Context.“, ECCV14 [Plummer+, ICCV15]:Plummer, Bryan A., et al. "Flickr30k entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models.“, ICCV15 [Karan+, CVPR21]:Desai, Karan, and Justin Johnson. "Virtex: Learning Visual Representations from Textual Annotations.“, CVPR21 [Zhang+, CVPR20] :Zhang, Qi, et al. "Context-Aware Attention Network for Image-Text Retrieval.“, CVPR20 [Chen+, CVPR21]:Chen, Jiacheng, et al. "Learning the Best Pooling Strategy for Visual Semantic Embedding.“, CVPR21 [Frome+, NIPS13]:Frome, Andrea, et al. "Devise: A Deep Visual-Semantic Embedding model.“, NIPS13 [Song+, CVPR19]:Song, Yale, and Mohammad Soleymani. "Polysemous visual-semantic embedding for cross-modal retrieval.“, CVPR19 [Chun+, CVPR21]:Chun, Sanghyuk, et al. "Probabilistic Embeddings for Cross-modal Retrieval.“, CVPR21 [Locatello+, NeurIPS20]:Locatello, Francesco, et al. "Object-Centric Learning with Slot Attention.“, NeurIPS20 [DL輪読会]Object-Centric Learning with Slot Attention https://www.slideshare.net/DeepLearningJP2016/dlobjectcentric-learning-with-slot-attention 26 参考文献
