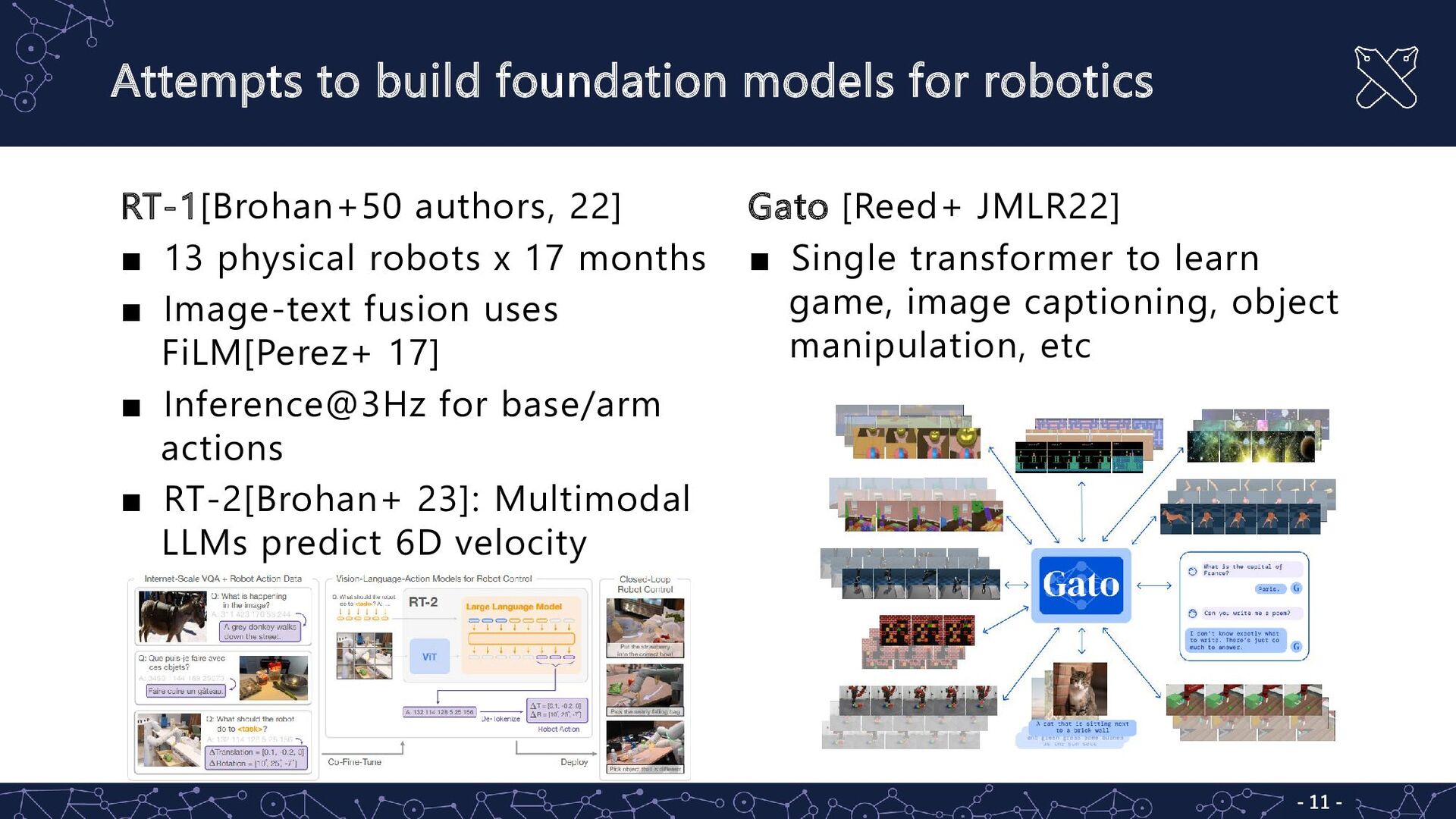
Foundation models: Trained on broad data at scale and are adaptable to a wide range of downstream tasks* ▪ e.g. BERT, GPT-3, CLIP ▪ Impact of foundation models to Robotics: Major ▪ Robustness for unseen situations (Zero-shot/few-shot) ▪ Easily usable for non-experts of NLP/CV ▪ Impact of robotics to foundation models: Minor ▪ RT-1/2 ▪ (Future) Self-driving cars, automated experiments, … *Bommasani et al, “On the Opportunities and Risks of Foundation Models”, 2021.
