Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
偏りのある時系列データの分類について
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Masato MIWADA
October 19, 2024
Technology
82
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
偏りのある時系列データの分類について
Time series classification on imbalanced data
Masato MIWADA
October 19, 2024
More Decks by Masato MIWADA
See All by Masato MIWADA
画像による脳腫瘍の検出
masato_miwada
0
85
河川流計測における画像解析技術の実用化
masato_miwada
1
73
河川流計測における画像解析技術の実用化
masato_miwada
0
55
慣性センサログの効果的な可視化と分類手法について
masato_miwada
0
60
t-SNE(t分布型確率的近傍埋め込み法)による高次元データの可視化について
masato_miwada
0
92
畳み込みニューラルネットワークによる画像分類について
masato_miwada
0
77
Other Decks in Technology
See All in Technology
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
2k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
8
2k
AIQAのナレッジ構築について
qatonchan
1
140
Atlassian Cloudサポート業務でのAIエージェント活用事例
smt7174
0
220
MIRU 2026 チュートリアル
keisuke198619
0
400
AI驚き屋発見器
yama3133
2
390
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
220
検索技術知識0のエンジニアが広告検索システムを内製化して運用するまで
lycorptech_jp
PRO
0
180
plamo-3-translateの開発
pfn
PRO
0
240
AI ネイティブな組織に Gemini Enterprise Agent Platform がなぜ必要なのか
asei
1
140
AIは実装を速くする。では、私たちは何を今作るべきか?-立場を越えてリリースに向き合ったチーム開発の実践 / 20260801 Hiromi Nakaya and Naoki Takahashi
shift_evolve
PRO
3
170
PLaMo 3.0 Primeの事後学習
pfn
PRO
0
240
Featured
See All Featured
Google's AI Overviews - The New Search
badams
0
1.1k
Balancing Empowerment & Direction
lara
6
1.2k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Unsuck your backbone
ammeep
672
58k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
250
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Navigating Team Friction
lara
192
16k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.6k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.2k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Transcript
偏りのある時系列データ の分類について (Time series classification on imbalanced data) (課題名:オゾンレベルの分類) (ミワダ
マサト) 三和田 将人
お詫び 前回の勉強会(3月7日)で、交差検証(Cross Validation)における評価値(正答 率:ACC)を各Foldにおける正解率の平均として算出していました。しかし、これは 厳密には誤りでした。 参考サイト:データ化学工学研究室(金子研究室)@明治大学 理工学部 応用化学科, "クロスバリデーションにおける注意点のまとめ https://datachemeng.com/cautions_in_cross_validation/#toc3
