the music the moment you own it you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002) 3 / 42
the music the moment you own it you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002) 3 / 42
the music [-ɪk] ? [ɔi] the moment you own it [-ɪt] ? [ai] you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002) 3 / 42
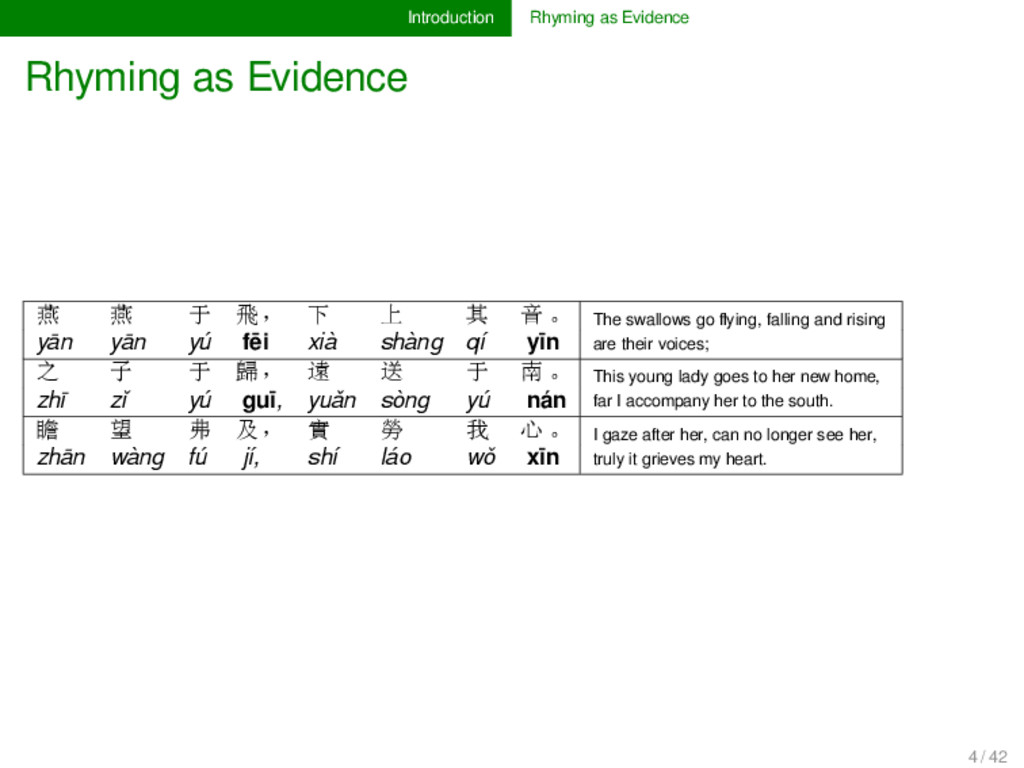
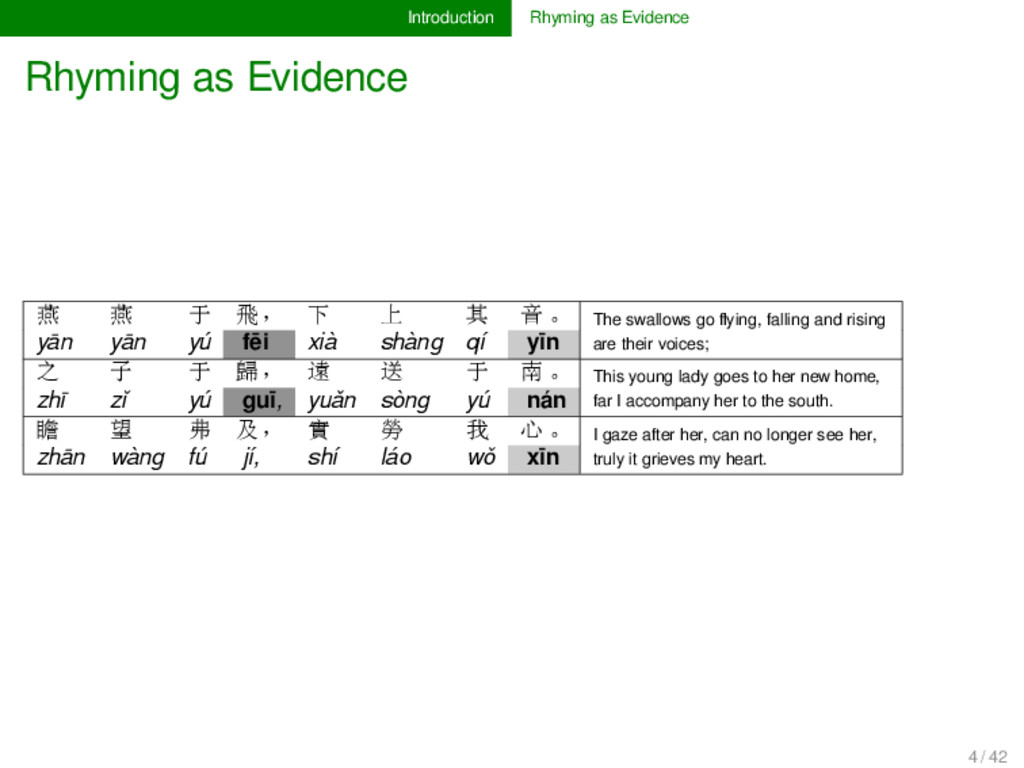
飛, 下 上 其 音。 The swallows go flying, falling and rising are their voices; yān yān yú fēi xià shàng qí yīn 之 子 于 歸, 遠 送 于 南。 This young lady goes to her new home, far I accompany her to the south. zhī zǐ yú guī, yuǎn sòng yú nán 瞻 望 弗 及, 實 勞 我 心。 I gaze after her, can no longer see her, truly it grieves my heart. zhān wàng fú jí, shí láo wǒ xīn 4 / 42
飛, 下 上 其 音。 The swallows go flying, falling and rising are their voices; yān yān yú fēi xià shàng qí yīn 之 子 于 歸, 遠 送 于 南。 This young lady goes to her new home, far I accompany her to the south. zhī zǐ yú guī, yuǎn sòng yú nán 瞻 望 弗 及, 實 勞 我 心。 I gaze after her, can no longer see her, truly it grieves my heart. zhān wàng fú jí, shí láo wǒ xīn 4 / 42
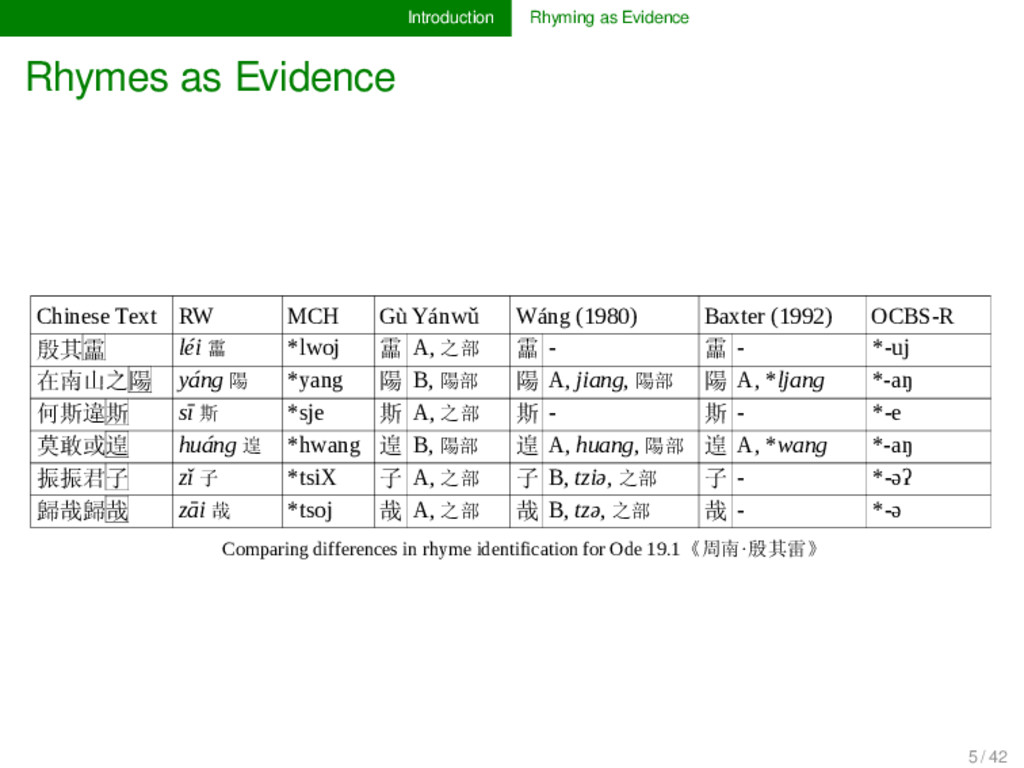
difficulty to judge rhyme evidence, specifically, for unattested, reconstructed languages, as we cannot directly query the speakers. Given that poetry in general is influenced by multiple factors, in- cluding the language system, the structure of the soci- ety, and human cognition in general, it is difficult for us to disentangle which factors we are dealing with under which situations. 6 / 42
linguistic reconstruction in China (starting with Chén Dì 陳第, 1541 – 1606), breakthrough in the early 20th century with Karlgren’s reconstructions and impressive work by Wáng Lí 王力 (1980) and Li Fang-kuei 李方桂 (1971), 7 / 42
linguistic reconstruction in China (starting with Chén Dì 陳第, 1541 – 1606), breakthrough in the early 20th century with Karlgren’s reconstructions and impressive work by Wáng Lí 王力 (1980) and Li Fang-kuei 李方桂 (1971), since then more and more improved concrete reconstructions of Old Chinese phonology, 7 / 42
