Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Dynamic DETR: End-to-End Object ...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
Technology
340
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Dynamic DETR: End-to-End Object Detection with Dynamic Attention
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
130
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
310
kaonavi Tech Night#1
kaonavi
0
160
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
AI工学特論: MLOps・継続的評価
asei
4
1.1k
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
520
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
420
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
Featured
See All Featured
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
The Language of Interfaces
destraynor
162
27k
It's Worth the Effort
3n
188
29k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
Music & Morning Musume
bryan
47
7.3k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
GitHub's CSS Performance
jonrohan
1033
470k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Transcript
Dynamic DETR: End-to-End Object Detection with Dynamic Attention Xiyang Dai,
Yinpeng Chen, Jianwei Yang, Pengchuan Zhang, Lu Yuan, Lei Zhang Microsoft ICCV 2021 杉浦孔明研究室 神原 元就 Dai, X., Chen, Y., Yang, J., Zhang, P., Yuan, L., & Zhang, L. (2021). Dynamic detr: End-to-end object detection with dynamic attention. In ICCV (pp. 2988-2997).
背景:Detection Transformer (DETR [Carion+ ECCV20])の登場 3 The Power of PowerPoint
- thepopp.com • Transformerをエンコーダ-デコーダとして利用 (backbornはResNet) • (クラスラベル,位置,大きさ)の集合を予測 • 得られた集合について,𝑦𝑖 及びො 𝑦𝑖 を対応させるための2部マッチング損失を提案 • MS COCOにおいて,既存手法と同程度か上回る検出性能
背景:DETRには普及のため克服すべき問題点が存在 4 The Power of PowerPoint - thepopp.com ①:入力特徴量マップの解像度を上げることが難しい ②:訓練の収束まで,既存手法よりもエポック数を必要とする
