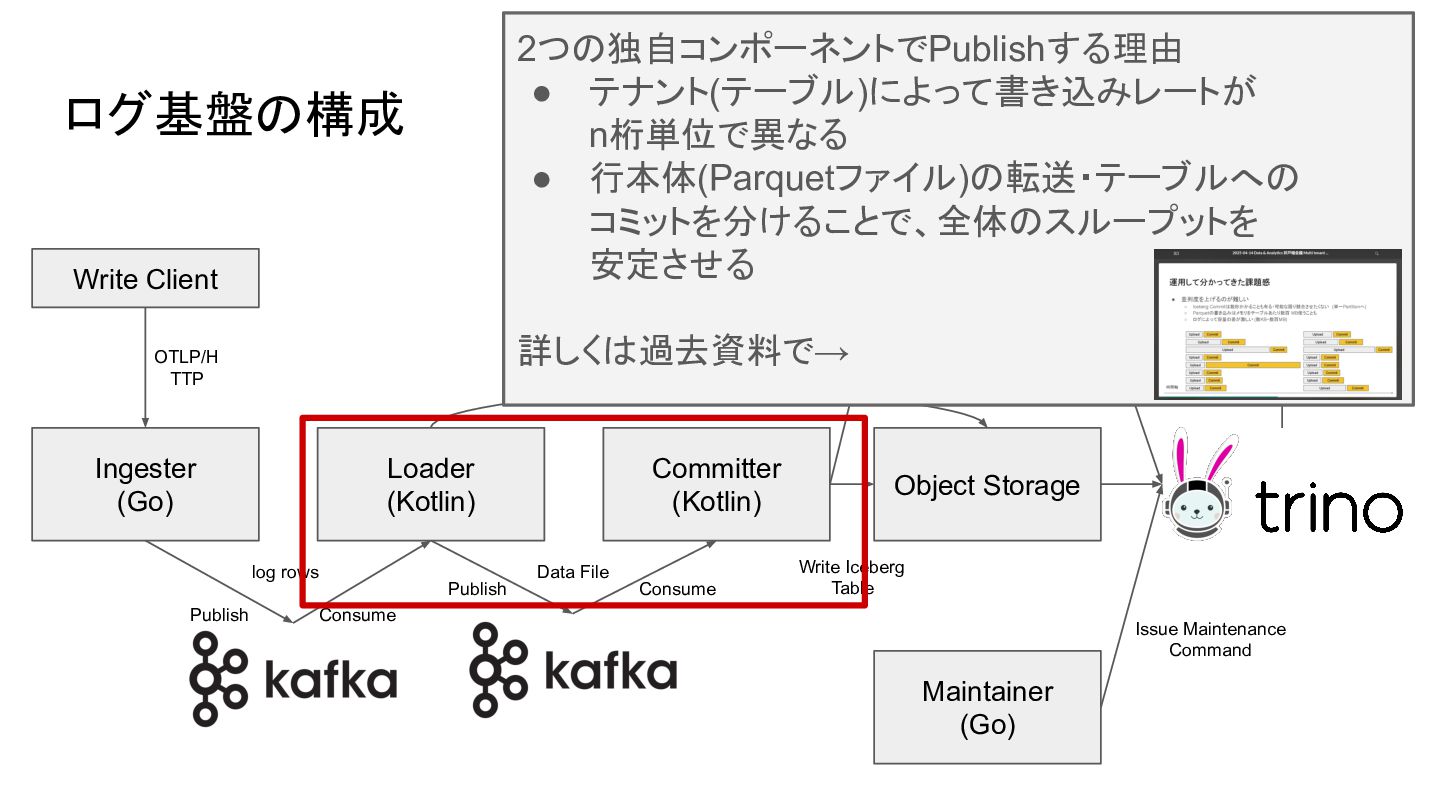
ログ基盤の構成 Write Client Ingester (Go) Committer (Kotlin) Object Storage REST
Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows
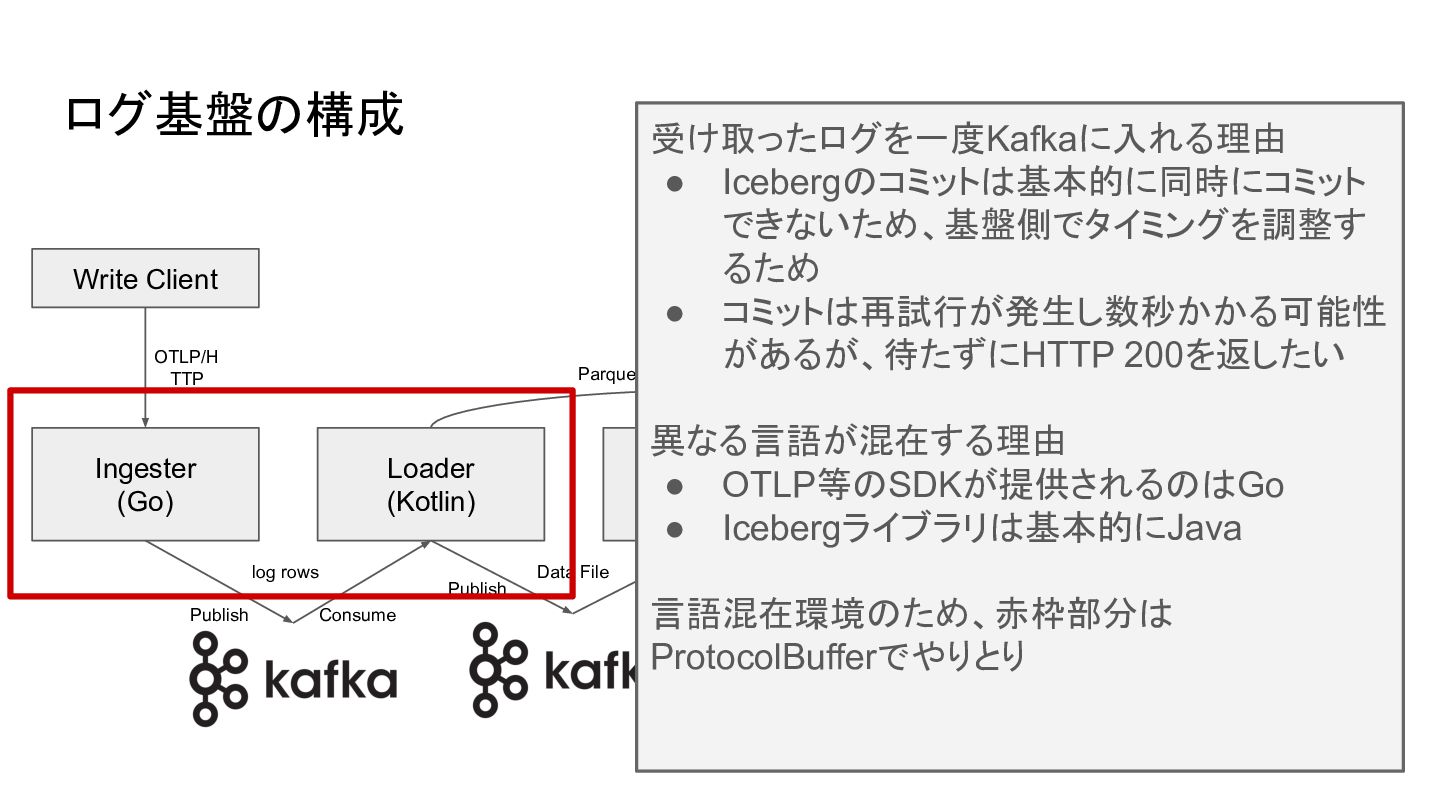
ログ基盤の構成 Write Client Ingester (Go) Committer (Kotlin) Object Storage REST
Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows 受け取ったログを一度Kafkaに入れる理由 • Icebergのコミットは基本的に同時にコミット