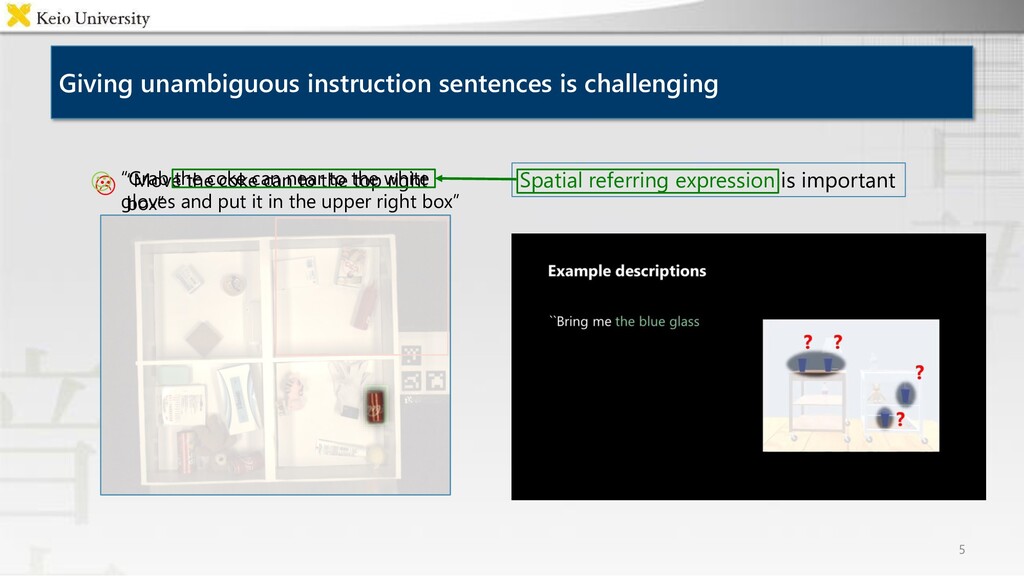
Social background: Domestic service robots communicating with users are a promising solution for disabled and elderly people Problem: Multimodal language understanding models require large multimodal corpora [Magassouba+ RAL&ICRA20] [Magassouba+ IROS18 RoboCup Best Paper Award] Our previous studies
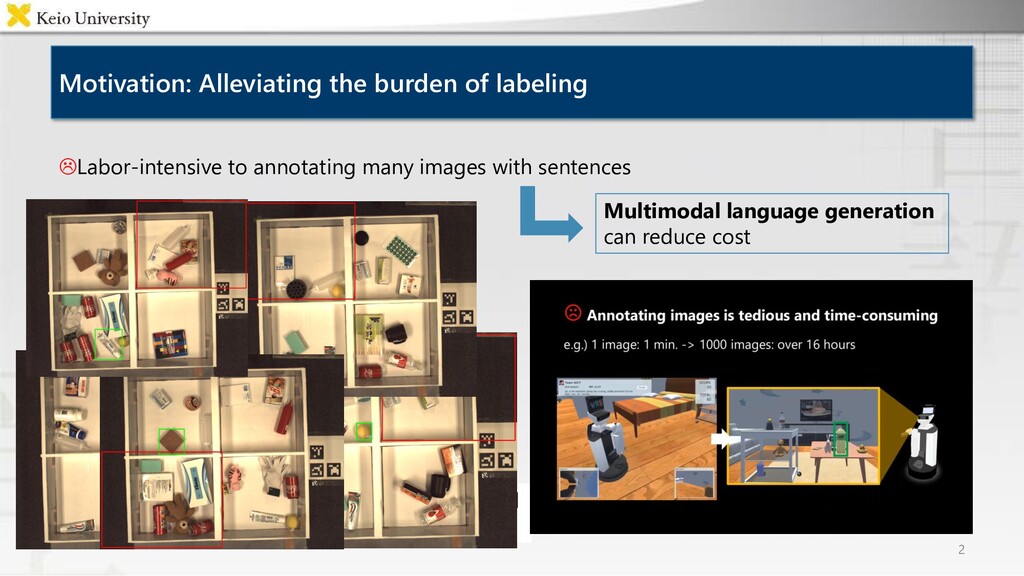
and put it into the lower left box Motivation: Alleviating the burden of labeling 2 Multimodal language generation can reduce cost Labor-intensive to annotating many images with sentences
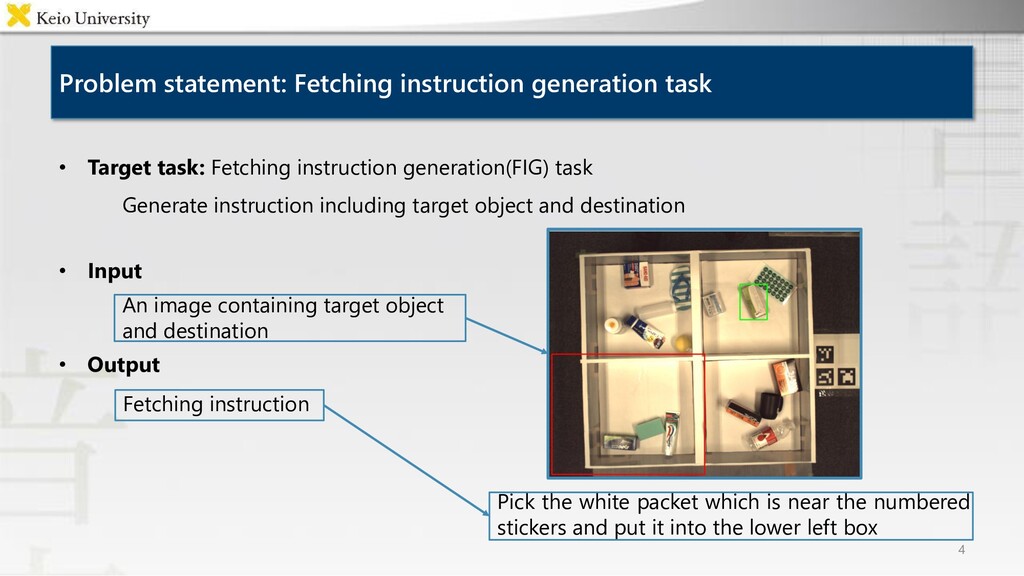
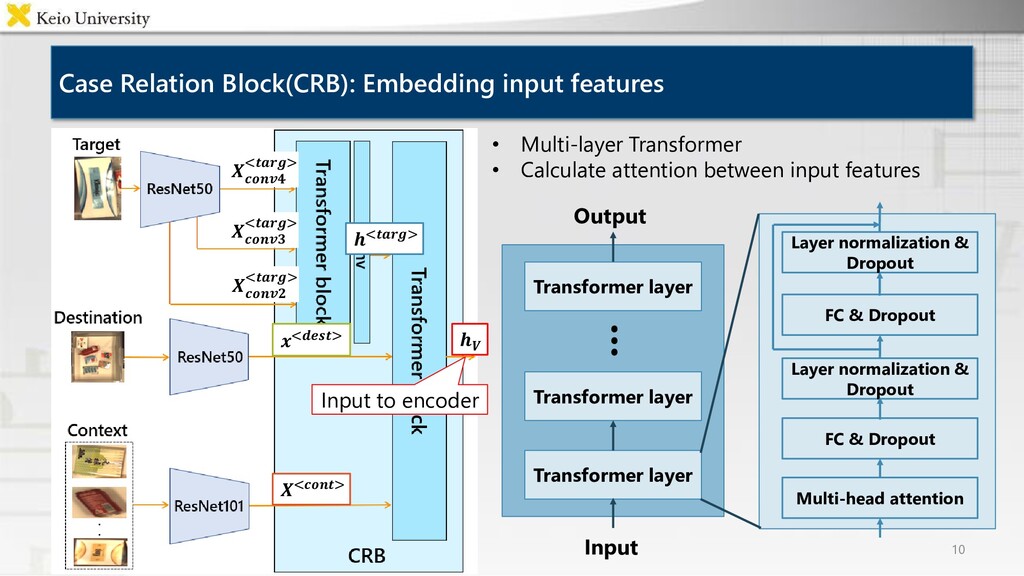