• Encoderにおいて,Self-attentionの計算量はΟ(𝑑(𝐻𝑊)2) 特徴量マップを大きくすると計算量が爆発的に増加 • このために小さい物体の検出性能が比較的低い query key query key Decoderにおいて,attention の重み(HW × 𝑁個)は 密→疎 と訓練されていく
関連研究:DETRの派生形 5 The Power of PowerPoint - thepopp.com DETRの課題を克服 DETRをベースに発展
• Up-DETR [Dai+ CVPR21] • Deformable DETR [Zhu+ ICLR21] • Spatially Modulated Co-Attention [Gao+ ICCV21] • Conditional DETR [Meng+ ICCV21] • MDETR [Kamath+ ICCV21] • Mete-DETR [Zhang+ 21] • DA-DETR [Zhang+ 21] [Dai+ CVPR21] [Kamath+ ICCV21]
関連研究:Deformable DETR [Zhu+ ICLR21] 6 The Power of PowerPoint -
thepopp.com DETRにおける2つの課題を解決するため, • Feature Pyramid + Deformable convolution [Dai+ ICCV17]を基とし た,Deformable attentionを導入 • 推論結果から,オフセットを用い てbboxの座標を予測 DETRと比べ1.6倍のFLOPs,数倍早く収 束,各指標で高い性能
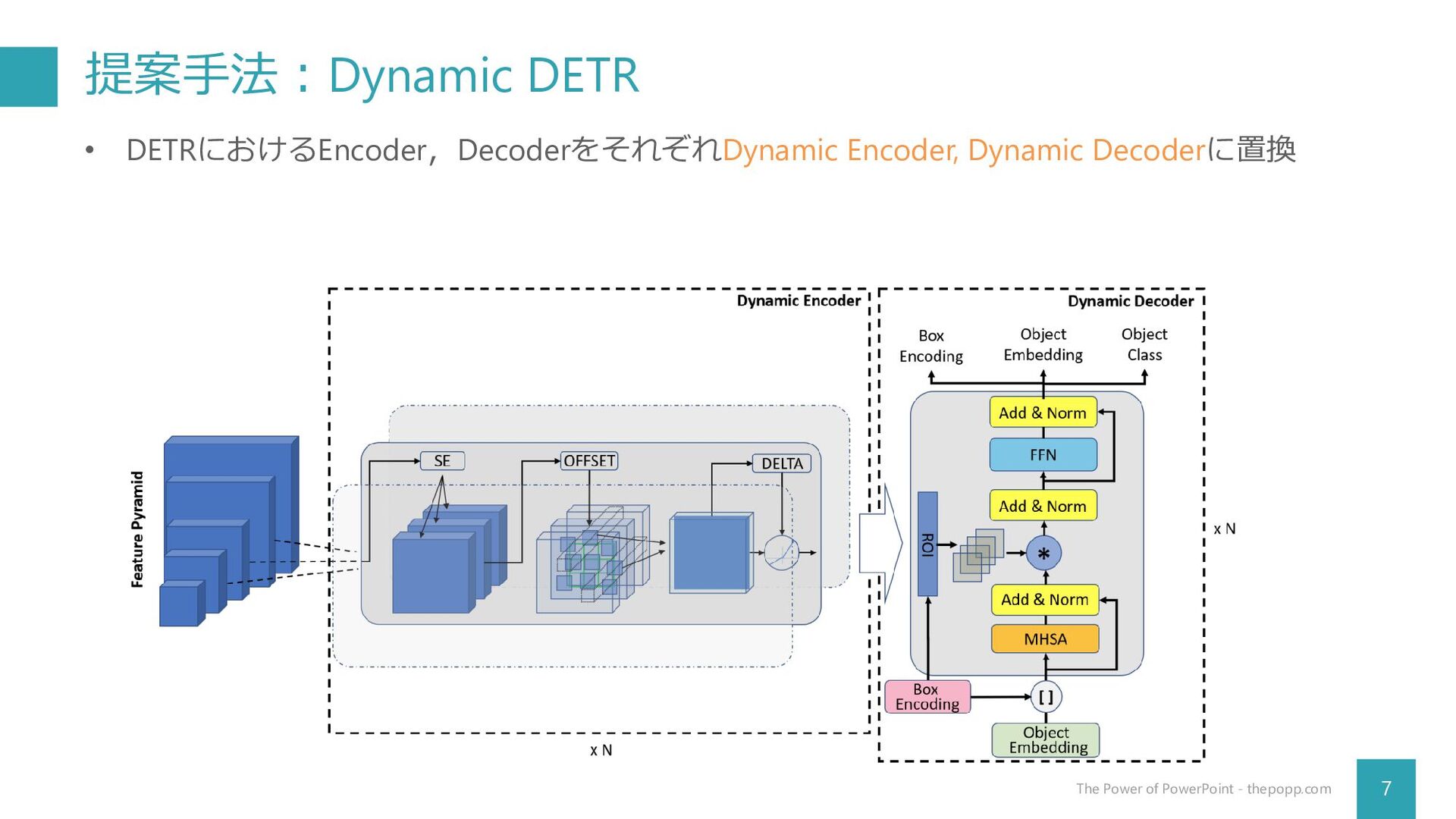
提案手法:Dynamic DETR 7 The Power of PowerPoint - thepopp.com •
DETRにおけるEncoder,DecoderをそれぞれDynamic Encoder, Dynamic Decoderに置換
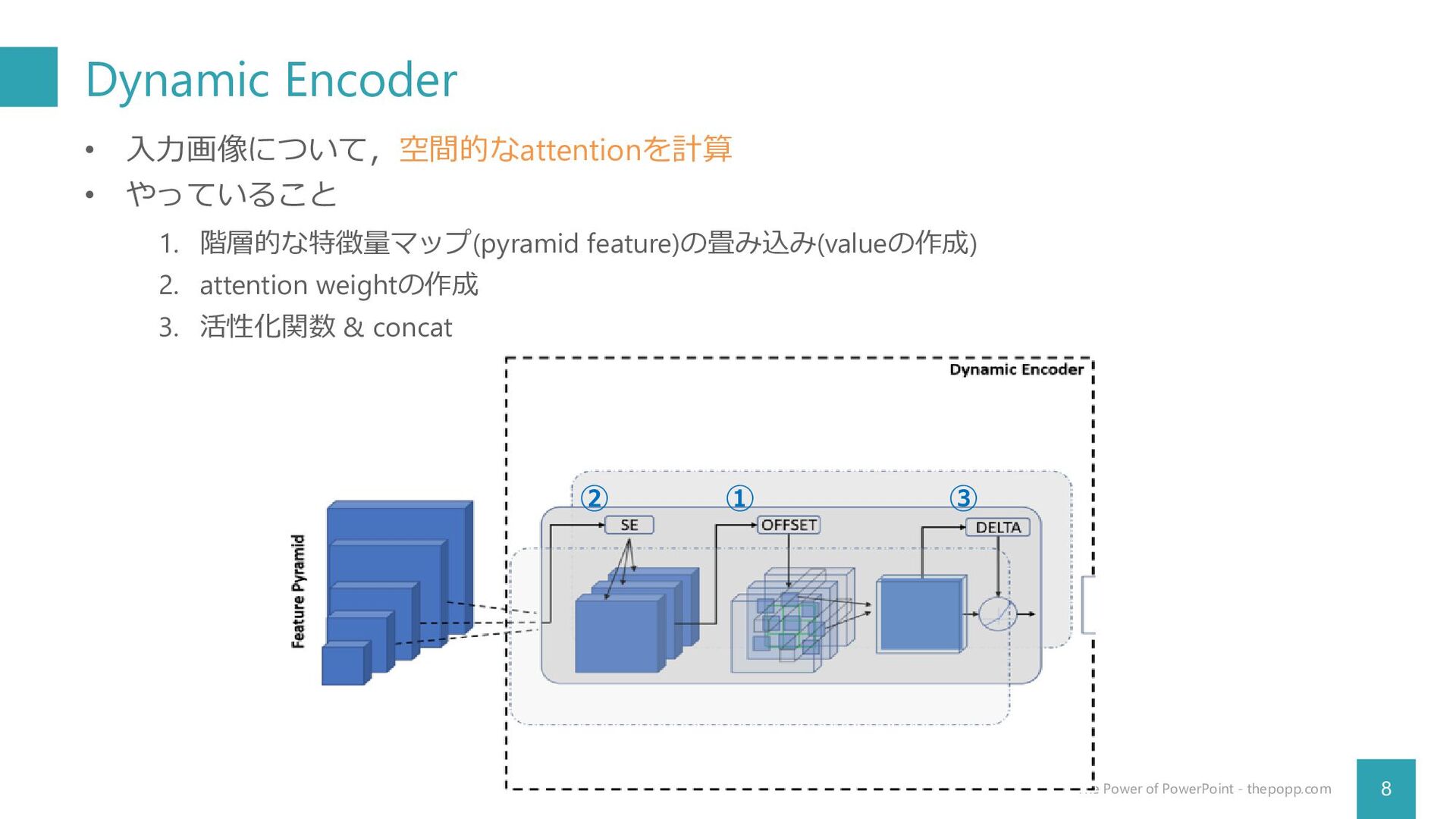
Dynamic Encoder 8 The Power of PowerPoint - thepopp.com •