できないため、基盤側でタイミングを調整す るため • コミットは再試行が発生し数秒かかる可能性 があるが、待たずにHTTP 200を返したい 異なる言語が混在する理由 • OTLP等のSDKが提供されるのはGo • Icebergライブラリは基本的にJava 言語混在環境のため、赤枠部分は ProtocolBufferでやりとり
ログ基盤の構成 Write Client Ingester (Go) Committer (Kotlin) Object Storage REST
Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows 2つの独自コンポーネントでPublishする理由 • テナント(テーブル)によって書き込みレートが n桁単位で異なる • 行本体(Parquetファイル)の転送・テーブルへの コミットを分けることで、全体のスループットを 安定させる 詳しくは過去資料で→
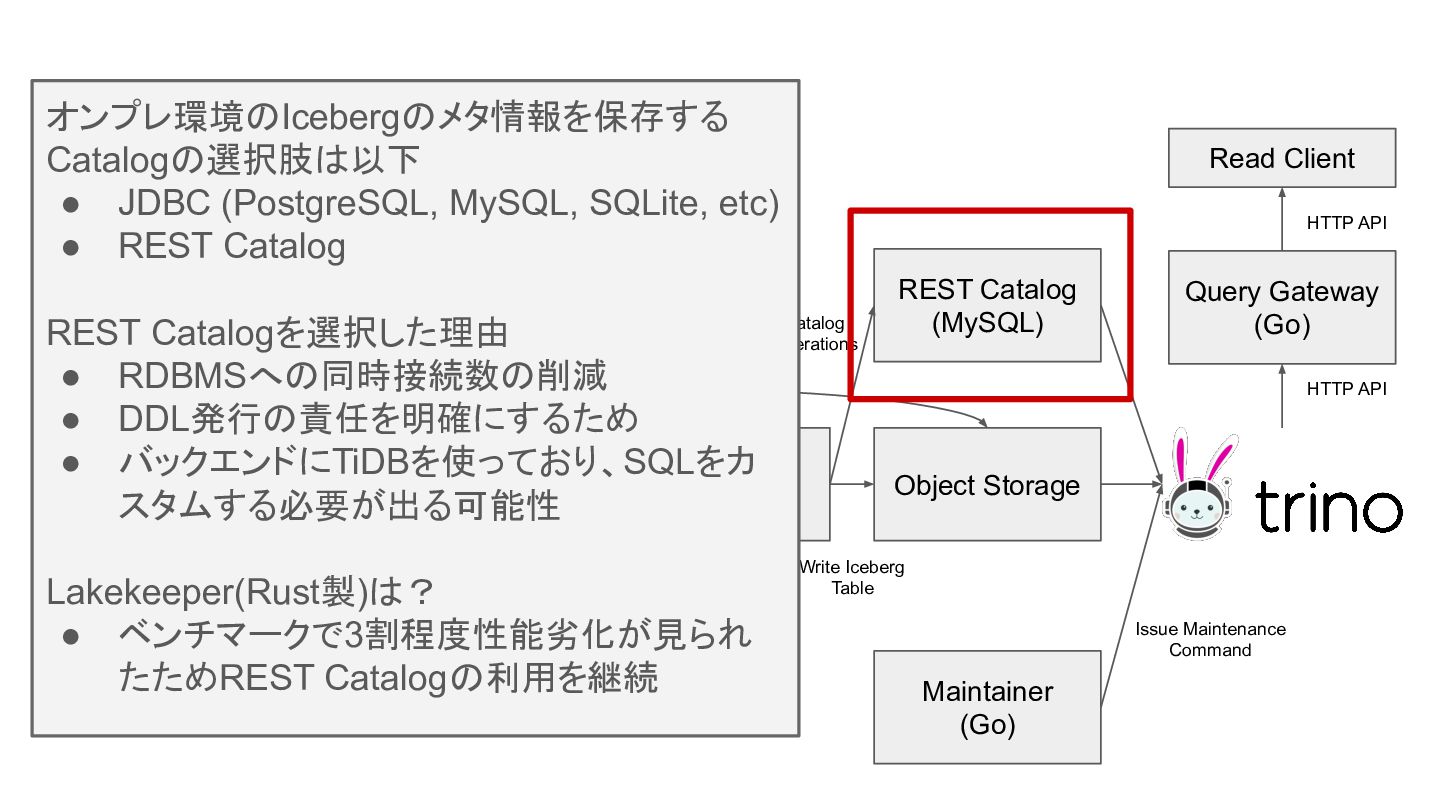
ログ基盤の構成 Write Client Ingester (Go) Committer (Kotlin) Object Storage REST
Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows オンプレ環境のIcebergのメタ情報を保存する Catalogの選択肢は以下 • JDBC (PostgreSQL, MySQL, SQLite, etc) • REST Catalog REST Catalogを選択した理由 • RDBMSへの同時接続数の削減 • DDL発行の責任を明確にするため • バックエンドにTiDBを使っており、SQLをカ スタムする必要が出る可能性 Lakekeeper(Rust製)は? • ベンチマークで3割程度性能劣化が見られ たためREST Catalogの利用を継続
