Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Flow as the Cross-Domain Manipul...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 09, 2026
Technology
96
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Flow as the Cross-Domain Manipulation Interface
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 09, 2026
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
71
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
77
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
[Journal club] Improved Mean Flows: On the Challenges of Fastforward Generative Models
keio_smilab
PRO
0
200
Other Decks in Technology
See All in Technology
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
300
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
160
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
270
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.9k
公式ドキュメントの歩き方etc
coco_se
0
110
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.5k
SRE Lounge Hiroshimaへの招待
grimoh
0
670
Kaggleで成長するために意識したこと
prgckwb
2
370
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
750
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
220
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
250
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
9
3.7k
Featured
See All Featured
Embracing the Ebb and Flow
colly
88
5.1k
The Limits of Empathy - UXLibs8
cassininazir
1
470
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Designing for humans not robots
tammielis
254
26k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
270
Skip the Path - Find Your Career Trail
mkilby
1
170
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Navigating Team Friction
lara
192
16k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Transcript
Mengda Xu1,2,3 Zhenjia Xu1,2 Yinghao Xu1 Cheng Chi1,2 Gordon Wetzstein1
Manuela Veloso3,4 Shuran Song1,2 1Stanford University, 2Columbia University, 3J.P. Morgan AI Research, 4Carnegie Mellon University Flow as the Cross-Domain Manipulation Interface 2026 杉浦孔明研究室 小林菖太 Xu, Mengda., Xu, Zhenjia., Xu, Yinghao., Chi, Cheng., Wetzstein, Gordon., Veloso, Manuela., Song, Shuran. “Flow as the Cross-domain Manipulation Interface”. In 8th Conference of Robot Learning, 2024. CoRL24
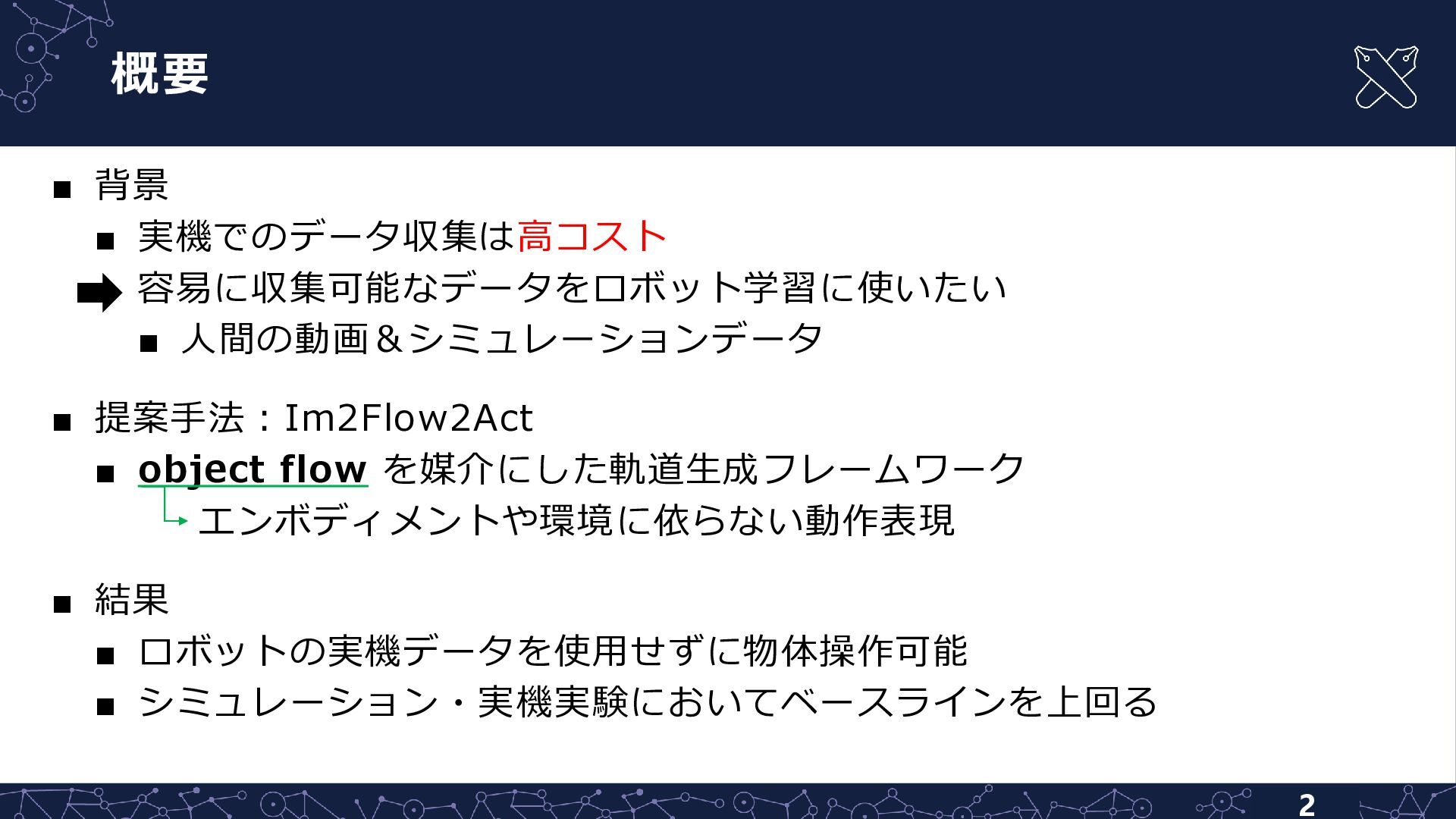
概要 2 ▪ 背景 ▪ 実機でのデータ収集は高コスト 容易に収集可能なデータをロボット学習に使いたい ▪ 人間の動画&シミュレーションデータ ▪
