Deep Reinforcement Learning Mingjie Sun1,2, Jimin Xiao1, Eng Gee Lim1 (1Xi’an Jiaotong-Liverpool University, 2University of Liverpool) CVPR 2021 Sun, Mingjie, Jimin Xiao, and Eng Gee Lim. "Iterative Shrinking for Referring Expression Grounding Using Deep Reinforcement Learning." CVPR 2021.
{kind=link}
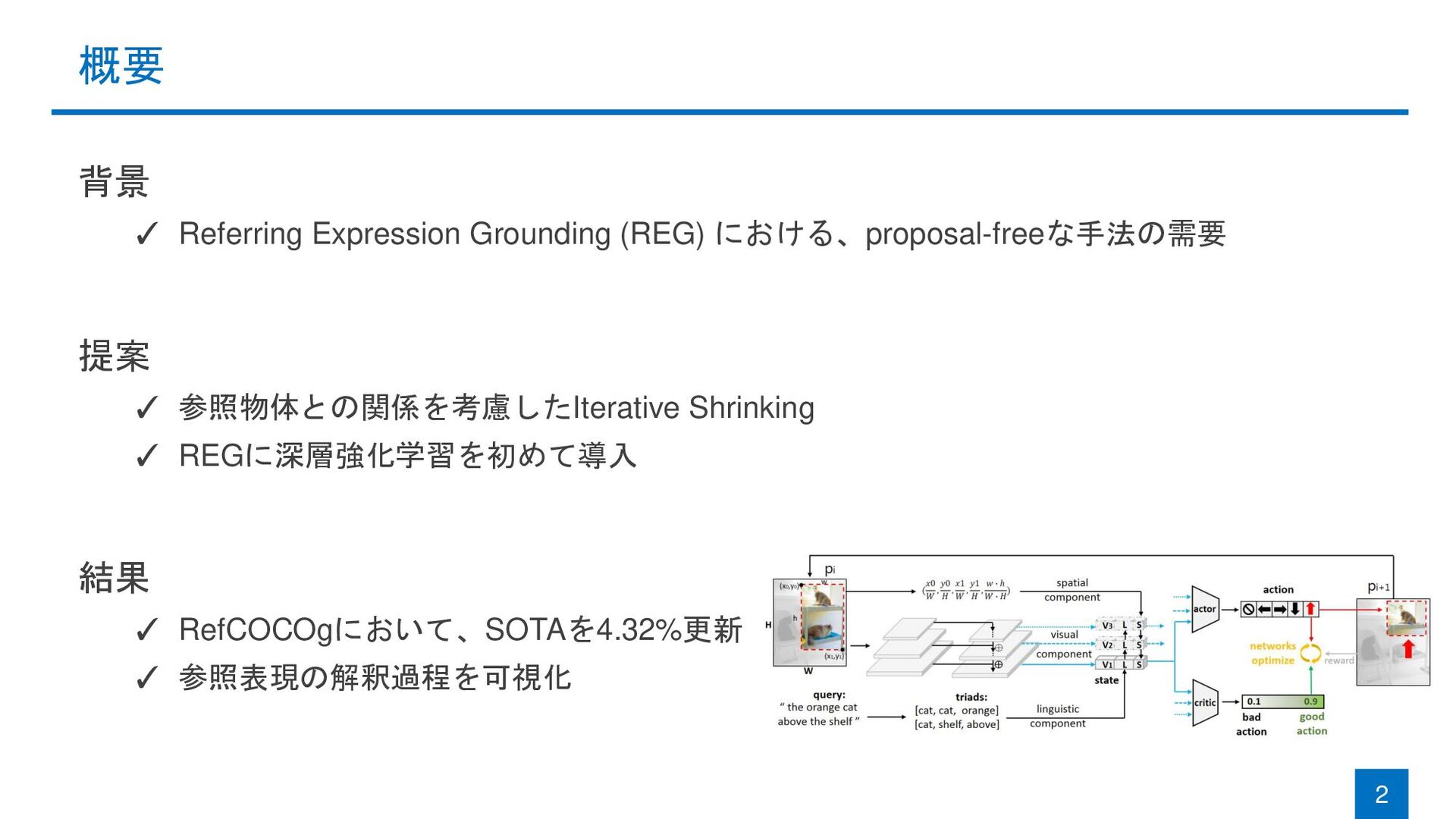{kind=link}
{kind=link}
{kind=link}