入力画像について,空間的なattentionを計算 • やっていること ① ② ③ 1. 階層的な特徴量マップ(pyramid feature)の畳み込み(valueの作成) 2. attention weightの作成 3. 活性化関数 & concat
Dynamic Encoder: Pyramid Convolution [Wang+ CVPR20] 9 The Power of
PowerPoint - thepopp.com 𝑃𝑙+1 𝑃𝑙 𝑃𝑙−1 𝑃1 ... • 𝑃′𝑙 = Upsample Conv 𝑃𝑙−1 + Conv 𝑃𝑙 + Downsample(Conv(𝑃𝑙+1 )) • 異なる解像度の画像を畳み込むことにより,様々な粒度での特徴量を獲得 空間的な注意の獲得はカーネルサイズに依存 𝑃′𝑙
Dynamic Encoder: Deformable Convolution [Dai+ ICCV17] 10 The Power of
PowerPoint - thepopp.com • Deformable convolutionにより,空間的な注意を獲得 𝑦 𝑝0 = 𝑝𝑛∈𝑅 𝑤(𝑝𝑛 ) ∙ 𝑥(𝑝0 + 𝑝𝑛 + ∆𝑝𝑛 ) 𝑅 = { −1, −1 , −1, 0 , … , 0, 1 , 1, 1 } (3×3のカーネルの場合) オフセット どのピクセルを用いるかを学習 • 𝑃𝑙 + = Upsample DeformConv 𝑃𝑙−1 + DeformConv 𝑃𝑙 + Downsample(DeformConv(𝑃𝑙+1 ) オフセットは同一
Dynamic Encoder: Squeeze and Excitation[Hu+ CVPR18] 11 The Power of
PowerPoint - thepopp.com • 𝑃𝑙 +についてのAttention weightにSqueeze and Excitationモジュールを利用 • チャネル間の相互関係をモデリング • 具体的な手順 ① ② ③ 1. 画像全体の画素平均を取り,各チャネルを単一の値に変換 2. 非線形変換による重みの獲得 sigmoid(𝑾𝑑 ReLU(𝑾𝑒 𝒉)) 3. 重みを各チャネルにかけ合わせる 一度チャネル数を1/r倍する ことで複雑性を抑える Attention weight𝒘𝑃𝑙を獲得