図の引用元:こちきか, "クロスバリデーション(交差検証), https://gochikika.ntt.com/Learning/cv.html 正しくは 各Foldにおける検証結果を全て足し合 わせてから混合行列を始めとする統計 量を確認する でした。 (理由) 分割数によって、同じサンプル数にならな い状況があるから。
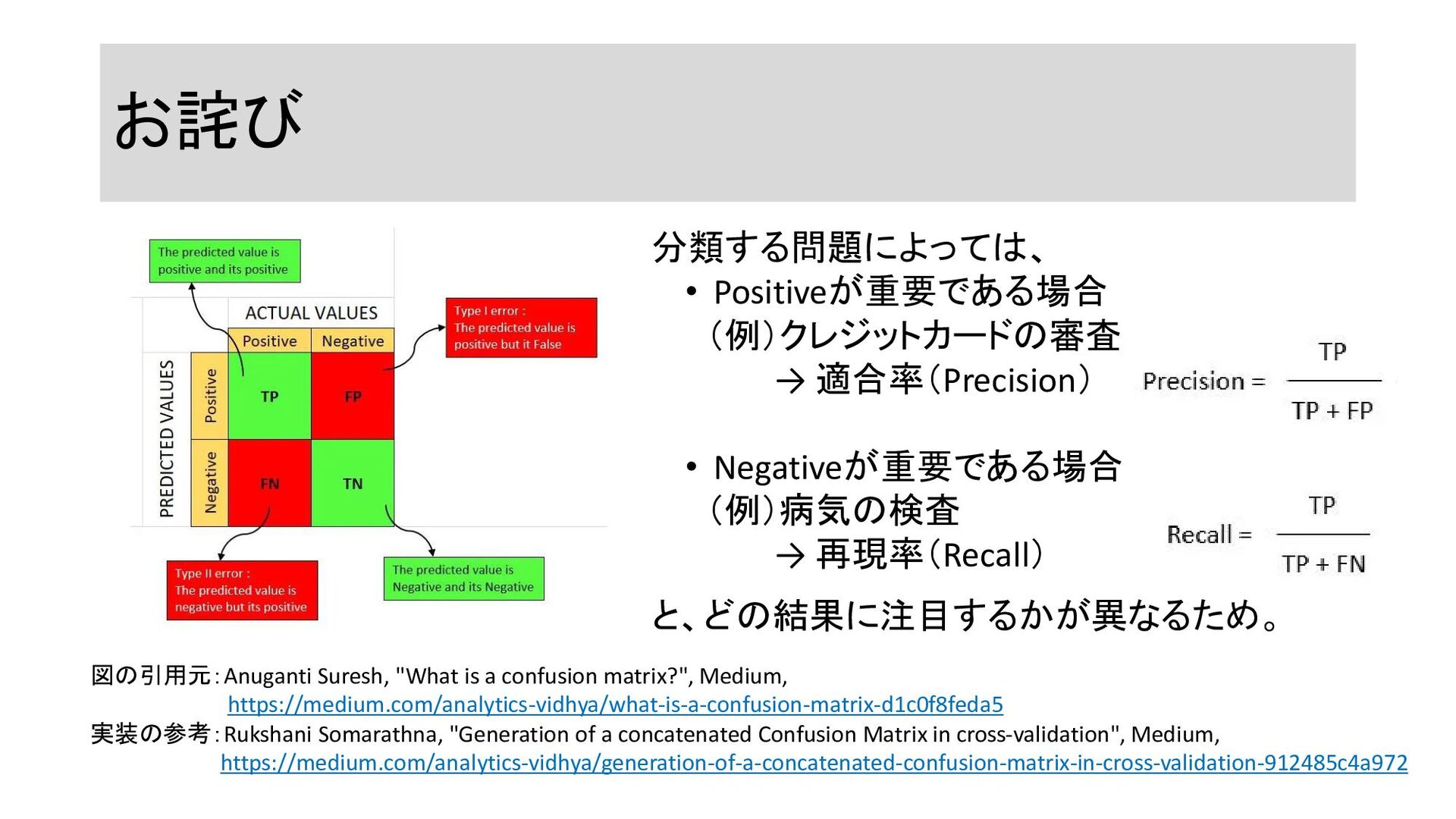
お詫び 図の引用元:Anuganti Suresh, "What is a confusion matrix?", Medium, https://medium.com/analytics-vidhya/what-is-a-confusion-matrix-d1c0f8feda5
実装の参考:Rukshani Somarathna, "Generation of a concatenated Confusion Matrix in cross-validation", Medium, https://medium.com/analytics-vidhya/generation-of-a-concatenated-confusion-matrix-in-cross-validation-912485c4a972 分類する問題によっては、 • Positiveが重要である場合 (例)クレジットカードの審査 → 適合率(Precision) • Negativeが重要である場合 (例)病気の検査 → 再現率(Recall) と、どの結果に注目するかが異なるため。
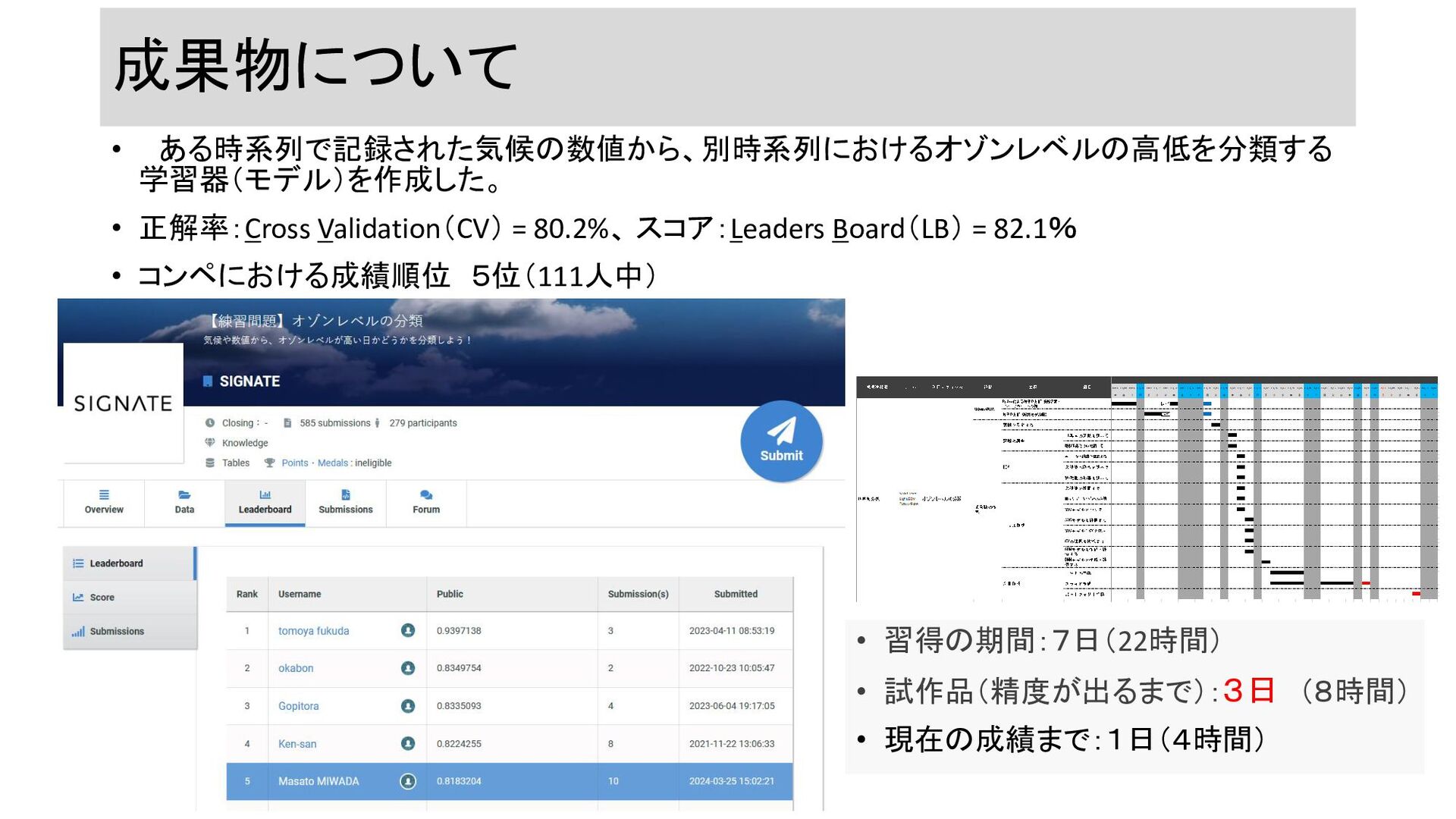
成果物について • ある時系列で記録された気候の数値から、別時系列におけるオゾンレベルの高低を分類する 学習器(モデル)を作成した。 • 正解率:Cross Validation(CV) = 80.2%、 スコア:Leaders
Board(LB) = 82.1% • コンペにおける成績順位 5位(111人中) • 習得の期間:7日(22時間) • 試作品(精度が出るまで):3日 (8時間) • 現在の成績まで:1日(4時間)
発表の流れについて 1. 時系列データについて 2. 今回の時系列データと問題点について 3. 作成スケジュール 4. 開発環境 5.