提案手法:Im2Flow2Act ▪ object flow を媒介にした軌道生成フレームワーク エンボディメントや環境に依らない動作表現 ▪ 結果 ▪ ロボットの実機データを使用せずに物体操作可能 ▪ シミュレーション・実機実験においてベースラインを上回る
背景:エンボディメントや環境に依らない動作表現の必要性 3 ロボットの実機データの収集は高コスト 実機環境に合わせたシミュレータ環境の構築は高コスト 収集コストの低いデータを用いたい ◼ 人間動画
human-robot のエンボディメントギャップ ◼ シミュレータの単一環境における軌道データ sim-real のドメインギャップ (背景, 物体テクスチャ, etc...) エンボディメントや環境に依らない動作表現の必要性
関連研究: cross-domain data からのロボット学習 4 手法 特徴 VRB [Bahl+, CVPR23]
人間動画から物体の把持点と軌道を学習 PEAC [Ying+, NeurIPS24] Cross-embodiment data から latent action を学習 ATM [Wen+, RSS24] 人間動画から hand-centric なフローを学習 実機適用時に target embodiment でのデータ収集が必要 VRB [Bahl+, CVPR23] ATM [Wen+, RSS24]
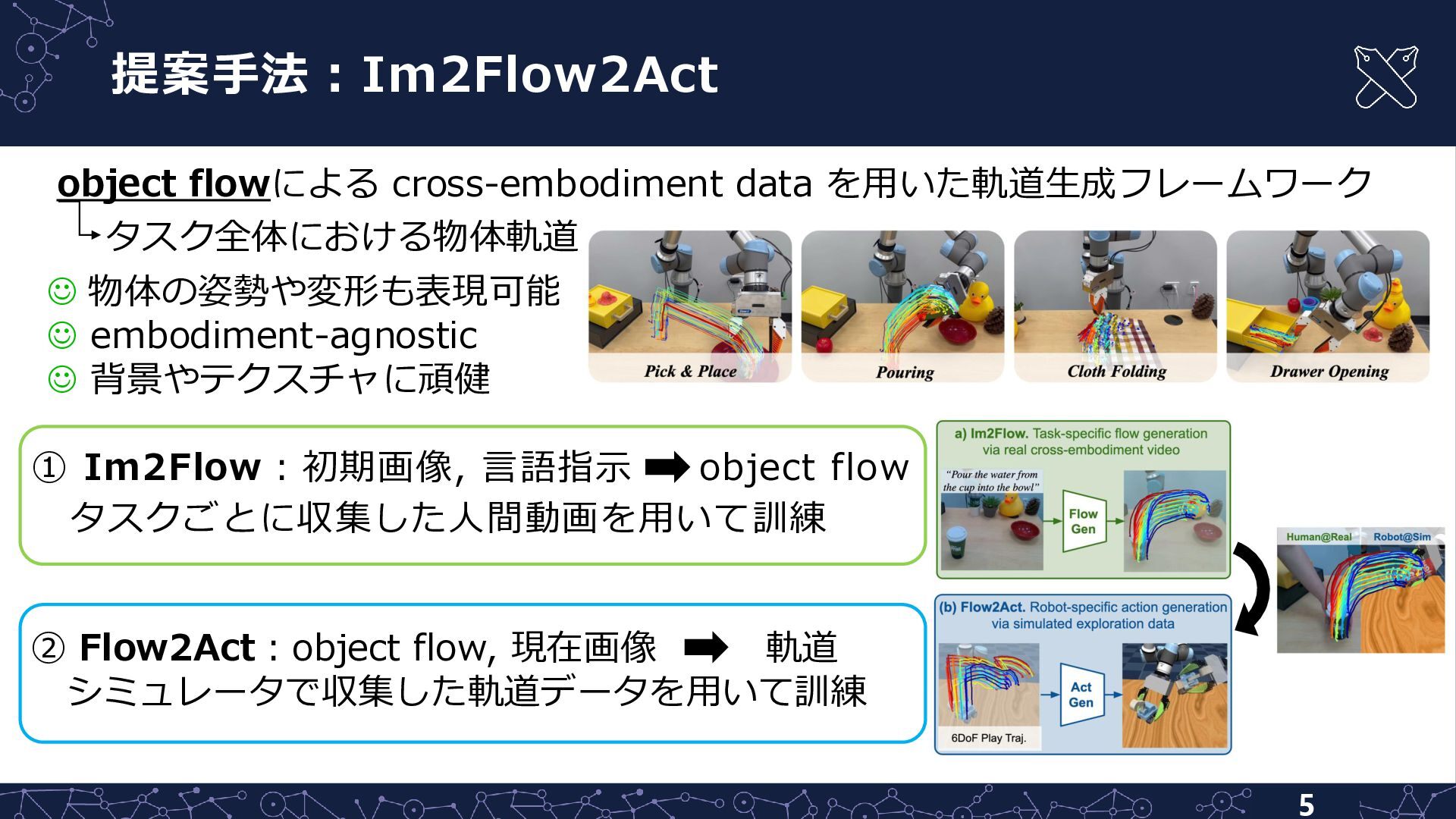
提案手法:Im2Flow2Act 5 ① Im2Flow:初期画像, 言語指示 object flow タスクごとに収集した人間動画を用いて訓練 object flowによる
