Vocabulary Mobile Manipulation Challenge n 自動化とオペレータによる介入を 組み合わせたhuman-in-the-loop設定 n Open-Vocabularyのユーザ指示文から 対象物体を検索・把持 L Closed-vocabulary設定では実用性 低 本手法のアプローチ L 成功率 約 30% [Qi+, CVPR20]
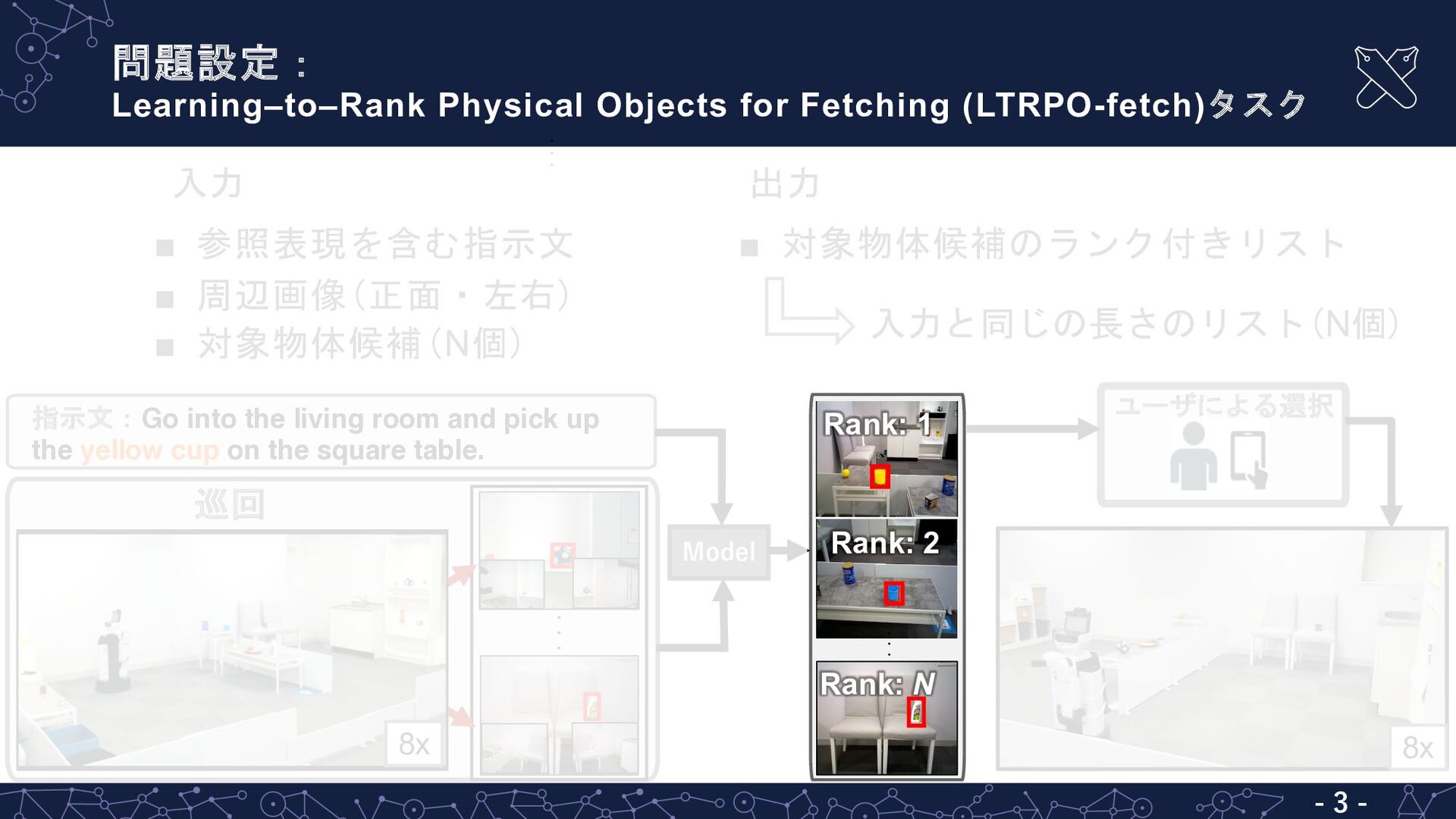
