Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] DIRL:Domain-Invariant Representa...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 19, 2022
Technology
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] DIRL:Domain-Invariant Representation Learning for Sim-to-Real Transfer
Semantic Machine Intelligence Lab., Keio Univ.
PRO
May 19, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
85
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AICoEでAIネイティブ組織への進化
yukiogawa
0
220
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
220
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
200
発表と総括 / Presentations and Summary
ks91
PRO
0
190
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
270
「休む」重要さ
smt7174
6
1.6k
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
480
そのドキュメント、自動化しませんか?
yuksew
1
410
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
Featured
See All Featured
Measuring & Analyzing Core Web Vitals
bluesmoon
9
900
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Mobile First: as difficult as doing things right
swwweet
225
10k
Practical Orchestrator
shlominoach
191
11k
Between Models and Reality
mayunak
4
380
Google's AI Overviews - The New Search
badams
0
1.1k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
RailsConf 2023
tenderlove
30
1.5k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Transcript
Ajay Kumer Tanwai ( University of California, Berkeley ) DIRL
: Domain-Invariant Representation Learning for Sim-to-Real Transfer Tanwani, Ajay Kumar. "DIRL: Domain-Invariant Representation Learning for Sim-to-Real Transfer." CoRL (2020). 慶應義塾大学 杉浦孔明研究室 畑中駿平