cross-embodiment data を用いた軌道生成フレームワーク ☺ 物体の姿勢や変形も表現可能 ☺ embodiment-agnostic ☺ 背景やテクスチャに頑健 ② Flow2Act:object flow, 現在画像 軌道 シミュレータで収集した軌道データを用いて訓練 タスク全体における物体軌道
前提:LDM (Latent Diffusion Model), AnimateDiff 6 事前学習済みT2I拡散モデル (SD) に motion
module を導入して動画を生成 ◼ Temporal Transformer ☺ 時間方向の一貫性を向上 ◼ T2Iモデルを freeze して学習を行う ☺ 低コストな訓練 AnimateDiff [Guo+, ICLR24] LDM [Rombach+, CVPR22] 生成空間を低次元な潜在空間にするこ とで高品質な画像を高速に生成可能 ◼ cross-attention ☺ 柔軟な条件入力 (text, bbox, etc...) ◼ 計算量を削減 ☺ 高効率な訓練 ☺ 高速な推論 ◼ Stable Diffusion を使用 LDM [Rombach+, CVPR22] AnimateDiff [Guo+, ICLR24]
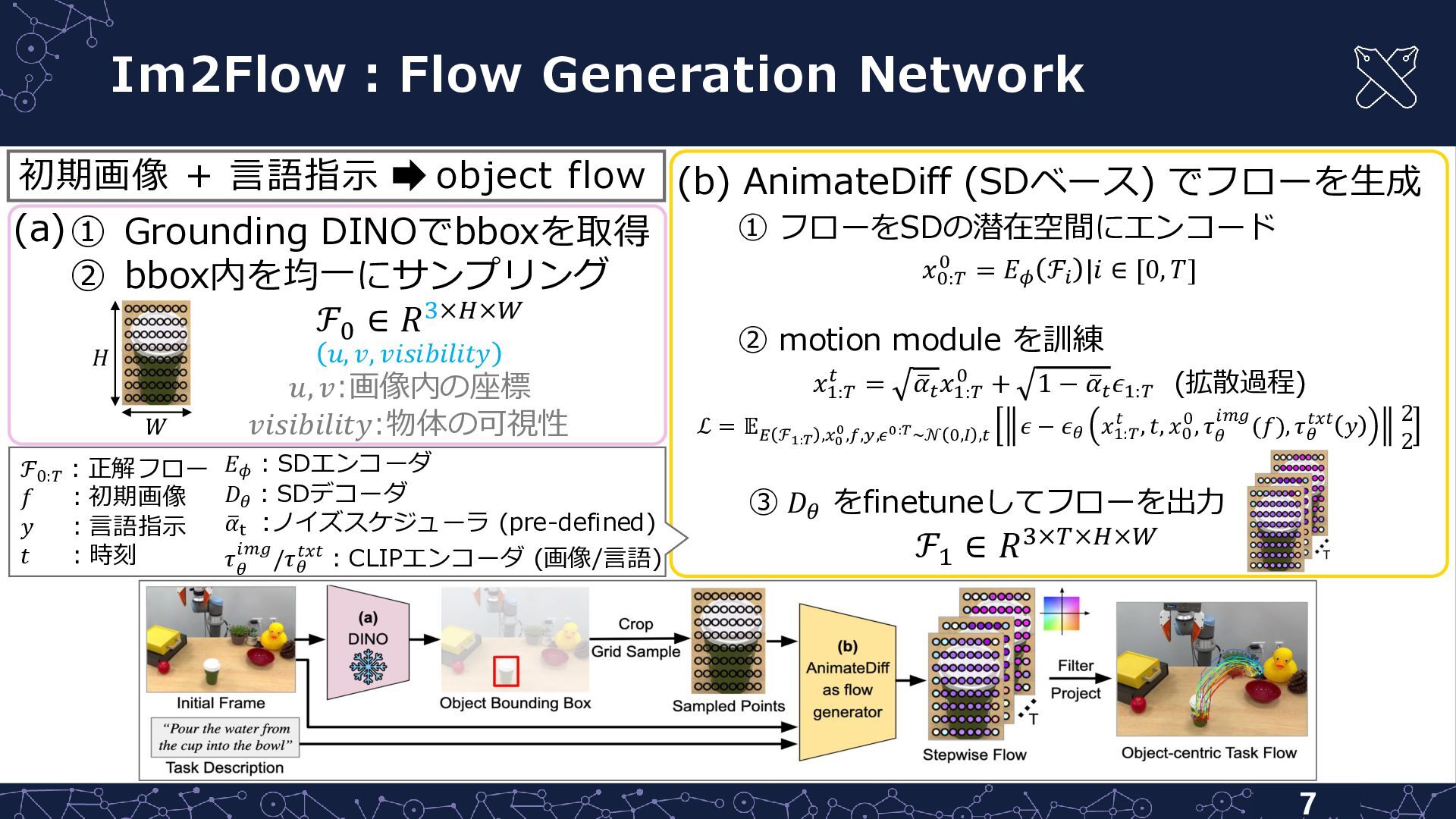
(b) AnimateDiff (SDベース) でフローを生成 ① フローをSDの潜在空間にエンコード 𝑥0:𝑇 0 = 𝐸𝜙
ℱ𝑖 |𝑖 ∈ [0, 𝑇] ② motion module を訓練 𝑥1:𝑇 𝑡 = ത 𝛼𝑡 𝑥1:𝑇 0 + 1 − ത 𝛼𝑡 𝜖1:𝑇 (拡散過程) ℒ = 𝔼 𝐸 ℱ1:𝑇 ,𝑥0 0,𝑓,𝑦,𝜖0:𝑇~𝒩 0,𝐼 ,𝑡 𝜖 − 𝜖𝜃 𝑥1:𝑇 𝑡 , 𝑡, 𝑥0 0, 𝜏 𝜃 𝑖𝑚𝑔(𝑓), 𝜏𝜃 𝑡𝑥𝑡 𝑦 2 2 ③ 𝐷𝜃 