{kind=link}
{kind=link}
{kind=link}
![• 入力から画像-言語対の類似度を直接計算 • Virtex [Desai+, CVPR21] CAAN [Zhang+, CVPR20]など ](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_3.jpg){kind=link}
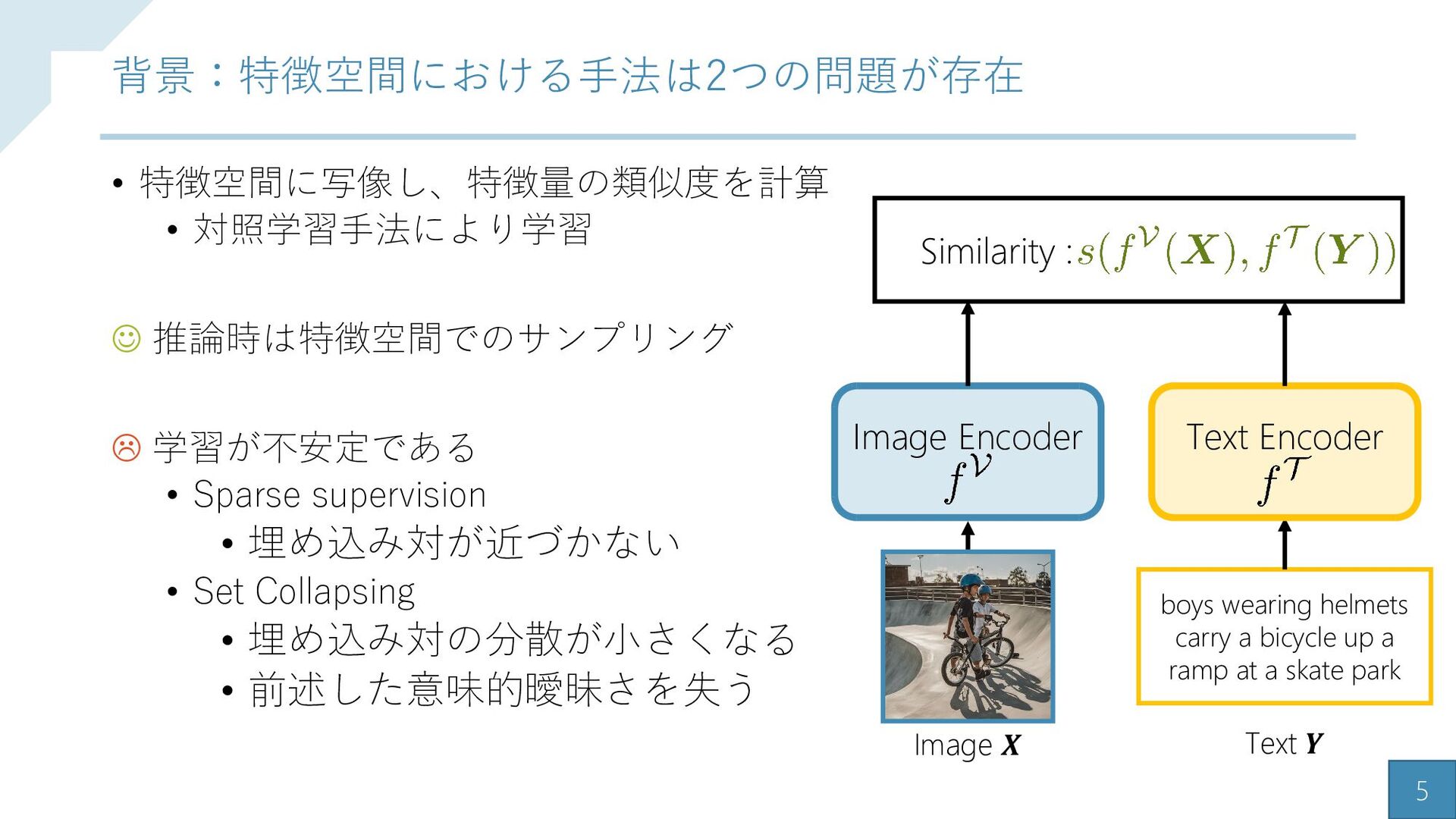{kind=link}
![Method 概要 VSE ∞ [Chen+, CVPR21] DeViSE [Frome+, NIPS13] の後続研究](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_5.jpg){kind=link}