and put it into the lower left box Problem statement: Fetching instruction generation task 4 • Target task: Fetching instruction generation(FIG) task Generate instruction including target object and destination • Input An image containing target object and destination • Output Fetching instruction
• Sample configuration • Image • Coordinates of region of target object • destination • Fetching instruction • Size Set #Image #Target object #Instruction train 1044 22014 81087 valid 116 2503 8774 test 20 352 898 “Move the blue and white tissue box to the top right bin”
19 Ground truth Move the black rectangle from the lower left box, to the upper right box [Ogura+ RAL20] Grab the the the red and and put it in the lower left box Ours ☺Move the black object in the lower left box to the upper right box Specify the target by referring expression
20 Ground truth Move the rectangular black thing from the box with an empty drink bottle in it to the box with a coke can in it [Ogura+ RAL20] Move the red bottle to the right upper box Ours ☺Move the black mug to the lower left box Clearly express the target as "black mug"
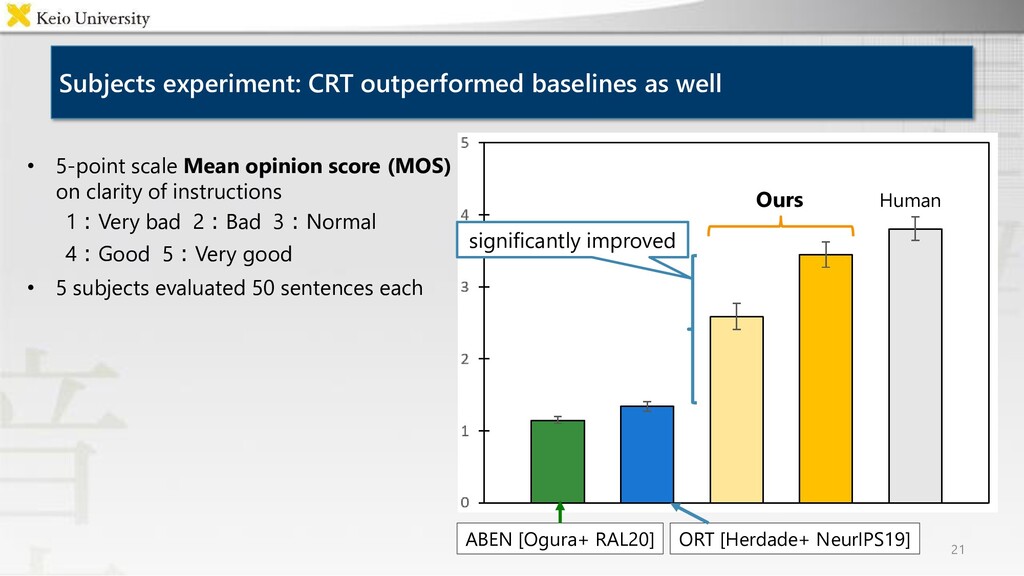
scale Mean opinion score (MOS) on clarity of instructions 1:Very bad 2:Bad 3:Normal 4:Good 5:Very good • 5 subjects evaluated 50 sentences each significantly improved Ours ABEN [Ogura+ RAL20] ORT [Herdade+ NeurIPS19] Human