をfinetuneしてフローを出力 Im2Flow:Flow Generation Network 7 初期画像 + 言語指示 object flow ① Grounding DINOでbboxを取得 ② bbox内を均一にサンプリング ℱ0 ∈ 𝑅3×𝐻×𝑊 𝑢, 𝑣, 𝑣𝑖𝑠𝑖𝑏𝑖𝑙𝑖𝑡𝑦 𝑢, 𝑣:画像内の座標 𝑣𝑖𝑠𝑖𝑏𝑖𝑙𝑖𝑡𝑦:物体の可視性 (a) 𝐻 𝑊 ℱ1 ∈ 𝑅3×𝑇×𝐻×𝑊 ℱ0:𝑇 :正解フロー 𝑓 :初期画像 𝑦 :言語指示 𝑡 :時刻 𝐸𝜙 :SDエンコーダ 𝐷𝜃 :SDデコーダ ത 𝛼t :ノイズスケジューラ (pre-defined) 𝜏 𝜃 𝑖𝑚𝑔/𝜏𝜃 𝑡𝑥𝑡:CLIPエンコーダ (画像/言語)
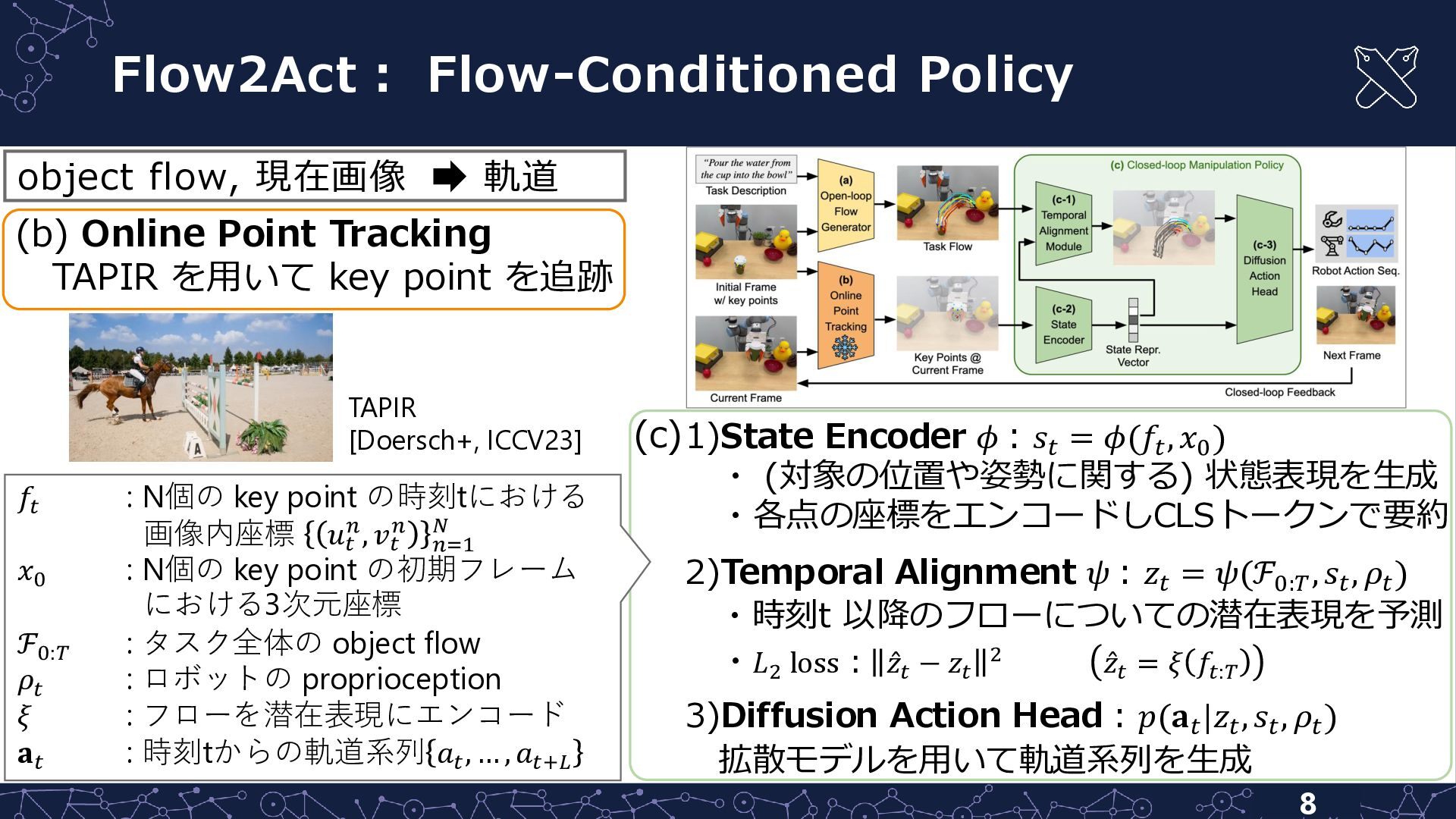
(c) 1)State Encoder 𝜙 : 𝑠𝑡 = 𝜙(𝑓𝑡 , 𝑥0
) ・ (対象の位置や姿勢に関する) 状態表現を生成 ・各点の座標をエンコードしCLSトークンで要約 2)Temporal Alignment 𝜓 : 𝑧𝑡 = 𝜓(ℱ0:𝑇 , 𝑠𝑡 , 𝜌𝑡 ) ・時刻t 以降のフローについての潜在表現を予測 ・𝐿2 loss: Ƹ 𝑧𝑡 − 𝑧𝑡 2 Ƹ 𝑧𝑡 = 𝜉 𝑓𝑡:𝑇 3)Diffusion Action Head : 𝑝(𝐚𝑡 |𝑧𝑡 , 𝑠𝑡 , 𝜌𝑡 ) 拡散モデルを用いて軌道系列を生成 Flow2Act: Flow-Conditioned Policy 8 𝑓𝑡 : N個の key point の時刻tにおける 画像内座標 𝑢𝑡 𝑛, 𝑣𝑡 𝑛 𝑛=1 𝑁 𝑥0 : N個の key point の初期フレーム における3次元座標 ℱ0:𝑇 : タスク全体の object flow 𝜌𝑡 : ロボットの