Yan Chang1 1NVIDIA, 2University of Southern California, 3University of Texas at Austin ICRA 2025 慶應義塾大学 杉浦孔明研究室 B4 高科明哲 ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation Abrar Anwar, et al. ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation. ICRA 2025. pp. 2838-2845.
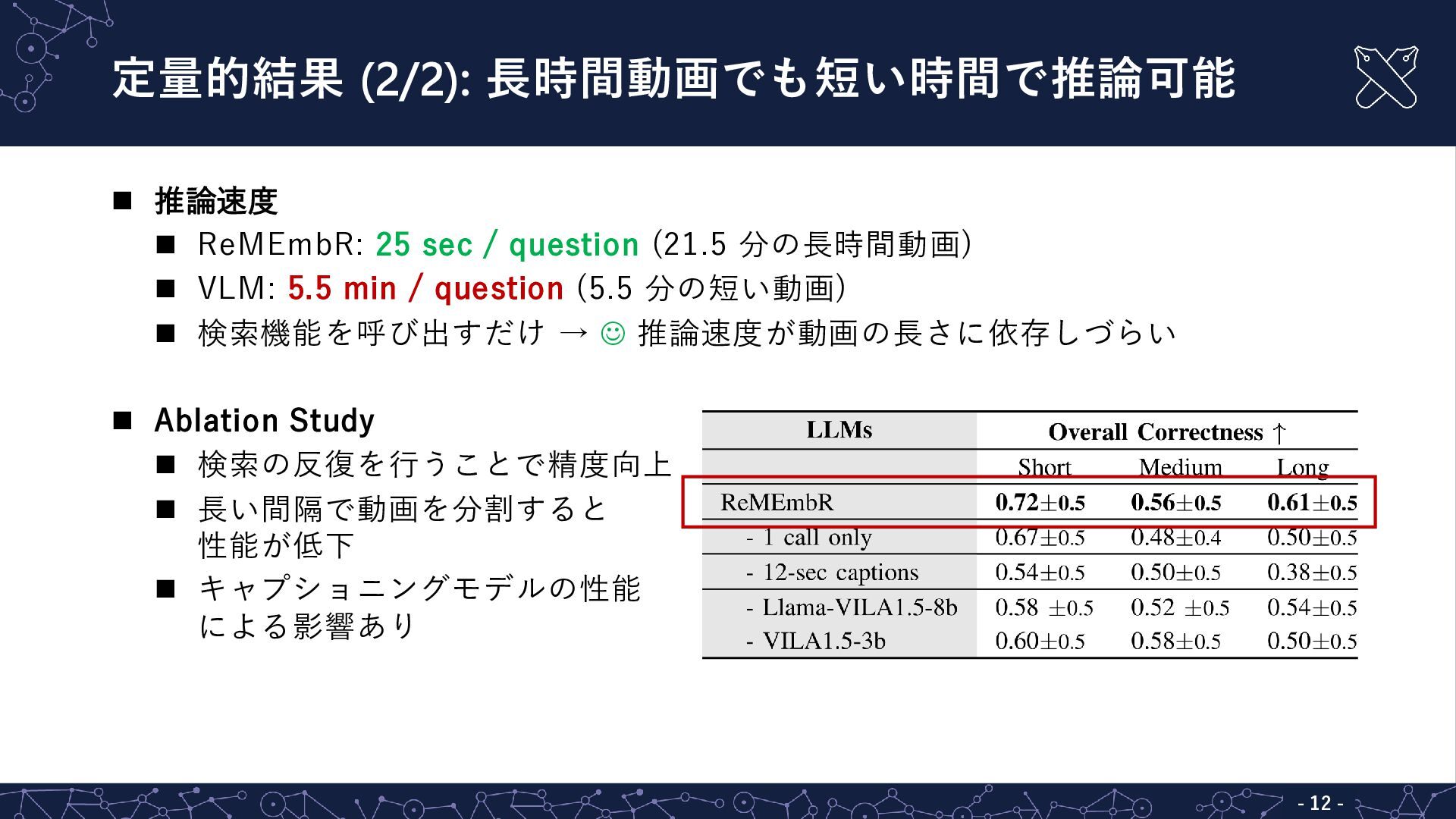
◼ 定性的結果 ◼ 成功例 • Q: “Did you see a red fire hydrant?” A: “yes” • Q: “When did you first enter the building?” A: “4.5 min ago” • Q: “Where is the closest place to sit?” A: [-104, 170, -2.4] ◼ 失敗例 • Q: “Where is the nearest recycling bin?” • Q: “Are you stopped in a loading zone right now?” キャプションによる情報の欠落 Overall Correctness ↑ 推論速度 (s) Short Medium Long 実験値 0.88 (7/8) 0.71 (5/7) 0.50 (5/10) 19.3 論文値 0.72±0.5 0.56±0.5 0.61±0.5 25
{kind=link}
{kind=link}
{kind=link}
![関連研究: 既存手法は長時間動画や時系列を扱えない - 4 - タスク・手法 特徴 OpenEQA [Majumdar+, CVPR24]](https://files.speakerdeck.com/presentations/5fe68998df834c47a3e22d4bfa41177e/slide_3.jpg){kind=link}
{kind=link}
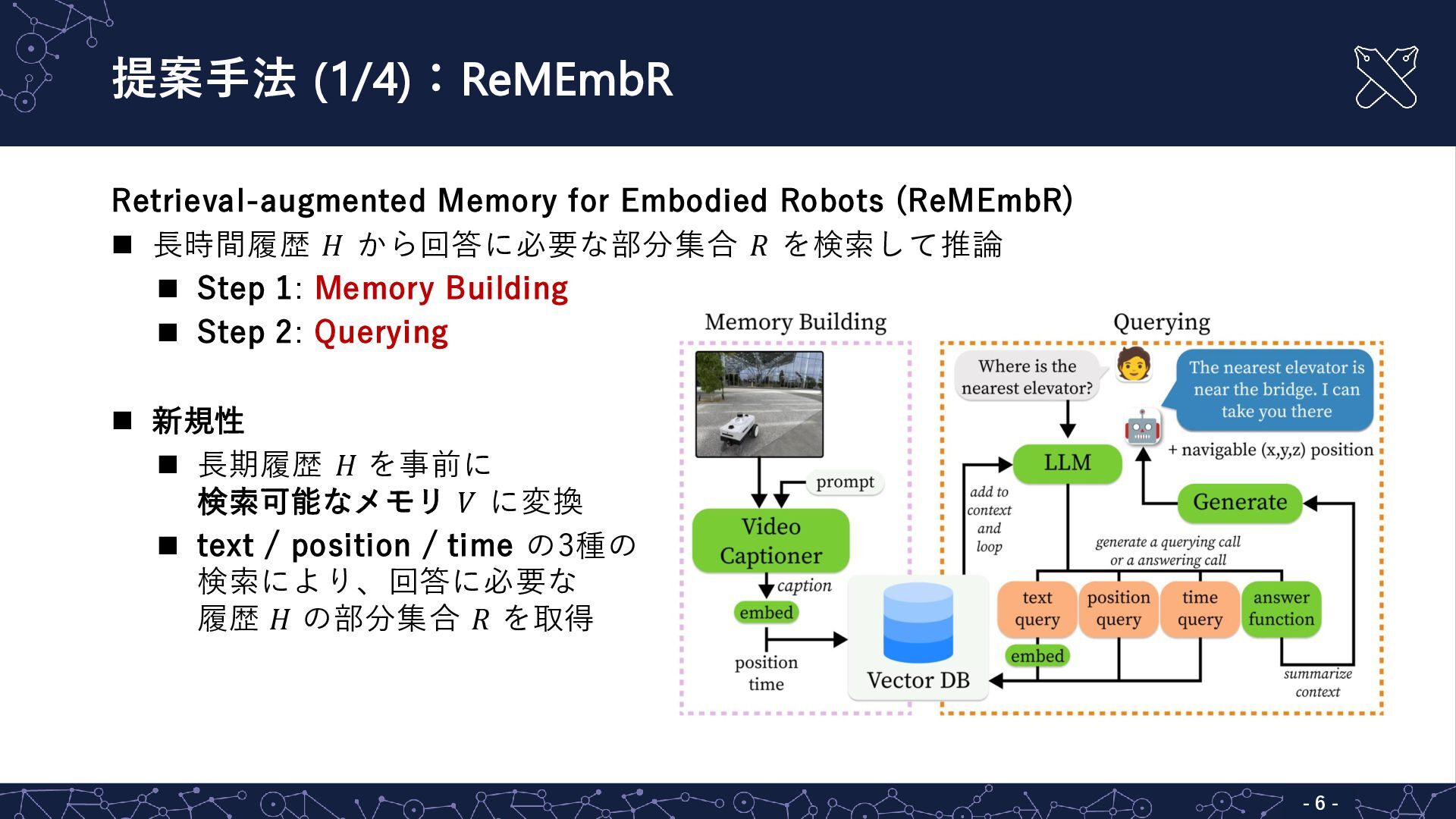{kind=link}
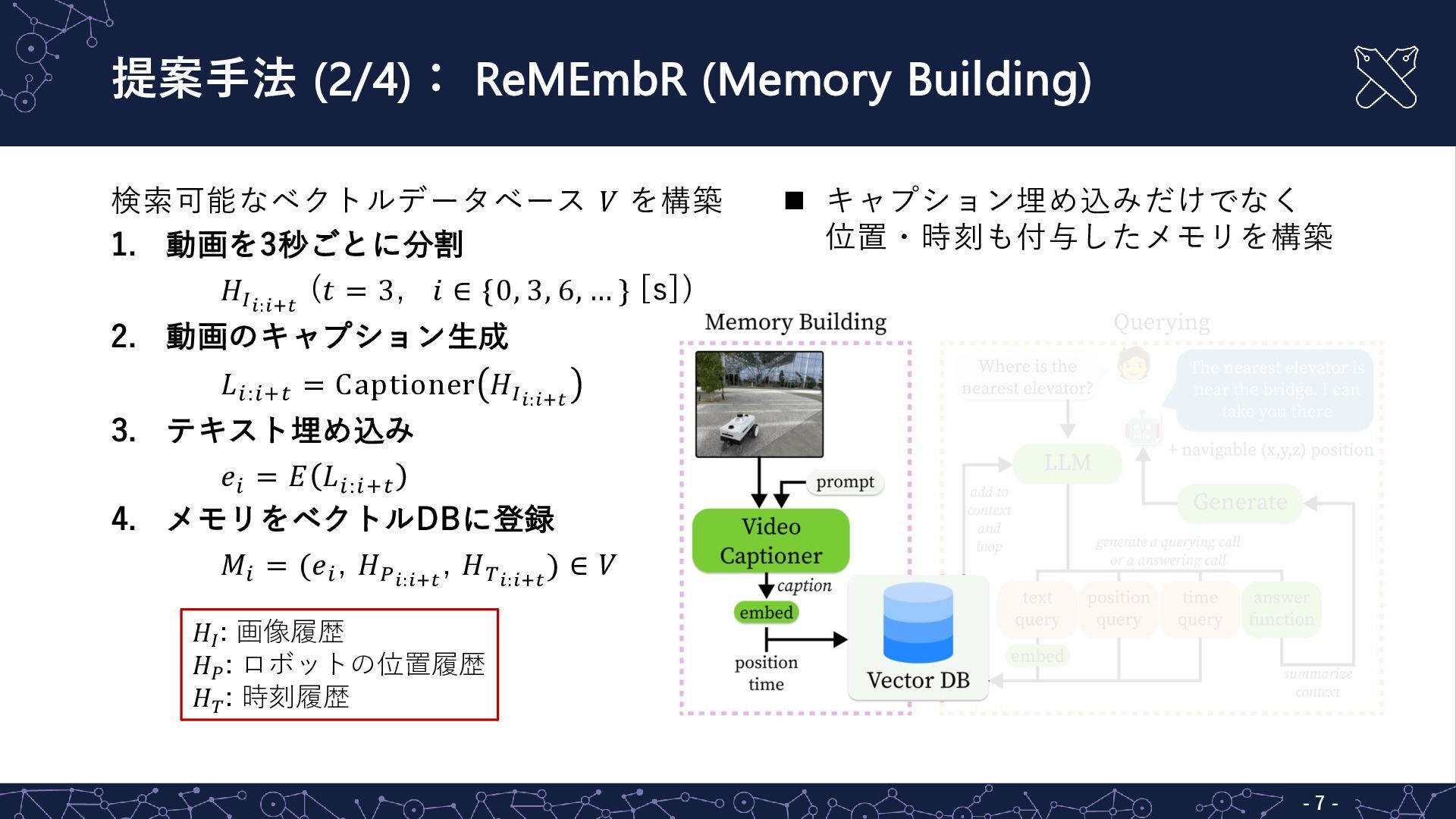{kind=link}
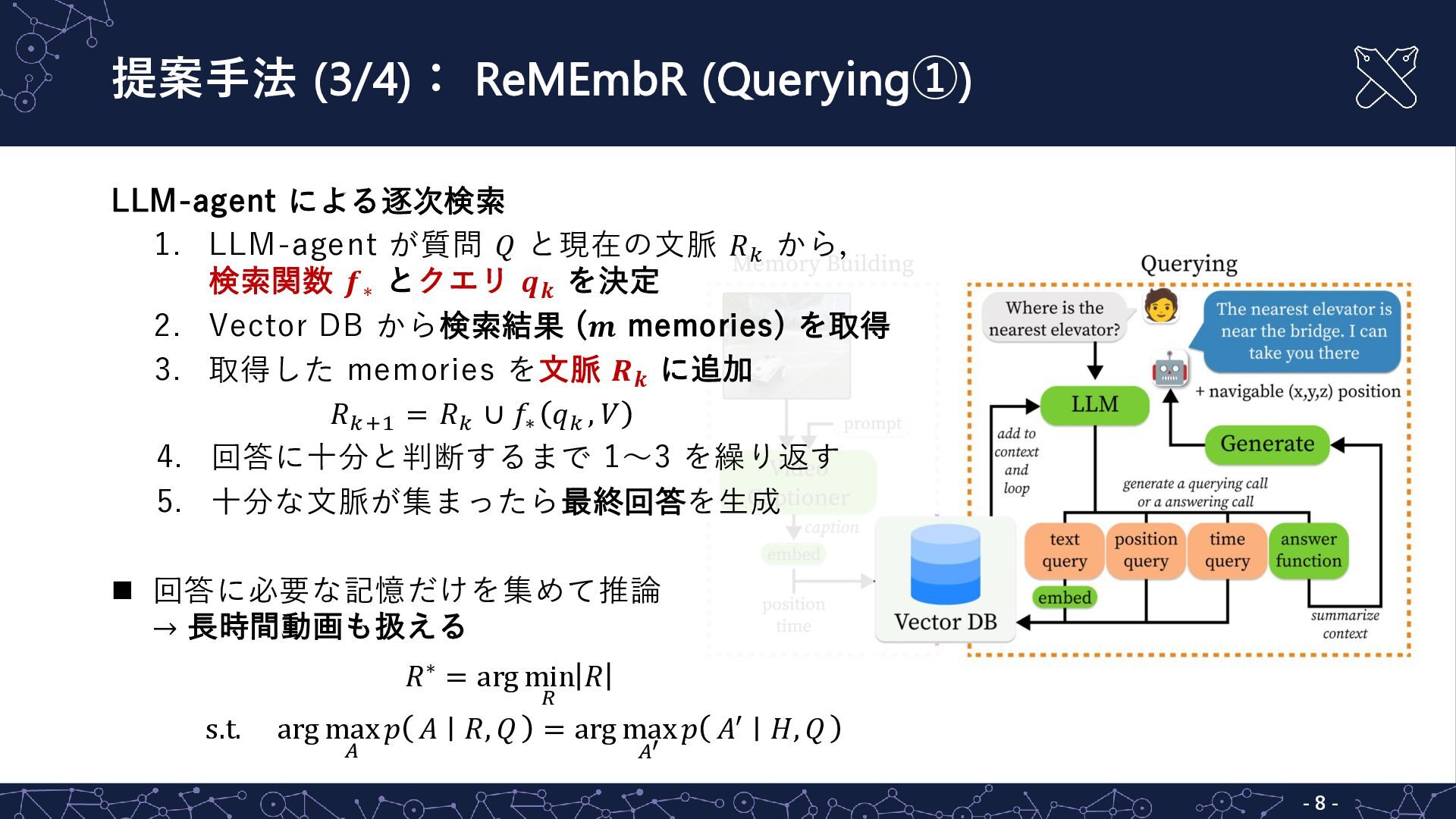{kind=link}
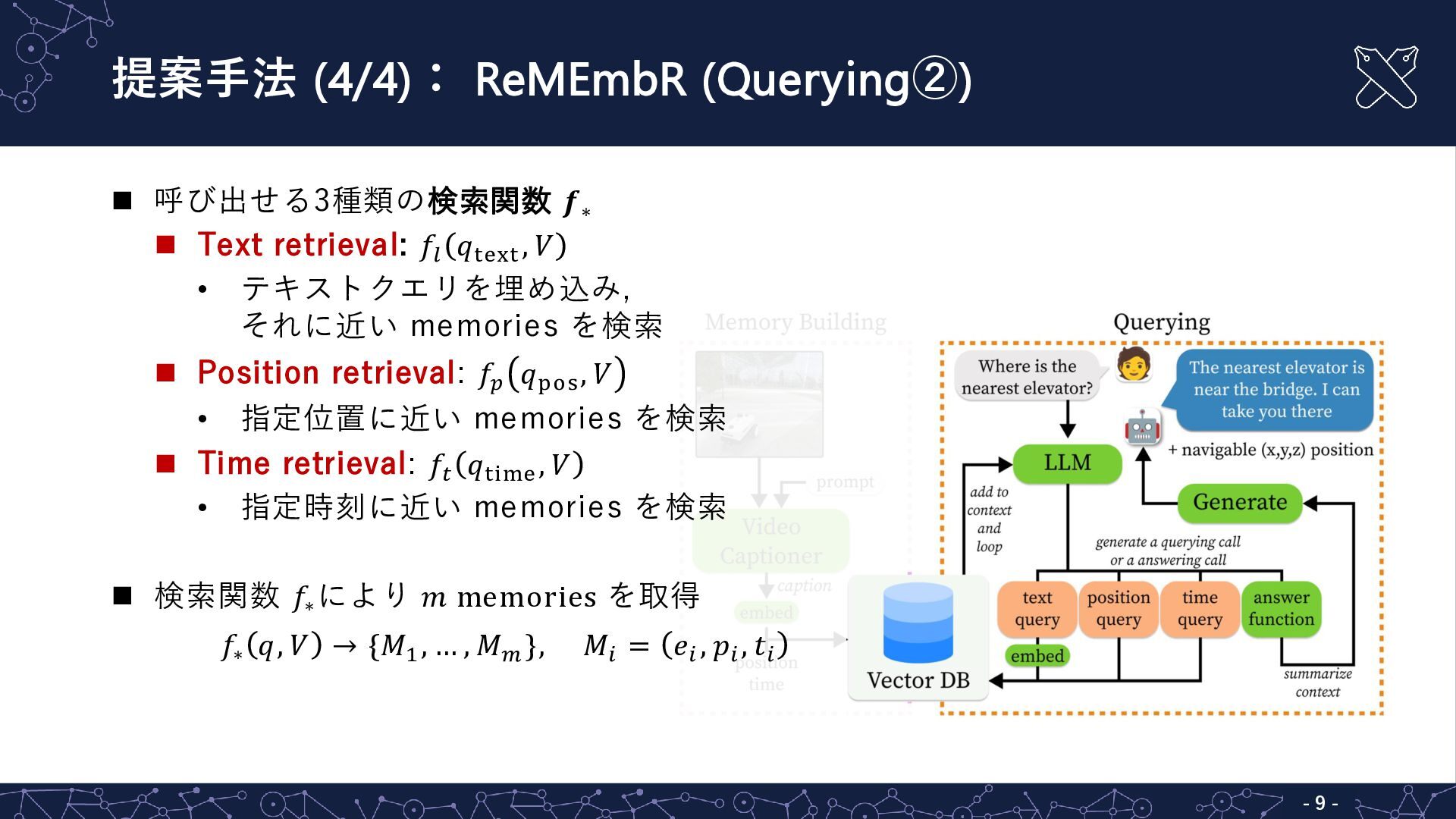{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}