auxiliary reconstruction loss can reduce errors GT ☺Take blue cup and put it in the left upper box Ours Move the white bottle to the left upper box Target object error 79% Major 51% Minor 28% Spatial referring expression error 16% Others 5%
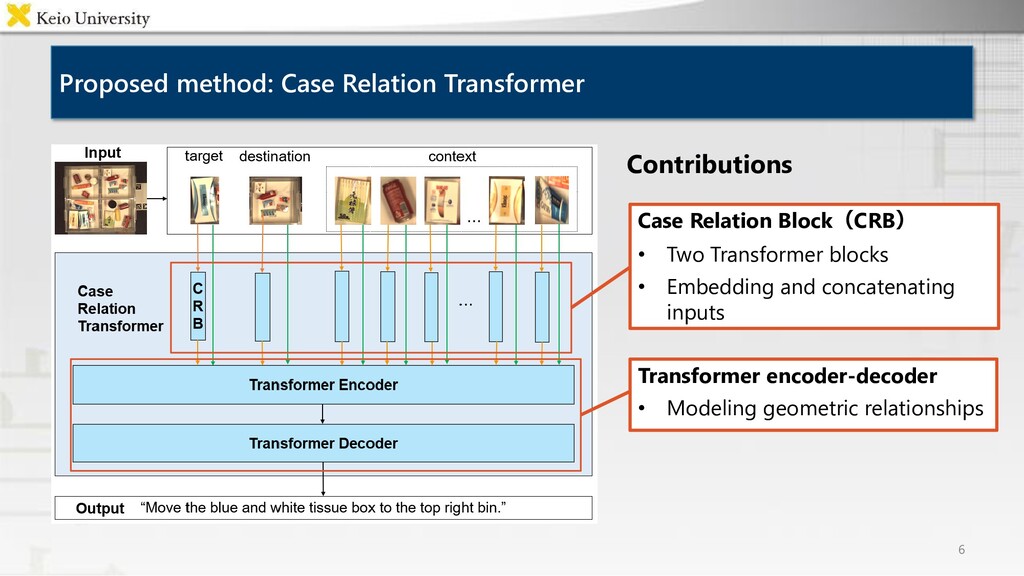
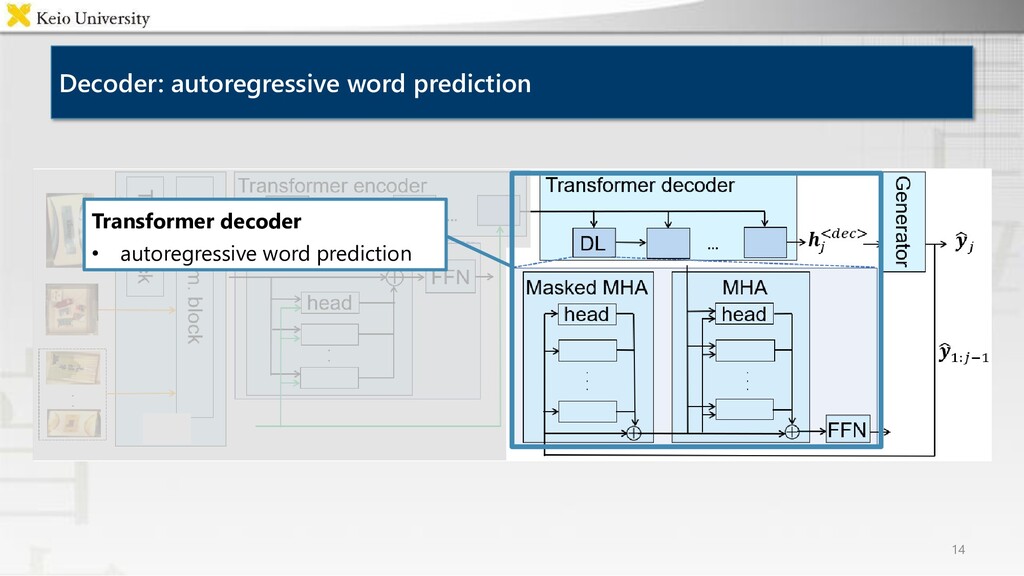
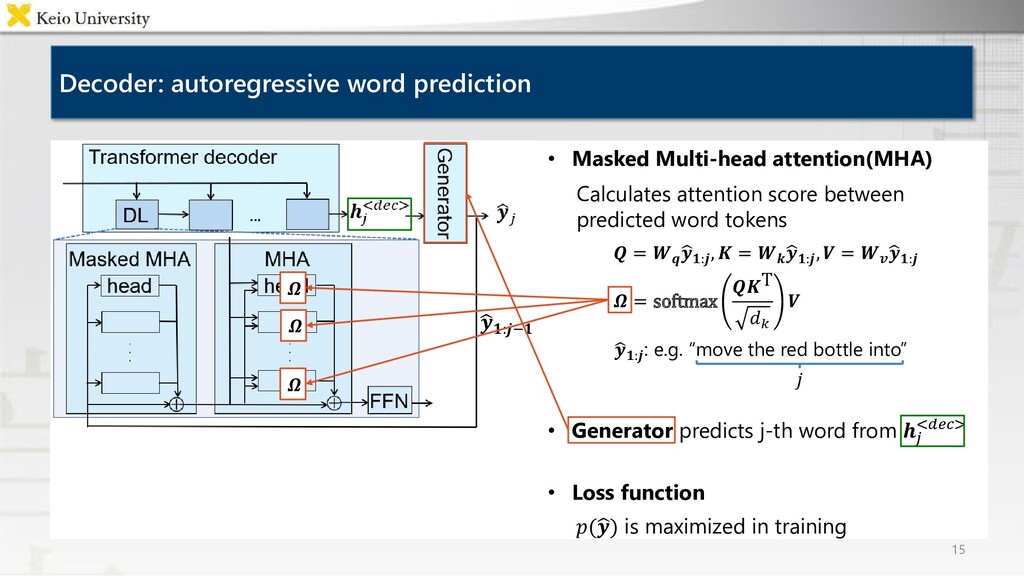
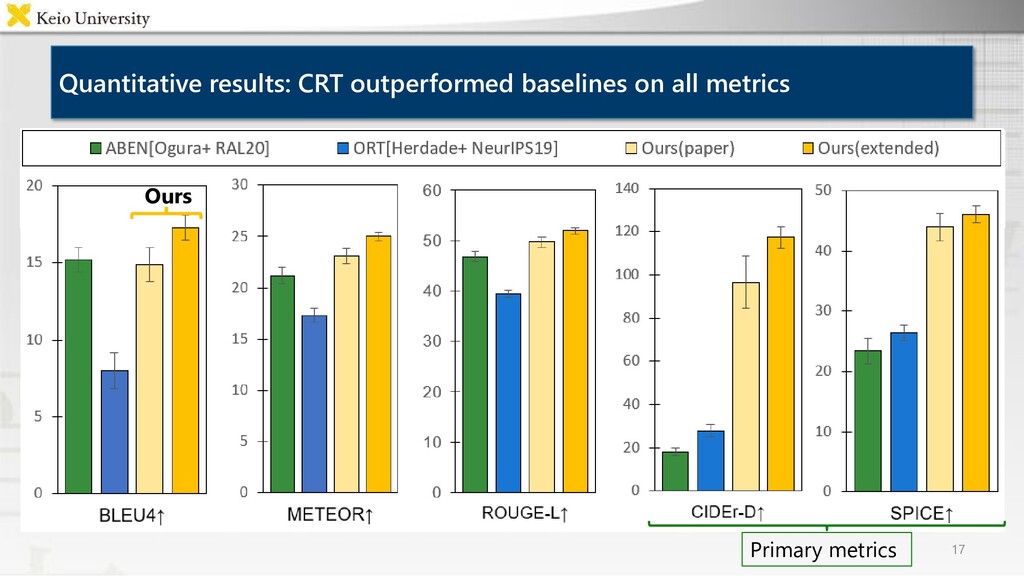
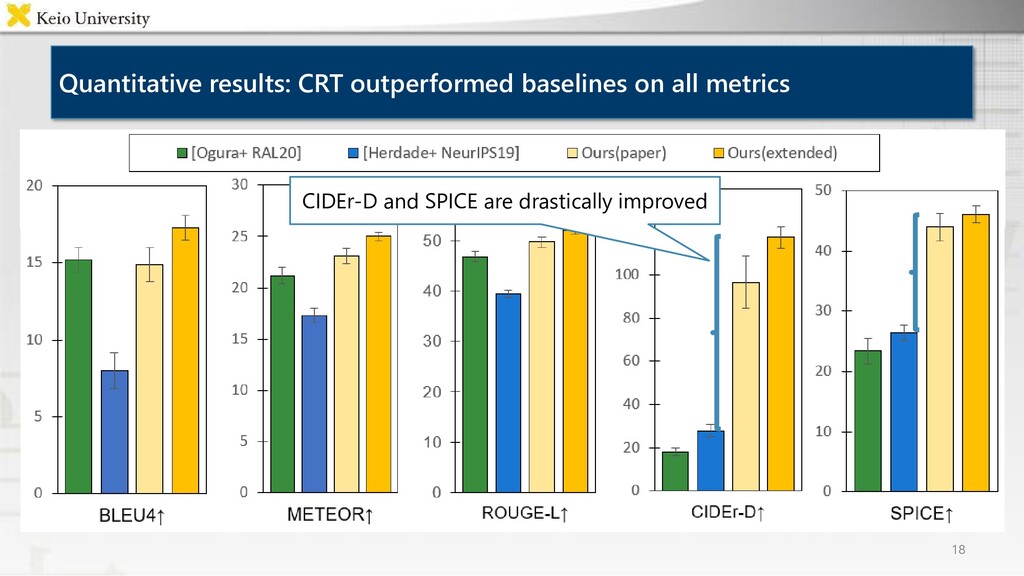
corpora, however it is labor-intensive to annotate many images • Proposed method Case Relation Transformer: Crossmodal fetching instruction generation model • Experimental results CRT outperformed baselines on all metrics, and generated concise instructions using referring expressions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Transformer encoder based on ORT [Herdade+ NeurIPS19] 11 Transformer encoder](https://files.speakerdeck.com/presentations/2aa1de63c67048d8a253c9b009268b02/slide_11.jpg){kind=link}
![Transformer encoder based on ORT [Herdade+ NeurIPS19] 12 • 𝝎𝐺](https://files.speakerdeck.com/presentations/2aa1de63c67048d8a253c9b009268b02/slide_12.jpg){kind=link}
![Transformer encoder based on ORT [Herdade+ NeurIPS19] 13 • 𝝎𝐺](https://files.speakerdeck.com/presentations/2aa1de63c67048d8a253c9b009268b02/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
![PFN-PIC dataset[Hatori+ ICRA18]: Set of images and fetching instructions 16](https://files.speakerdeck.com/presentations/2aa1de63c67048d8a253c9b009268b02/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}