2 • ドメイン適応 ( Domain Adaptation )の新たなアルゴリズム DIRL (ドメイン不変表現学習, Domain-Invariant
Representation Learning ) の提案 概要 ✓ 敵対的学習を含む4つの損失関数の導入 ✓ Sim-to-Real の把持タスクで高い精度を獲得
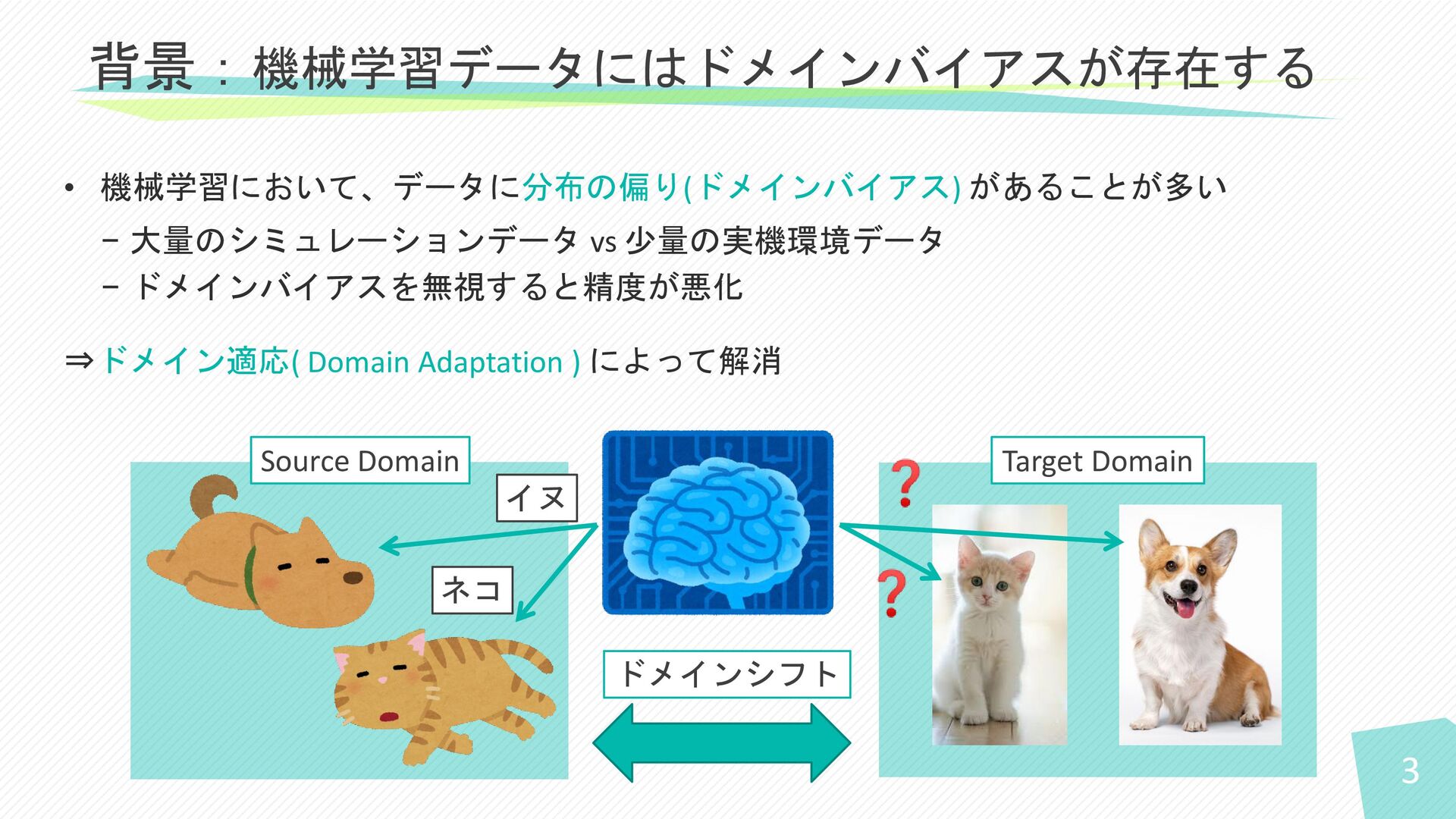
3 • 機械学習において、データに分布の偏り(ドメインバイアス) があることが多い − 大量のシミュレーションデータ vs 少量の実機環境データ − ドメインバイアスを無視すると精度が悪化
⇒ドメイン適応( Domain Adaptation ) によって解消 背景:機械学習データにはドメインバイアスが存在する Source Domain Target Domain イヌ ネコ ドメインシフト
4 既存研究:様々なアプローチからのドメイン適応 既存手法 特徴 DANN [Ganin+, 2016] • 敵対的学習によるドメイン適応 •
Source Domain か Target Domainを識別させる [Saito+, CVPR2018] • ラベルおよび条件付きドメイン適応 • 2つのクラス識別器それぞれの推定結果の不一致(discrepancy)に注目 [Seita+, IROS2020] • Sim-to-Real Transfer の手法・ドメインランダム法 • ドメイン間の不一致をシミュレーションパラメータの変動として扱う [Saito+, CVPR18] DANN[Ganin+, 2016]
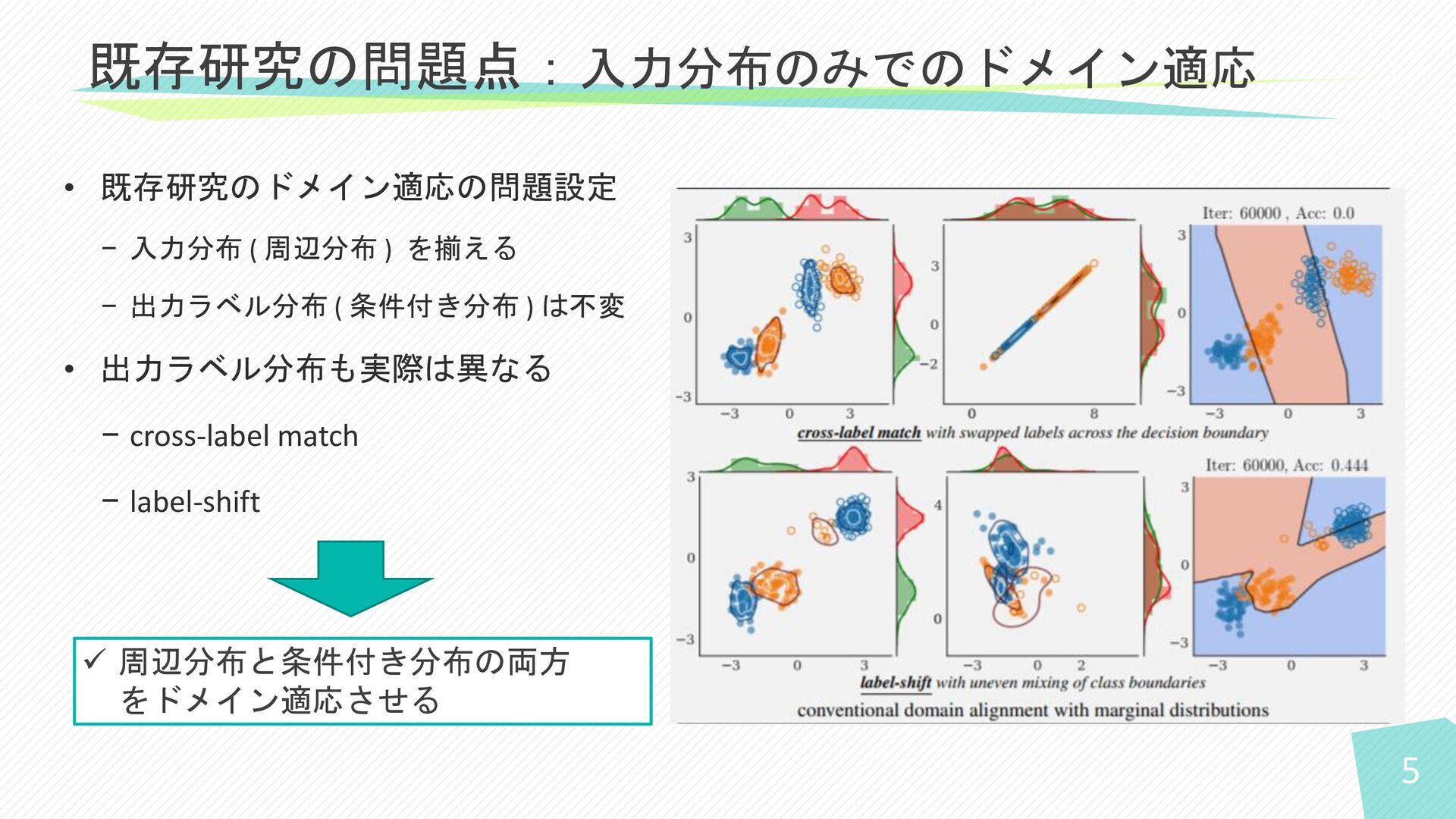