Dynamic Encoder:Dynamic ReLU [Chen+ ECCV20] 12 The Power of PowerPoint
- thepopp.com Multi-scale attention𝒉𝑚𝑠𝑎 は以下で得られる 𝒉𝑚𝑠𝑎 = {DyReLU 𝒘𝑃1𝑷1 + ; … ; DyReLU 𝒘𝑃𝑘𝑷𝑘 + } Dynamic ReLU DyReLU 𝑥𝑐 = max(𝑎𝑐 (1)𝑥𝑐 + 𝑏𝑐 (1), 𝑎𝑐 (2)𝑥𝑐 + 𝑏𝑐 (2)) • ReLUの一般化 • Squeeze and Excitationと同様の処理を行い, [𝑎 1 (1), … , 𝑎𝐶 1 , 𝑎1 2 , … , 𝑎𝐶 2 , 𝑎 1 (1), … , 𝑏𝐶 1 , 𝑏1 2 , … , 𝑏𝐶 2 ]を求める ReLUにおいて,チャネル間の相互関係を考慮した 重みづけを導入
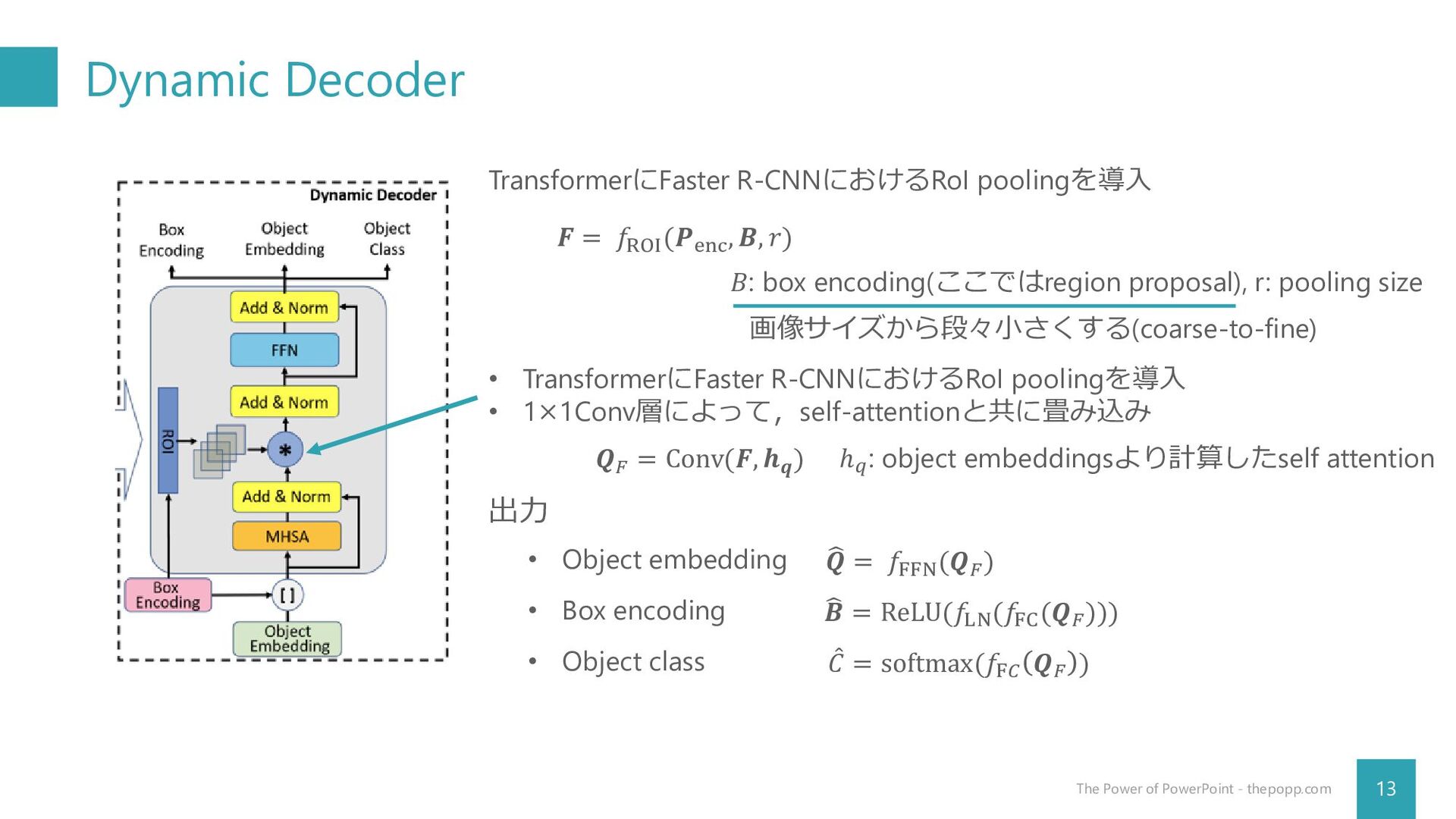
Dynamic Decoder 13 The Power of PowerPoint - thepopp.com TransformerにFaster
R-CNNにおけるRoI poolingを導入 𝑭 = 𝑓ROI (𝑷enc , 𝑩, 𝑟) 𝐵: box encoding(ここではregion proposal), r: pooling size • TransformerにFaster R-CNNにおけるRoI poolingを導入 • 1×1Conv層によって,self-attentionと共に畳み込み 出力 • Object embedding • Box encoding • Object class 𝑸𝐹 = Conv(𝑭, 𝒉𝒒 ) ℎ𝑞: object embeddingsより計算したself attention 𝑸 = 𝑓FFN (𝑸𝐹 ) 𝑩 = ReLU(𝑓LN (𝑓FC (𝑸𝐹 ))) መ 𝐶 = softmax(𝑓F𝐶 𝑸𝐹 ) 画像サイズから段々小さくする(coarse-to-fine)
