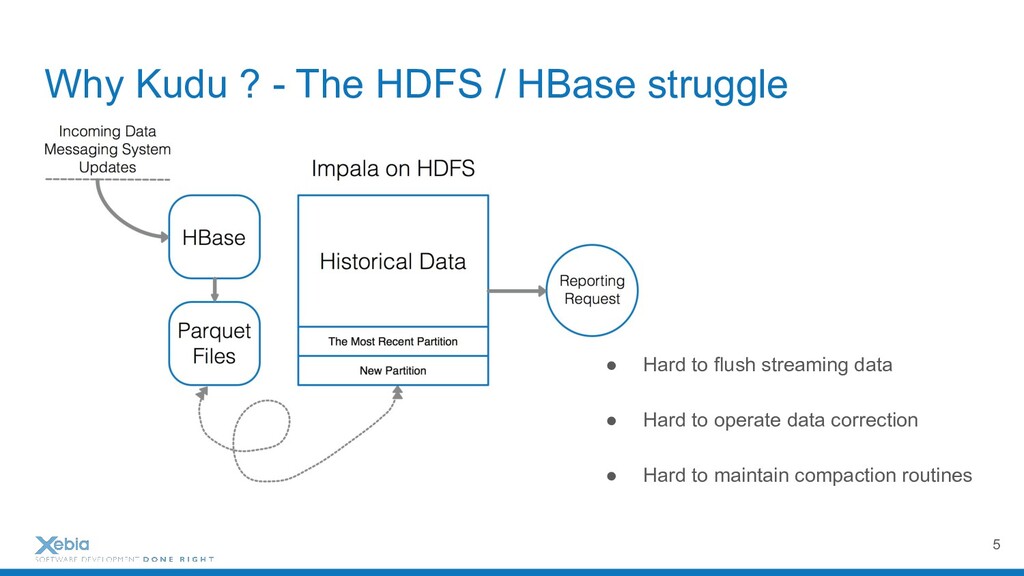
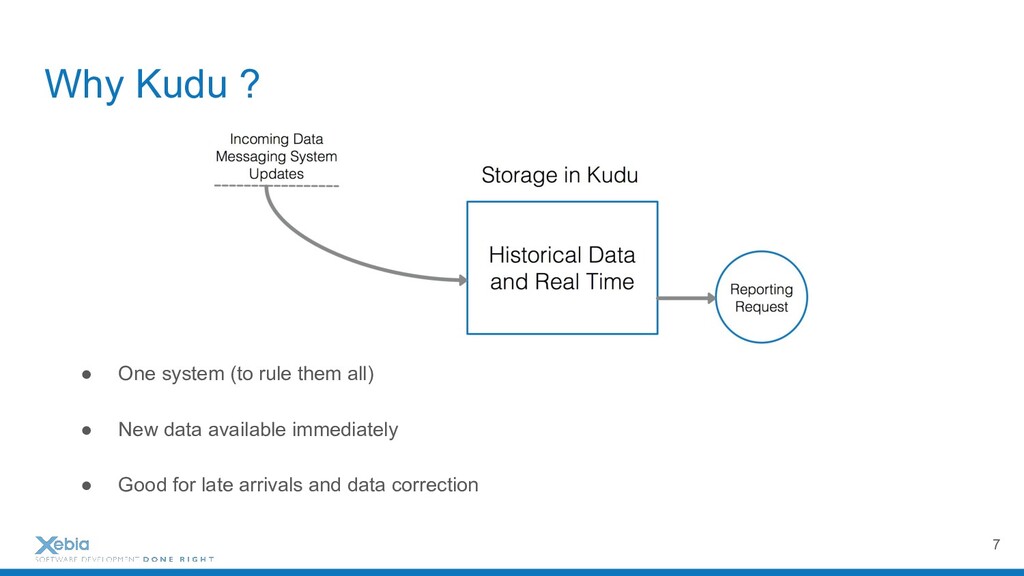
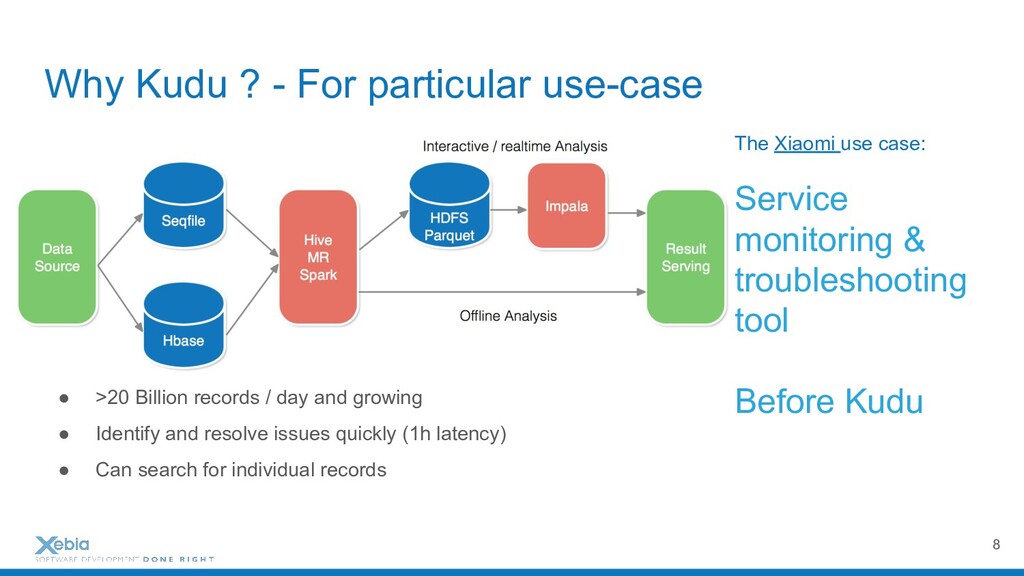
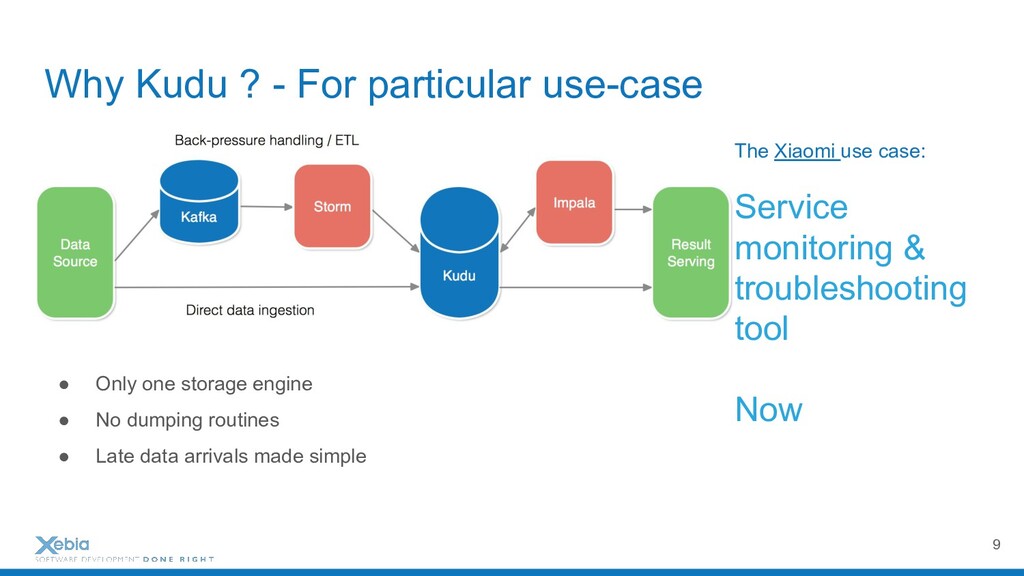
Apache Hadoop and it's distributed file system are