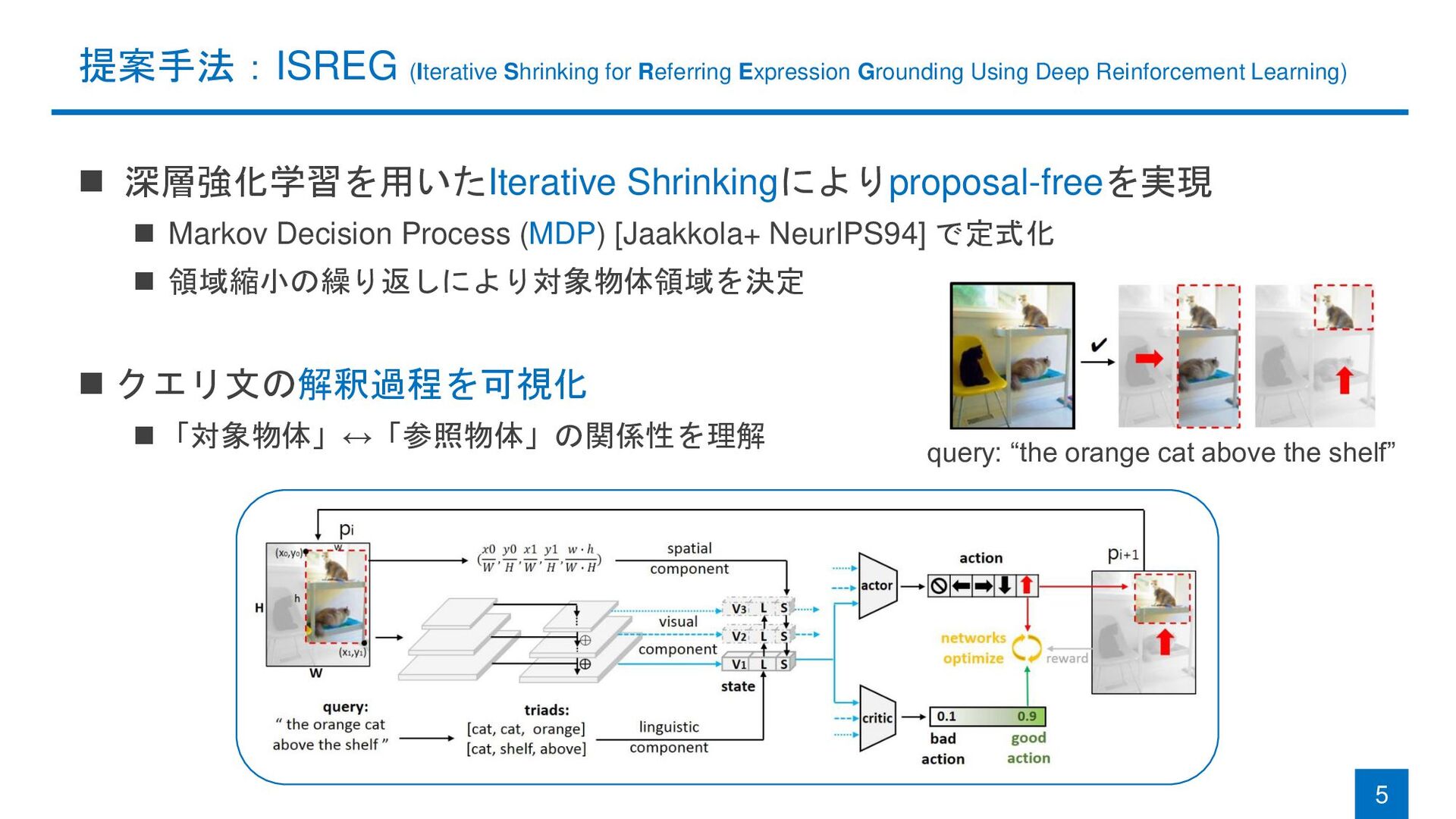{kind=link}
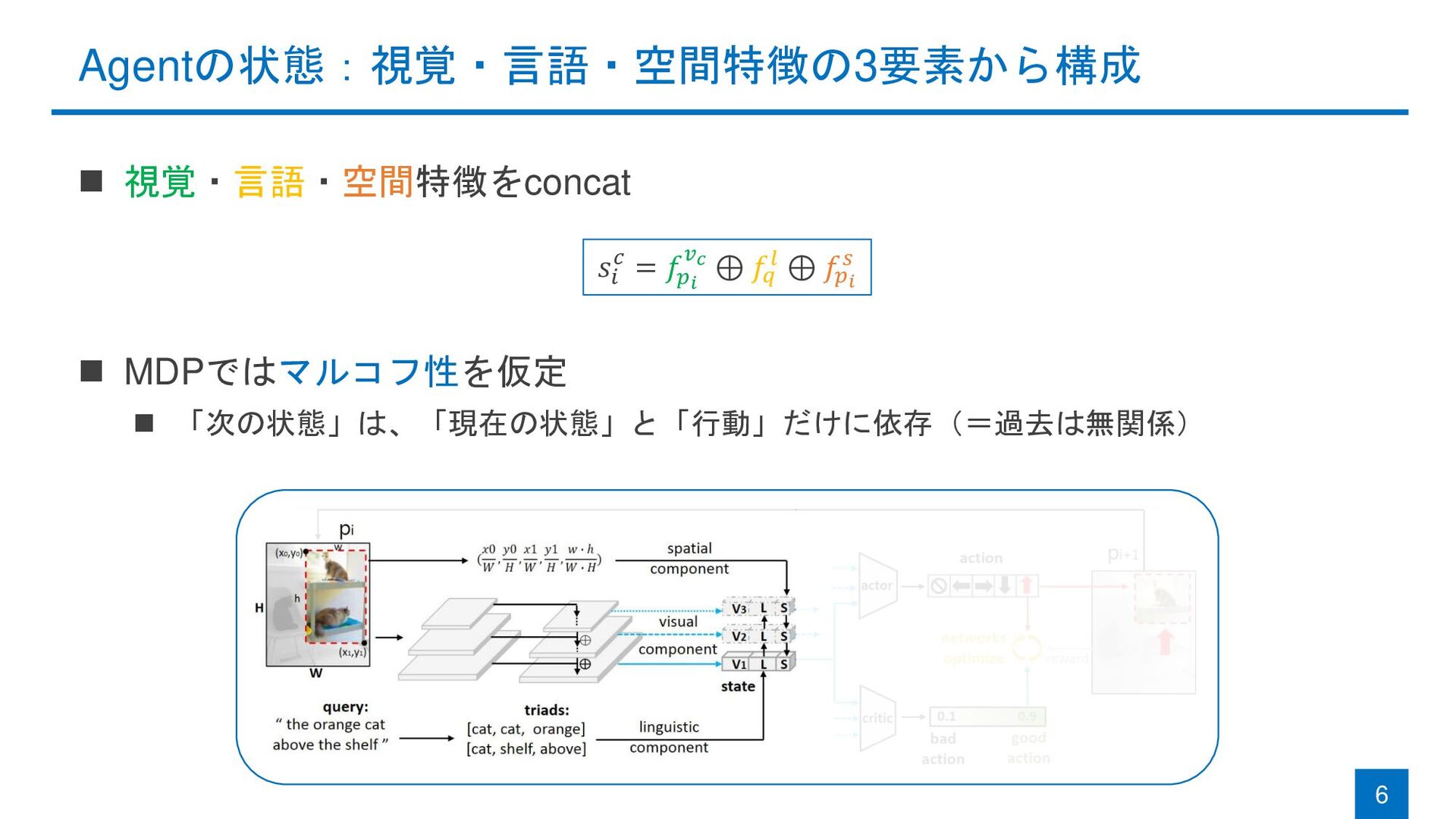{kind=link}
![FPN: ① up-sampling ② average-pooling 視覚特徴:スケールの異なる3つの特徴を獲得 ◼ ResNet [He+ CVPR16]](https://files.speakerdeck.com/presentations/9b57bbf9510a48d6b9c8f76957fbd783/slide_6.jpg){kind=link}
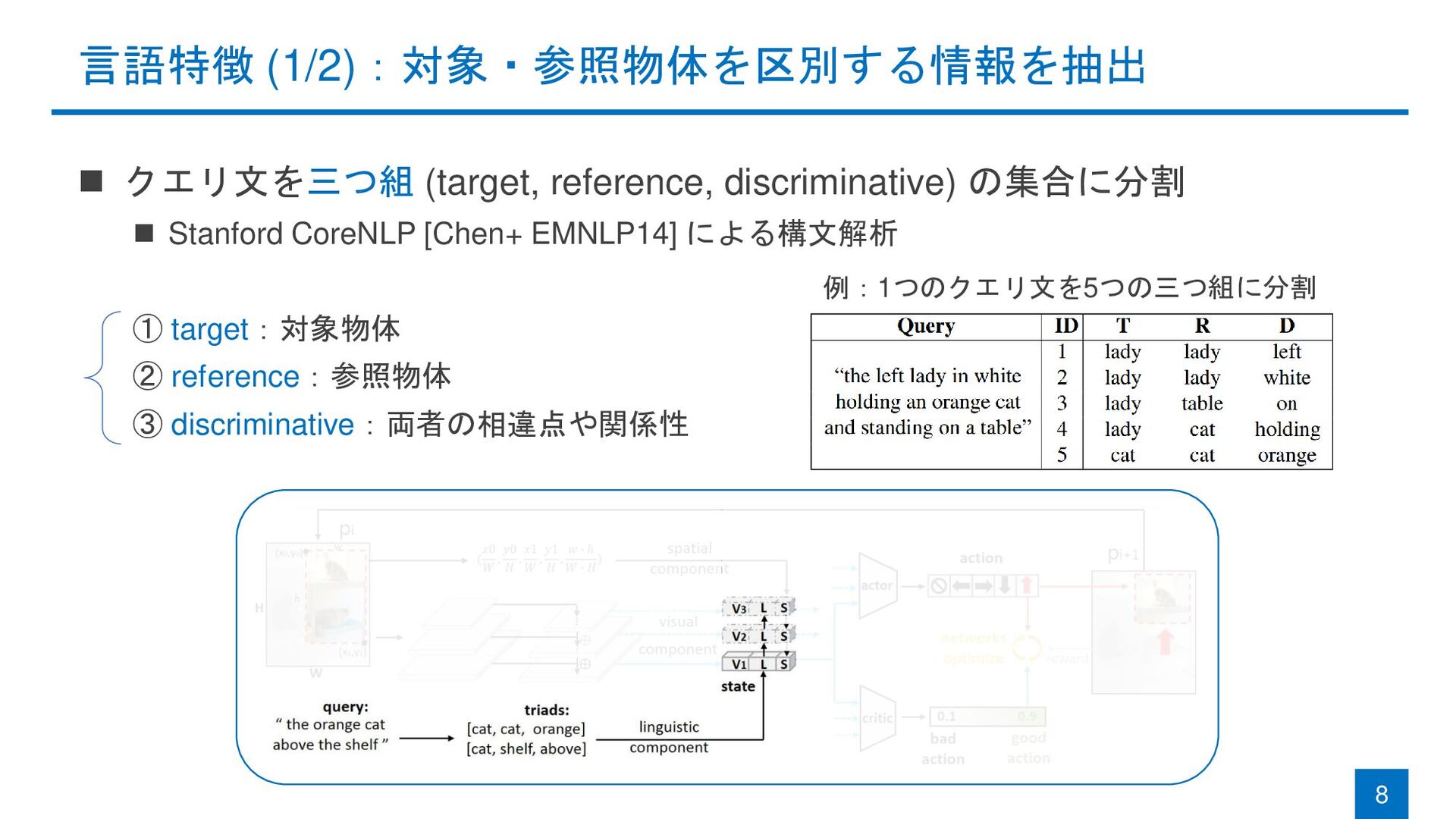{kind=link}
![言語特徴 (2/2):単語をベクトル表現で埋め込み ◼ GloVe [Pennington+ EMNLP14] により各単語をベクトルで表現 9 𝑓𝑡𝑘 𝑙](https://files.speakerdeck.com/presentations/9b57bbf9510a48d6b9c8f76957fbd783/slide_8.jpg){kind=link}
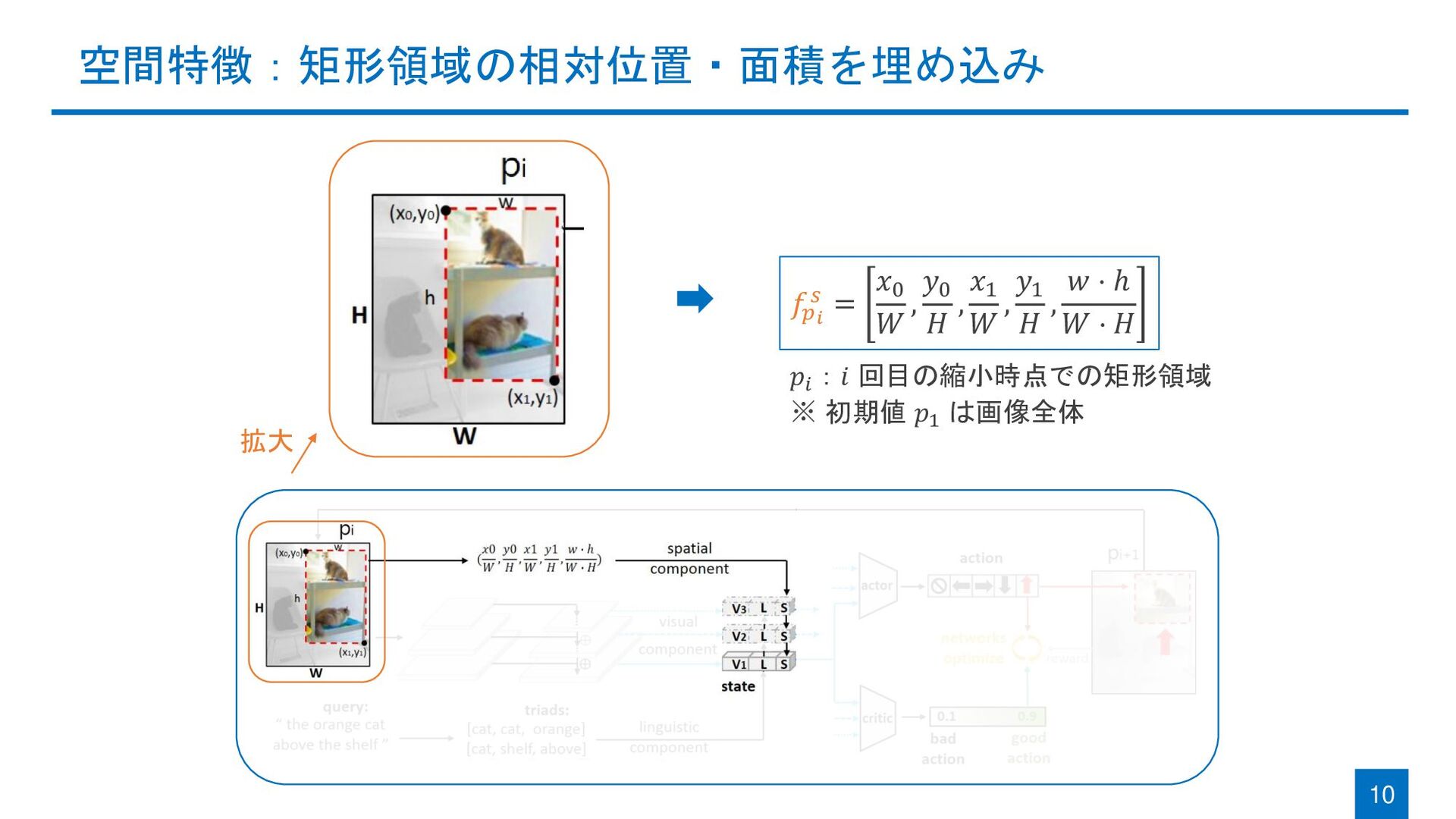{kind=link}