linguistic reconstruction in China (starting with Chén Dì 陳第, 1541 – 1606), breakthrough in the early 20th century with Karlgren’s reconstructions and impressive work by Wáng Lí 王力 (1980) and Li Fang-kuei 李方桂 (1971), since then more and more improved concrete reconstructions of Old Chinese phonology, another breakthrough in the 1980s, when Baxter (1992), Starostin (1989), and Zhèngzhāng Shàngfāng (see Zhèngzhāng 2003) presented reconstructions in which they independently proposed several similar features (notably six vowels and more rhymes than proposed in the classical analysis) 7 / 42
problem, Old Chinese phonology, al- though representing a highly data-driven discipline, has so far paid little attention to the problem of making lin- guistic data transparently available and comparable. Thus, there exist many different reconstructions for Old Chinese, as well as many different rhyme annotations of the Book of Odes (Shījīng 詩經), but they have never been compared on a large scale. If disciplines rely on multiple different types of evidence, it is crucial that this evidence is handled in a comparable and principled way. 8 / 42
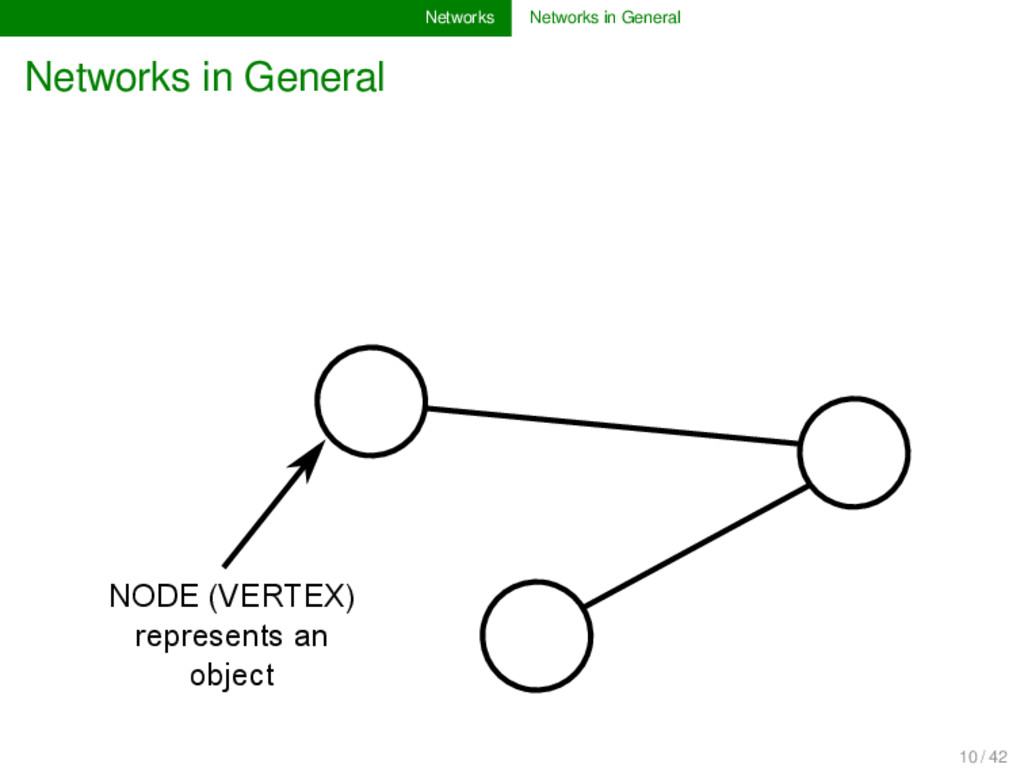
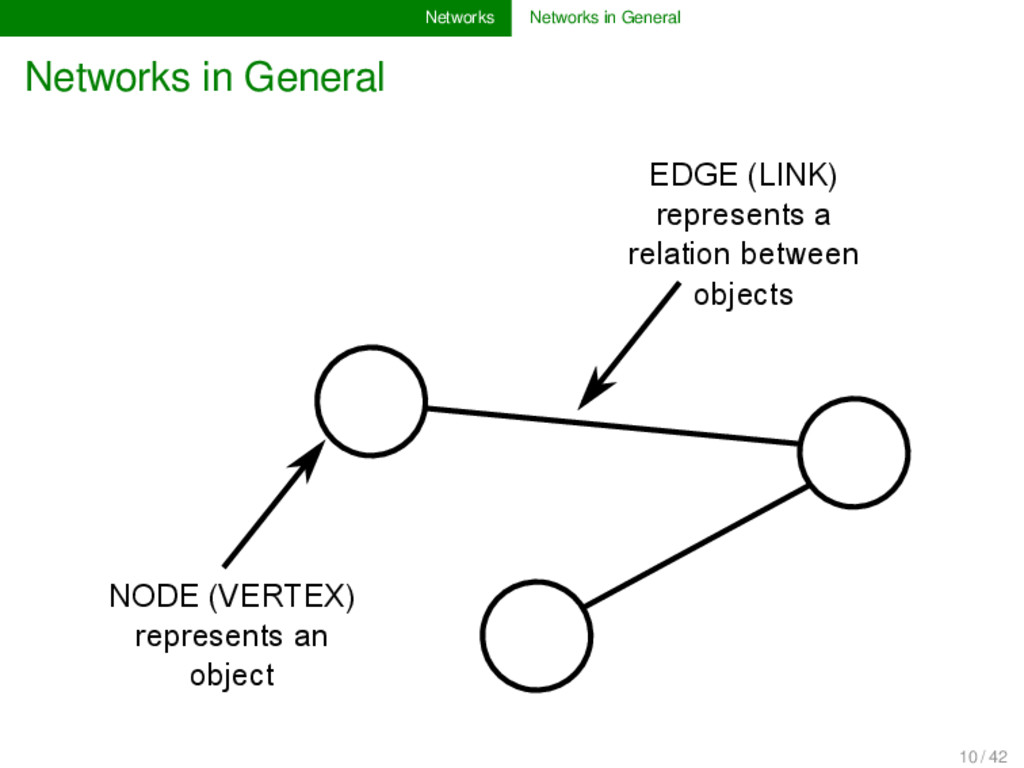
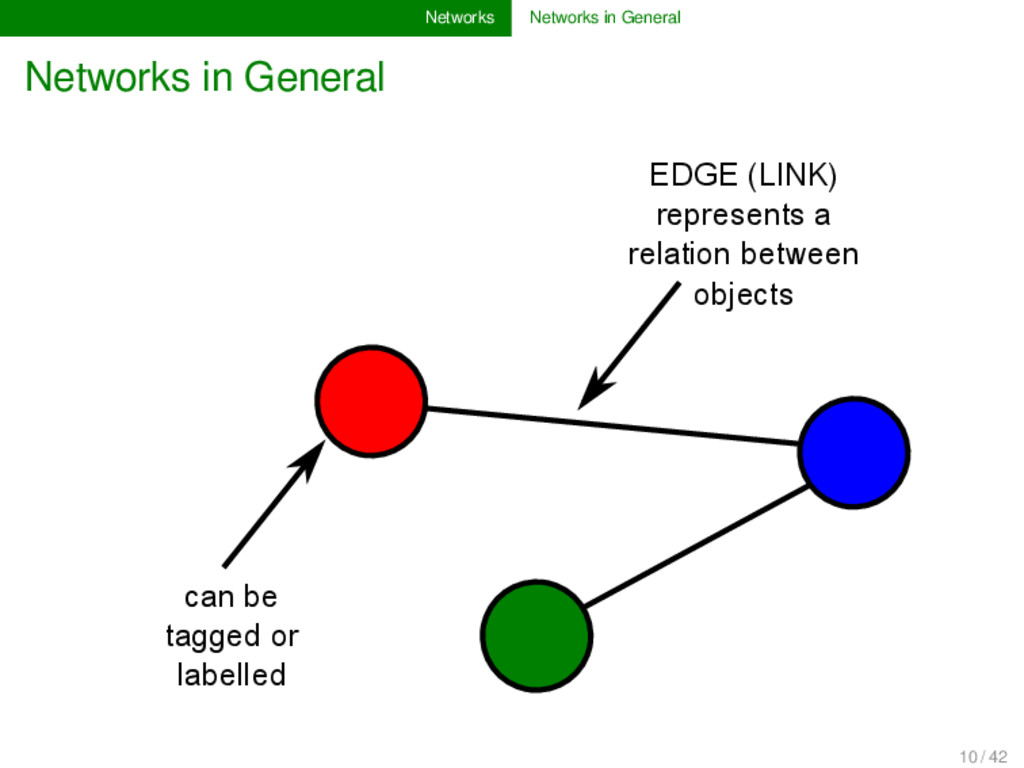
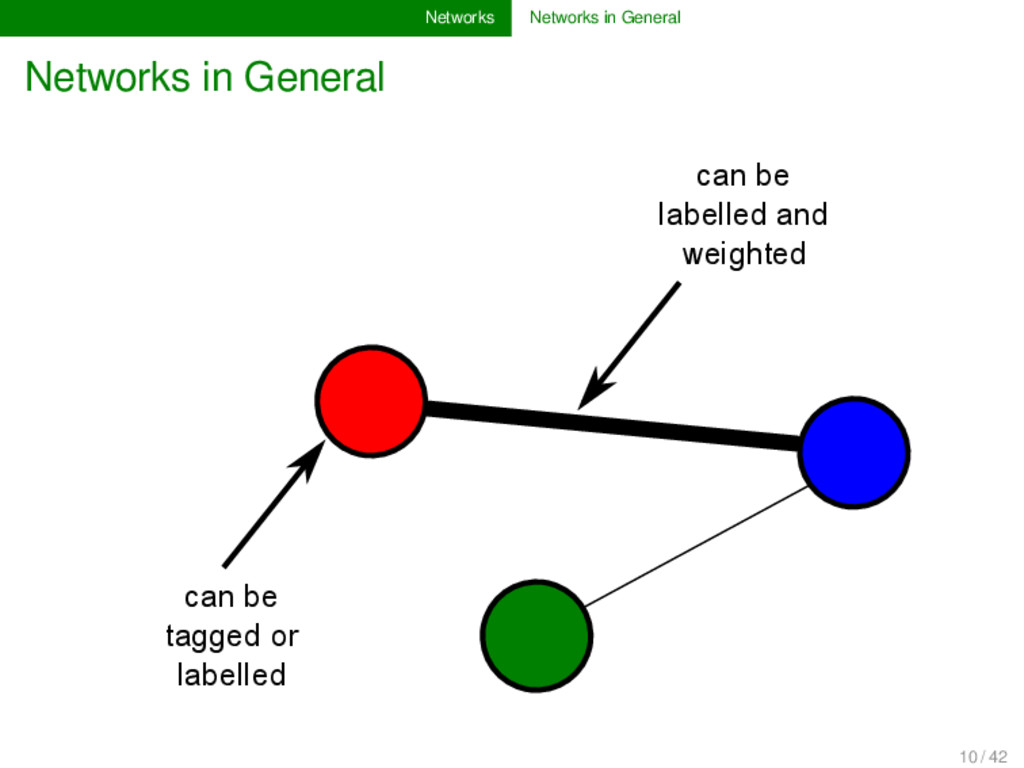
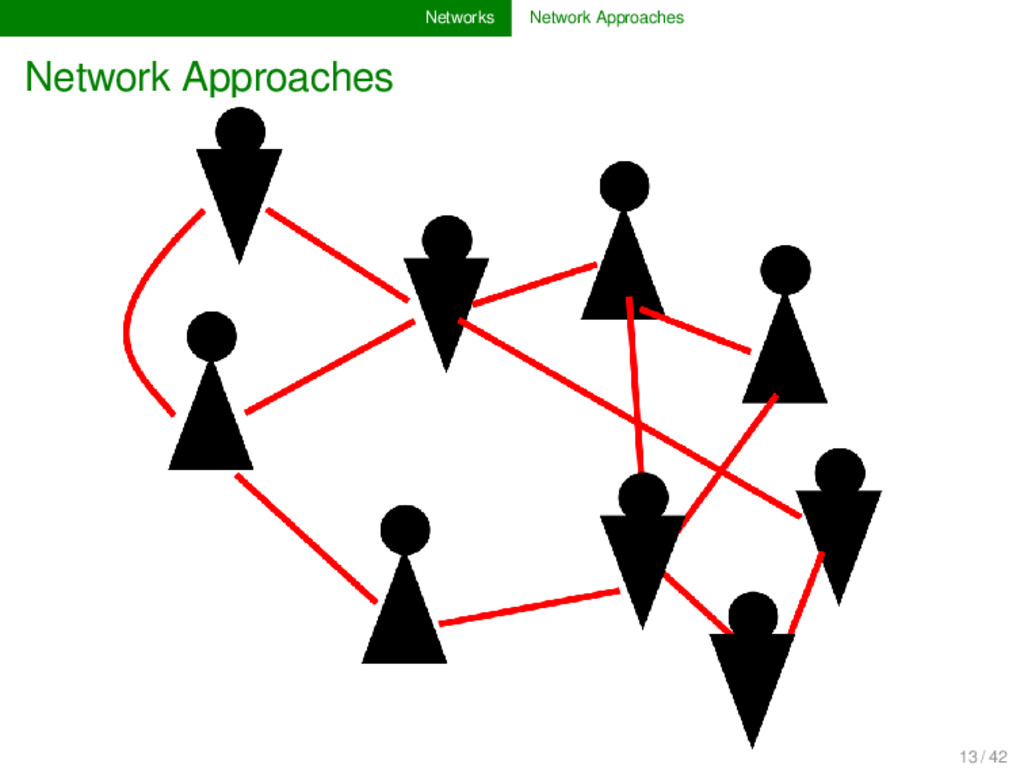
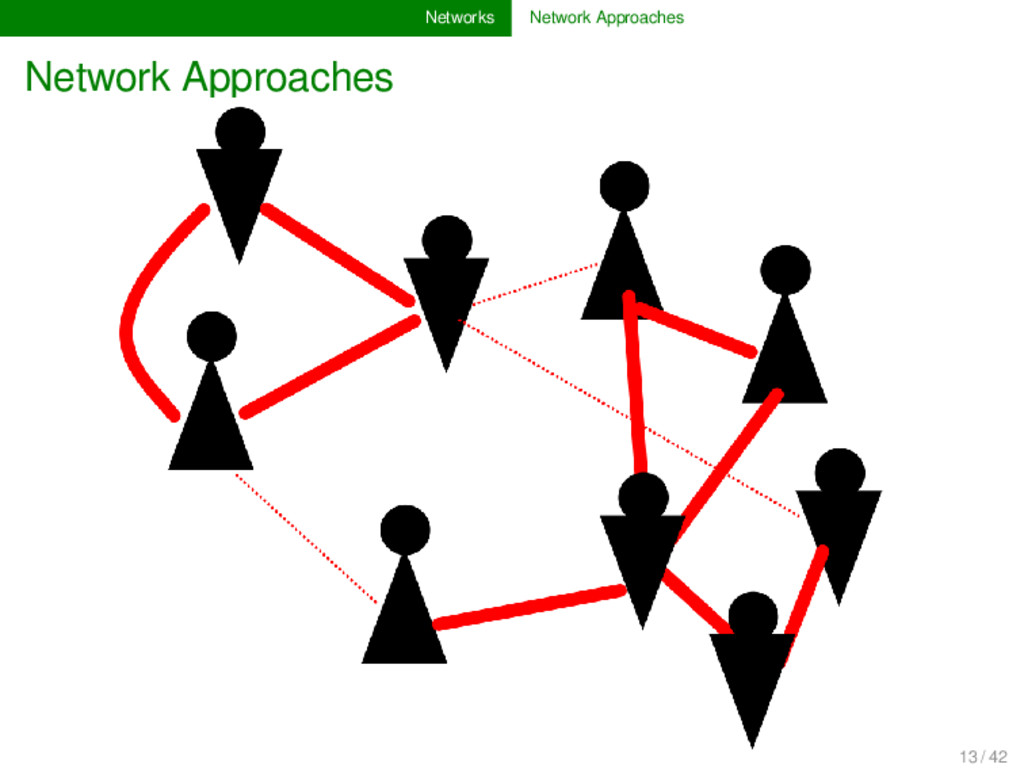
and science can be modeled as networks: social networks: nodes are persons, edges are relations between persons (e.g., friendship on FaceBook, etc.), 11 / 42
and science can be modeled as networks: social networks: nodes are persons, edges are relations between persons (e.g., friendship on FaceBook, etc.), phylogenetic networks: nodes are languages or dialect varieties, edges represent genetic closeness, 11 / 42
and science can be modeled as networks: social networks: nodes are persons, edges are relations between persons (e.g., friendship on FaceBook, etc.), phylogenetic networks: nodes are languages or dialect varieties, edges represent genetic closeness, network of sound change patterns: nodes are sounds, directed edges represent likelihood of sound change during language evolution, 11 / 42
and science can be modeled as networks: social networks: nodes are persons, edges are relations between persons (e.g., friendship on FaceBook, etc.), phylogenetic networks: nodes are languages or dialect varieties, edges represent genetic closeness, network of sound change patterns: nodes are sounds, directed edges represent likelihood of sound change during language evolution, ... 11 / 42