5 • 既存研究のドメイン適応の問題設定 − 入力分布 ( 周辺分布 ) を揃える −
出力ラベル分布 ( 条件付き分布 ) は不変 • 出力ラベル分布も実際は異なる − cross-label match − label-shift 既存研究の問題点:入力分布のみでのドメイン適応 ✓ 周辺分布と条件付き分布の両方 をドメイン適応させる
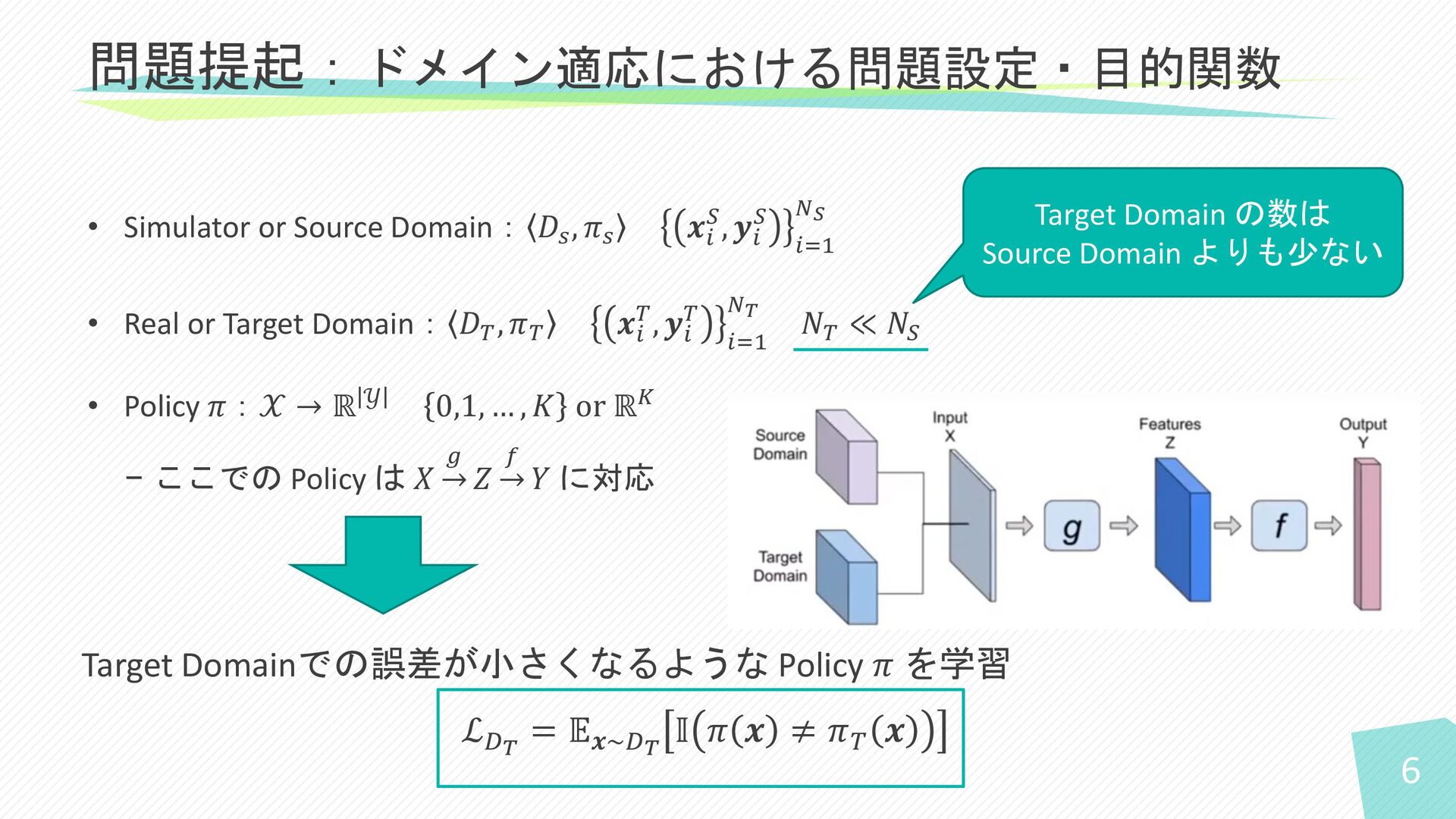
6 • Simulator or Source Domain: 𝐷𝑠 , 𝜋𝑠 𝒙𝑖
𝑆, 𝒚𝑖 𝑆 𝑖=1 𝑁𝑆 • Real or Target Domain: 𝐷𝑇 , 𝜋𝑇 𝒙𝑖 𝑇, 𝒚𝑖 𝑇 𝑖=1 𝑁𝑇 𝑁𝑇 ≪ 𝑁𝑆 • Policy 𝜋:𝒳 → ℝ 𝒴 0,1, … , 𝐾 or ℝ𝐾 − ここでの Policy は 𝑋 → 𝑔 𝑍 → 𝑓 𝑌 に対応 問題提起:ドメイン適応における問題設定・目的関数 Target Domainでの誤差が小さくなるような Policy 𝜋 を学習 ℒ𝐷𝑇 = 𝔼𝒙~𝐷𝑇 𝕀 𝜋 𝒙 ≠ 𝜋𝑇 𝒙 Target Domain の数は Source Domain よりも少ない
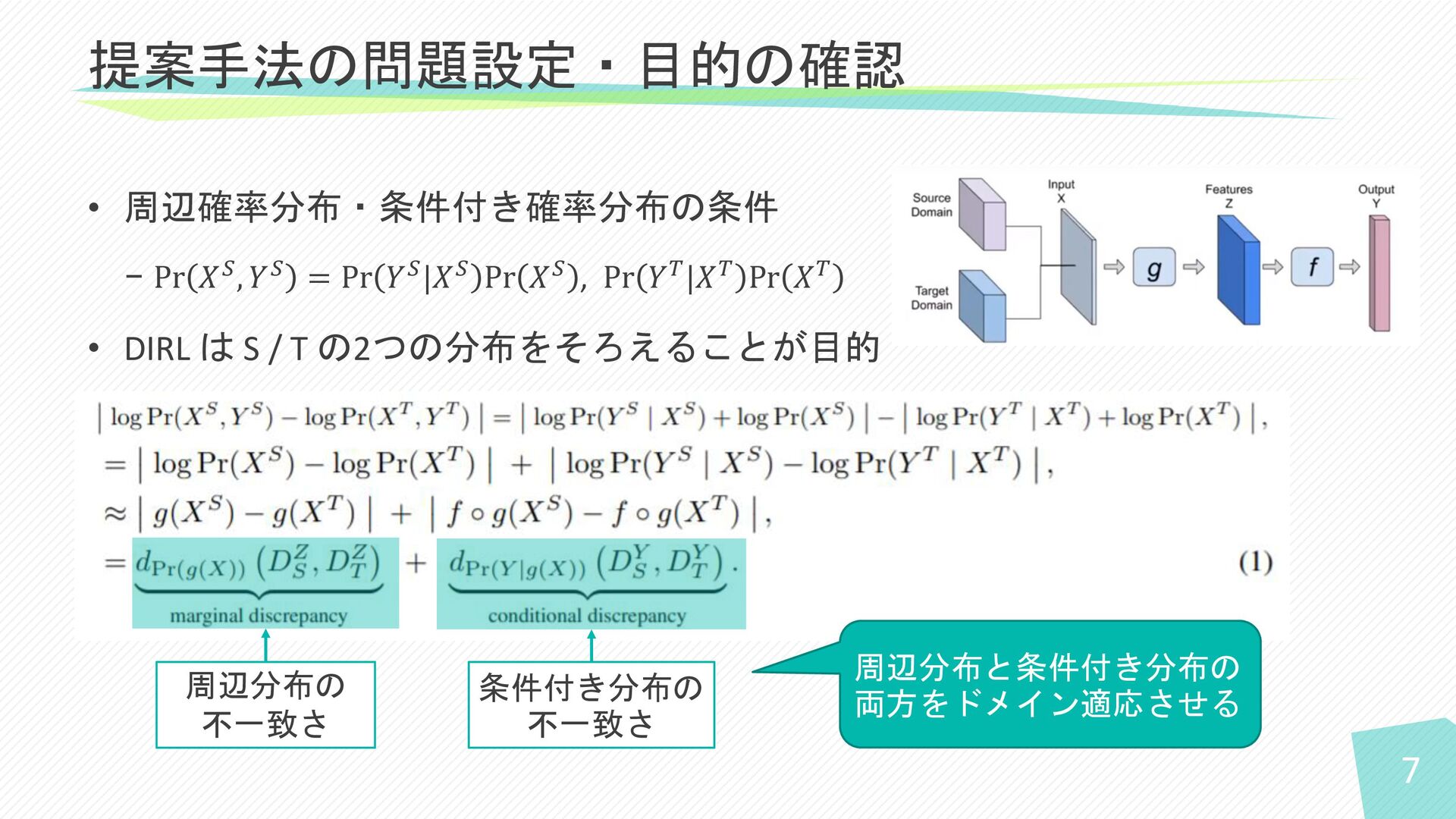
7 • 周辺確率分布・条件付き確率分布の条件 − Pr 𝑋𝑆, 𝑌𝑆 = Pr 𝑌𝑆|𝑋𝑆
Pr 𝑋𝑆 , Pr 𝑌𝑇|𝑋𝑇 Pr 𝑋𝑇 • DIRL は S / T の2つの分布をそろえることが目的 提案手法の問題設定・目的の確認 周辺分布の 不一致さ 条件付き分布の 不一致さ 周辺分布と条件付き分布の 両方をドメイン適応させる
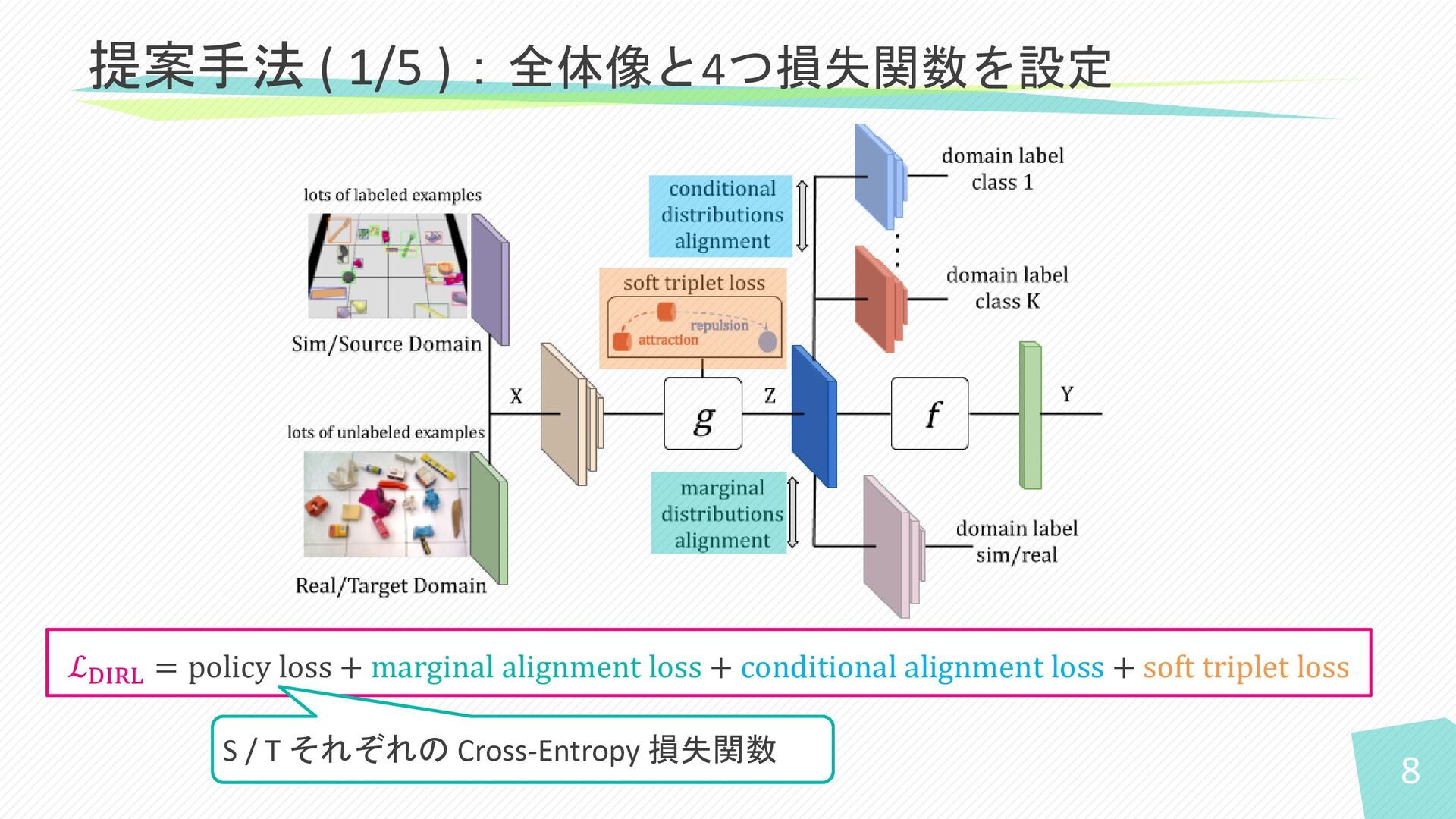