▪ 参照表現を含む指示文 ▪ 周辺画像(正面・左右) ▪ 対象物体候補(N個) 入力 8x 指示文:Go into the living room and pick up the yellow cup on the square table. Model ・・・ 巡回 Rank: 1 Rank: 2 Rank: N ・・・ ユーザによる選択 ・・・ 8x 出力 ▪ 対象物体候補のランク付きリスト 入力と同じの長さのリスト(N個)
Challenge / Real Space の標準環境に準拠 n 実機:Human Support Robot (HSR) n 物体:YCB Object [Calli+, RAM15] n 評価指標:MRR@10, 把持・タスク成功率 LTRRIE [兼田+, JSAI23] n REVERIE [Qi+, CVPR20] から指示 文を収集 n Matterport3D Simulator [Chang+, 3DV17] から画像を収集 図:https://yuankaiqi.github.io/REVERIE_Challenge/static/img/demo.gif 物体を移動させるような 英語の指示文 (5501文)
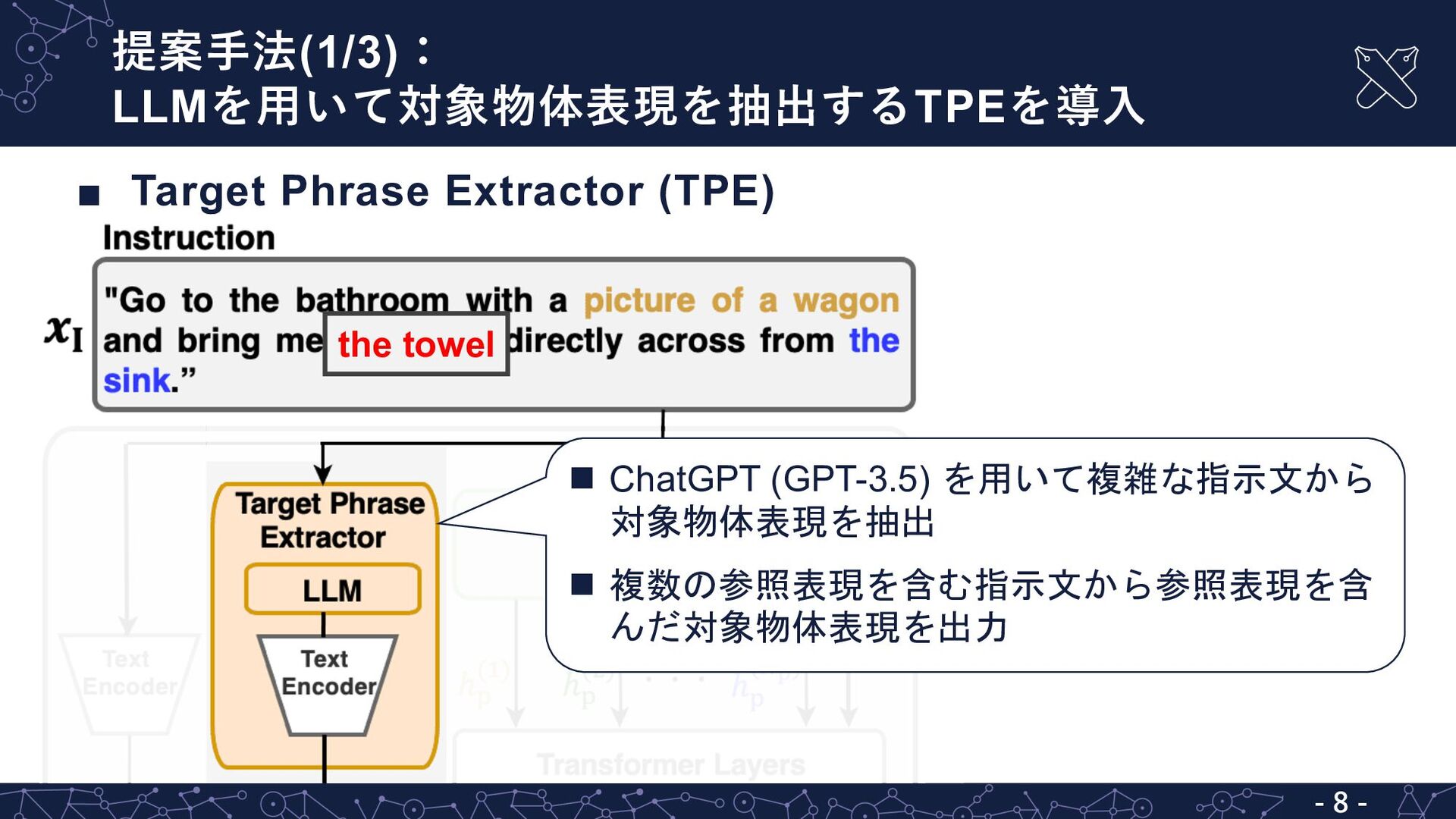