existing networks can be quickly analyzed and we can infer interesting things about their general structure or specific characteristics. The litera- ture on network approaches is abundant, and often it is dif- ficult for scientists to find the right way to tackle their prob- lems. For this reason it is useful to work in an interdisci- plinary and to discuss problems and questions of data han- dling and analysis with network specialists. 12 / 42
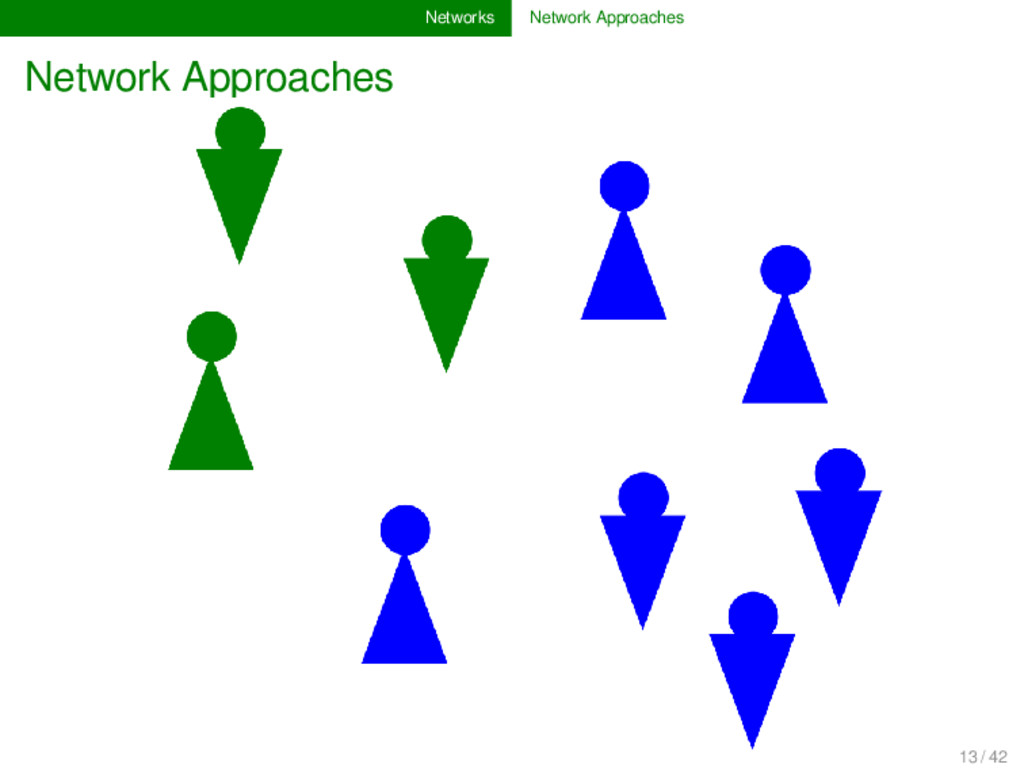
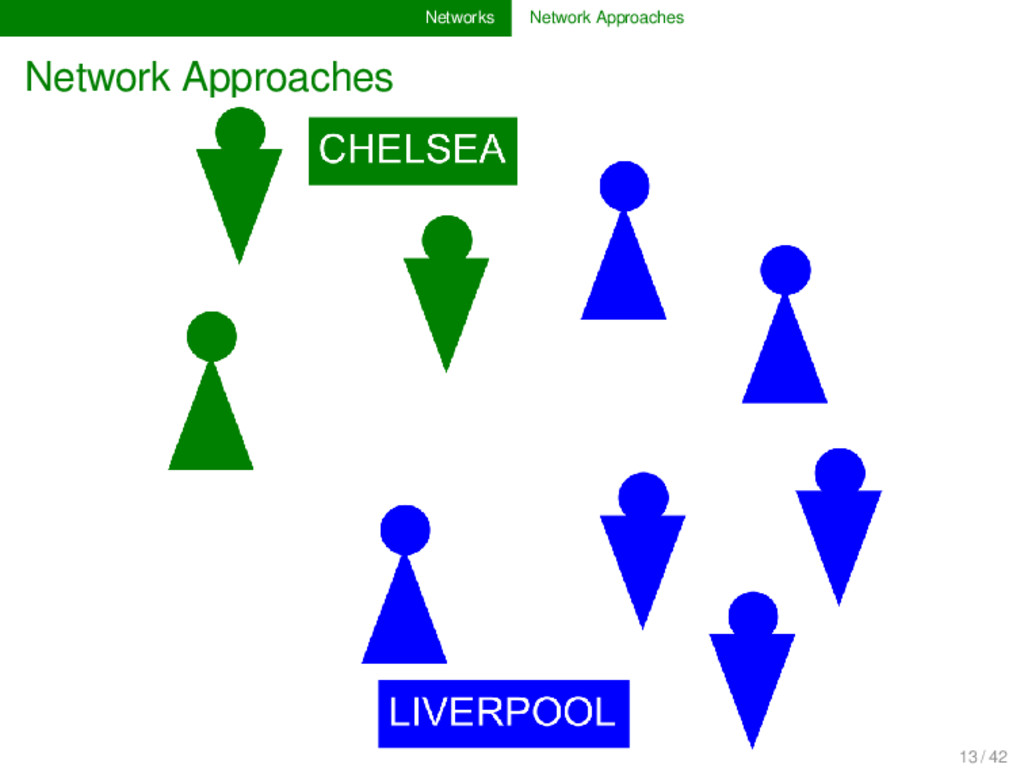
a specific type of par- titioning algorithm. They allow us to partition (cluster) the nodes of a network into different parts. Community detec- tion algorithms are very useful to detect natural groupings in networks. 14 / 42
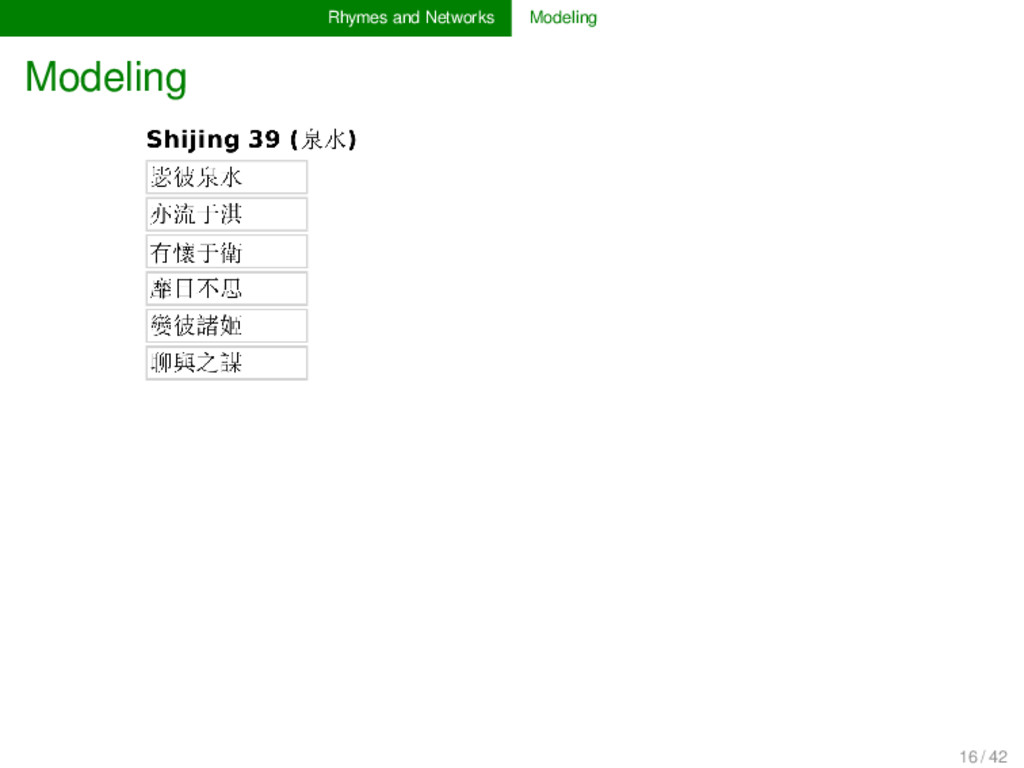
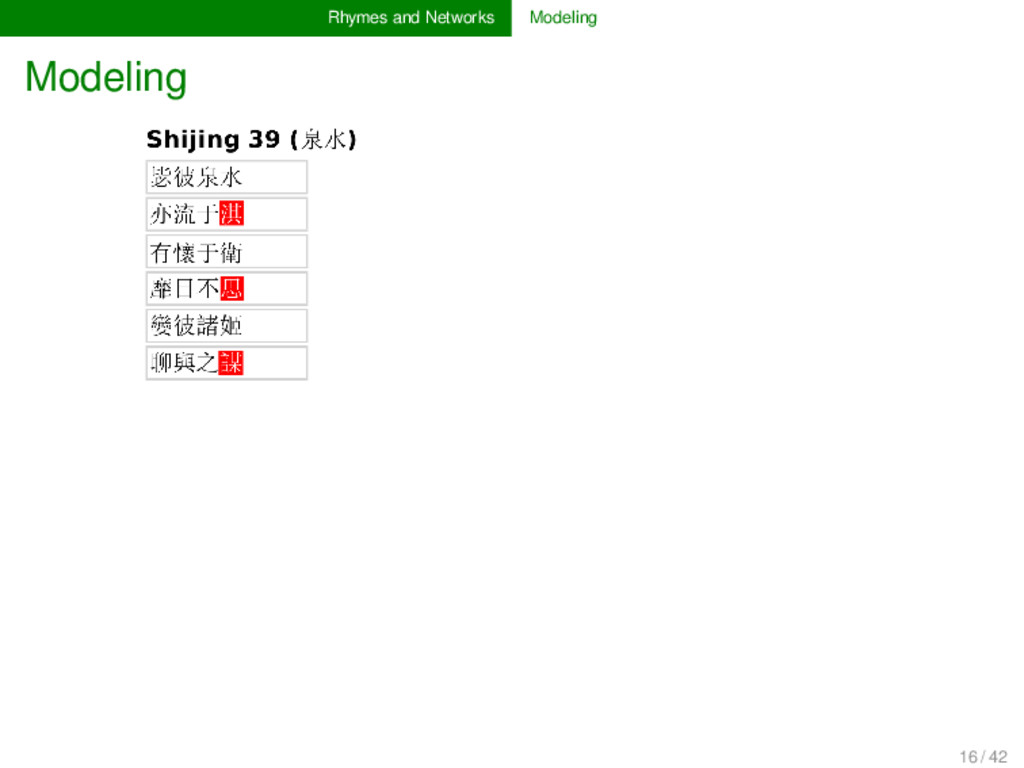
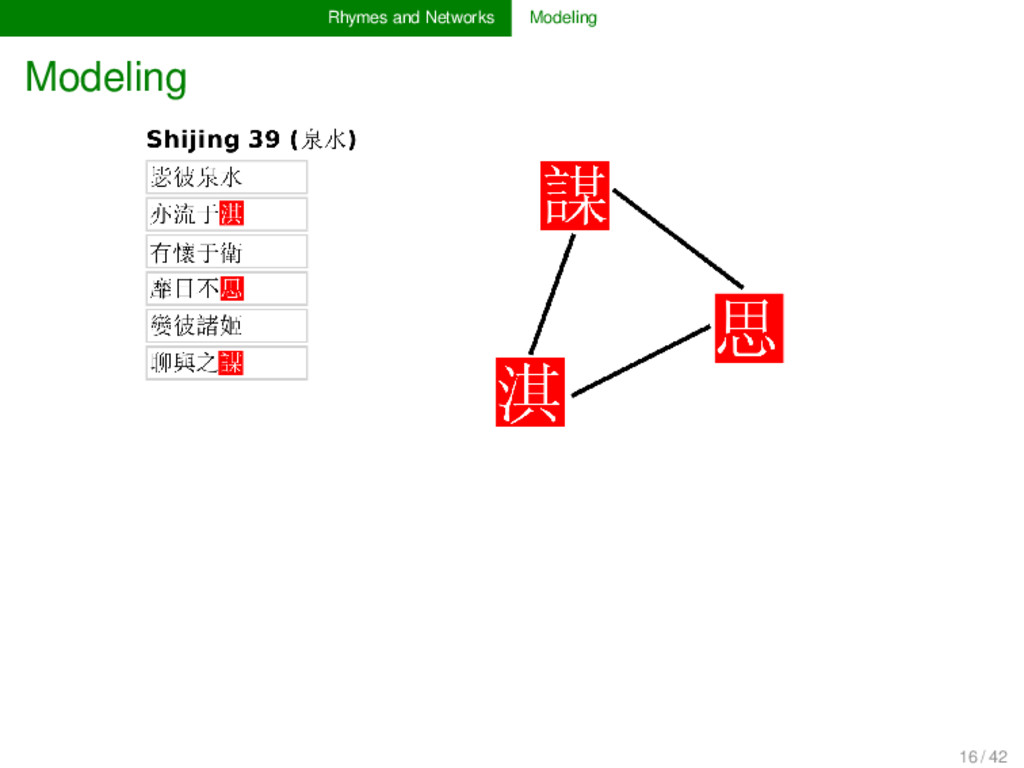
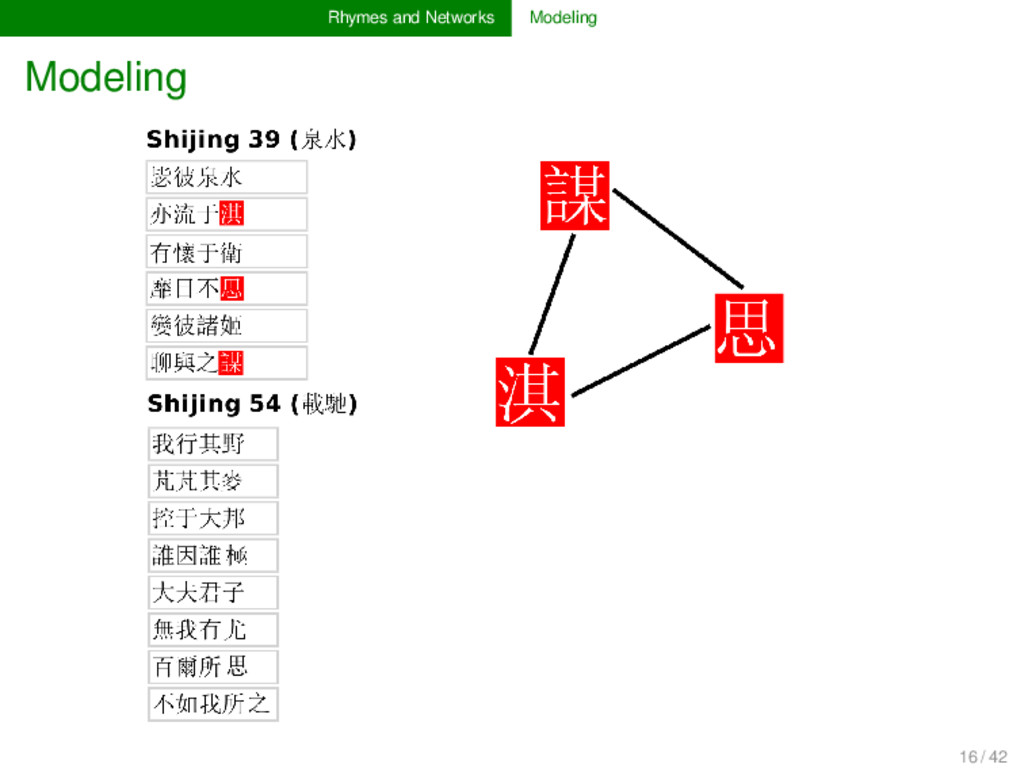
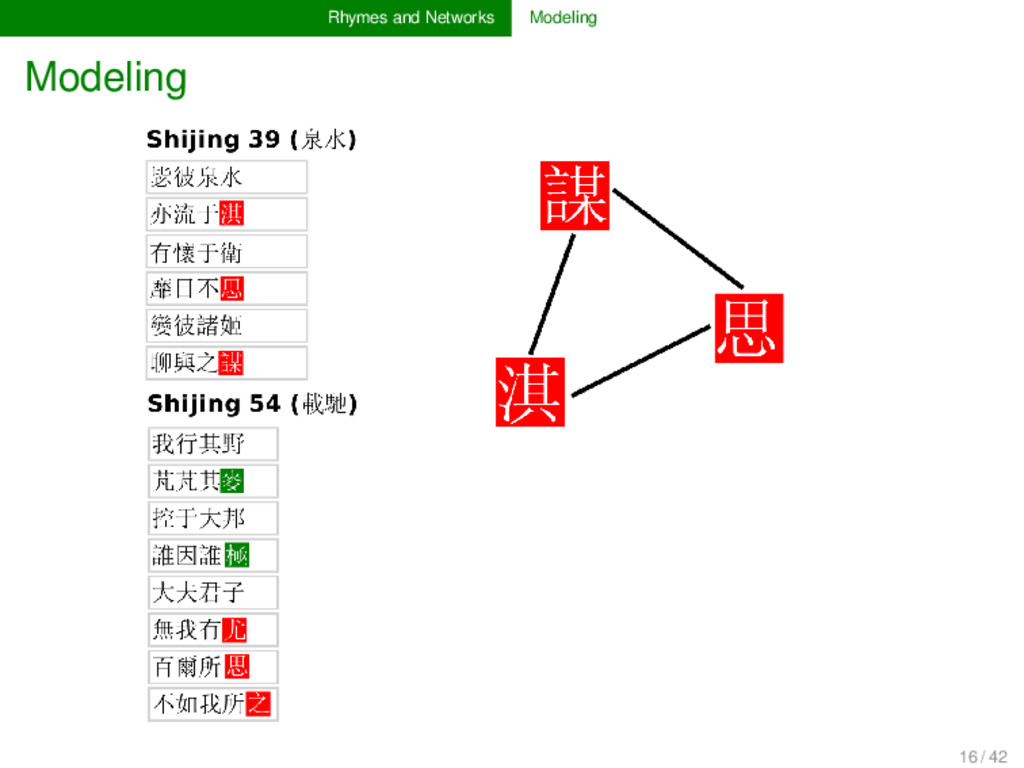
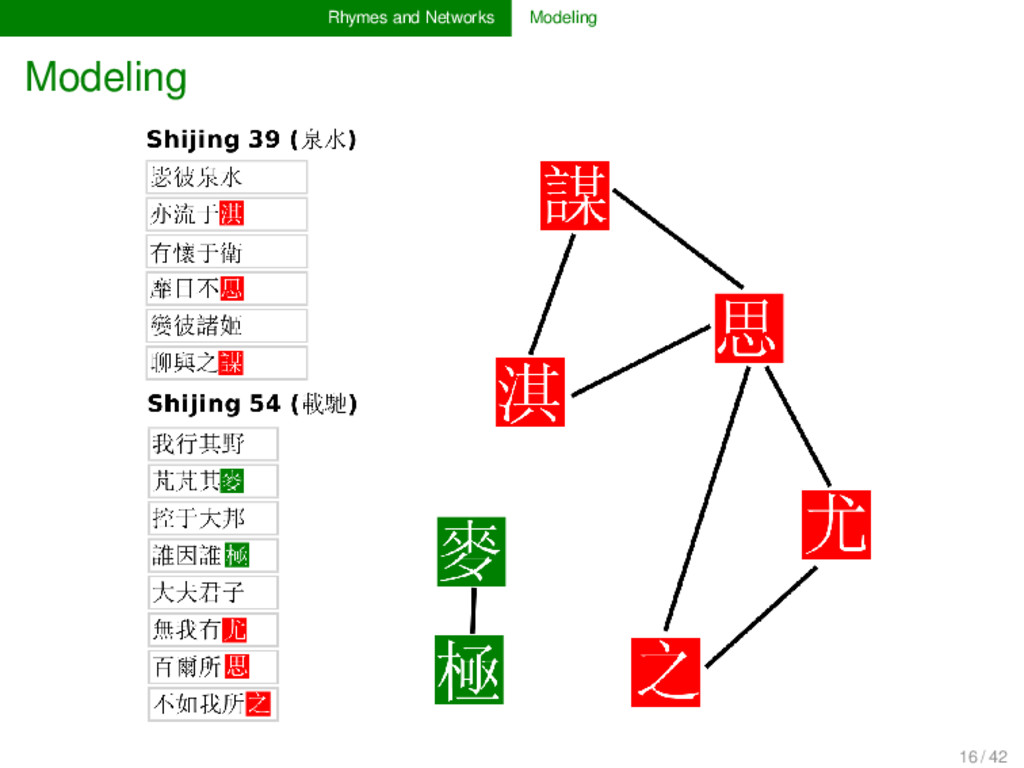
for poems which are annotated for their rhyme relations is straightforward. Prob- lematic is the weighting of recurring rhyme connections, the treatment of larger poems, and the handling of specific types of rhyme (rhymes inside the same line, rhymes of bi-syllabic units, etc.). 18 / 42
than one time throughout a collection of poems, this is of course stronger evidence for their similarity than a spurious rhyming, and it should be handled in the model (→ use weighted networks to represent frequency) if words rhyme in larger stanzas, these stanzas contain more words, and accordingly, more units will rhyme with more other units, which may overweight the closeness between the rhyme words in a longer stanza (→ normalize rhyme connections in each stanza) line-internal rhymes and bi-syllabic rhymes follow at times different rules (especially the former), and ideally their modeling would reflect them as such (question not yet solved in the current application) 19 / 42
web-based application displays Shījīng rhymes in digitized form with rhyme annotations following Baxter (1992) and rhyme readings following Baxter and Sagart (2014) and Pān (2000, as provided in the Thesaurus Linguae Sericae). offers a quick and transparent way to inspect Baxter’s rhyme annotations, as well as a quick way to search through the Shījīng for rhyme patterns and brief glosses. URL: http://digling.org/shijing 20 / 42