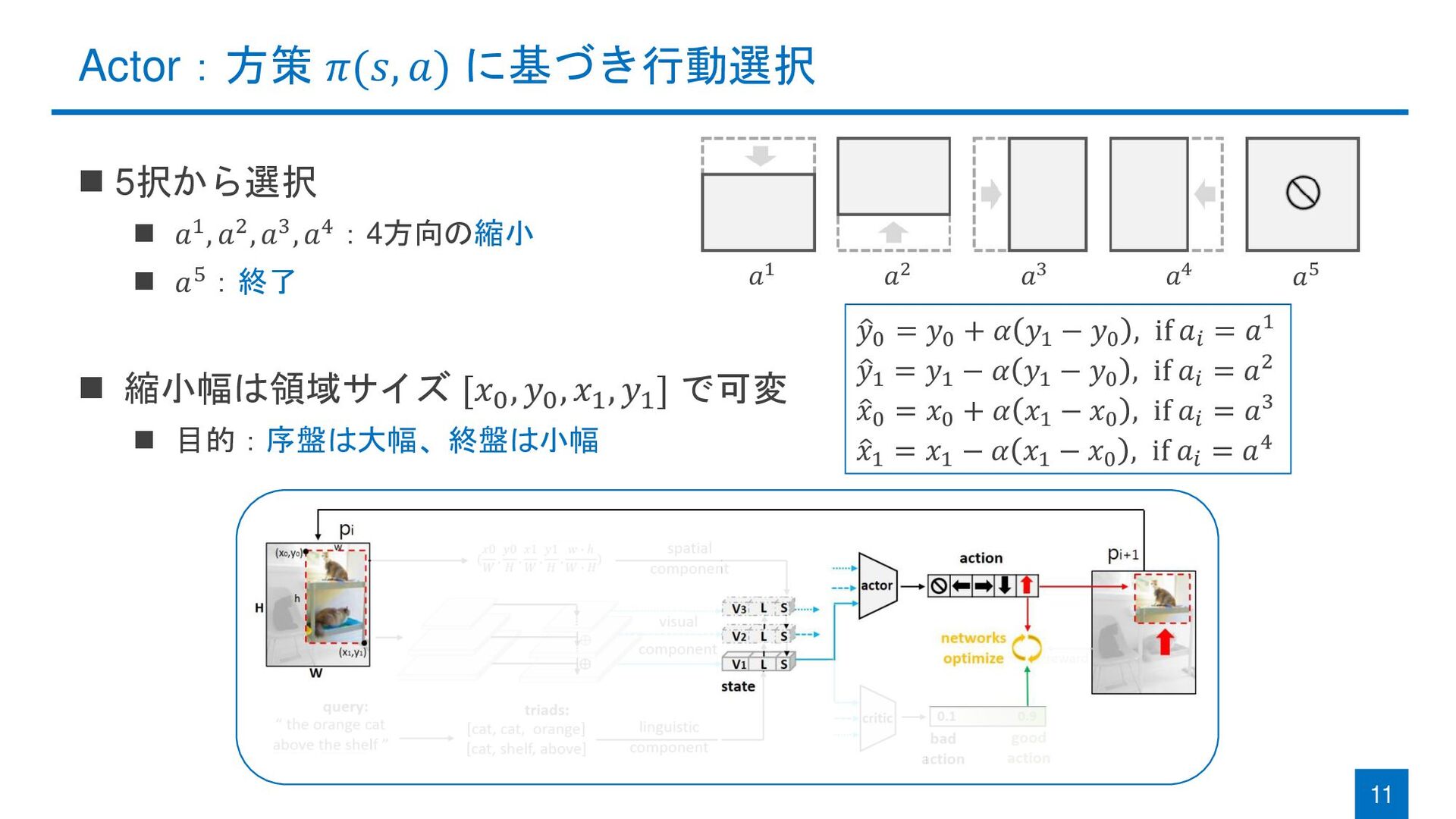{kind=link}
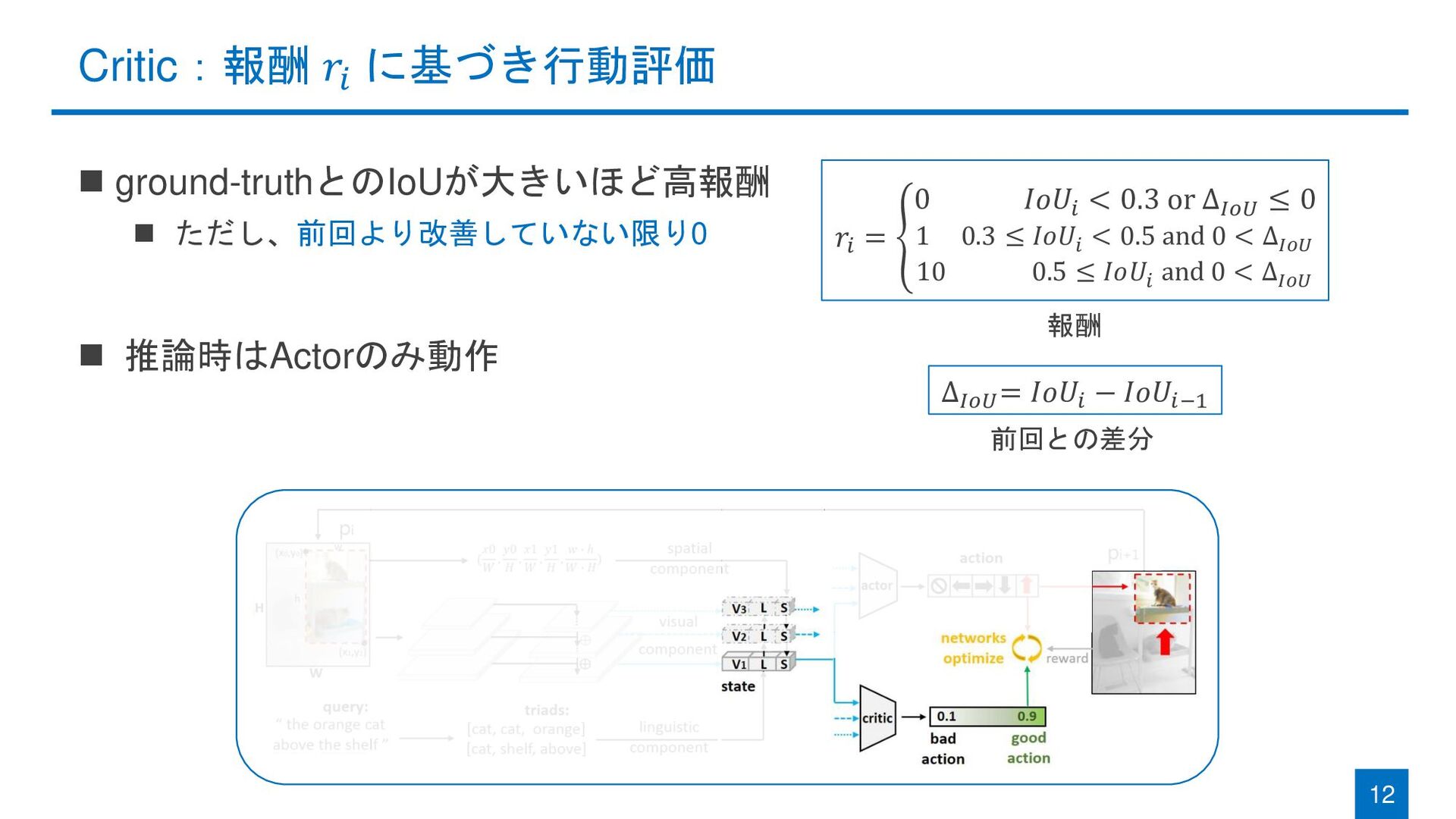{kind=link}
![Actor-Critic [Mnih+ ICML16]:Actor, Criticの順に交互に学習 ◼ Actor:TD誤差 𝛿𝑖 