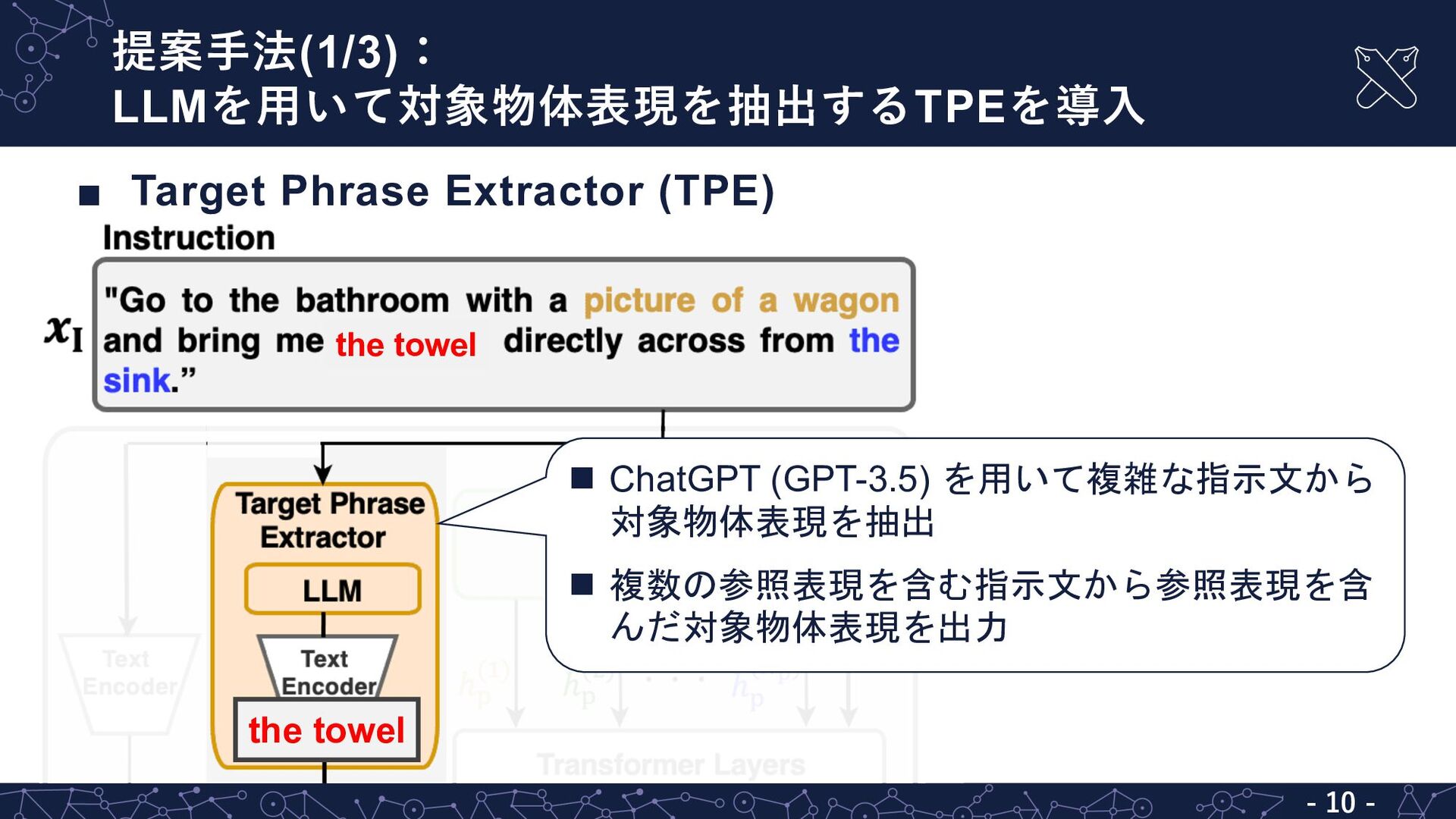
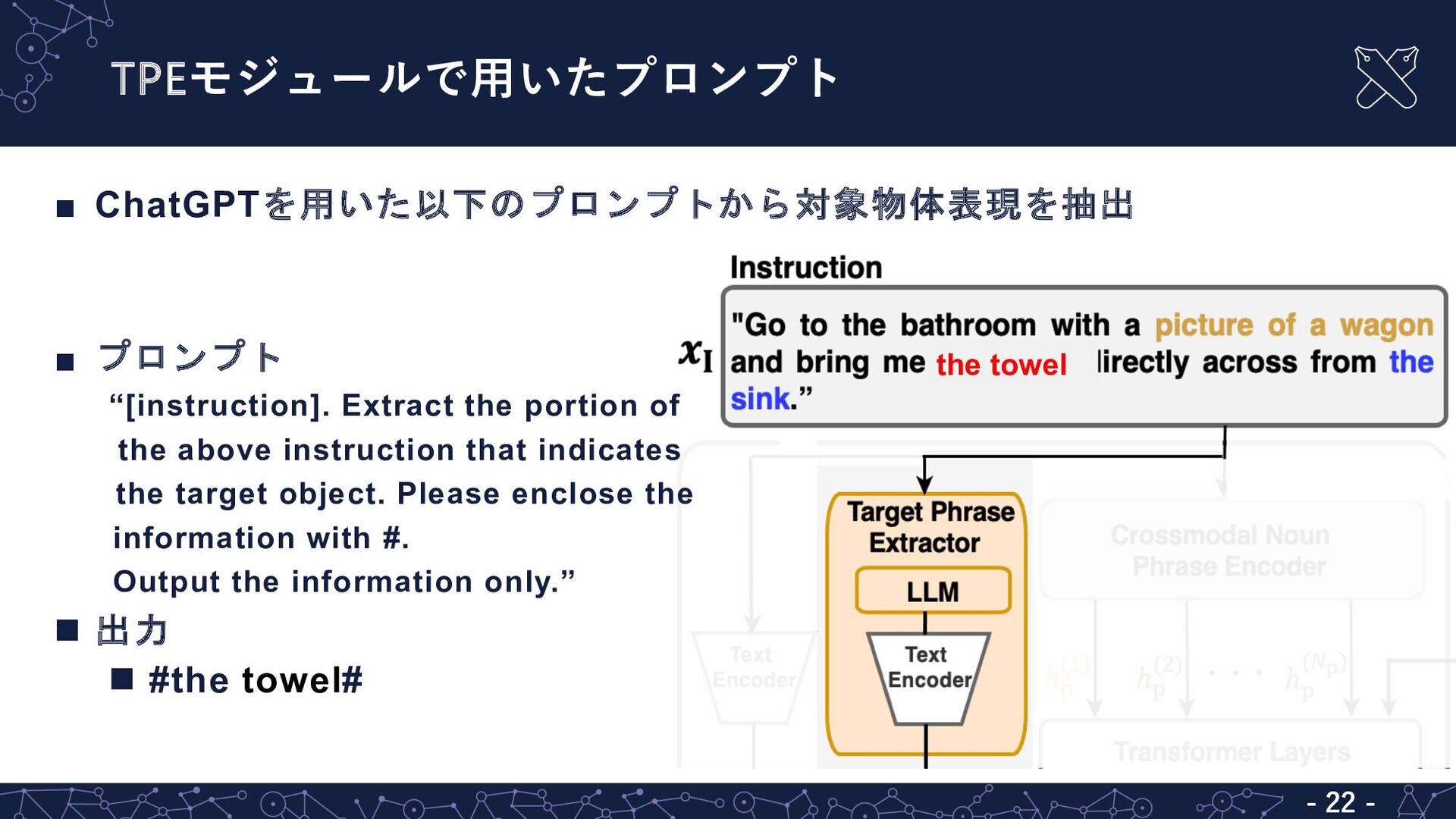
“[instruction]. Extract the portion of the above instruction that indicates the target object. Please enclose the information with #. Output the information only.” n 出力 n #the towel#