out by Starostin (1989: 338-340) who claimed that apparent rhyme connections between *-n and *-j-codas can be explained by reconstructing an additional coda *-r whose normal reflex in Middle Chinese was -n, 21 / 42
out by Starostin (1989: 338-340) who claimed that apparent rhyme connections between *-n and *-j-codas can be explained by reconstructing an additional coda *-r whose normal reflex in Middle Chinese was -n, further evidence was provided in presumed cognates from Tibetan (Hill 2014), 21 / 42
out by Starostin (1989: 338-340) who claimed that apparent rhyme connections between *-n and *-j-codas can be explained by reconstructing an additional coda *-r whose normal reflex in Middle Chinese was -n, further evidence was provided in presumed cognates from Tibetan (Hill 2014), Baxter and Sagart (2014) followed this idea in their new reconstruction for Old Chinese, but they did not test the hypothesis on the rhymes 21 / 42
out by Starostin (1989: 338-340) who claimed that apparent rhyme connections between *-n and *-j-codas can be explained by reconstructing an additional coda *-r whose normal reflex in Middle Chinese was -n, further evidence was provided in presumed cognates from Tibetan (Hill 2014), Baxter and Sagart (2014) followed this idea in their new reconstruction for Old Chinese, but they did not test the hypothesis on the rhymes Can we use the Shījīng network data to provide additional tests for this hypothesis? 21 / 42
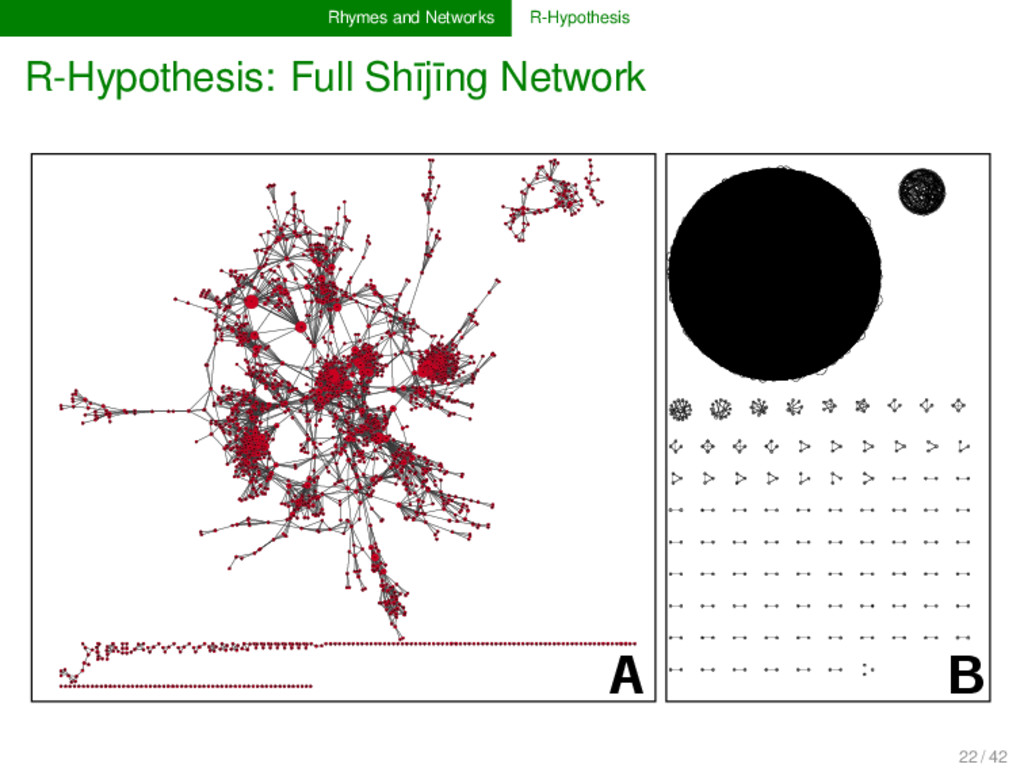
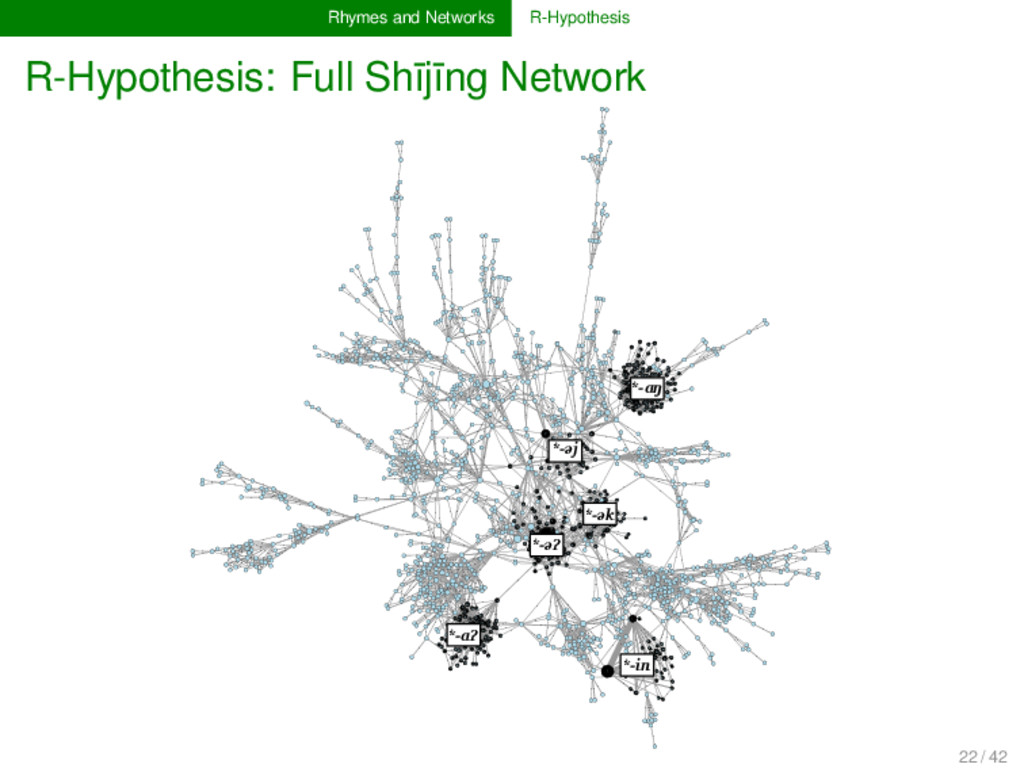
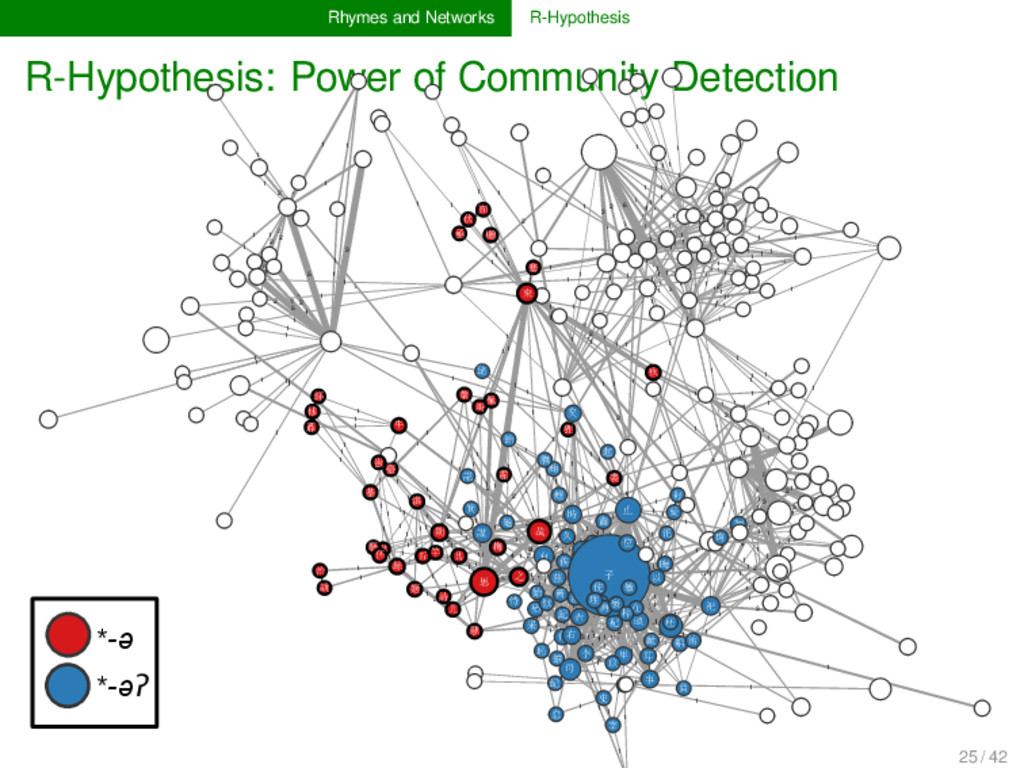
network alone, we cannot find any conclu- sive proof for any of the finals of Old Chinese. Instead, we need to partition the data, using classical methods for com- munity detection. If these clusters, inferred from the network structure, reflect the distinction of OC *-j and *-n words into three classes, this can be seen as strong evidence for the *-r coda. 23 / 42
help of Infomap (Rosvall and Bergstrom 2007) algorithm splits the Shījīng network into 345 distinct communities all data can be interactively browsed at http://digling.org/shijing/communities.html 24 / 42