proprioception 𝜉 : フローを潜在表現にエンコード 𝐚𝑡 : 時刻tからの軌道系列 𝑎𝑡 , … , 𝑎𝑡+𝐿 (b) Online Point Tracking TAPIR を用いて key point を追跡 TAPIR [Doersch+, ICCV23] object flow, 現在画像 軌道
実験設定 9 ◼ 4つのタスクで評価 ◼ Pick-and-place ◼ Pouring ◼ Open
drawer ◼ Folding cloth ◼ 学習設定 ◼ object flow: ◼ H=W=32 ◼ T=32 ◼ 学習時間:記載なし ◼ ロボット:UR5e ℱ1 ∈ 𝑅3×𝑇×𝐻×𝑊 ◼ 訓練データ ◼ 人間動画 ◼ 人間による各タスクのデモ ◼ データ数: 記載なし ◼ シミュレータ:MuJoCo ◼ ロボット:UR5e ◼ データ数: 4800
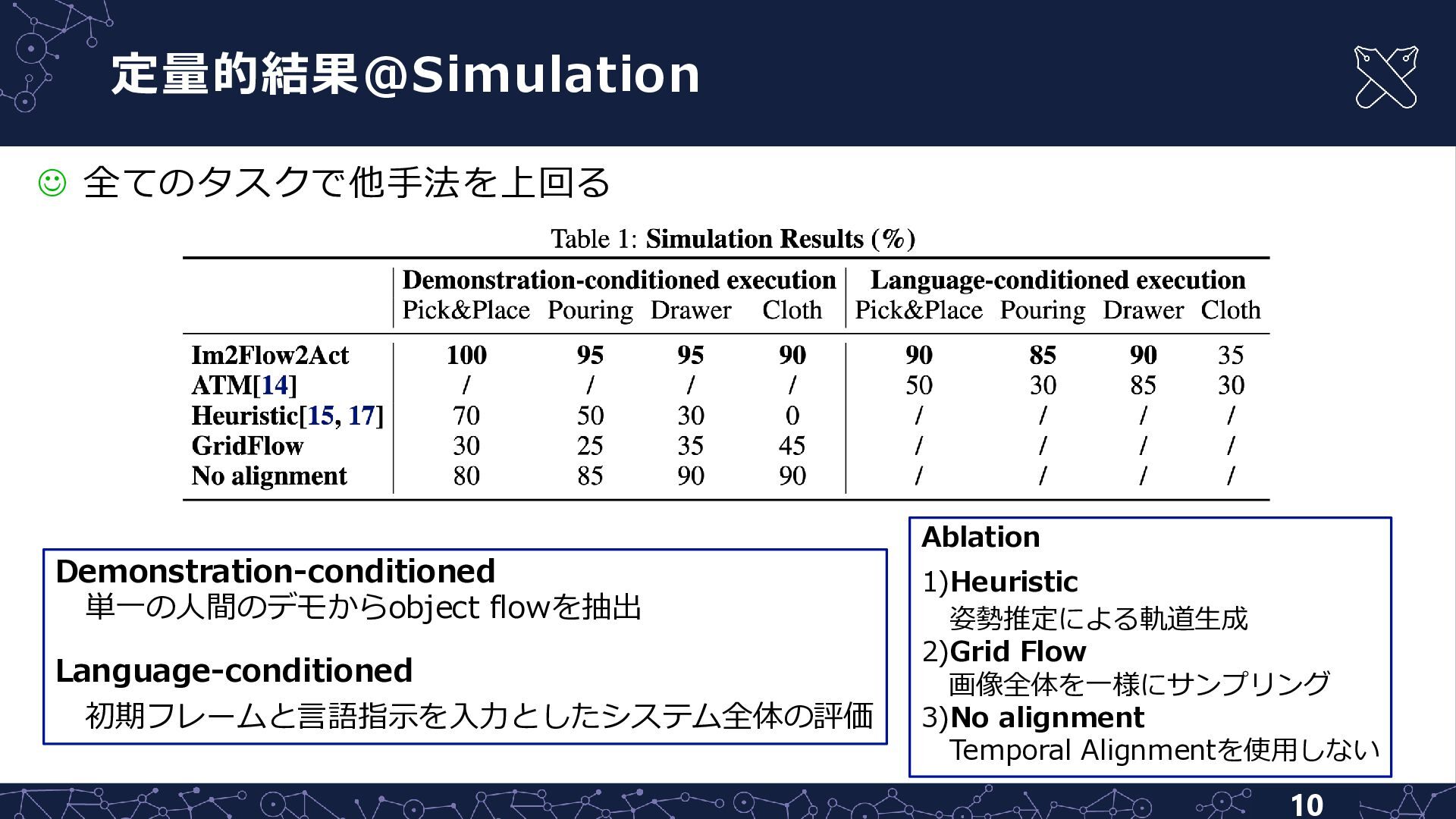
定量的結果@Simulation 10 ☺ 全てのタスクで他手法を上回る Demonstration-conditioned 単一の人間のデモからobject flowを抽出 Language-conditioned 初期フレームと言語指示を入力としたシステム全体の評価 Ablation
1)Heuristic 姿勢推定による軌道生成 2)Grid Flow 画像全体を一様にサンプリング 3)No alignment Temporal Alignmentを使用しない
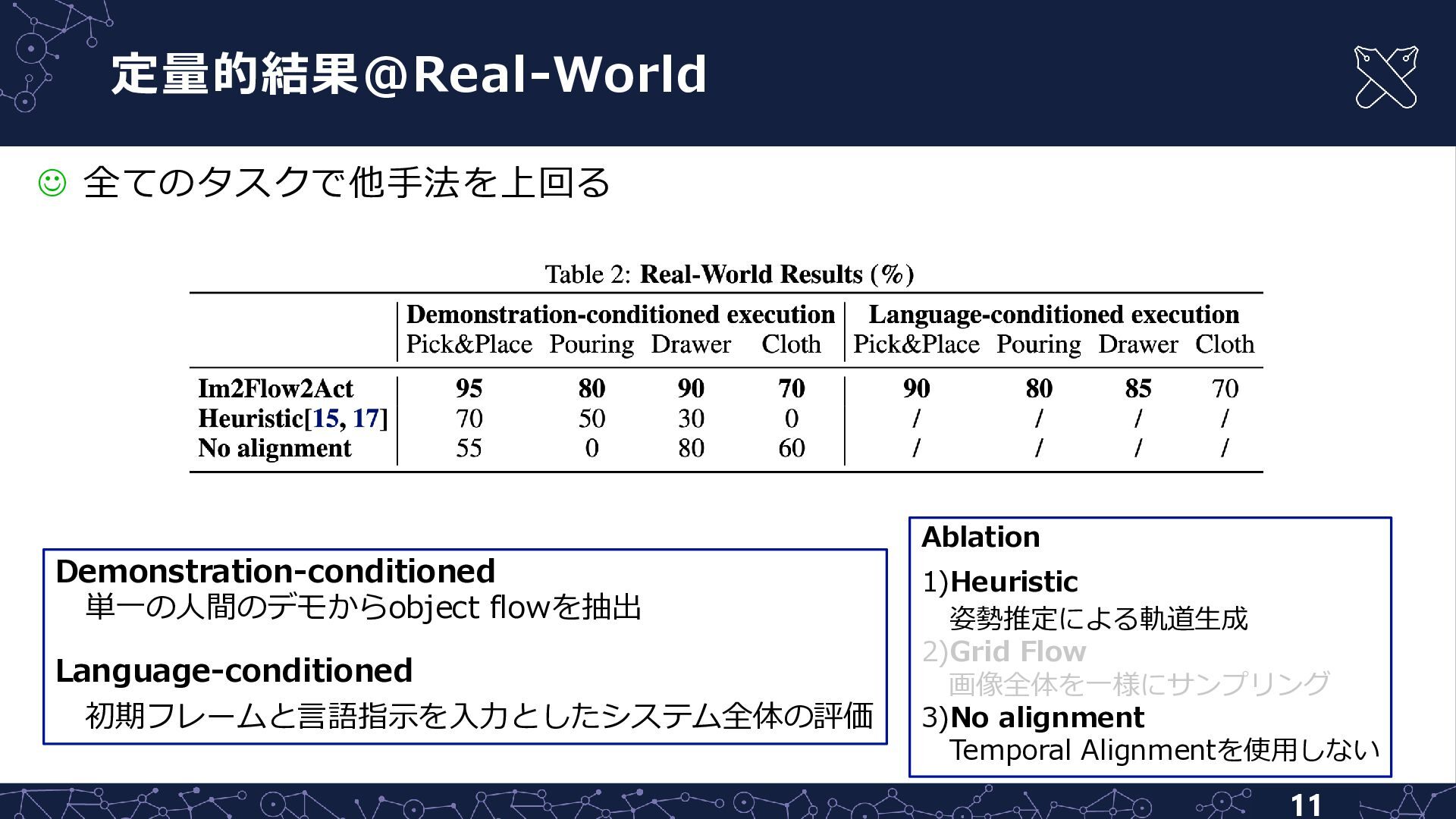
定量的結果@Real-World 11 ☺ 全てのタスクで他手法を上回る Demonstration-conditioned 単一の人間のデモからobject flowを抽出 Language-conditioned 初期フレームと言語指示を入力としたシステム全体の評価 Ablation