により、方策 𝜋(𝑠, 𝑎)](https://files.speakerdeck.com/presentations/9b57bbf9510a48d6b9c8f76957fbd783/slide_12.jpg){kind=link}
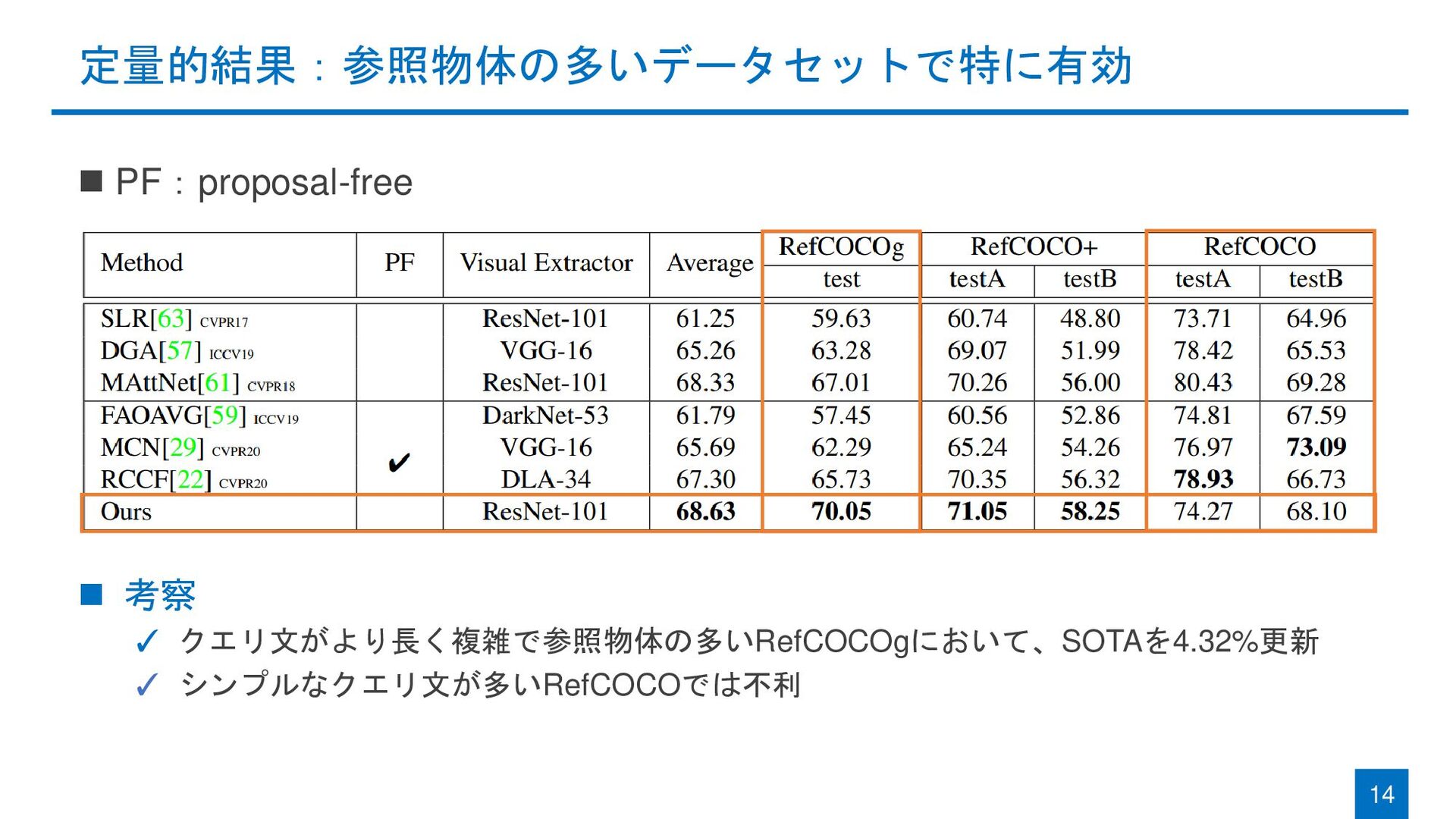{kind=link}