the -əʔ vs. the -ə-coda, as inferred by the algo- rithm, the inference comes very close to the reconstruction system of Baxter and Sagart (2014): of 74 rhyme words as- signed to -əʔ automatically, 59 also reconstructed as such; of 39 rhyme words automatically assigned to -ə, 30 are re- constructed as such in Baxter and Sagart. 25 / 42
to the community analysis on the Shījīng rhyme net- work, we can feed back to Baxter and Sagart’s reconstruc- tion and conform many cases of uncertainty. The structure of the clusters indicates that the r-coda can also be detected in the rhyme networks. More research is needed to include the results of the automatic analysis into the reconstruction of Old Chinese. 26 / 42
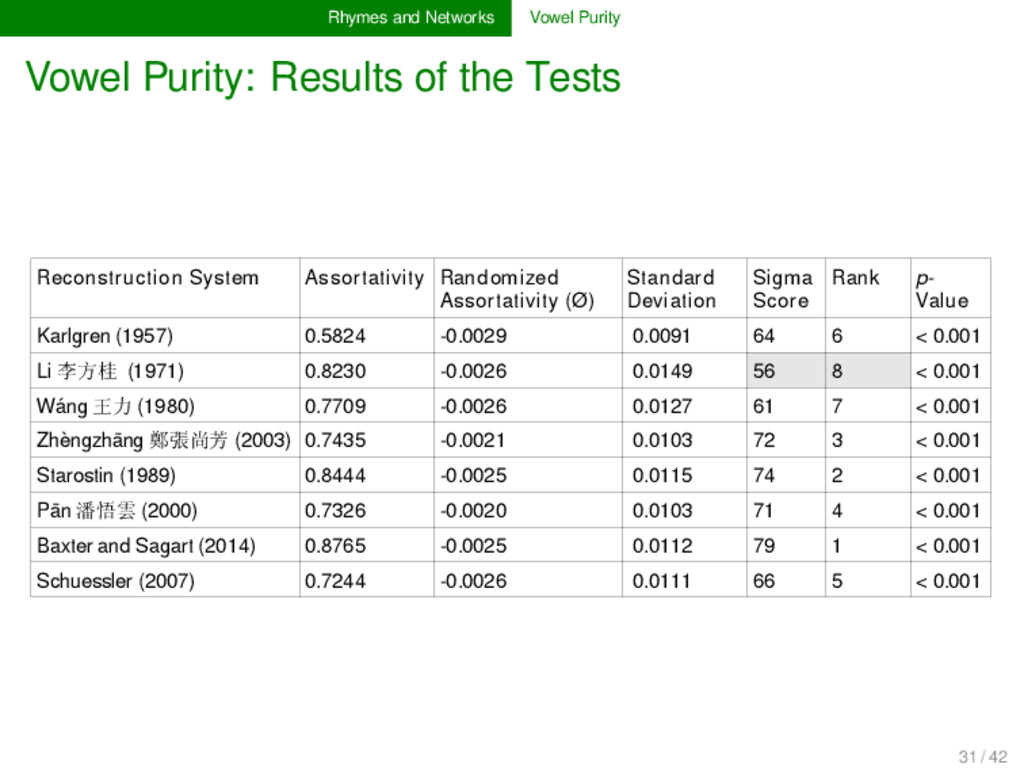
forthcoming) Ho (2016) claims that the principle of vowel purity was im- portant in Old Chinese rhyming: poets would try to avoid rhyming words with different consonants, while differences in the codas were more often tolerated. Reconstruction sys- tems which contradict this principle, may therefore be exter- nally criticized as neglecting the principle of vowel purity. On the other hand, we can compare different reconstruction re- garding the degree of purity of their vowels compared to the rhyme data in the Shījīng. 27 / 42
System No. Rhymes Density a ɑ æ e ə o ɔ u ʊ ɯ i Karlgren (1957) 1830 0.0031 0.0026 x x x x x x x x x x x Li 李方桂 (1971) 1830 0.0031 0.0026 x x x x Wáng 王力 (1980) 1830 0.0031 0.0026 x x x x x Zhèngzhāng 鄭張尚芳 (2003) 1830 0.0031 0.0030 x x x x x x Starostin (1989) 1358 0.0035 0.0026 x x x x x x Pān 潘悟雲 (2000) 1830 0.0031 0.0026 x x x x x Baxter and Sagart (2014) 1431 0.0038 0.0033 x x x x x x Schuessler (2007) 1224 0.0041 0.0035 x x x x x x 28 / 42
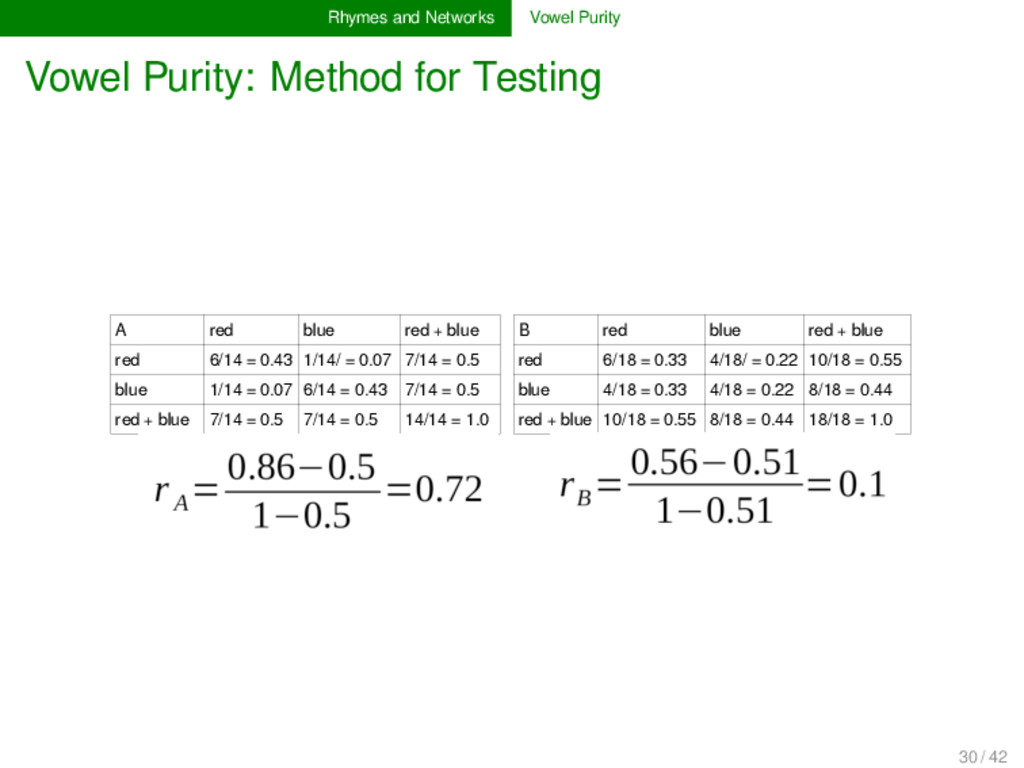
Assortativity tests whether nodes sharing connections in a graph are also similar regarding other characteristics (New- man 2003). In social network analyses it can, for exam- ple, be used to test whether observed patterns in a network, like friendship, come along with properties of the individu- als, such as language or gender (ibid.). Assortativity can be measured by calculating the assortativity coefficient of a network in which all nodes have a given attribute. 29 / 42