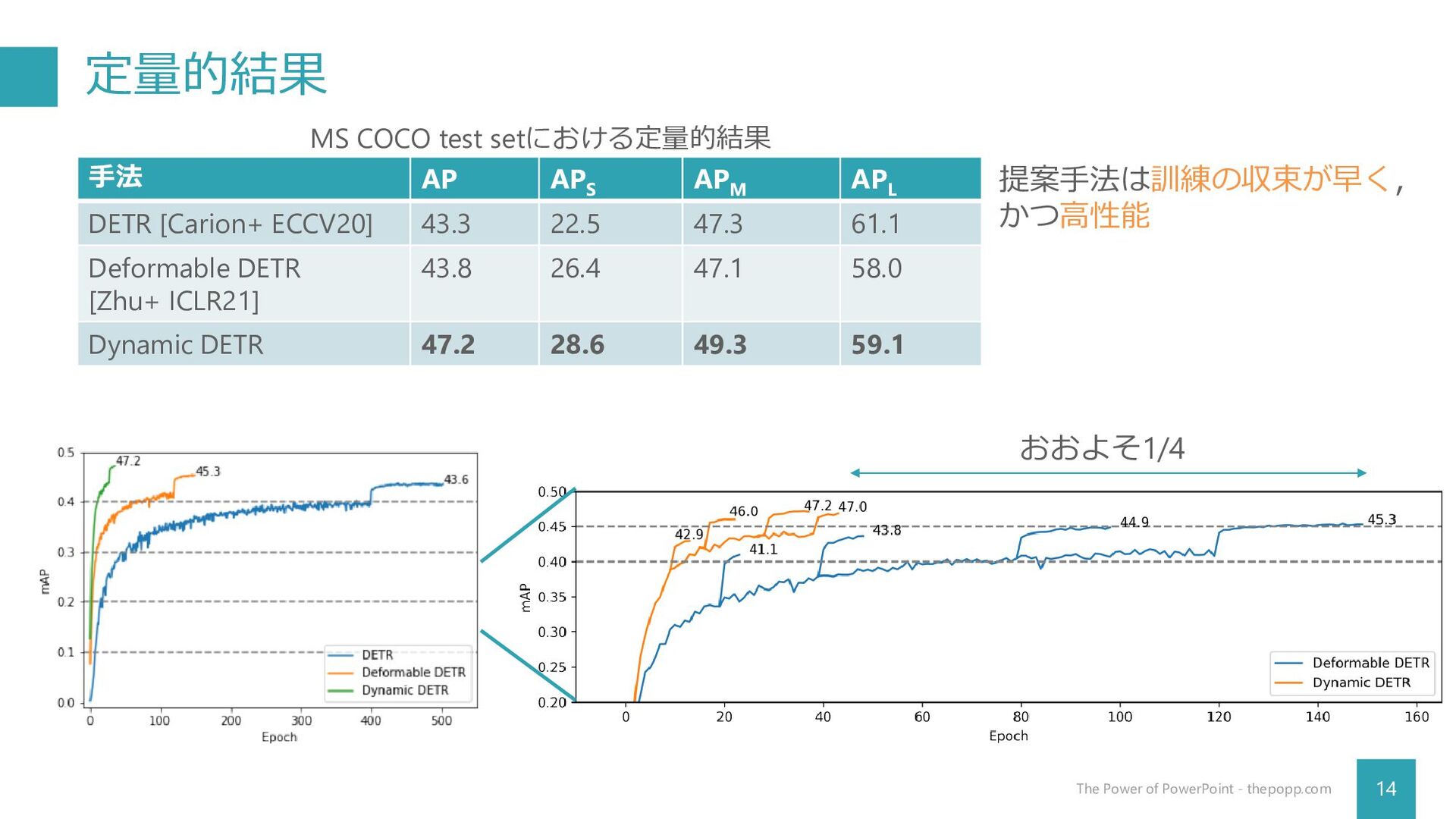
定量的結果 14 The Power of PowerPoint - thepopp.com 手法 AP
APS APM APL DETR [Carion+ ECCV20] 43.3 22.5 47.3 61.1 Deformable DETR [Zhu+ ICLR21] 43.8 26.4 47.1 58.0 Dynamic DETR 47.2 28.6 49.3 59.1 MS COCO test setにおける定量的結果 提案手法は訓練の収束が早く, かつ高性能 おおよそ1/4
定性的結果 15 The Power of PowerPoint - thepopp.com 候補全てを囲む より絞って囲む
• Dynamic decoderにおいて,疎→密(coarse-to-fine)というcross-attentionの 獲得ができている
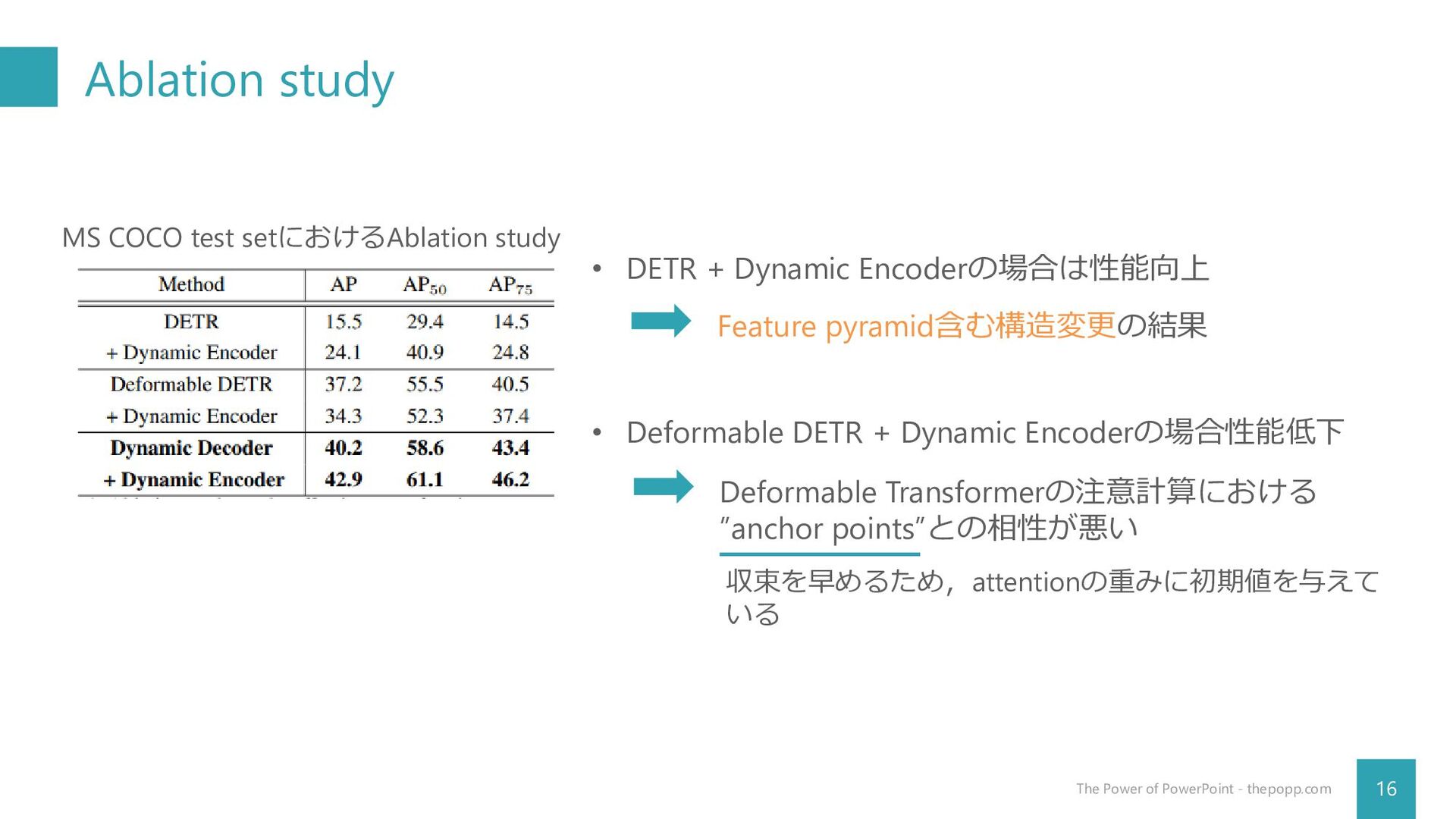
Ablation study 16 The Power of PowerPoint - thepopp.com MS
COCO test setにおけるAblation study • DETR + Dynamic Encoderの場合は性能向上 • Deformable DETR + Dynamic Encoderの場合性能低下 Feature pyramid含む構造変更の結果 Deformable Transformerの注意計算における ”anchor points”との相性が悪い 収束を早めるため,attentionの重みに初期値を与えて いる
まとめ 17 The Power of PowerPoint - thepopp.com • DETRには計算量が膨大,収束まで多くのエポック数を必要とする,という課題
• Dynamic attention機構を導入した物体検出モデル,Dynamic DETRを提案 • 計算量を減らし,収束までのエポック数も減らしつつ既存手法を超える検出性能
{kind=link}
![背景:Detection Transformer (DETR [Carion+ ECCV20])の登場 3 The Power of PowerPoint](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
![関連研究:Deformable DETR [Zhu+ ICLR21] 6 The Power of PowerPoint -](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![Dynamic Encoder: Pyramid Convolution [Wang+ CVPR20] 9 The Power of](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_7.jpg){kind=link}
![Dynamic Encoder: Deformable Convolution [Dai+ ICCV17] 10 The Power of](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_8.jpg){kind=link}
![Dynamic Encoder: Squeeze and Excitation[Hu+ CVPR18] 11 The Power of](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_9.jpg){kind=link}
![Dynamic Encoder:Dynamic ReLU [Chen+ ECCV20] 12 The Power of PowerPoint](https://files.speakerdeck.com/presentations/581157a2acdc430dbf23f35a8a91df2e/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}