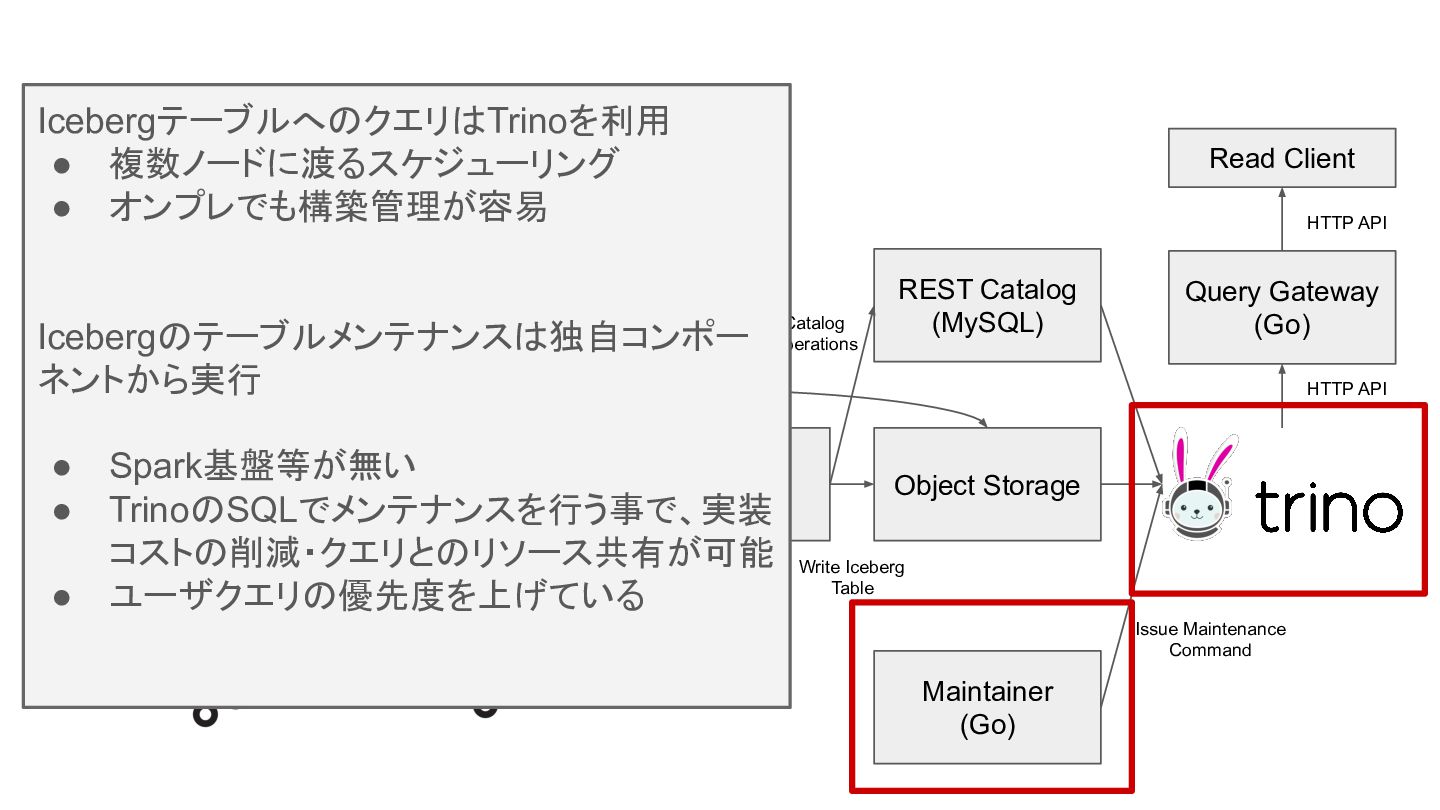
ログ基盤の構成 Write Client Ingester (Go) Committer (Kotlin) Object Storage REST
Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows IcebergテーブルへのクエリはTrinoを利用 • 複数ノードに渡るスケジューリング • オンプレでも構築管理が容易 Icebergのテーブルメンテナンスは独自コンポー ネントから実行 • Spark基盤等が無い • TrinoのSQLでメンテナンスを行う事で、実装 コストの削減・クエリとのリソース共有が可能 • ユーザクエリの優先度を上げている