8 提案手法 ( 1/5 ):全体像と4つ損失関数を設定 ℒDIRL = policy loss +
marginal alignment loss + conditional alignment loss + soft triplet loss S / T それぞれの Cross-Entropy 損失関数
9 • Source / Target Domain の周辺分布を敵対的学習によって揃える • Generator 𝑔(𝑋):データを
S / T 共有の特徴空間に符号化 − Target Domain のデータのみに関する特徴抽出器を適応 ( ∵ 𝑁𝑇 ≪ 𝑁𝑆 ) − 特徴分布 ( 周辺分布 ) において、S / T を一致させる • Discriminator 𝐷(𝑋):データが S / T のどちらかを識別 − 特徴分布 ( 周辺分布 ) において、S / T を一致させないようにする 提案手法 ( 2/5 ):Marginal Alignment Loss min 𝐷 ℒ𝑚𝑎 𝑔 𝒙𝑠 , 𝒙𝑡 , 𝐷 𝒙𝑠 , 𝒙𝑡 = −𝔼𝒙𝑠~𝑋𝑠 log 𝐷 𝑔 𝒙𝑠 − 𝔼𝒙𝑡~𝑋𝑡 log 1 − 𝐷 𝑔 𝒙𝑡 min 𝑔 ℒ𝑚𝑎 𝑔 𝒙𝑡 , 𝐷 𝒙𝑠 , 𝒙𝑡 = −𝔼𝒙𝑡~𝑋𝑡 log 𝐷 𝑔 𝒙𝑡
10 • 条件付き分布におけるラベル間のマッチングや label shift の問題を解決 • Generator 𝑔(𝑋):周辺分布から各クラスの条件付き分布を生成 −
各クラスで生じるドメインの重複を分離 • Discriminator 𝐷(𝑋):クラス識別器 − S / T データに関する条件付き分布の不一致さを推定・最小化 提案手法 ( 3/5 ):Conditional Alignment Loss min 𝐷 ℒ𝑐𝑎𝑘 