probably the most representative to tools in the Big Data Area. They have democratised distributed workloads on large datasets for hundreds of companies already, just in Paris. But these workloads are append-only batches. However, life in companies can't be only described by fast scan systems. We need writes but also updates. We need fast random access and mutable data on huge dataset too. And when it comes to supporting continuous ingestions of event, mix HDSF, and columnar database (e.g., HBase or Cassandra) within the same architecture may be complicated. To solve all these issues, I will present Apache Kudu, a fast analytics storage layer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
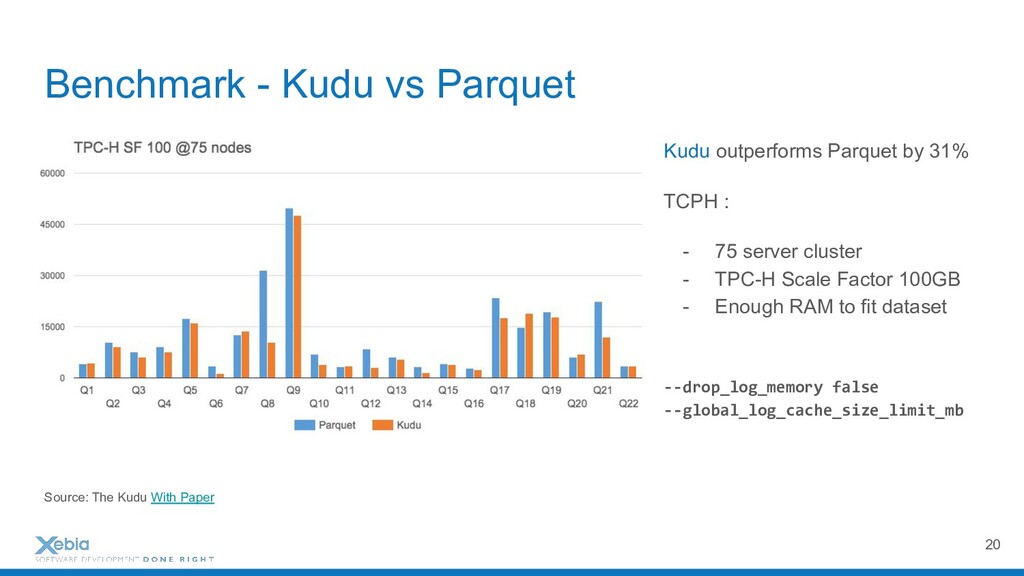{kind=link}
{kind=link}
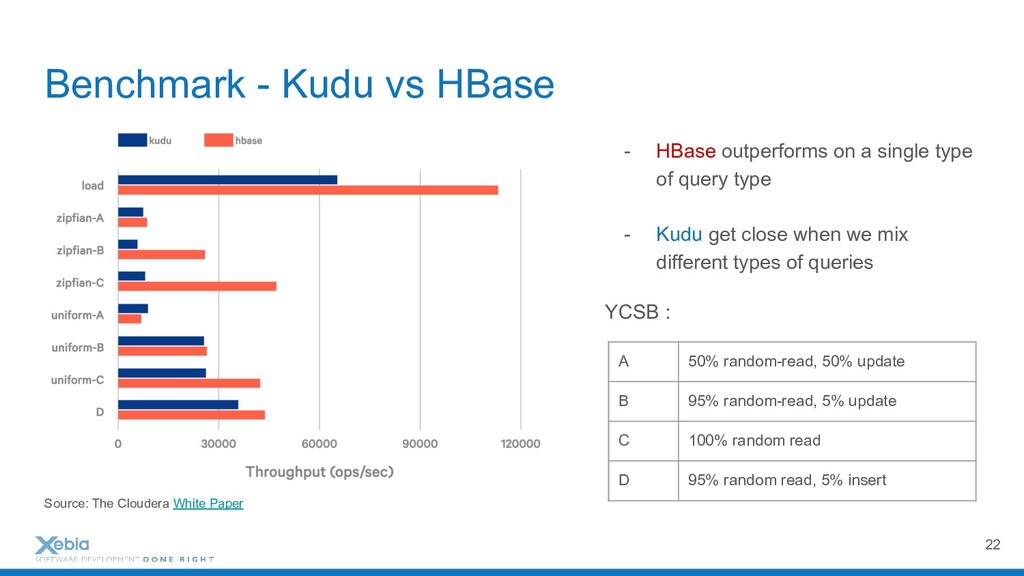{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