5 Code as Policies [Liang+ 22] LLM generates sequence of atomic actions (sensing & action) ChatGPT for Robotics [Vemprala+ 23] Humans give feedback to interactively generate control code TidyBot [Wu+ AR-IROS23] Recognizes target objects by CLIP and generates code (including receptacles) by LLM Situation information is manually given ▪ e.g. objects = ["yellow shirt", "black shirt”, ..]
image-text pairs ▪ CLIPInfoNCE loss, OTTER[Wu+ ICLR22]optimal transport ▪ Many applications (e.g. DALL·E 2+ 22] ) a photo of a beer bottle satellite imagery of roundabout a photo of a marimba a meme Text Text feat. Image feat. Image https://vimeo.com/692375454
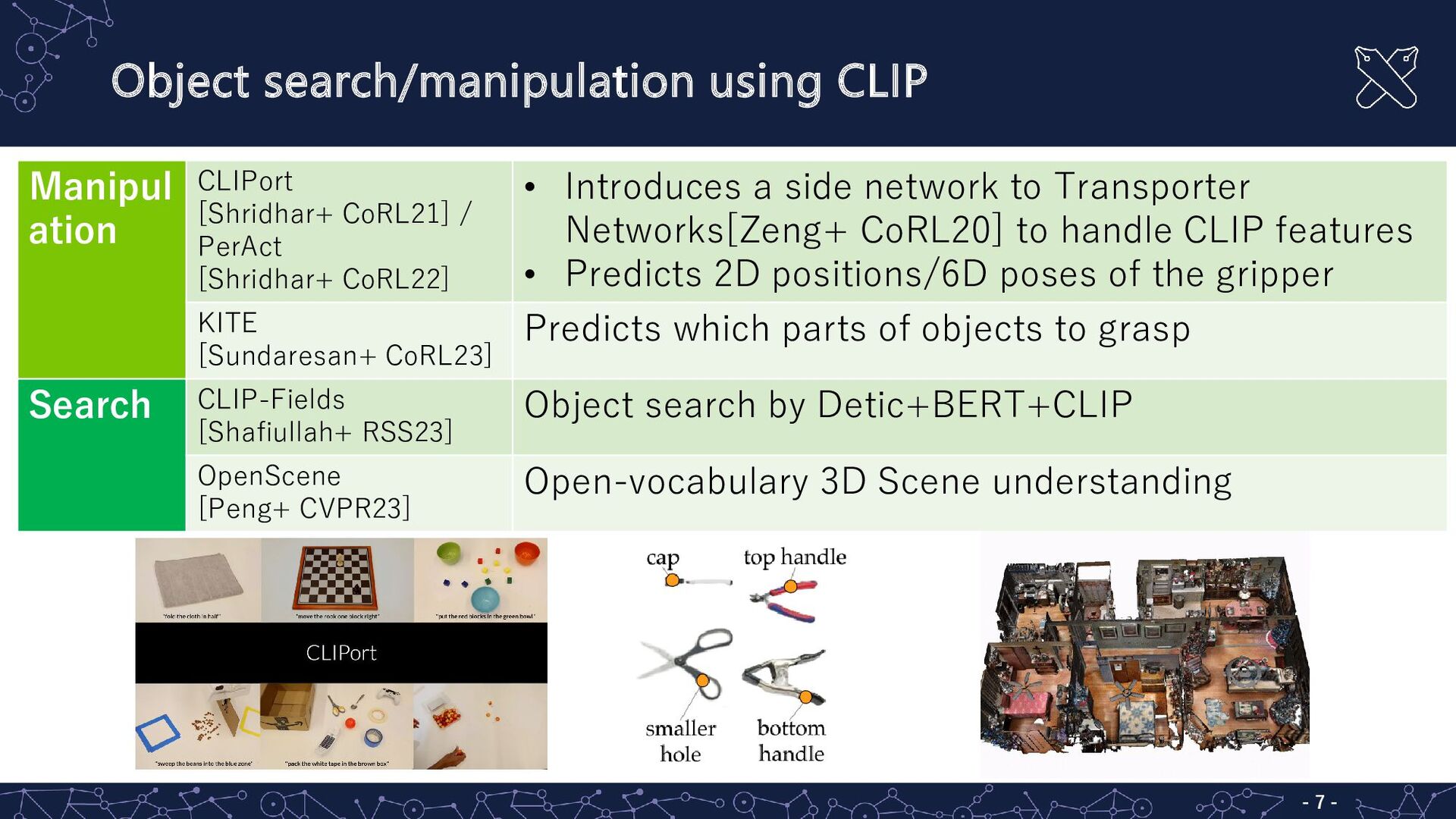
[Shridhar+ CoRL21] / PerAct [Shridhar+ CoRL22] • Introduces a side network to Transporter Networks[Zeng+ CoRL20] to handle CLIP features • Predicts 2D positions/6D poses of the gripper KITE [Sundaresan+ CoRL23] Predicts which parts of objects to grasp Search CLIP-Fields [Shafiullah+ RSS23] Object search by Detic+BERT+CLIP OpenScene [Peng+ CVPR23] Open-vocabulary 3D Scene understanding
1D feature vector ▪ Easy ▪ model.encode_image(image) ▪ Positional information is lost ▪ Additional information is required to handle e.g. “A is left of B” Text Text feat. Image feat. Image