1)Heuristic 姿勢推定による軌道生成 2)Grid Flow 画像全体を一様にサンプリング 3)No alignment Temporal Alignmentを使用しない
定性的結果 12 ☺ object flow が物体の軌道を適切に表現
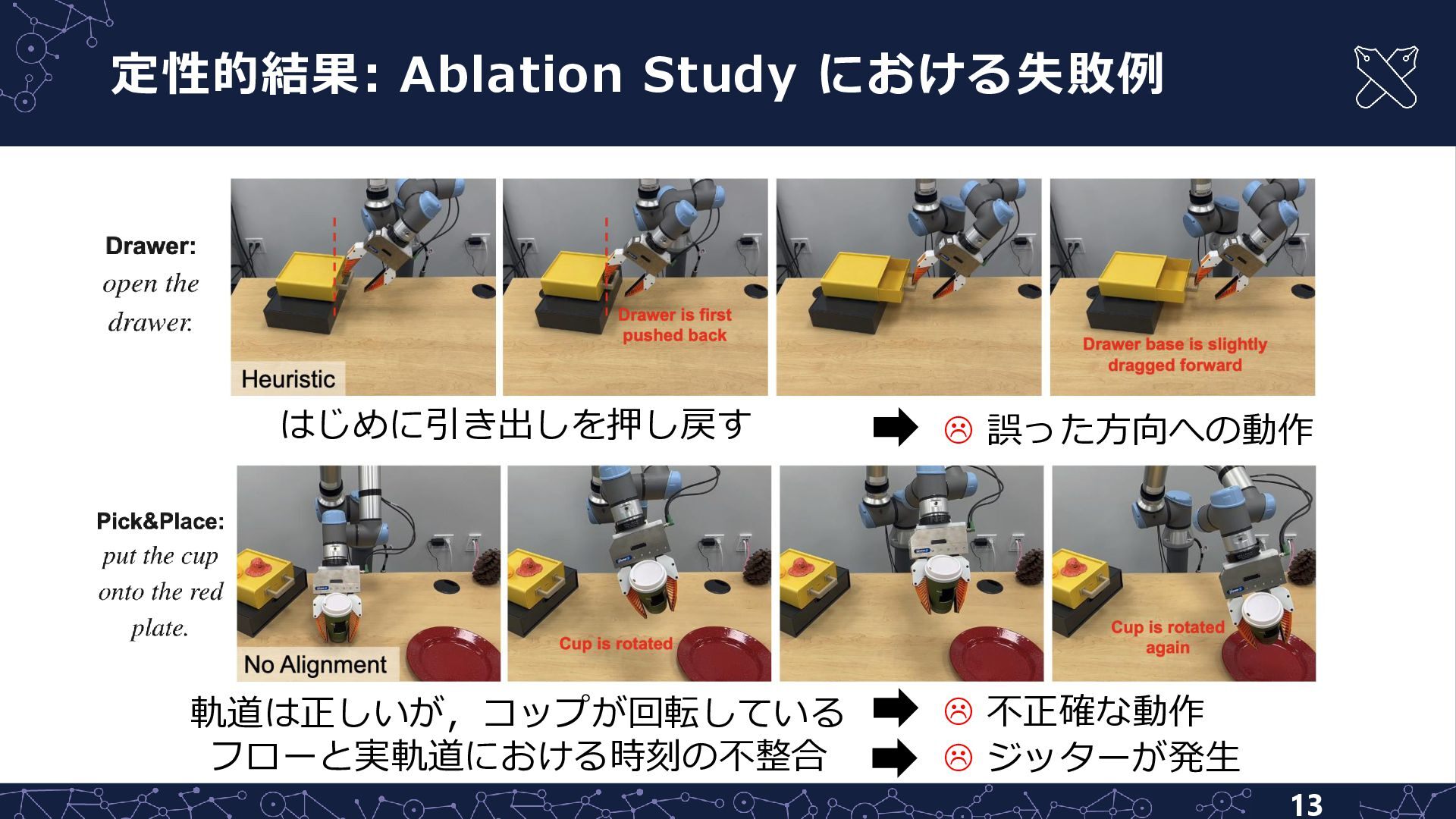
定性的結果: Ablation Study における失敗例 13 はじめに引き出しを押し戻す 軌道は正しいが,コップが回転している フローと実軌道における時刻の不整合 不正確な動作
誤った方向への動作 ジッターが発生
まとめ 14 ▪ 背景 ▪ 実機でのデータ収集は高コスト 容易に収集可能なデータをロボット学習に使いたい ▪ 人間の動画&シミュレーションデータ ▪
提案手法:Im2Flow2Act ▪ object flow を媒介にした軌道生成フレームワーク エンボディメントや環境に依らない動作表現 ▪ 結果 ▪ ロボットの実機データを使用せずに物体操作可能 ▪ シミュレーション・実機実験においてベースラインを上回る
{kind=link}
{kind=link}
{kind=link}
![関連研究: cross-domain data からのロボット学習 4 手法 特徴 VRB [Bahl+, CVPR23]](https://files.speakerdeck.com/presentations/6aa886495d5e41a8b481c2f11d327455/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}