𝑔 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) , 𝐷 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) = −𝔼 𝒙𝑠 (𝑘) ~𝑋𝑠 log 𝐷 𝑔 𝒙𝑠 (𝑘) − 𝔼 𝒙𝑡 (𝑘) ~𝑋𝑡 log 1 − 𝐷 𝒙 𝑡 (𝑘) min 𝑔 ℒ𝑐𝑎𝑘 𝑔 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) , 𝐷 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) = −𝔼 𝒙𝑡 (𝑘) ~𝑋𝑡 log 𝐷 𝑔 𝒙 𝑡 (𝑘)
11 • Triplet Loss [Schroff+, CoRR2015] の変形を導入 − クラス間の分散を大きく・クラス内の分散を小さくさせる −
ミニバッチ内からアンカー・正例・負例それぞれの特徴量の KL 距離を計算 • 𝒩 ҧ 𝑔 𝒙𝑎 , 𝜎2 はガウシアン分布に従う 提案手法 ( 4/5 ):Soft Triplet Loss 𝒩 ҧ 𝑔 𝒙𝑖 ; ҧ 𝑔 𝒙𝑎 , 𝜎2 = exp( −1 𝜎2 ҧ 𝑔 𝒙𝑖 − ҧ 𝑔 𝒙𝑎 2 2) σ 𝑗=1 𝐾 exp( −1 𝜎2 ҧ 𝑔 𝒙𝑗 − ҧ 𝑔 𝒙𝑎 2 2 ) 𝑖=1 𝐾 ℒ𝑡𝑙 = 𝑎=1 𝑀 1 𝑀𝑝 − 1 𝑝=1 𝑝≠𝑎 𝑀𝑝 KL 𝒩 ҧ 𝑔 𝒙𝑎 , 𝜎2 ||𝒩 ҧ 𝑔 𝒙𝑝 , 𝜎2 − 1 𝑀𝑛 𝑛=1 𝑀𝑛 KL 𝒩 ҧ 𝑔 𝒙𝑎 , 𝜎2 ||𝒩 ҧ 𝑔 𝒙𝑛 , 𝜎2 + α𝑡𝑙 + anchors positives negatives
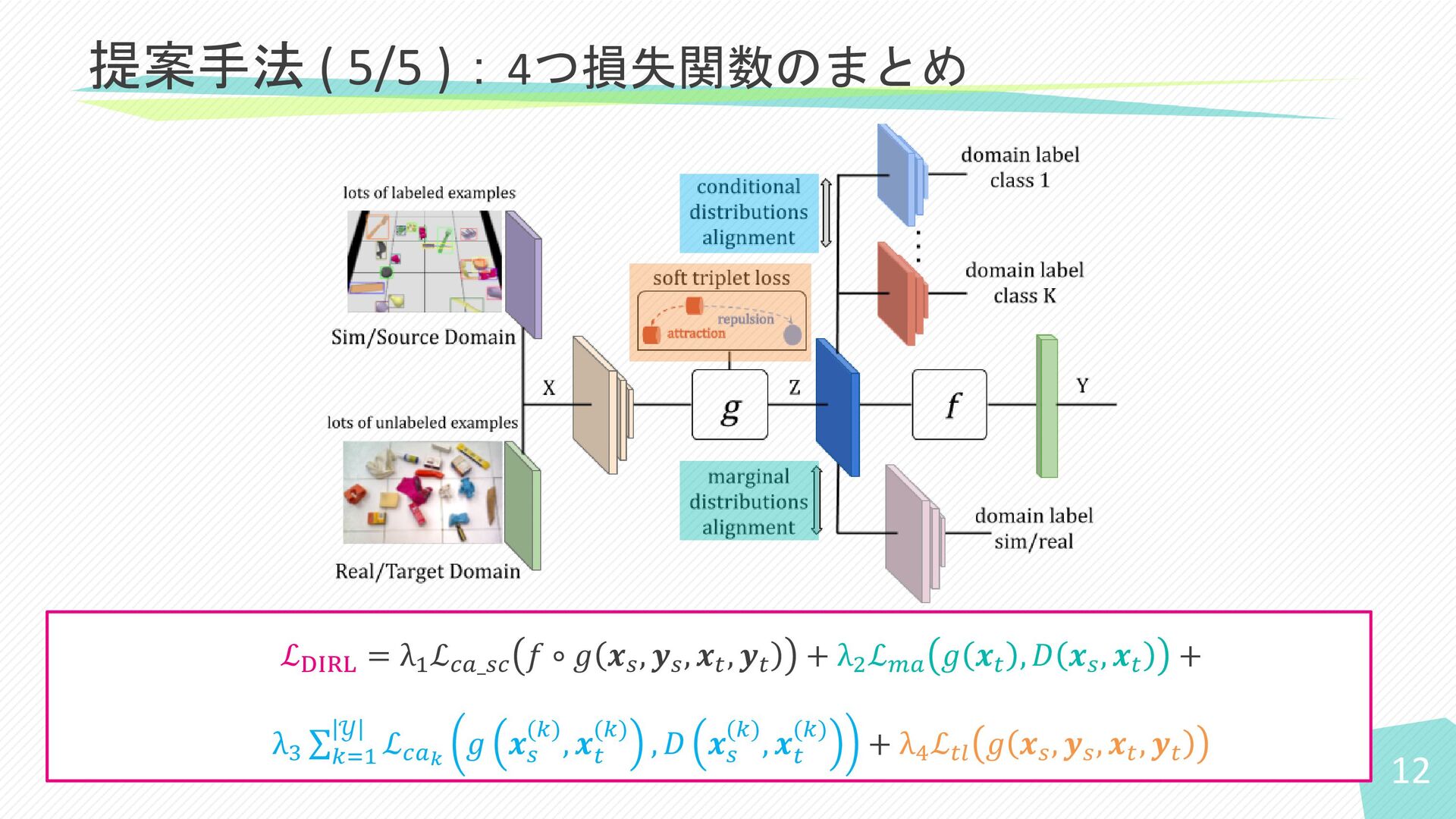