1D feature vector ▪ Easy ▪ model.encode_image(image) ▪ Positional information is lost ▪ Additional information is required to handle e.g. “A is left of B” 2D feature map ▪ Extract intermediate output from ResNet/ViT in CLIP ▪ E.g. 28 x 28 x 512 ▪ Typical work ▪ CLIPort [Shridhar+ CoRL21], CRIS [Wang+ CVPR22], SAN [Mengde+ CVPR23] Text Text feat. Image feat. Image Text Text feat. Image feat. Image
12 RoboCup@Home(2006-) ▪ Largest benchmarking test for domestic service robots HomeRobot [Yenamandra+ CoRL23] ▪ Open-vocabulary mobile manipulation ▪ Competition at NeurIPS23
environments” ▪ General Purpose Service Robots test (2010-) ▪ As difficult as tasks handled by RT-2/PaLM SayCan ▪ Almost solved by foundation models in 2023 ▪ We won 1st places (2008 & 2010), second places (2009 & 2012) L. Iocchi et al, "RoboCup@Home: Analysis and Results of Evolving Competitions for Domestic and Service Robots," Artificial Intelligence, Vol. 229, pp. 258-281, 2015.
Decrease in the working-age population that supports those who need assistance • Training an assistance dog takes two years I need to leave work to support my family… I can't manage to care for an assistance dog. What challenges arise to build language interfaces? If options are plentiful, touch panels may be inconvenient.