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
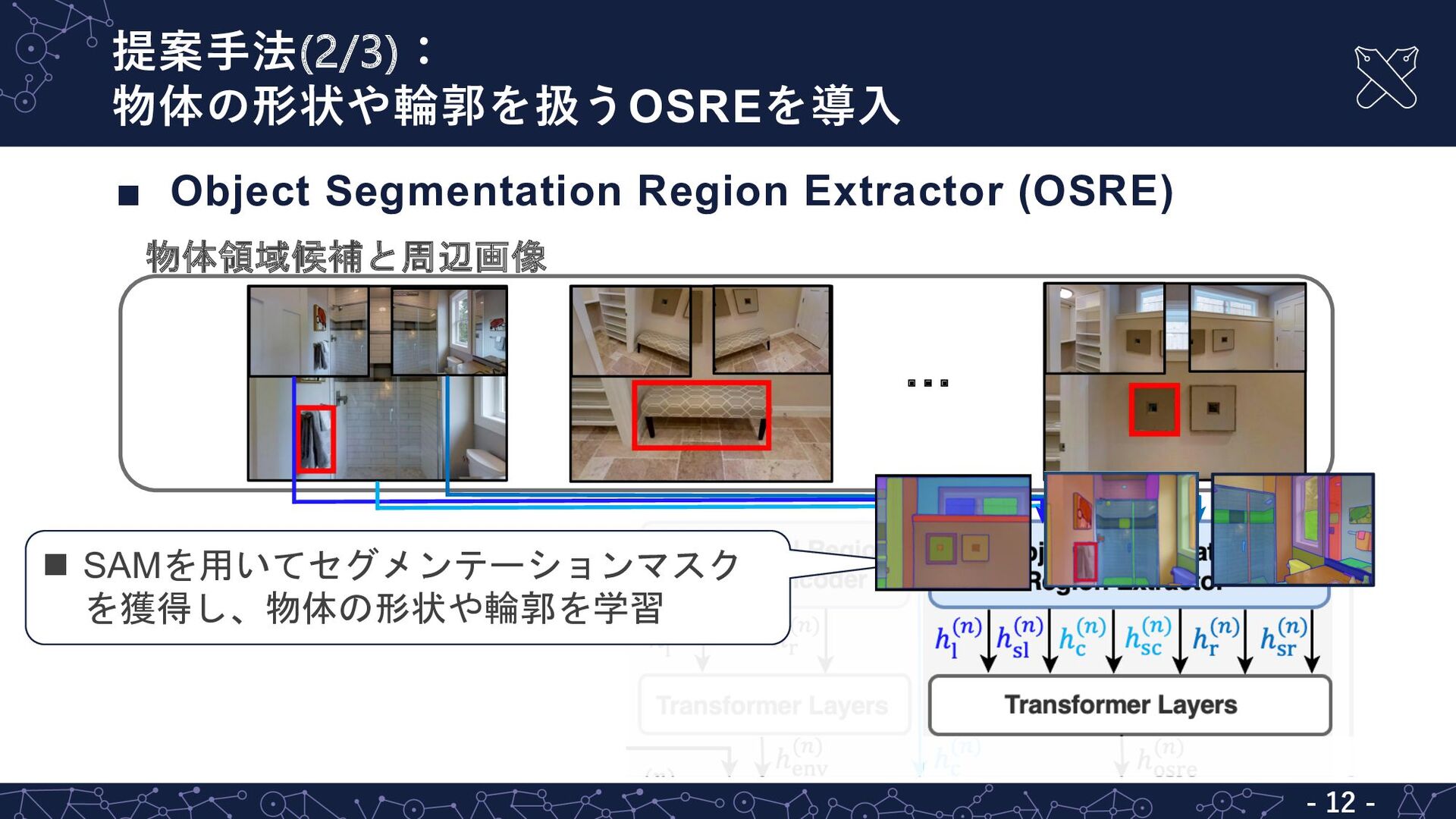
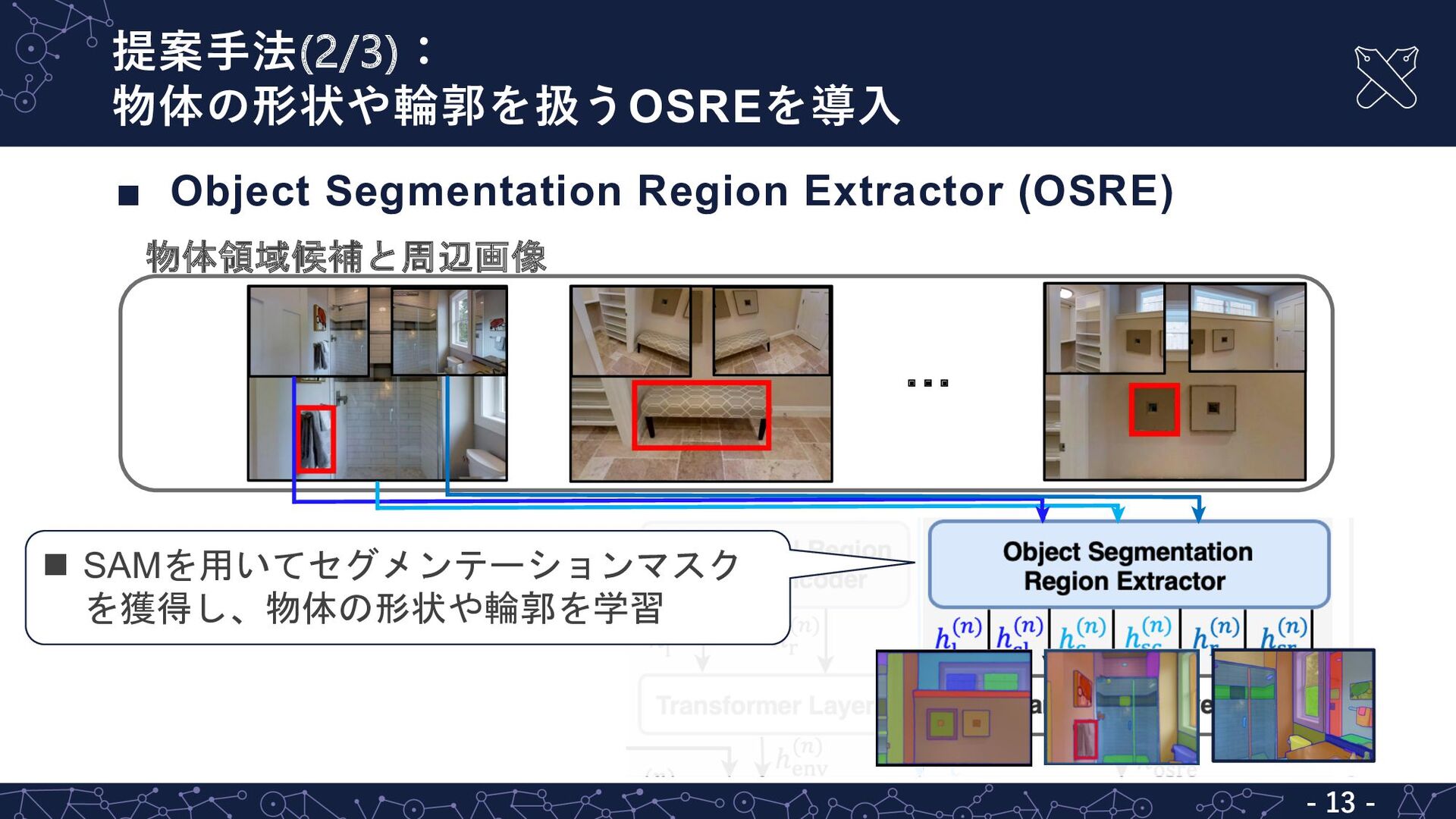
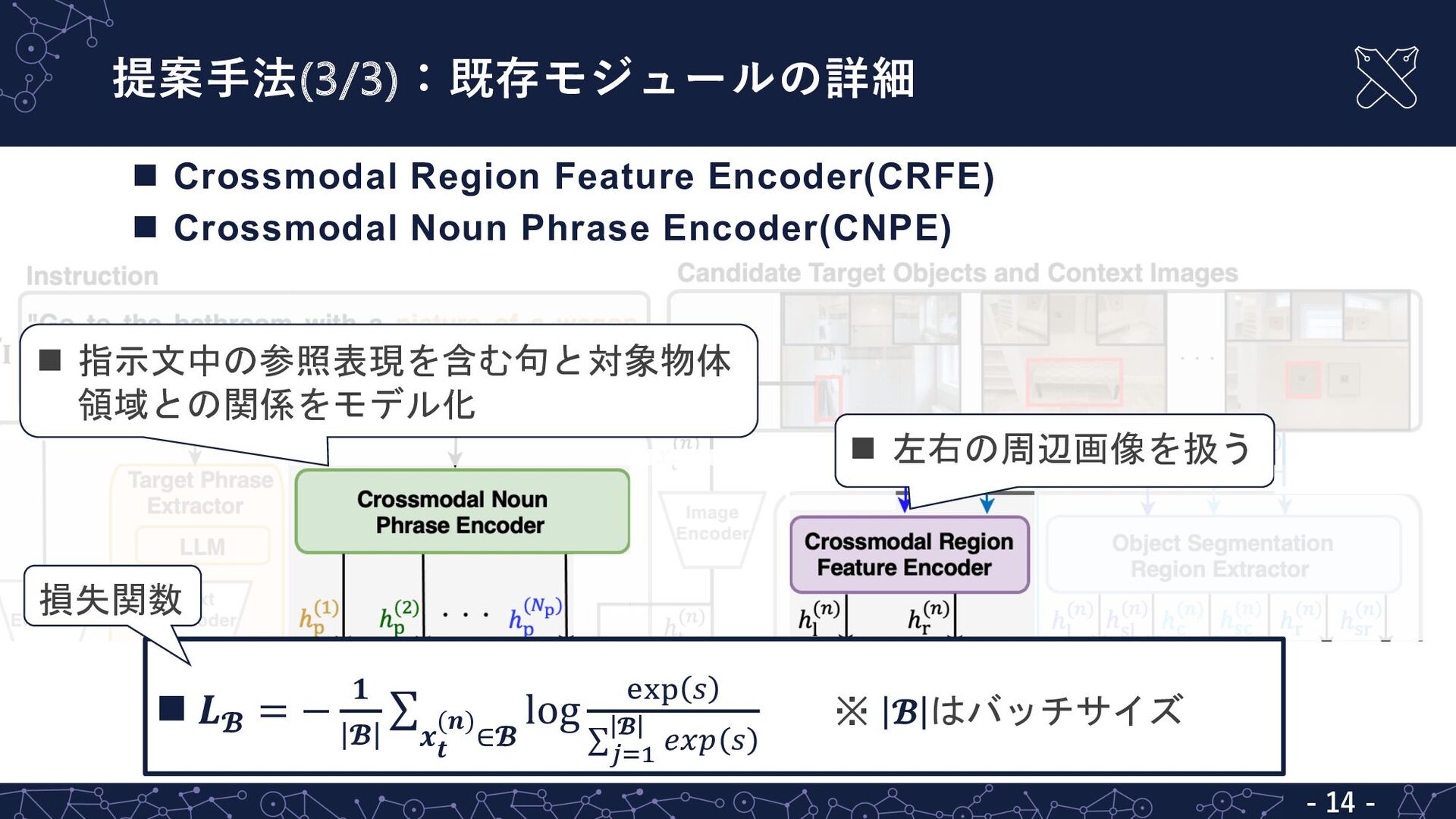
![既存⼿法の問題点:指⽰⽂からの対象物体表現の特定は困難 - 6 - MultiRankIt [兼田+, JSAI23] L 複数の候補を含む指示文からの対象物体表現の特定が困難 ▪](https://files.speakerdeck.com/presentations/14311097ebc6470cbc267000a3d3280b/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果: 全ての評価尺度においてベースライン手法を上回る - 16 - [%] MRR ↑ Recall@5 ↑](https://files.speakerdeck.com/presentations/14311097ebc6470cbc267000a3d3280b/slide_15.jpg){kind=link}
{kind=link}
![Ablation Studies:TPEの導⼊が最も性能向上に寄与 - 18 - J 新規モジュールの有効性を確認 J 対象物体表現を抽出するTPEの導入が最も性能向上に寄与 [%]](https://files.speakerdeck.com/presentations/14311097ebc6470cbc267000a3d3280b/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
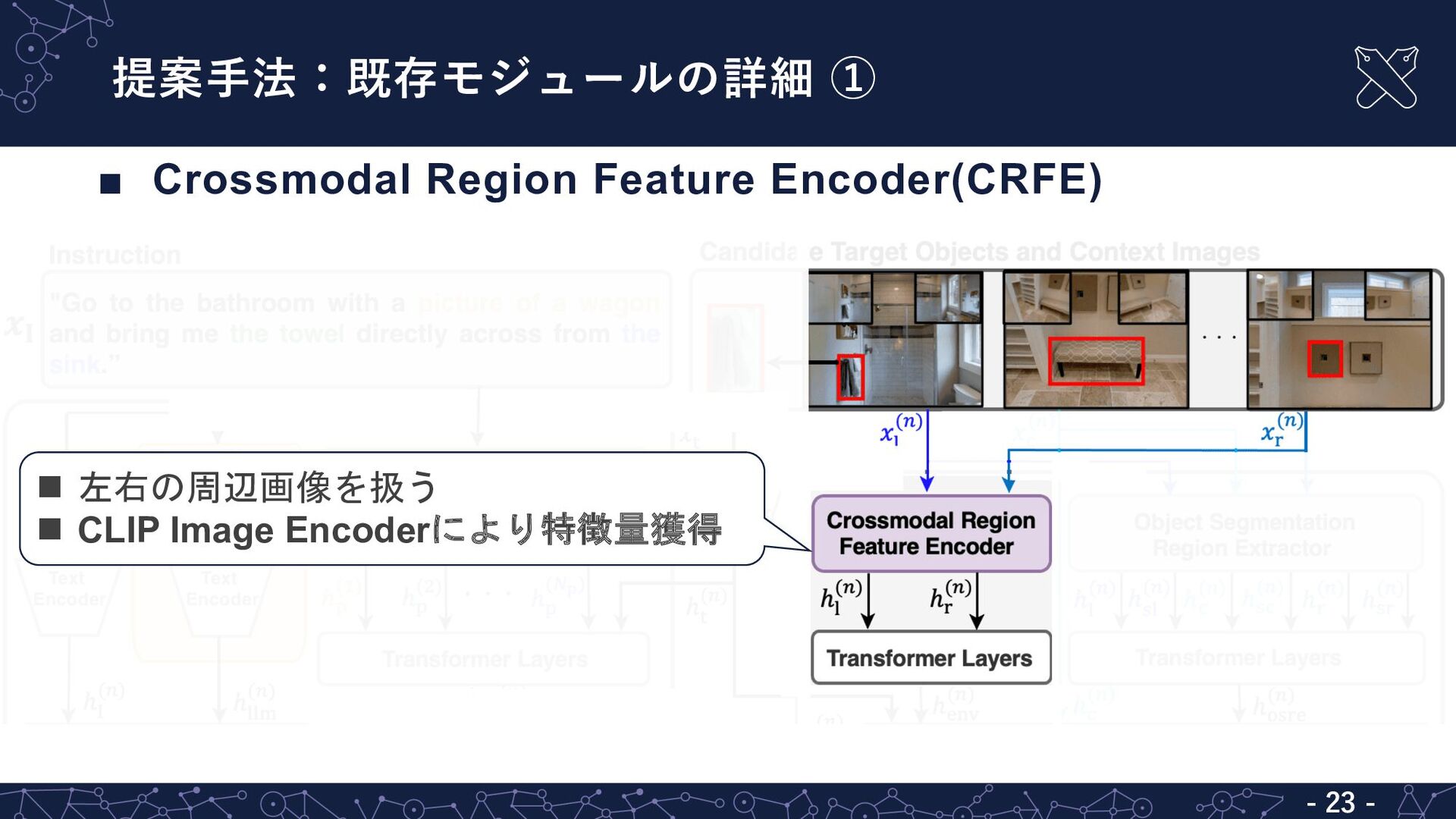{kind=link}
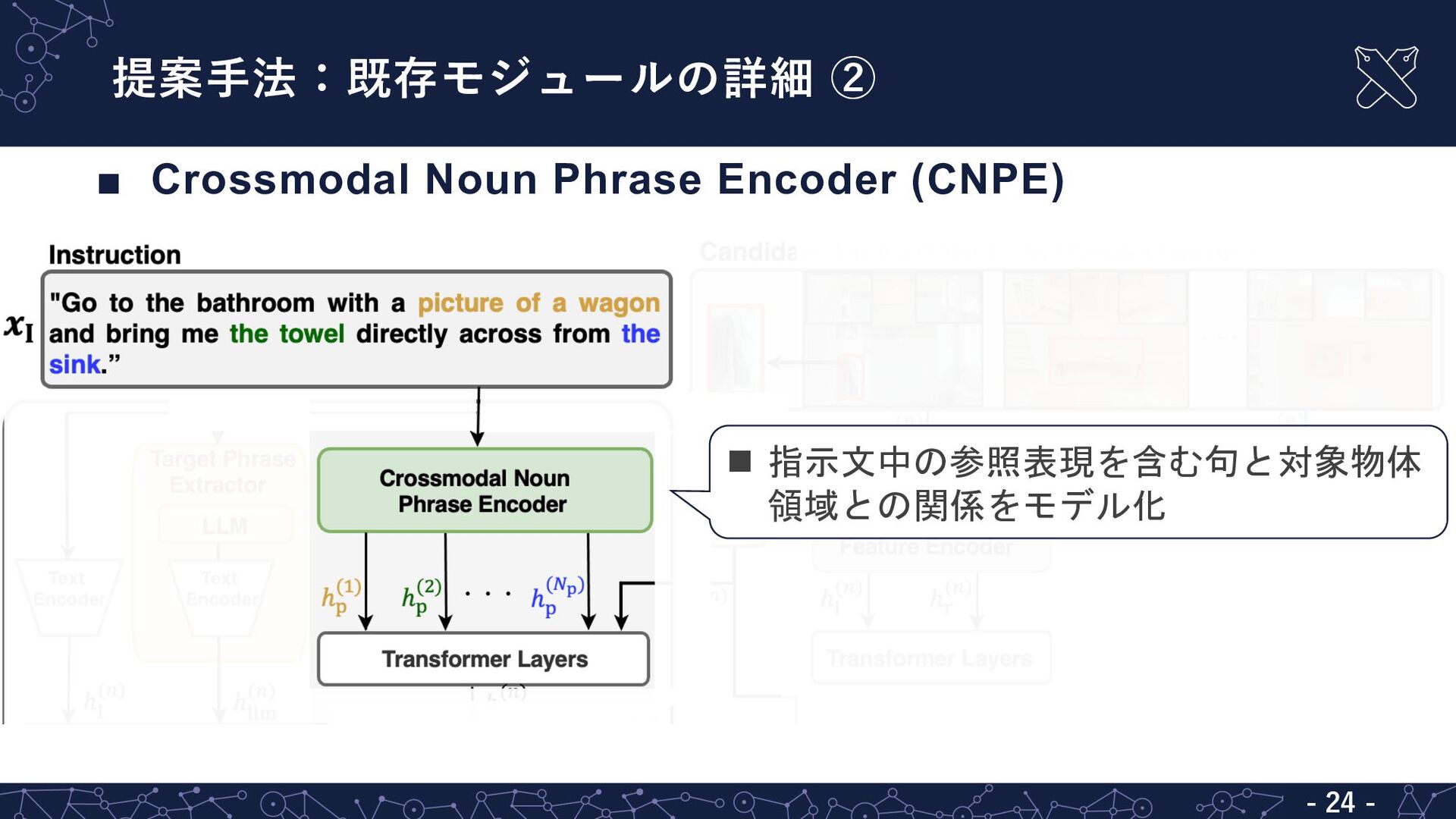{kind=link}
{kind=link}
![LTRRIE データセットの詳細 - 26 - LTRRIE データセット [兼田+, JSAI23] n](https://files.speakerdeck.com/presentations/14311097ebc6470cbc267000a3d3280b/slide_25.jpg){kind=link}
{kind=link}