12 提案手法 ( 5/5 ):4つ損失関数のまとめ ℒDIRL = λ1 ℒ𝑐𝑎_𝑠𝑐 𝑓
∘ 𝑔 𝒙𝑠 , 𝒚𝑠 , 𝒙𝑡 , 𝒚𝑡 + λ2 ℒ𝑚𝑎 𝑔 𝒙𝑡 , 𝐷 𝒙𝑠 , 𝒙𝑡 + λ3 σ 𝑘=1 𝒴 ℒ𝑐𝑎𝑘 𝑔 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) , 𝐷 𝒙𝑠 (𝑘), 𝒙 𝑡 (𝑘) + λ4 ℒ𝑡𝑙 𝑔 𝒙𝑠 , 𝒚𝑠 , 𝒙𝑡 , 𝒚𝑡
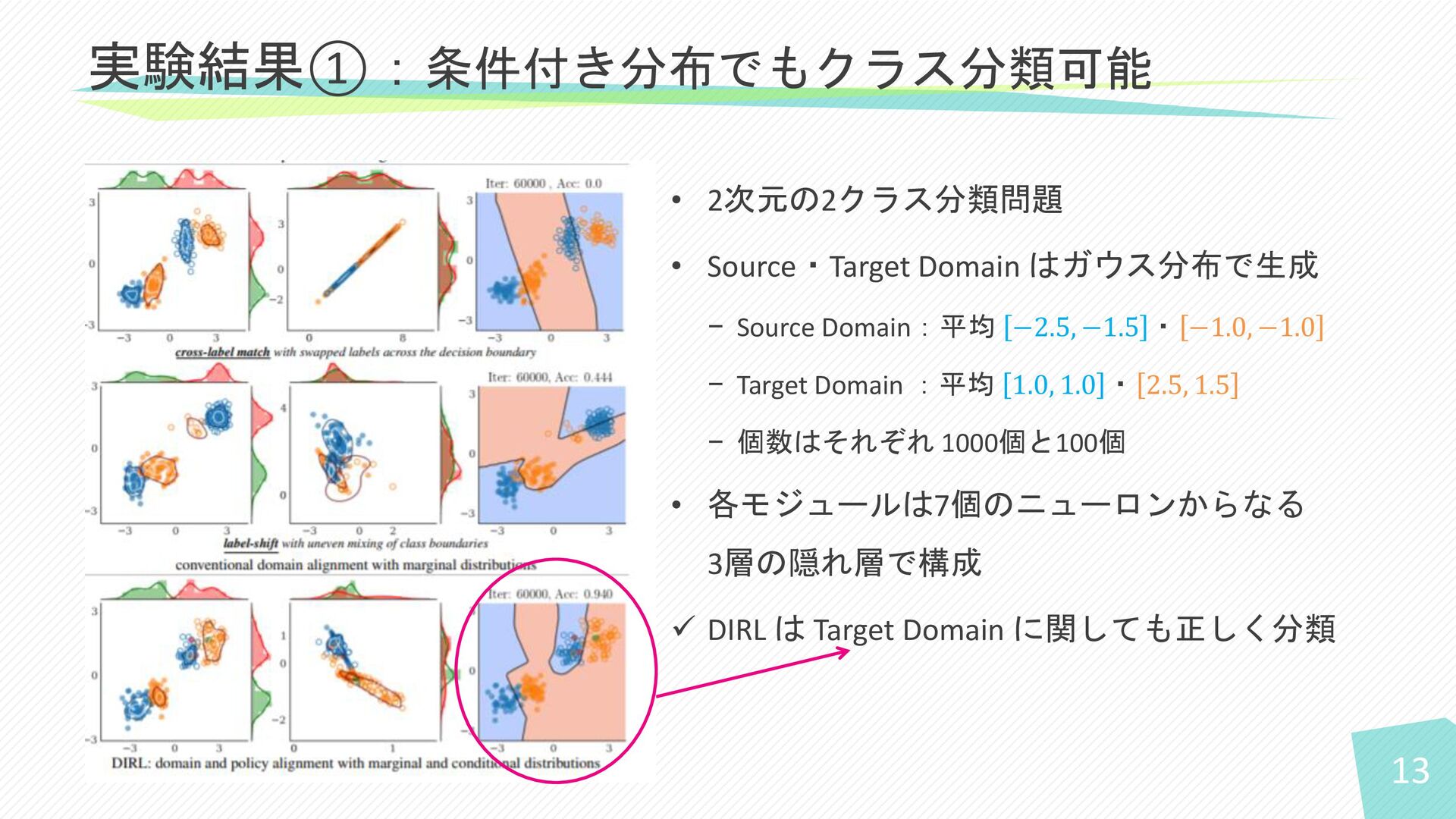
13 • 2次元の2クラス分類問題 • Source・Target Domain はガウス分布で生成 − Source Domain:平均
−2.5, −1.5 ・ −1.0, −1.0 − Target Domain :平均 1.0, 1.0 ・ 2.5, 1.5 − 個数はそれぞれ 1000個と100個 • 各モジュールは7個のニューロンからなる 3層の隠れ層で構成 ✓ DIRL は Target Domain に関しても正しく分類 実験結果①:条件付き分布でもクラス分類可能
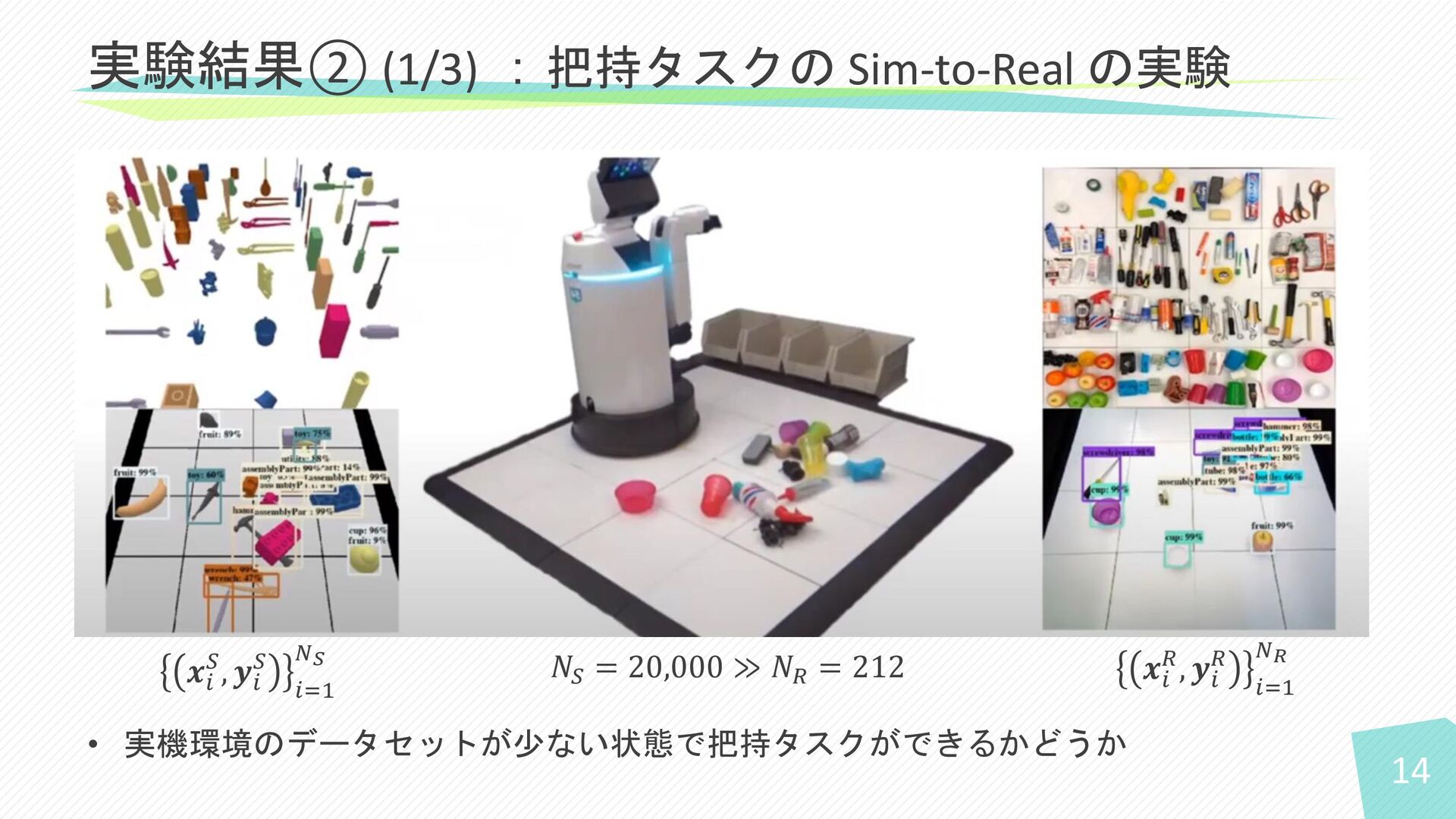
14 • 実機環境のデータセットが少ない状態で把持タスクができるかどうか 実験結果② (1/3) :把持タスクの Sim-to-Real の実験 𝒙𝑖 𝑆,
𝒚𝑖 𝑆 𝑖=1 𝑁𝑆 𝑁𝑆 = 20,000 ≫ 𝑁𝑅 = 212 𝒙𝑖 𝑅, 𝒚𝑖 𝑅 𝑖=1 𝑁𝑅
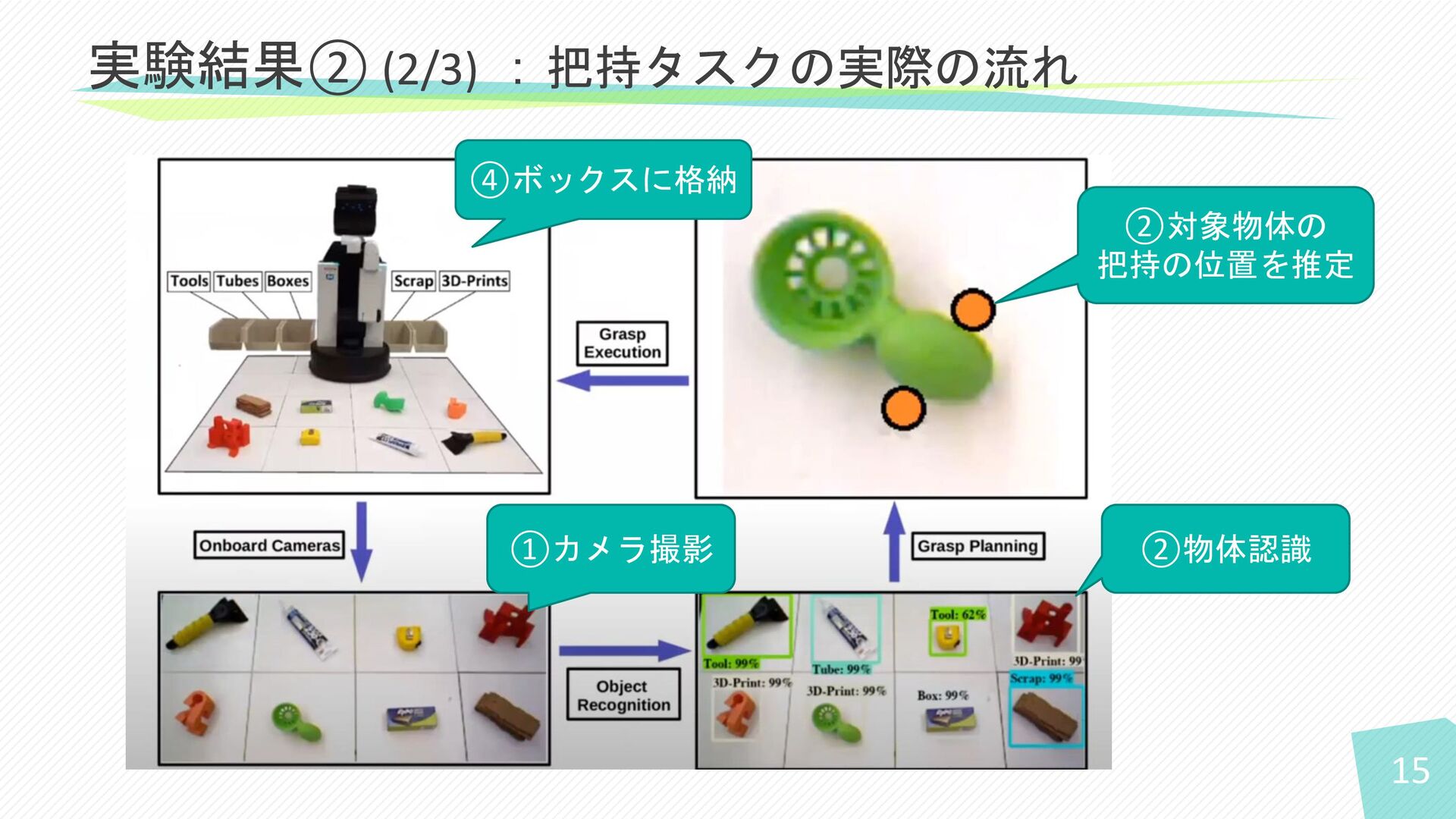
15 実験結果② (2/3) :把持タスクの実際の流れ ②物体認識 ②対象物体の 把持の位置を推定 ①カメラ撮影 ④ボックスに格納