Analyzed tasks defined by IAADP* ▪ Out of 108 subtasks, 50 subtasks are doable by HSR ▪ Metrics ▪ Task coverage: 80% ▪ Success rate: 80% *International Association of Assistance Dog Partners
bathroom with a picture of a wagon and bring me the towel directly across from the sink” Rank: 1 Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6 … Rank: 1 Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6 … Instruction: “Go to the hallway on level 1 that is lined with wine bottles and pull out the high chair closest to the wine bottles at the second table from the door”
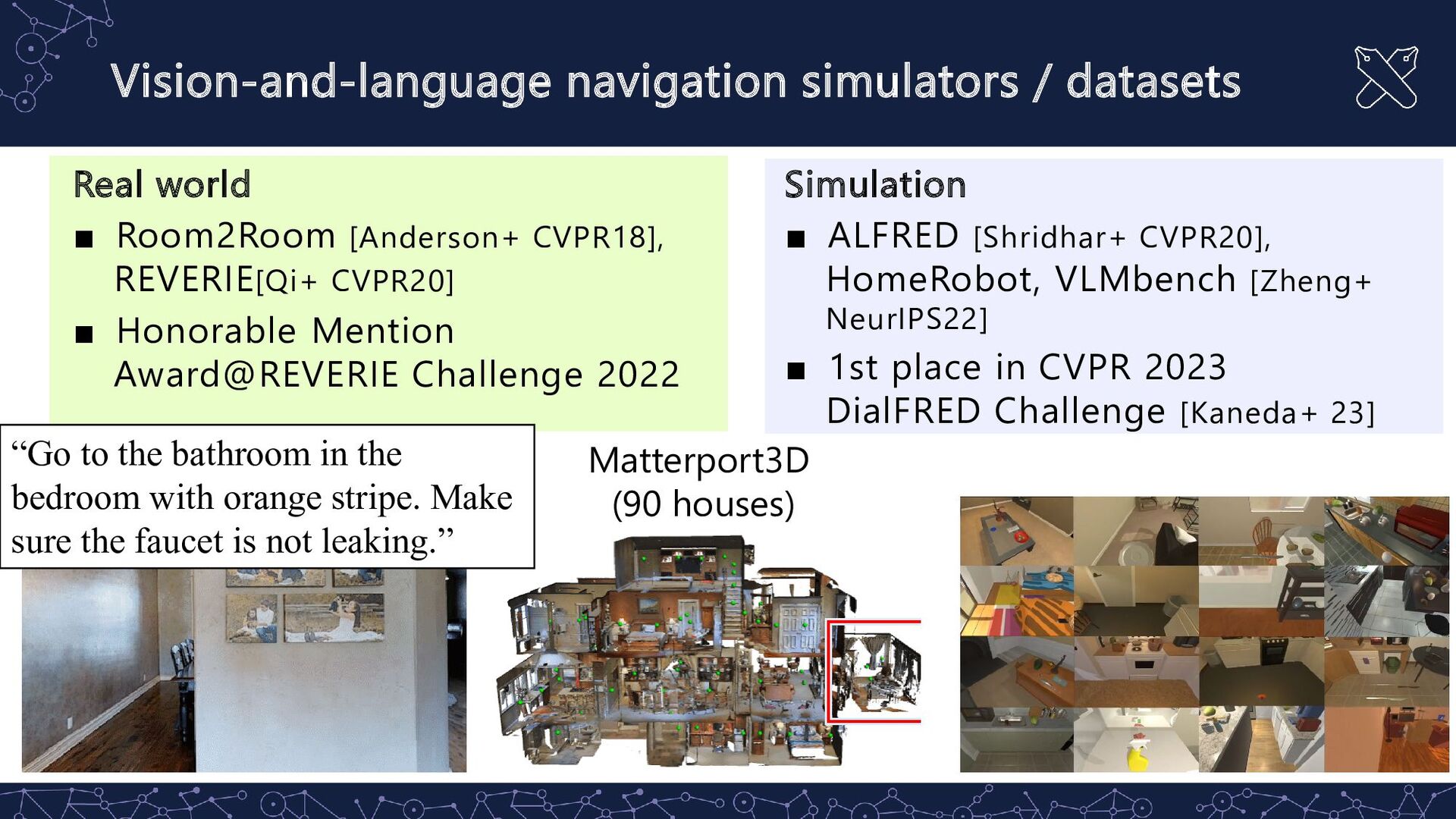
CVPR18], REVERIE[Qi+ CVPR20] ▪ Honorable Mention Award@REVERIE Challenge 2022 Simulation ▪ ALFRED [Shridhar+ CVPR20], HomeRobot, VLMbench [Zheng+ NeurIPS22] ▪ 1st place in CVPR 2023 DialFRED Challenge [Kaneda+ 23] VLN-BERT Matterport3D (90 houses) “Go to the bathroom in the bedroom with orange stripe. Make sure the faucet is not leaking.”