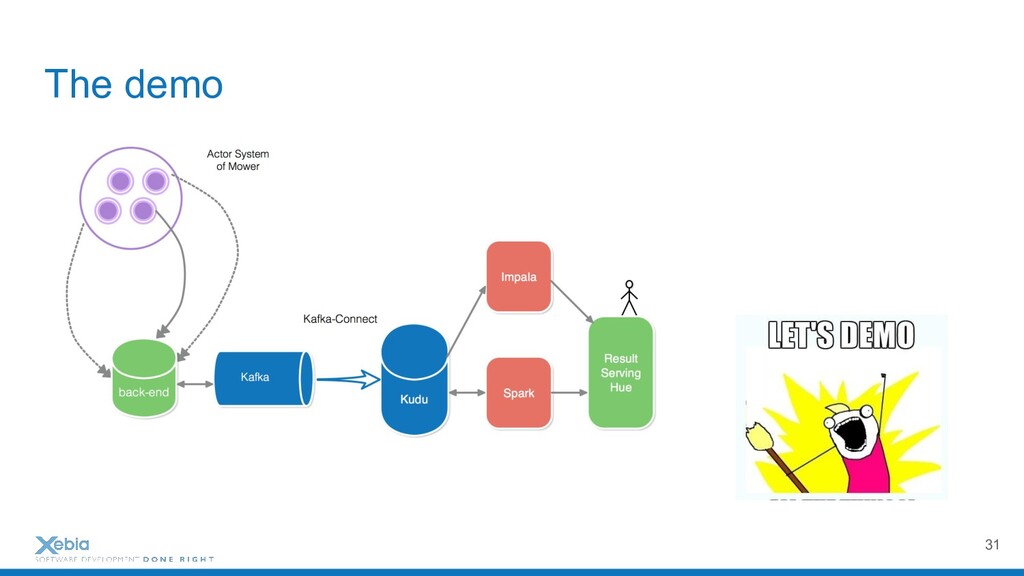{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
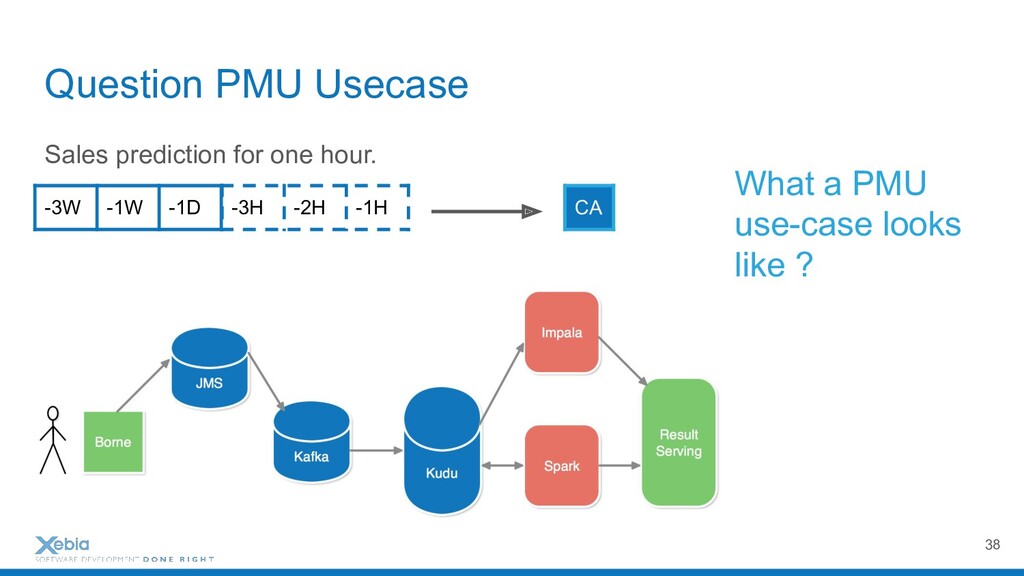{kind=link}
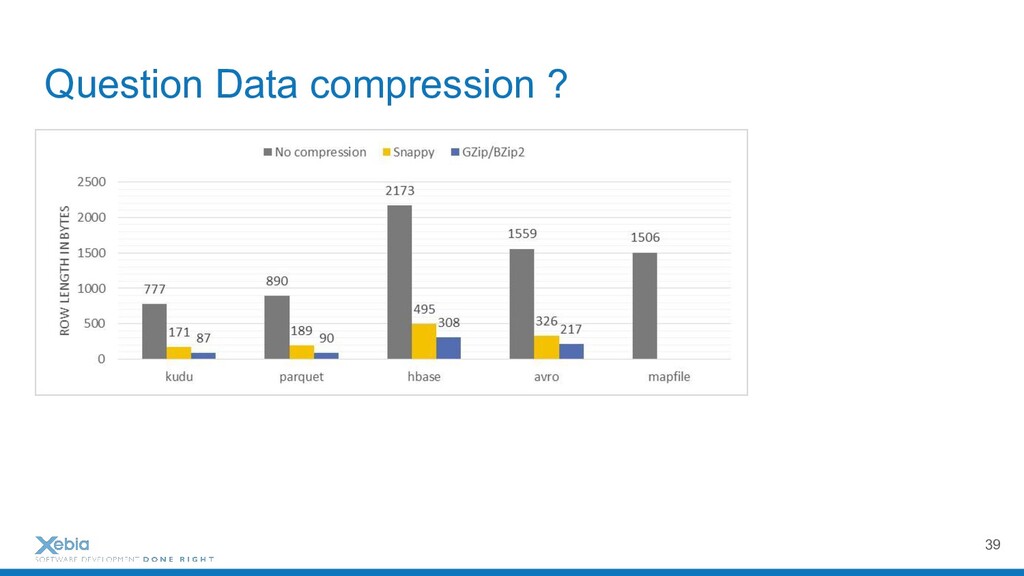{kind=link}
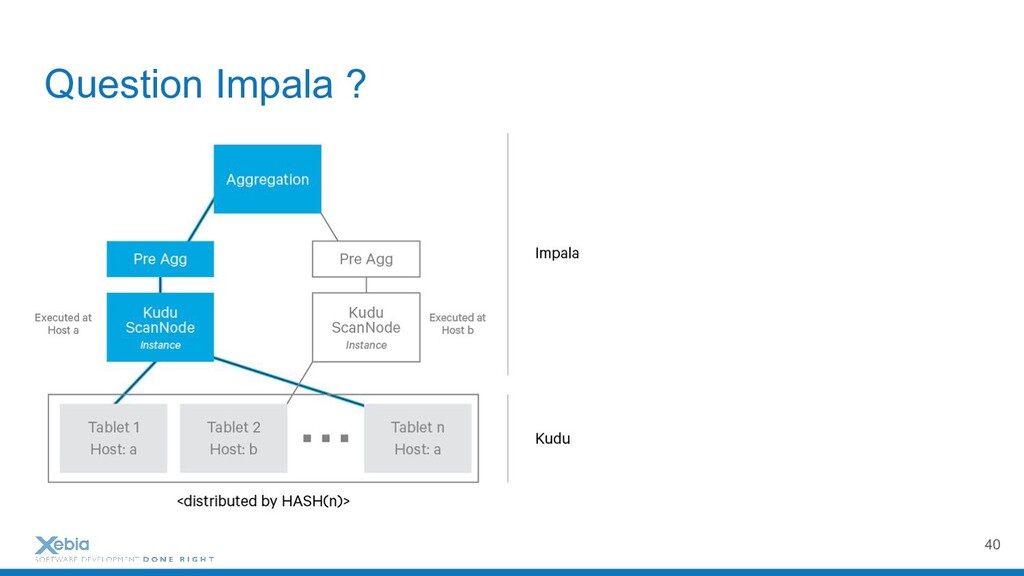{kind=link}