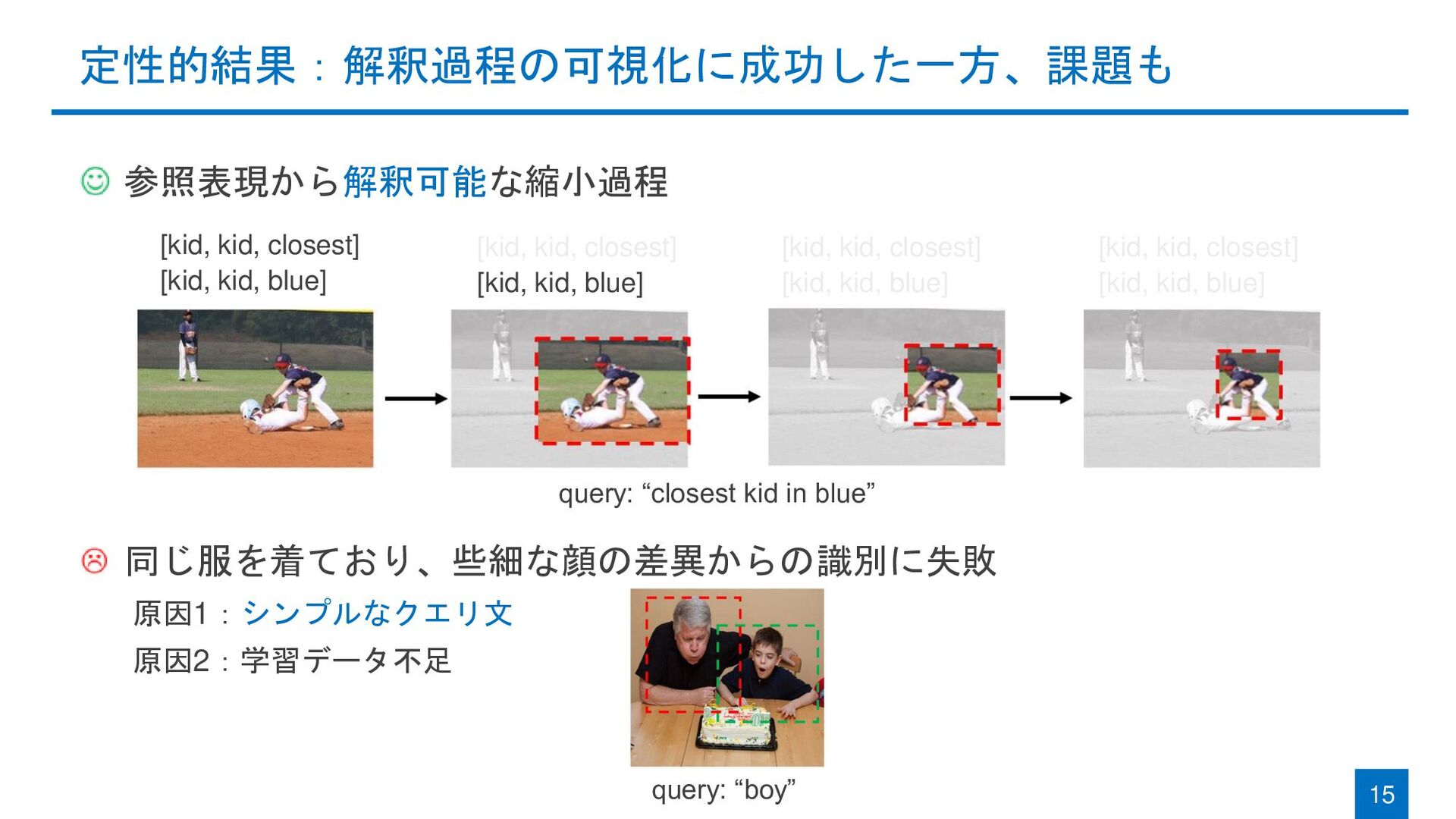{kind=link}
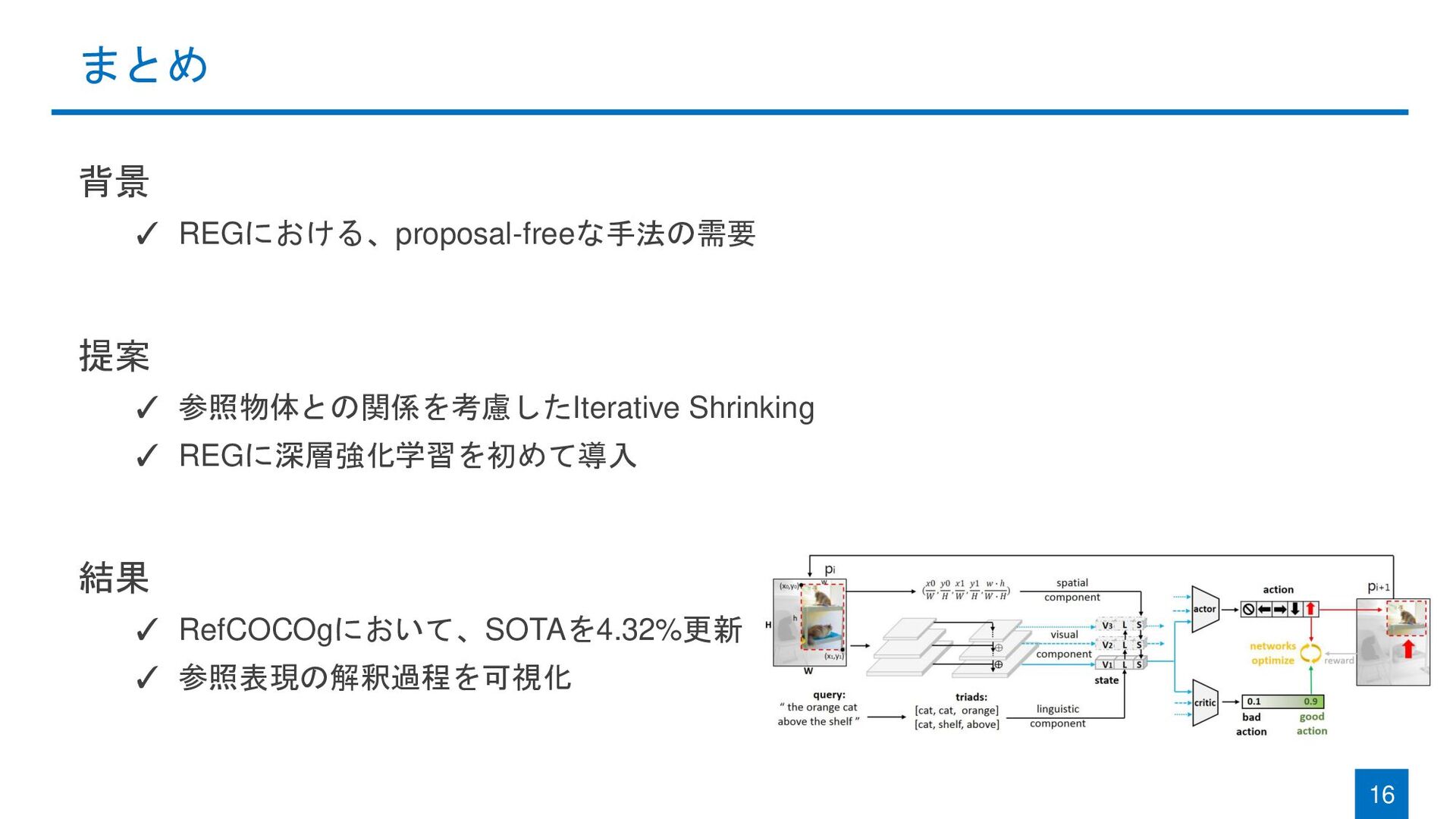{kind=link}
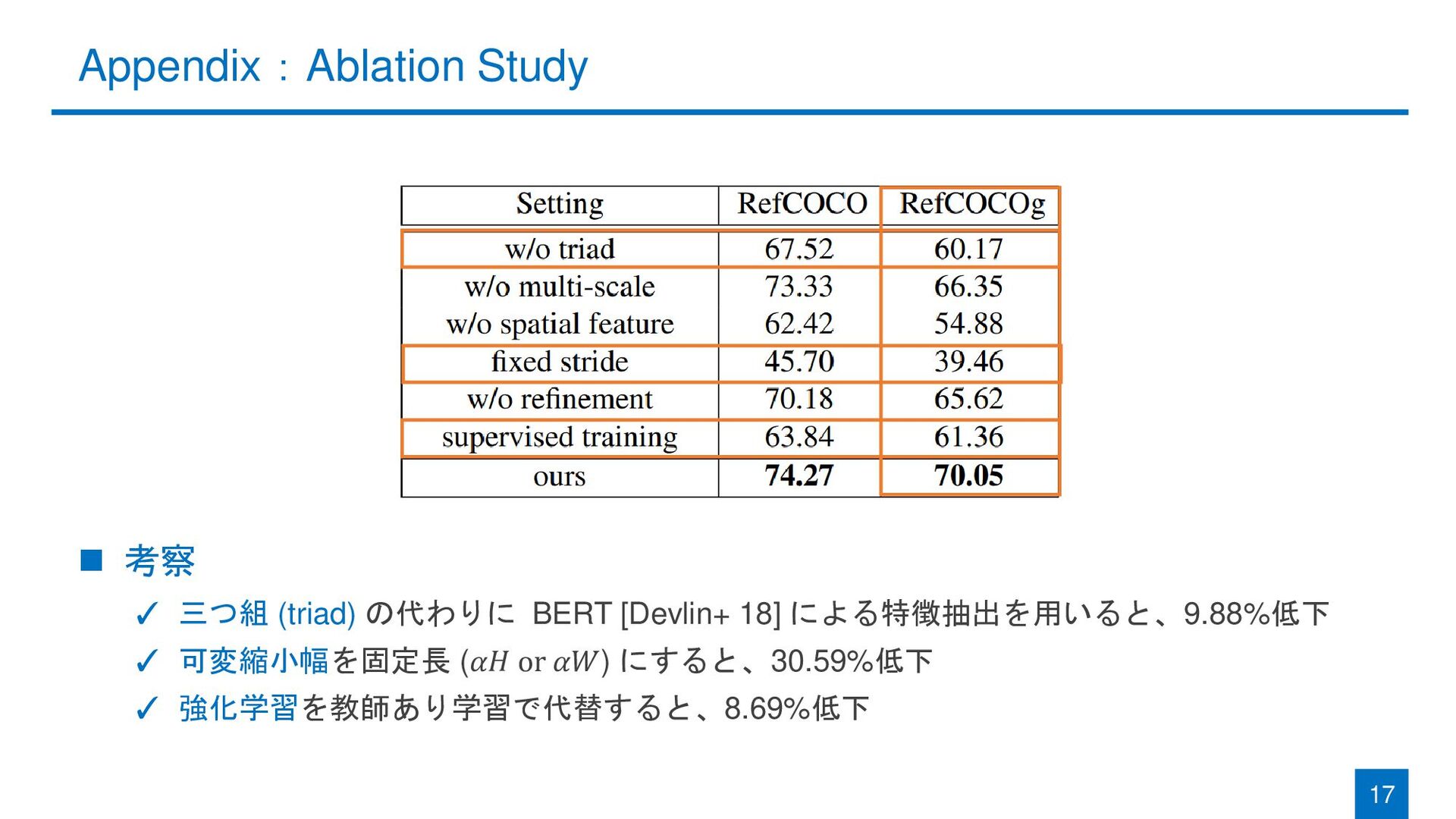{kind=link}
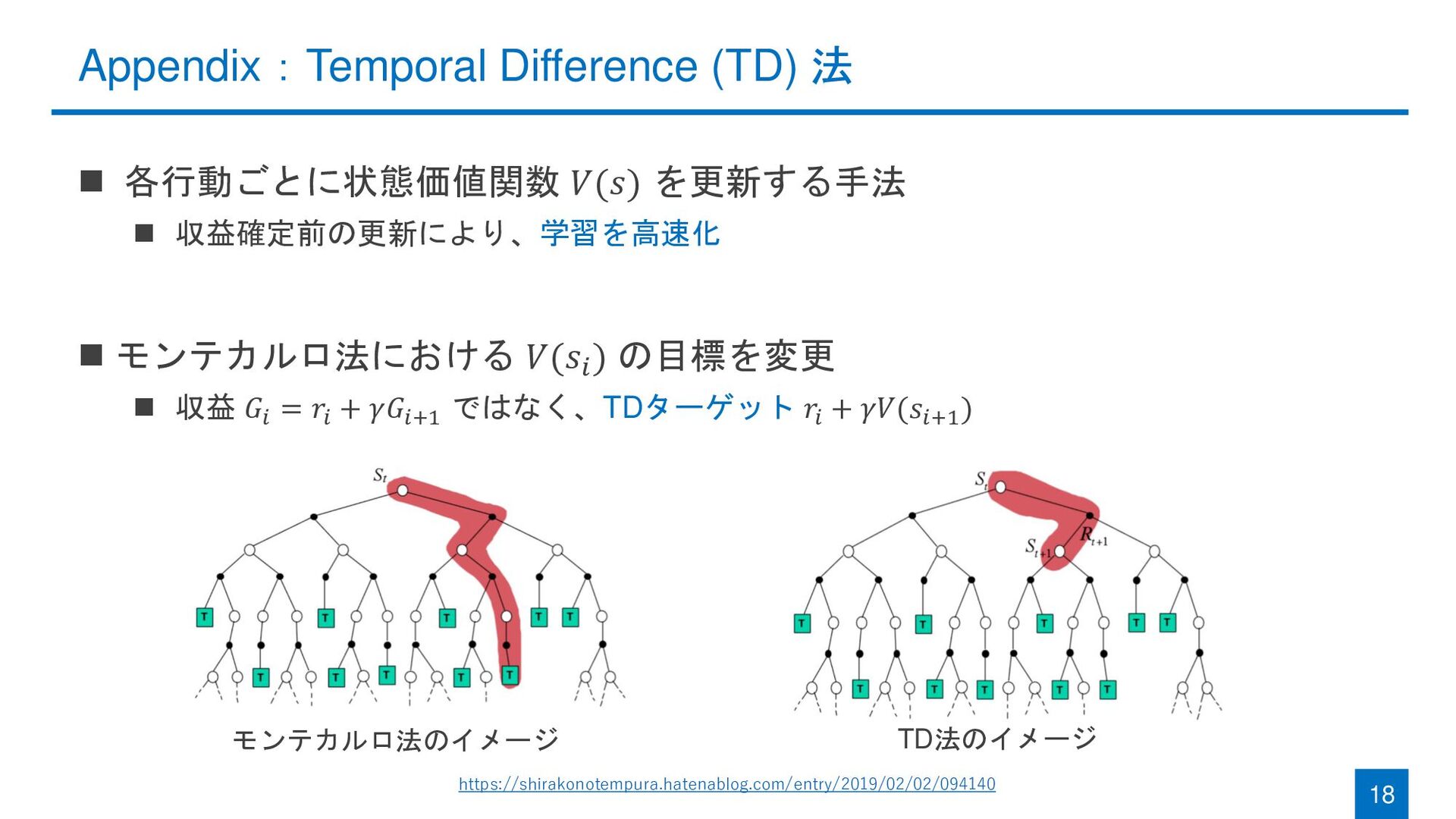{kind=link}