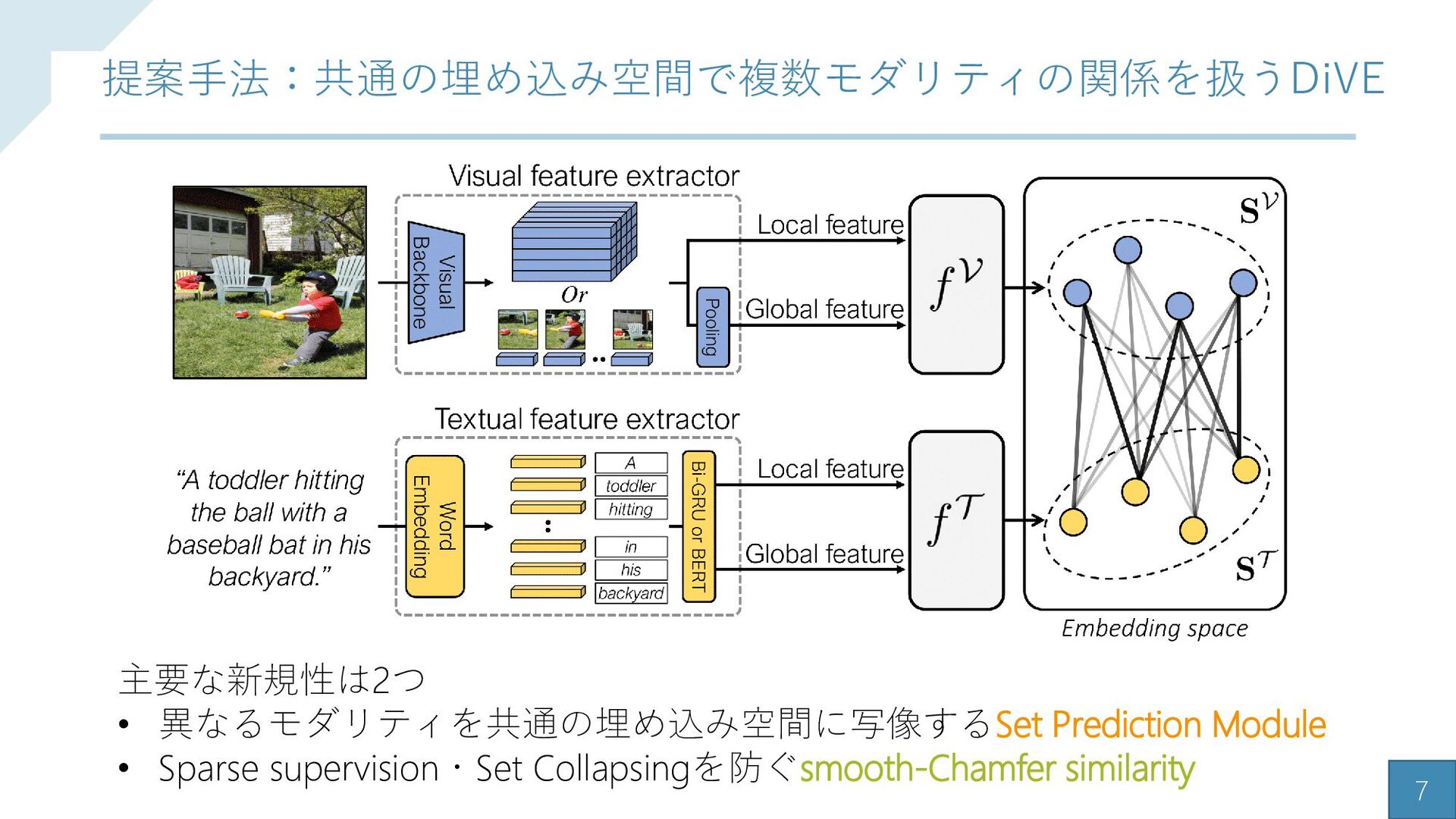{kind=link}
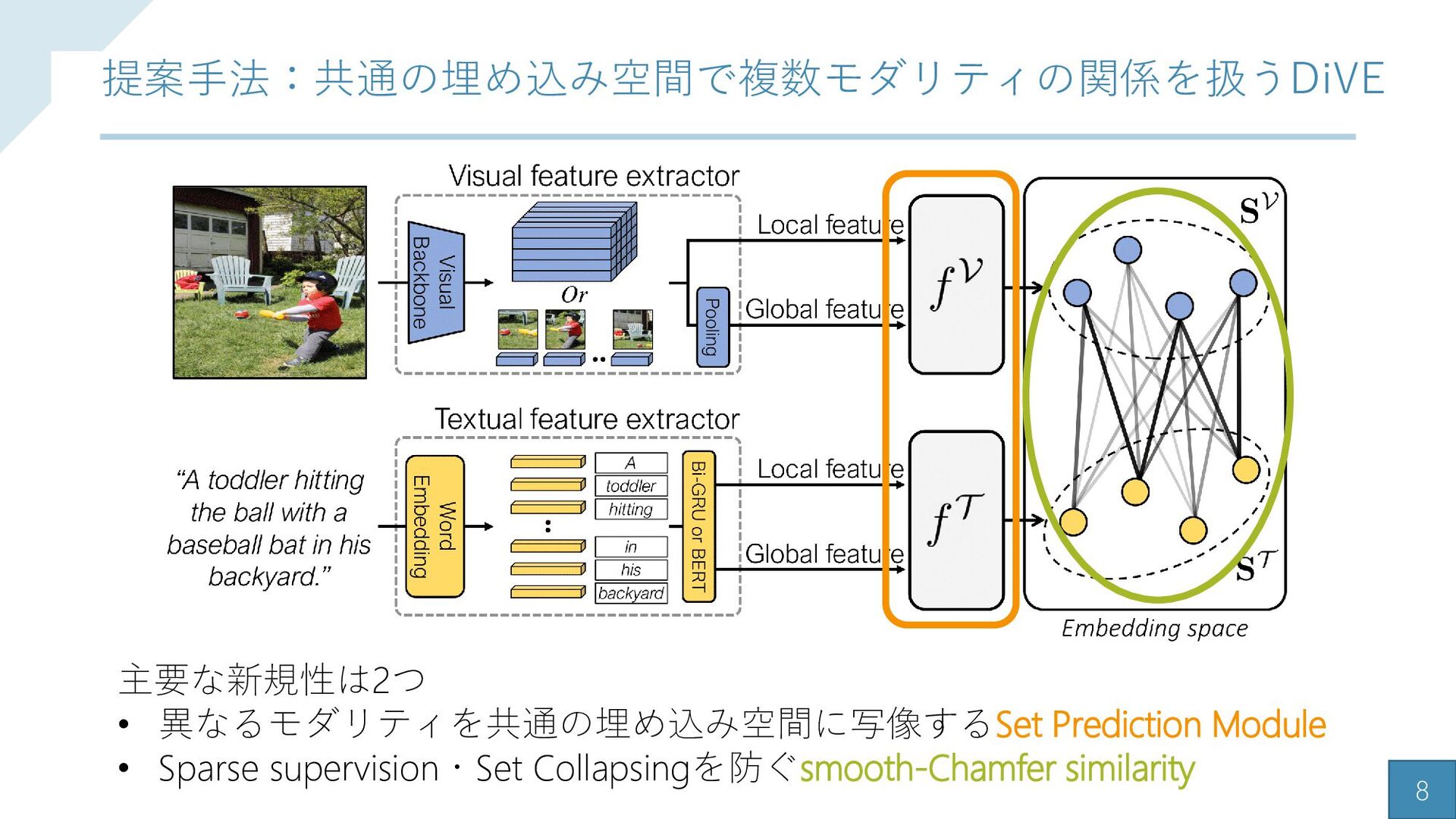{kind=link}
![• PCME [Chun+, CVPR21] との比較のため、局所/大域特徴を作成 • Local feature = Backboneからの出力](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_8.jpg){kind=link}
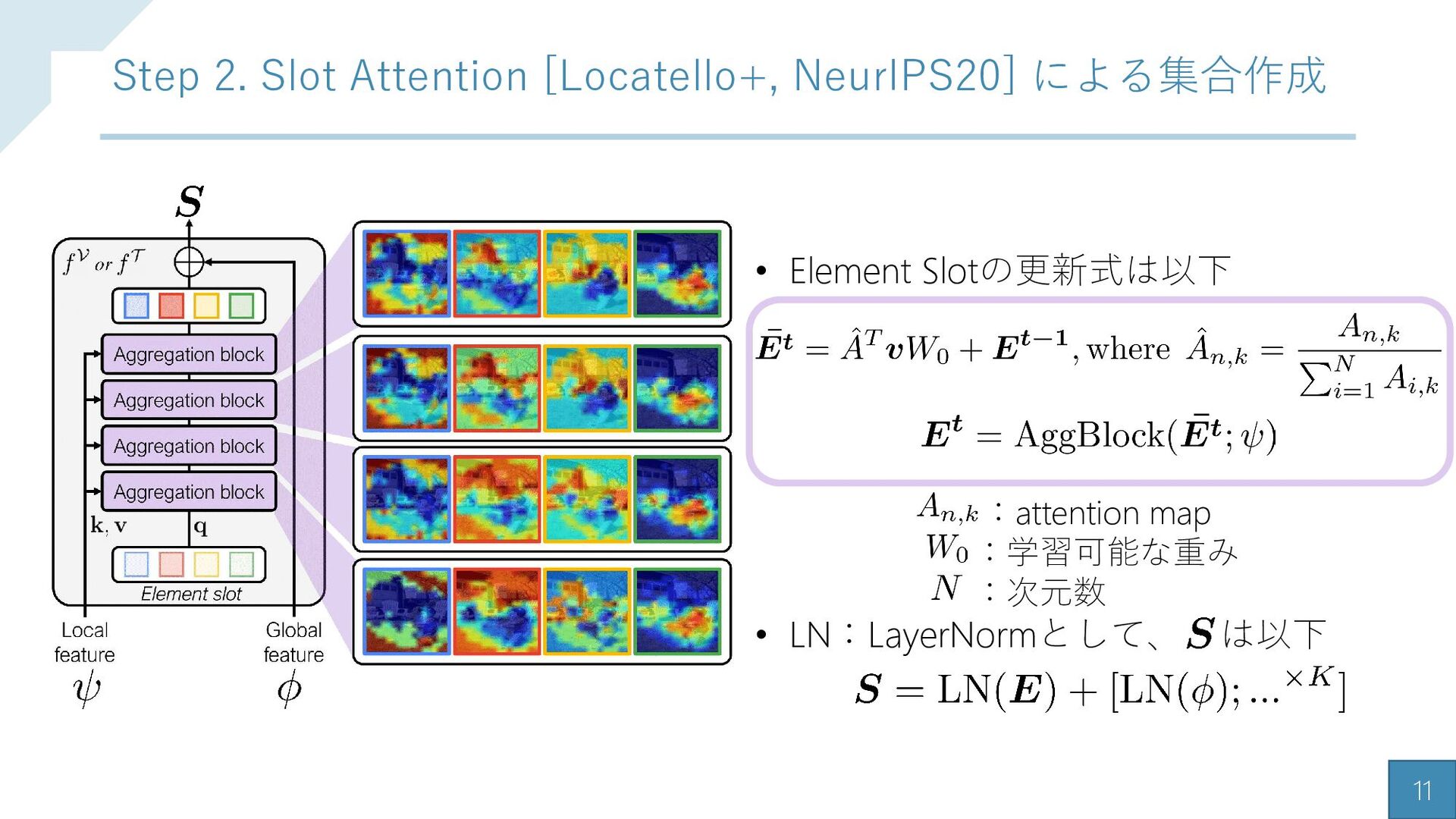