A red blue red + blue B red blue red + blue red 6/14 = 0.43 1/14/ = 0.07 7/14 = 0.5 red 6/18 = 0.33 4/18/ = 0.22 10/18 = 0.55 blue 1/14 = 0.07 6/14 = 0.43 7/14 = 0.5 blue 4/18 = 0.33 4/18 = 0.22 8/18 = 0.44 red + blue 7/14 = 0.5 7/14 = 0.5 14/14 = 1.0 red + blue 10/18 = 0.55 8/18 = 0.44 18/18 = 1.0 30 / 42
Tests Provided the principle of vowel purity was really dominant during time of the creation of the Shījīng, our results indicate that reconstruction systems with six vowels outperform those with less or more vowels. Given that we do not know to which degree vowel purity was important in Old Chinese rhyming, this does not allow us to prove or disprove any of the recon- struction systems. Further research on rhyming practice and pragmatics are needed. 31 / 42
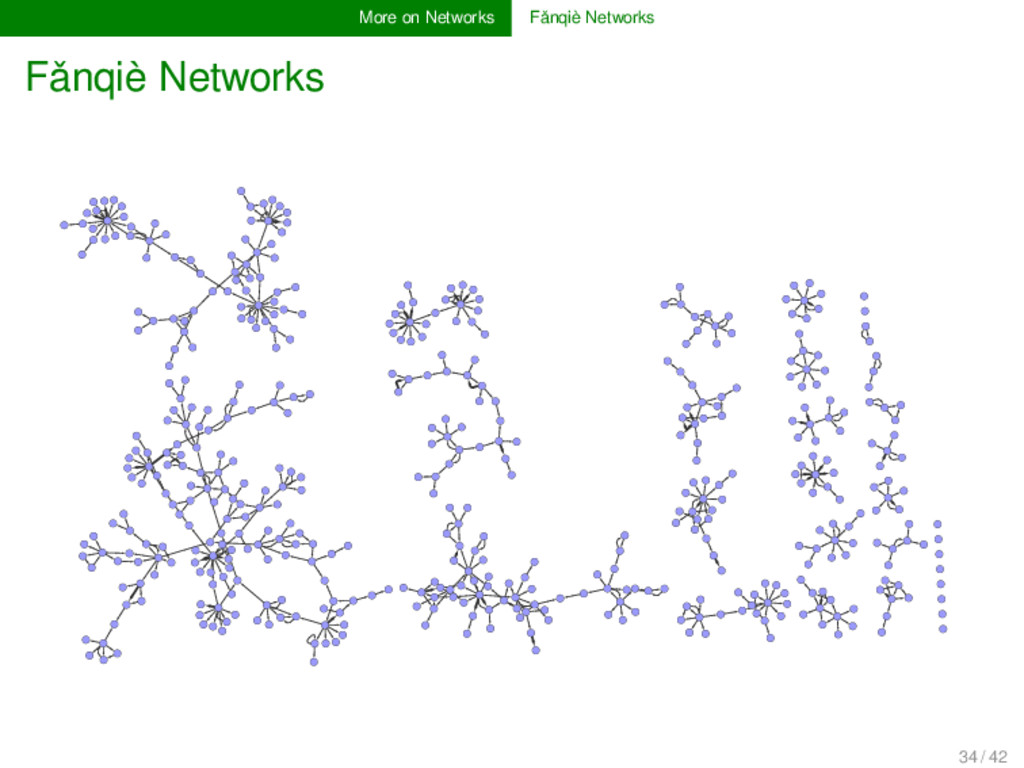
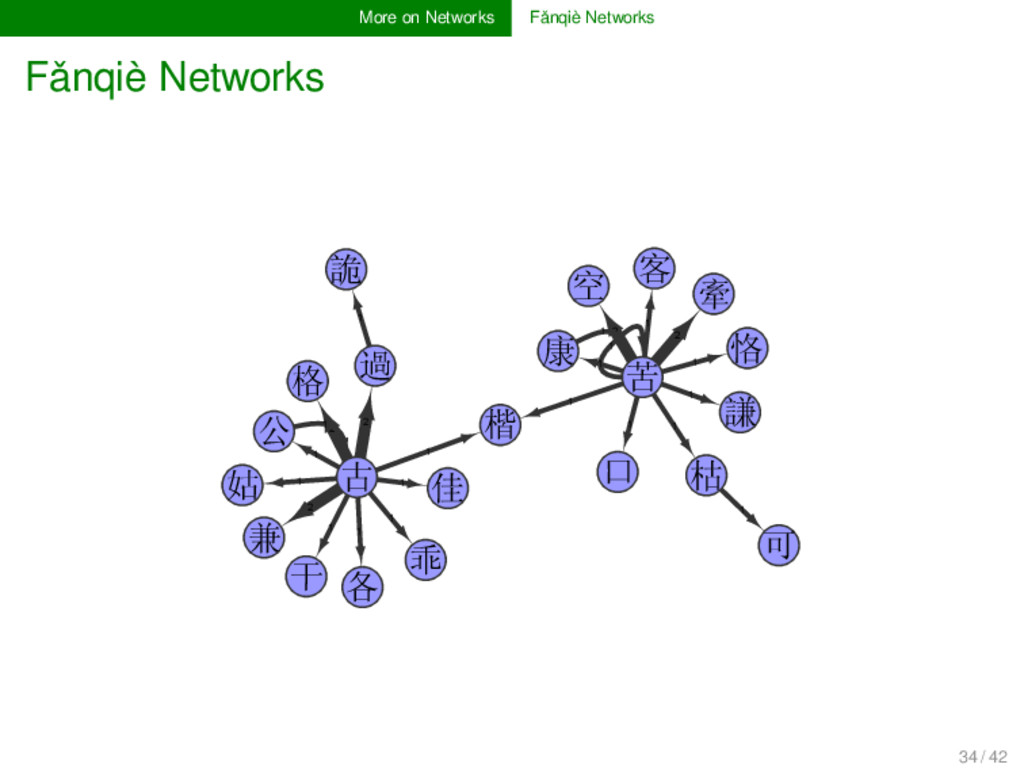
since been known that fǎnqiè 反切 readings can also be analyzed by exploiting their network characteristics (see, e.g., Gěng Zhènshēng 耿振生 2004 on the fǎnqiè xìliánfǎ 反切系聯法). 33 / 42
since been known that fǎnqiè 反切 readings can also be analyzed by exploiting their network characteristics (see, e.g., Gěng Zhènshēng 耿振生 2004 on the fǎnqiè xìliánfǎ 反切系聯法). But with modern network approaches, we can handle the data more consistently and transparently. 33 / 42
since been known that fǎnqiè 反切 readings can also be analyzed by exploiting their network characteristics (see, e.g., Gěng Zhènshēng 耿振生 2004 on the fǎnqiè xìliánfǎ 反切系聯法). But with modern network approaches, we can handle the data more consistently and transparently. By extracting, for example, all fǎnqiè shàngzì 反切上字 from the Guǎngyùn 廣韻, we can create networks of fǎnqiè connections. 33 / 42
since been known that fǎnqiè 反切 readings can also be analyzed by exploiting their network characteristics (see, e.g., Gěng Zhènshēng 耿振生 2004 on the fǎnqiè xìliánfǎ 反切系聯法). But with modern network approaches, we can handle the data more consistently and transparently. By extracting, for example, all fǎnqiè shàngzì 反切上字 from the Guǎngyùn 廣韻, we can create networks of fǎnqiè connections. These networks are ideal for teaching Chinese traditional phonology, but also for comparison if scholars have different opinions. 33 / 42