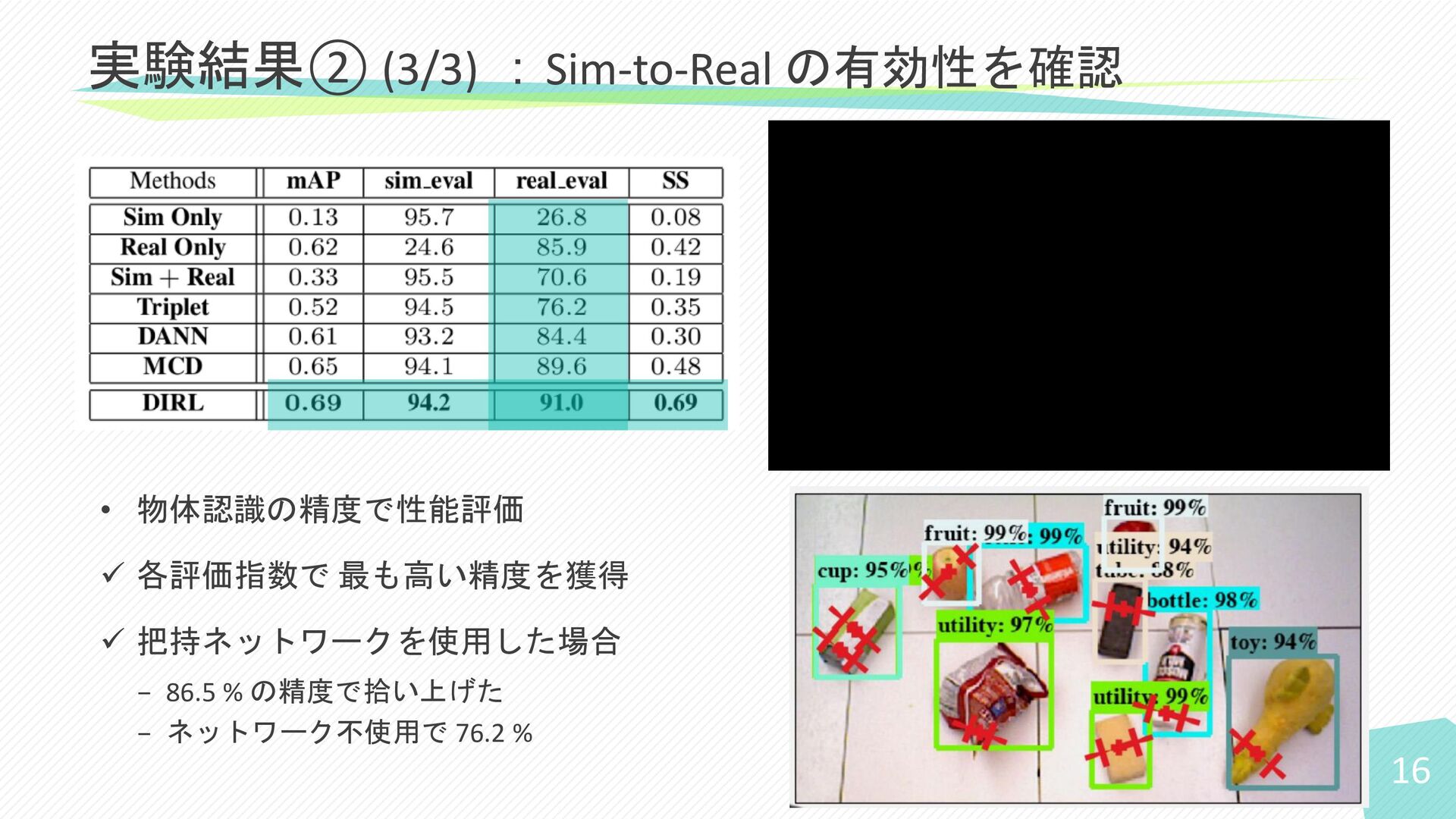
16 実験結果② (3/3) :Sim-to-Real の有効性を確認 • 物体認識の精度で性能評価 ✓ 各評価指数で 最も高い精度を獲得
✓ 把持ネットワークを使用した場合 − 86.5 % の精度で拾い上げた − ネットワーク不使用で 76.2 %
17 • ドメイン適応 ( Domain Adaptation )の新たなアルゴリズム DIRL (ドメイン不変表現学習, Domain-Invariant
Representation Learning ) の提案 まとめ ✓ 敵対的学習を含む4つの損失関数の導入 ✓ Sim-to-Real の把持タスクで高い精度を獲得
{kind=link}
{kind=link}
{kind=link}
![4 既存研究:様々なアプローチからのドメイン適応 既存手法 特徴 DANN [Ganin+, 2016] • 敵対的学習によるドメイン適応 •](https://files.speakerdeck.com/presentations/795a2b97c6c64296a0f209f1e0c4650e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 • Triplet Loss [Schroff+, CoRR2015] の変形を導入 − クラス間の分散を大きく・クラス内の分散を小さくさせる −](https://files.speakerdeck.com/presentations/795a2b97c6c64296a0f209f1e0c4650e/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}