![10 Step 2. Slot Attention [Locatello+, NeurIPS20] による集合作成 • と](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_9.jpg){kind=link}
{kind=link}
![• 類似する埋め込み表現をどのように近づけるべきか? (a) MIL [Song+, CVPR19] • 集合の要素の最短の組の距離 • ほとんどの要素は疎なまま](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_11.jpg){kind=link}
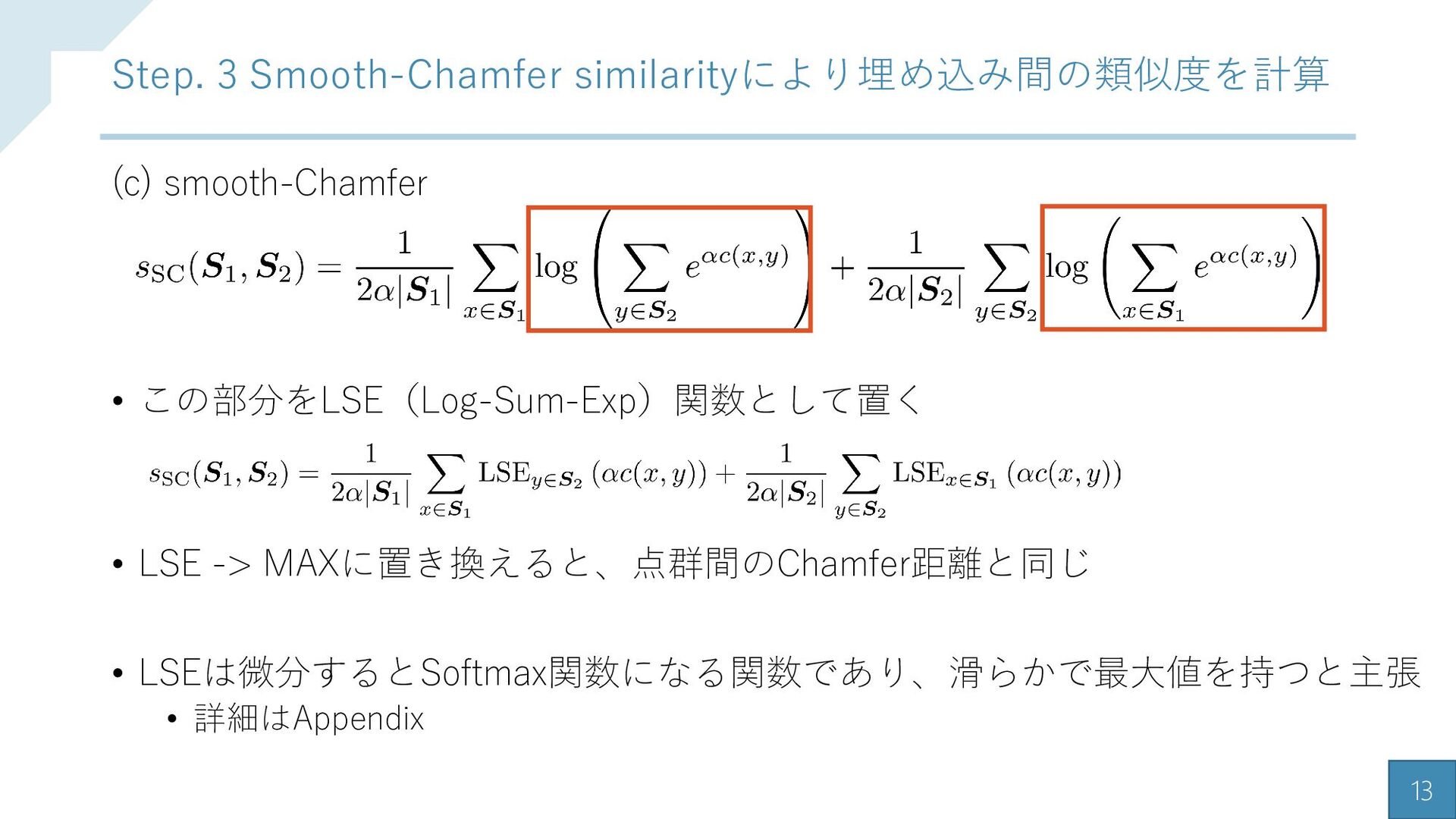{kind=link}
{kind=link}