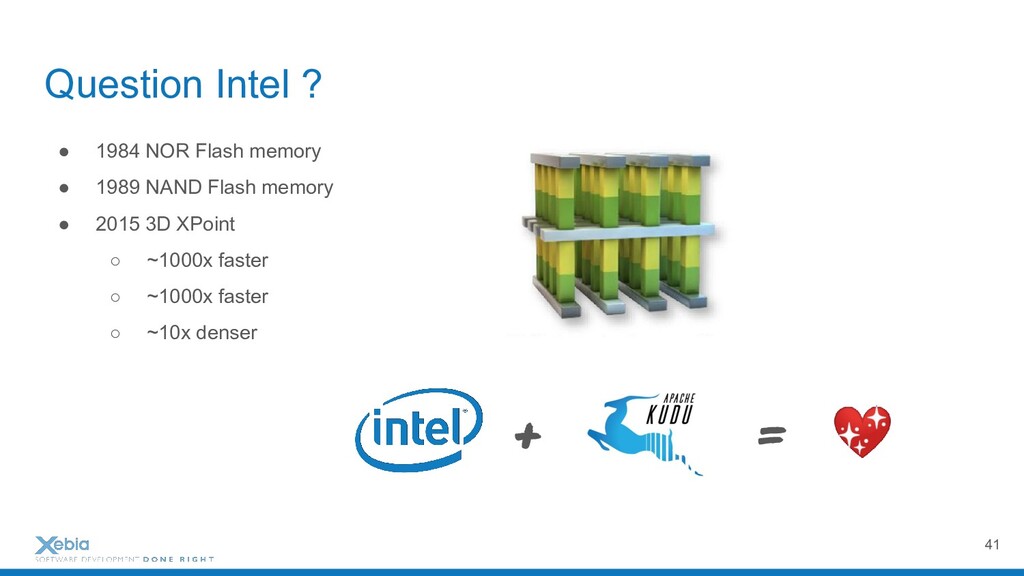{kind=link}
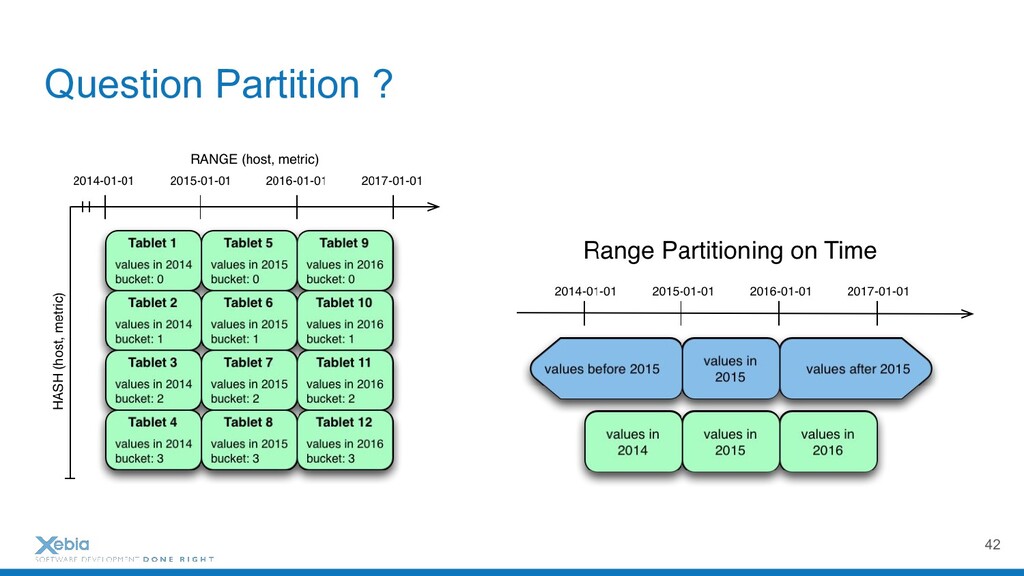{kind=link}
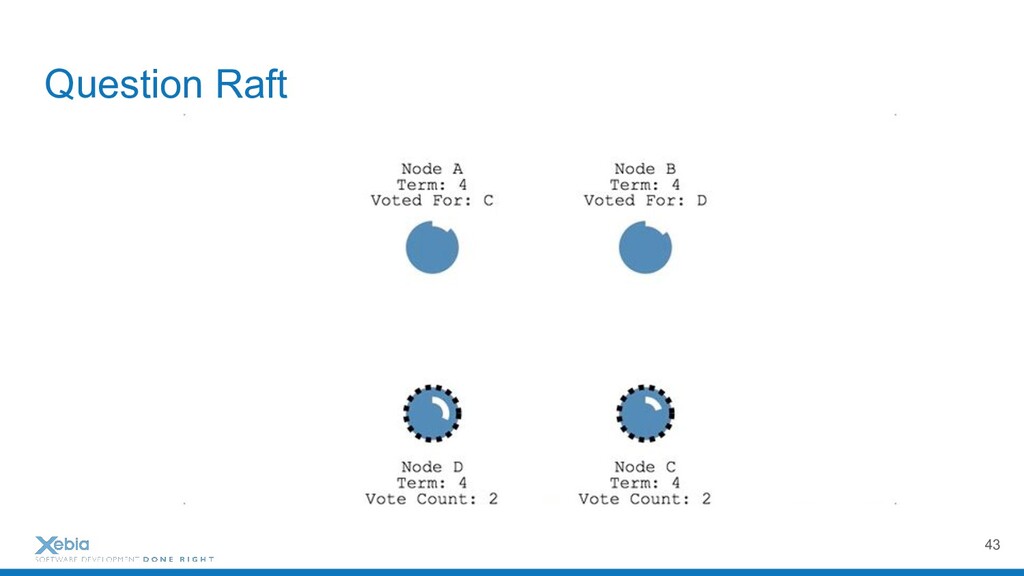{kind=link}
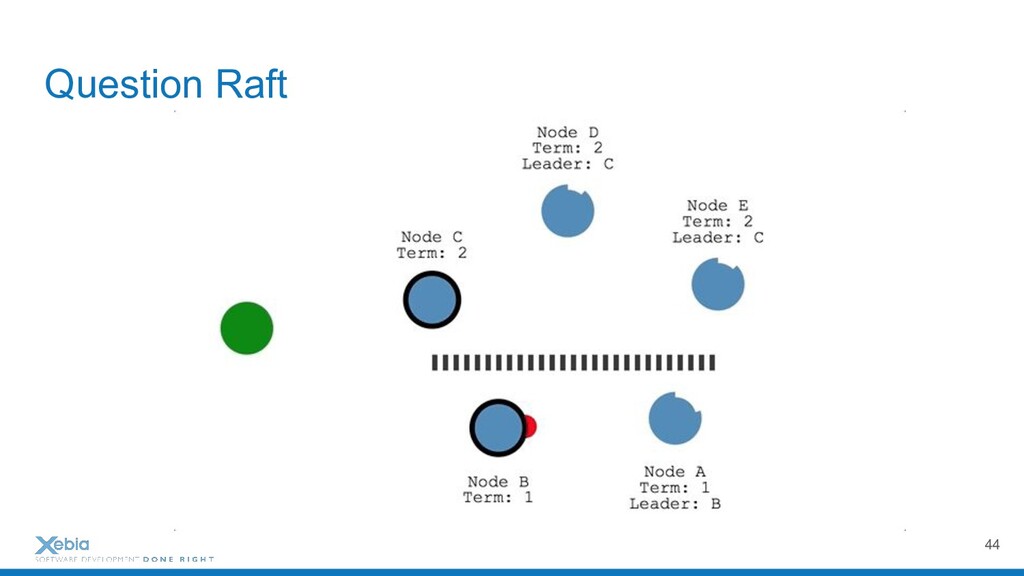{kind=link}