still underexplored, both with respect to traditional scholarship on Chinese historical phonology and with respect to the way they are best handled, and potential differences across Chinese rhyme books or other sources containing fǎnqiè readings from different epochs or authors. However, it seems promising to further exploit and test the approaches, as they may drastically increase the transparency of current approaches. 35 / 42
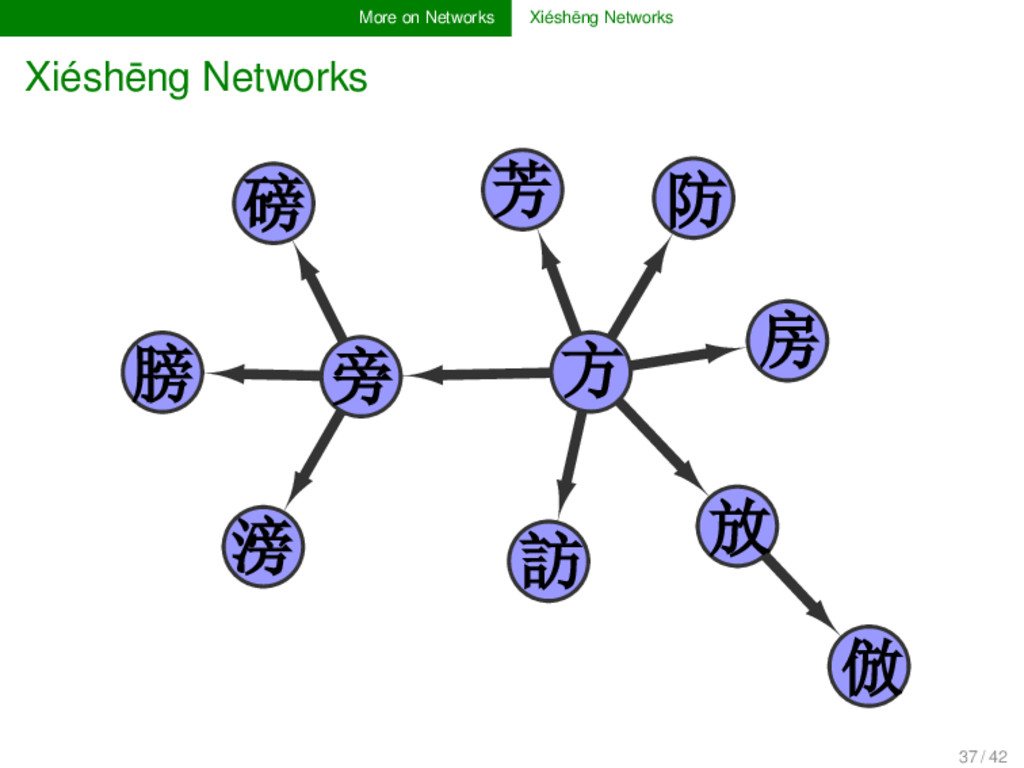
段玉裁 detected the strong correlation between the phonetic part of xíngshēng 形聲 characters, we know that the Chinese system basically reflects a network structure, since a large part of the characters can be decomposed into subparts which reflect other characters or recur across different characters. 36 / 42
段玉裁 detected the strong correlation between the phonetic part of xíngshēng 形聲 characters, we know that the Chinese system basically reflects a network structure, since a large part of the characters can be decomposed into subparts which reflect other characters or recur across different characters. Not often really taken into consideration is the historical aspect of these connections. Not all phonetic units of xíngshēng characters were formed at the same time, and the characters reflect a complex evolution of character formation at different steps. 36 / 42
段玉裁 detected the strong correlation between the phonetic part of xíngshēng 形聲 characters, we know that the Chinese system basically reflects a network structure, since a large part of the characters can be decomposed into subparts which reflect other characters or recur across different characters. Not often really taken into consideration is the historical aspect of these connections. Not all phonetic units of xíngshēng characters were formed at the same time, and the characters reflect a complex evolution of character formation at different steps. Instead of listing xíngshēng series in form of lists of characters and common component, we should create explicit networks, as they are much more transparent to display where scholars disagree in their analyses, but also which characters are immediately composed of other characters. 36 / 42
especially aspects of char- acter formation, with help of directed networks could greatly benefit not only scientific exchange among scholars, who would be encouraged to present their judgments more trans- parently, but also other aspects of Chinese writing, such as, e.g., pedagogical aspects of teaching the structure of the writing system to beginners, or information-theoretic as- pects. 38 / 42