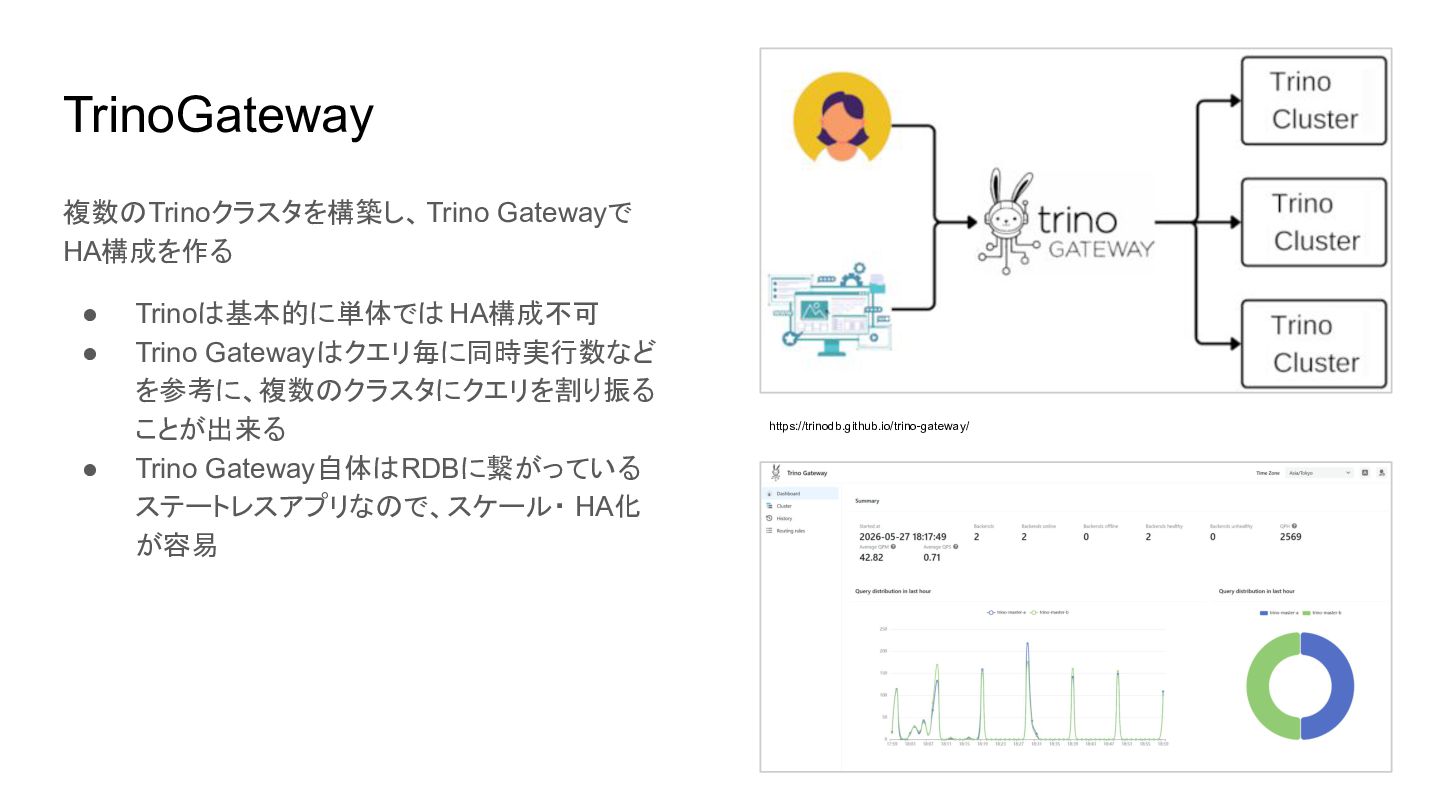
TrinoGateway 複数のTrinoクラスタを構築し、Trino Gatewayで HA構成を作る • Trinoは基本的に単体では HA構成不可 • Trino Gatewayはクエリ毎に同時実行数など
を参考に、複数のクラスタにクエリを割り振る ことが出来る • Trino Gateway自体はRDBに繋がっている ステートレスアプリなので、スケール・ HA化 が容易 https://trinodb.github.io/trino-gateway/
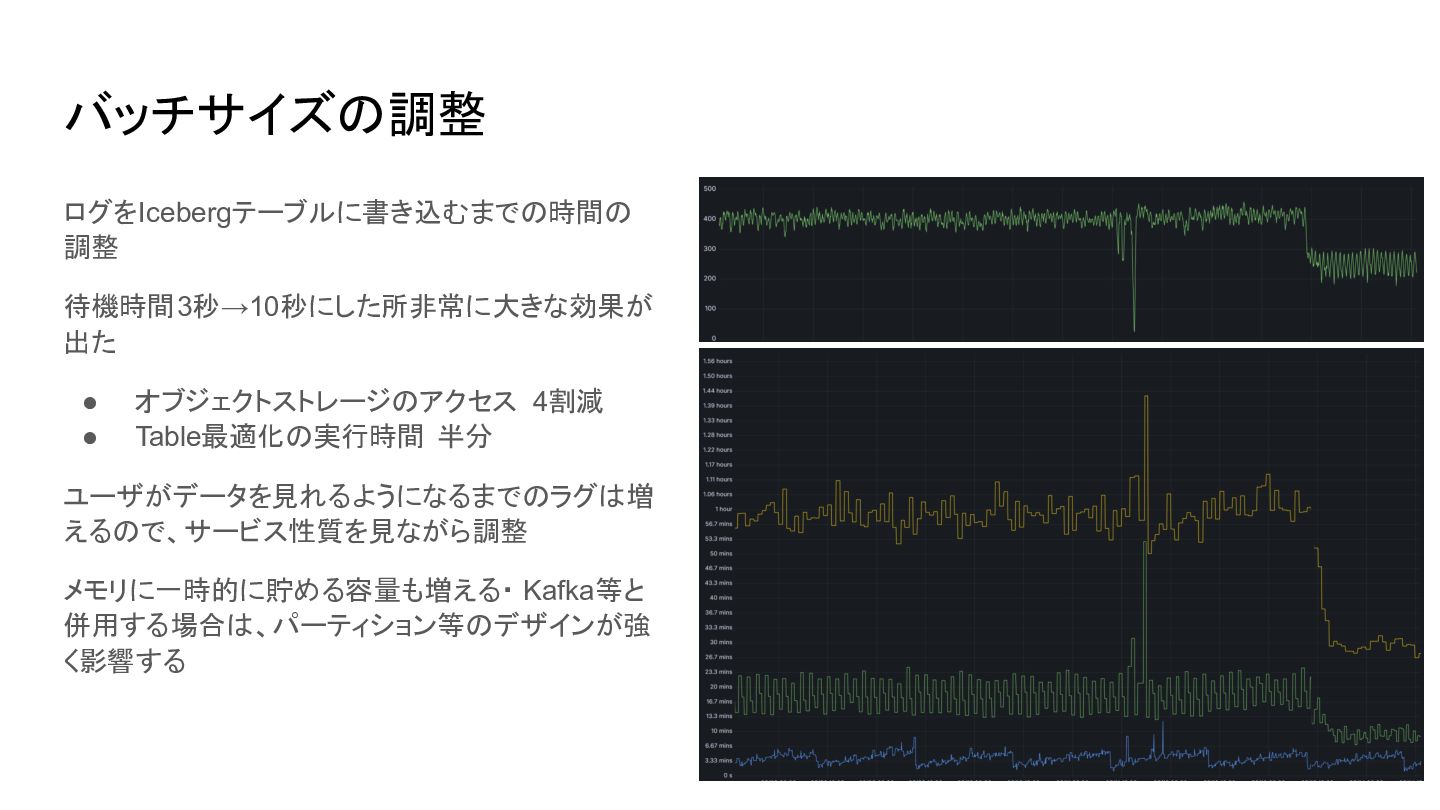
バッチサイズの調整 ログをIcebergテーブルに書き込むまでの時間の 調整 待機時間3秒→10秒にした所非常に大きな効果が 出た • オブジェクトストレージのアクセス 4割減 • Table最適化の実行時間
半分 ユーザがデータを見れるようになるまでのラグは増 えるので、サービス性質を見ながら調整 メモリに一時的に貯める容量も増える・ Kafka等と 併用する場合は、パーティション等のデザインが強 く影響する
Iceberg Trinoログ基盤の設計ポイント • テーブルでテナント分離 • 日付ベースでのパーティション・時間でのソート • マイクロサービス構成 ◦ KafkaでMQ
◦ 2段書き込み構成でスループット向上 ◦ REST Catalog(BackendはTiDB) ◦ Trinoでクエリ・テーブル最適化 • TrinoGatewayでのTrinoクラスタHA化 • バッチサイズを適切なサイズに設定
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}