Predict target region (stuff) based on landmark (thing) Proposed method ▪ Trimodal architecture ▪ Introduces day-night branch to estimate mask quality Mean IoU [Rufus+ IROS21] 32.71±4.59 Ours 37.61±2.73 - 23 - “pull in behind the blue van on the left side.”
head-tail enables the model to predict target and receptacle with a single model ▪ 𝑂𝑂(𝑀𝑀 × 𝑁𝑁) 𝑂𝑂(𝑀𝑀 + 𝑁𝑁) ▪ Task success: 89% Put the red chips can on the white table with the soccer ball on it.
contrastive transfer learning [Otsuki+ IROS23] ▪ Sim2Real for language comprehension Multimodal diffusion segmentation model [Iioka+ IROS23] ▪ Instruction understanding and segmentation
Lambda ABN [Iida+ ACCV22] - Explanation generation using branch structures for CNNs - ABN for lambda networks Attention Rollout [Abnar+, 20] Explanation generation method based on QKV attention [Petsiuk+, BMCV18] Generic method for explanation generation (RISE) https://vitalab.github.io/article/2019/07/18/attention-branch-network.html RISE Attention rollout Lambda ABN Explanation generation for solar flare prediction
IROS2020] [Kambara+ IEEE RAL & IROS2021] [Kambara+ IEEE ICIP22] Motivation: Potential risks should be explained to operators in advance Method: Extended relational self attention [Kim+ NeurIPS21] for future captioning Results: Our method outperformed MART[Lei+ ACL2020] on YouCook2 and collision explanation tasks 33 "The robot might hit the hourglass. Should we cancel the action?"
Robot hits the camera from above because robot tried to put the white bottle where it is MART [Lei, ACL20] Robot hits a black teapot because robot tried to put a round white bottle Ours Robot hits the camera hard because robot tried to put a white jar t t+ 1
Reference Rub flour onto the chicken dip it in egg and coat with breadcrumbs MART [Lei, ACL20] Coat the chicken in the flour Ours Coat the chicken with flour and breadcrumbs Missing information t-2 t-1 t t+1
▪ Automatic evaluation is essential for development of image captioning models ▪ cf. machine translation ▪ Human evaluation is labor-intensive for daily development
Japanese language do not correlate well with human evaluations Novelty: graph matching based on predicate-argument structure Collected 22,350 samples collected from 100 subjects
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CLIP[Radford+ 21]: Vision-language foundation model ▪ Contrastive learning on 400M](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RoboCup@Home [Iocchi+ AI15] - - 13 ▪ Includes real ”real](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CrossMap Transformer: A masked [language, vision, path] model [Magassouba+ RAL](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_21.jpg){kind=link}
![Vision-and-language navigation for personal mobility Task: Talk2Car [Rufus+ IROS21] ▪](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Switching Head-tail Funnel UNITER [Korekata+ IROS23] 27 Novelty ▪ Switching](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![PonNet: Predicting and explaining collisions [Magassouba+ Advanced Robotics 2021] Background:](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_30.jpg){kind=link}
![Related Works - - 32 Attention Branch Network [Fukui+, CVPR19],](https://files.speakerdeck.com/presentations/48a36a9ede47429b8c4d564fd4d58145/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}