data we model in networks can be enhanced, also our methods to analyze the networks need to be fur- ther improved. As an example, consider dynamic networks, which would analyze and model network changes in time. By improving on these methods, we could, for example, com- pare fǎnqiè networks across different epochs, as well as rhyme networks from different authors, dialects, and styles. We could further try to induce fundamental hierarchies and relative time frames from xiéshēng networks. 39 / 42
the last years in my research is that despite the great achievements scholars have made in historical linguistics, and especially in Chinese traditional phonology, we still lack clear-cut frameworks that help us to produce our data transparently. Historical linguis- tics is a data-driven discipline, but scholars tend to ignore this when presenting their incredible insights in an intrans- parent form. Networks can help in two ways here: first, they are a transparent way of data-representation; and second, they provide an added value in those cases, where data be- comes too large for scholars to be inspected by eye-balling only. 41 / 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Introduction Rhyming in General Rhyming in General music [-ɪk] own](https://files.speakerdeck.com/presentations/f22146259fc34ad597cc788da6c65aa5/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Rhymes and Networks R-Hypothesis R-Hypothesis: Testing the *-a[nrj] Coda 2](https://files.speakerdeck.com/presentations/f22146259fc34ad597cc788da6c65aa5/slide_56.jpg){kind=link}
![Rhymes and Networks R-Hypothesis R-Hypothesis: Testing the *-a[nrj] Coda 1](https://files.speakerdeck.com/presentations/f22146259fc34ad597cc788da6c65aa5/slide_57.jpg){kind=link}
![Rhymes and Networks R-Hypothesis R-Hypothesis: Testing the *-a[nrj] Coda 3](https://files.speakerdeck.com/presentations/f22146259fc34ad597cc788da6c65aa5/slide_58.jpg){kind=link}
![Rhymes and Networks R-Hypothesis R-Hypothesis: Testing the *-a[nrj] Coda Thanks](https://files.speakerdeck.com/presentations/f22146259fc34ad597cc788da6c65aa5/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}