![• 4つのPublic Benchmarksにおいて検証 • COCO [Lin+, ECCV14]、Flickr30K [Plummer+, ICCV15]、ECCV caption](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_14.jpg){kind=link}
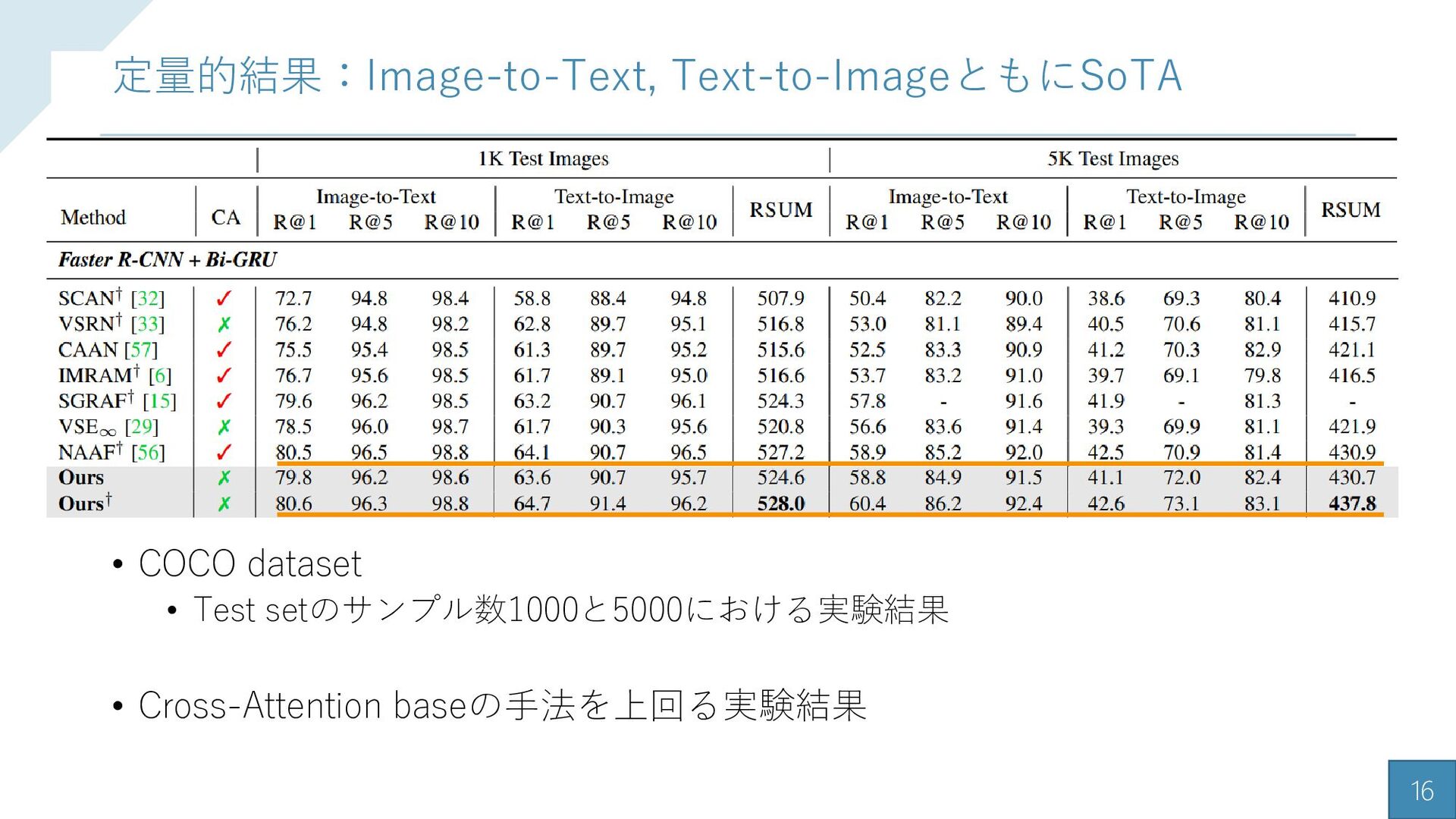{kind=link}
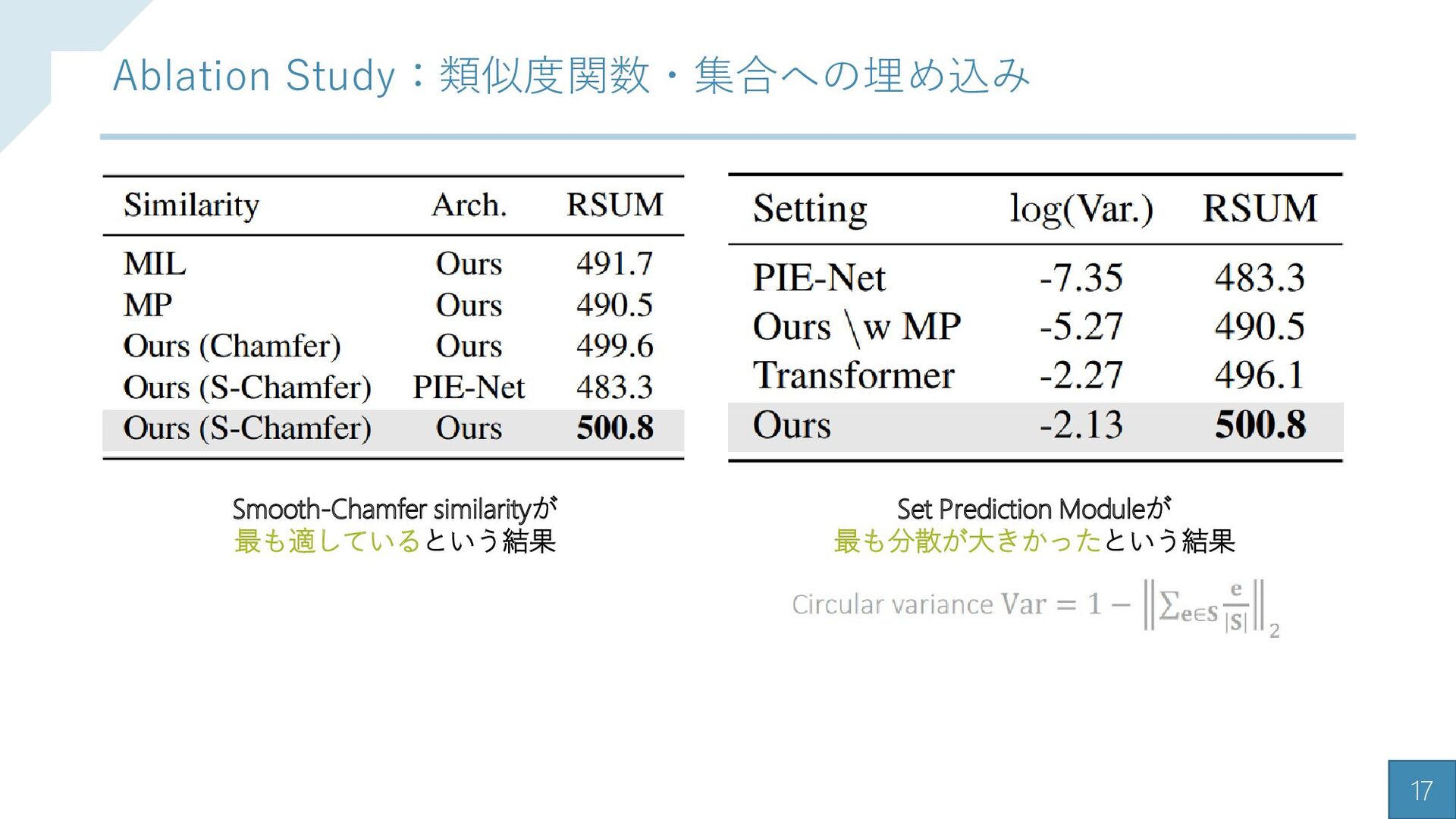{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
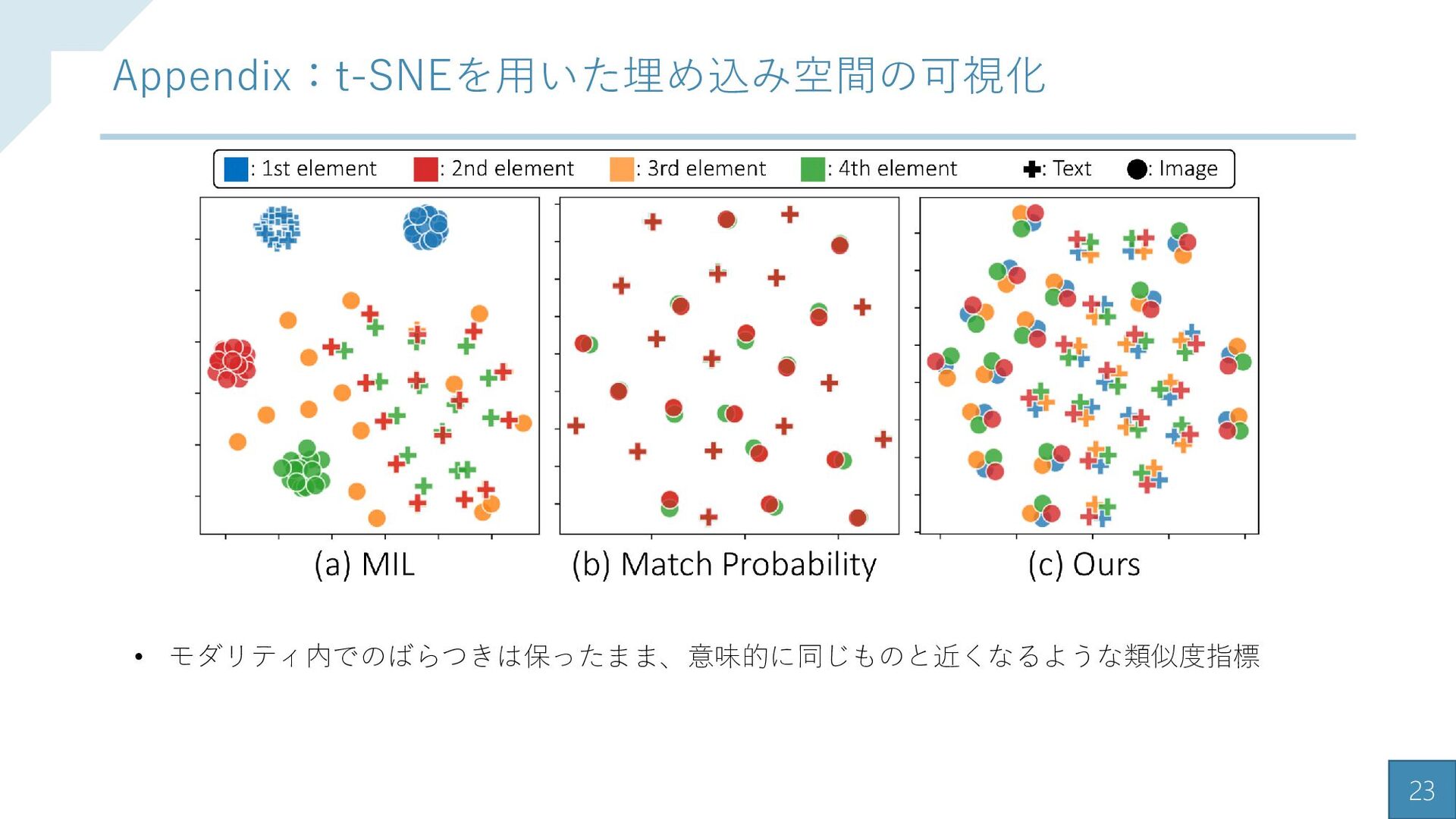{kind=link}
{kind=link}
{kind=link}
![[Lin+, ECCV14]:Lin, Tsung-Yi, et al. "Microsoft COCO: Common Objects in](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_25.jpg){kind=link}
![[Chun+, ECCV22]:Chun, Sanghyuk, et al. "Eccv Caption: Correcting False Negatives](https://files.speakerdeck.com/presentations/986a348ab30f474abafd22fb76d72828/slide_26.jpg){kind=link}