作製したモデルについて(モデルの種類、評価) 6. 苦労、実践したこと 7. 今回の振返りと今後について
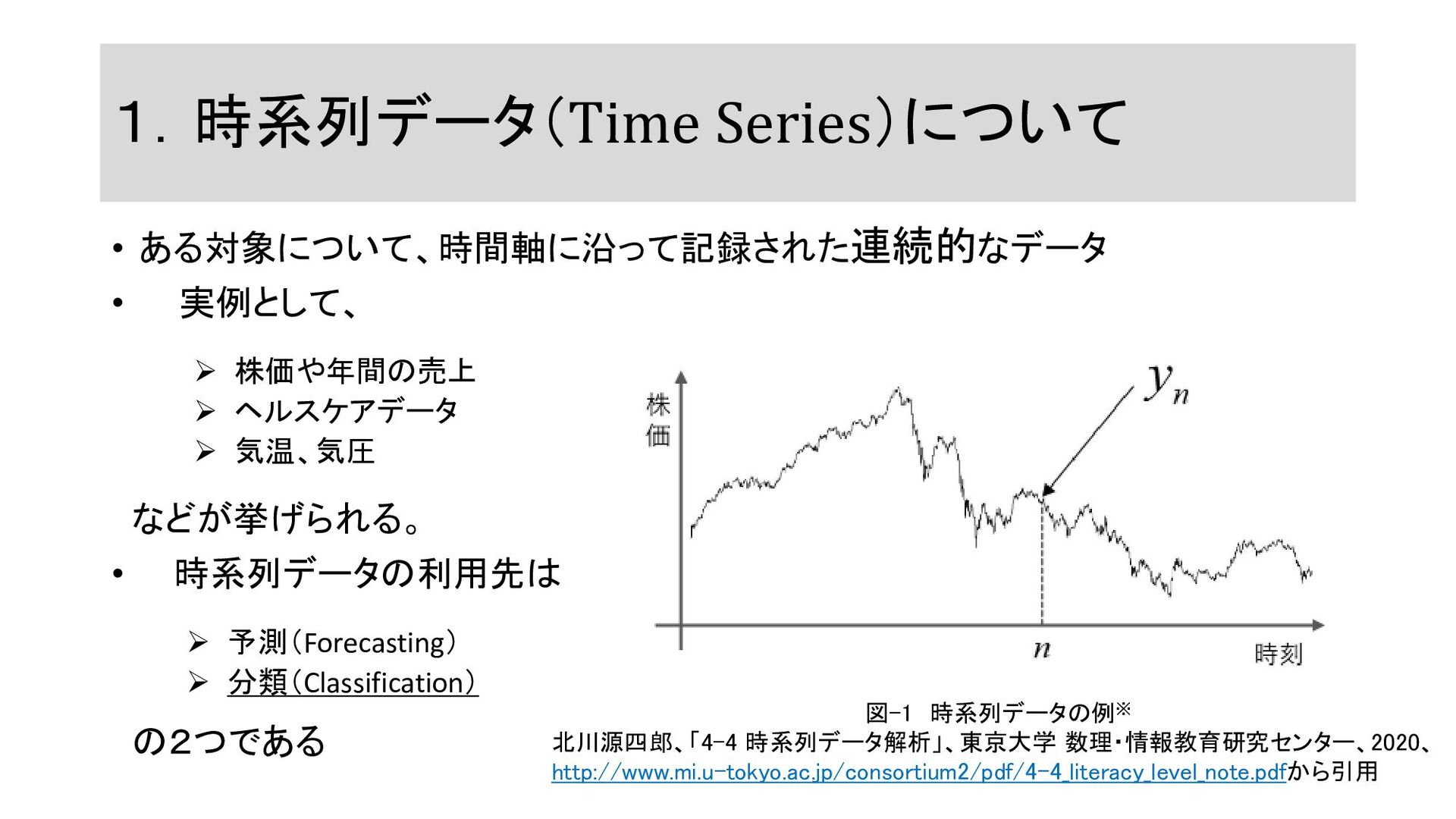
1.時系列データ(Time Series)について • ある対象について、時間軸に沿って記録された連続的なデータ • 実例として、 ➢ 株価や年間の売上 ➢ ヘルスケアデータ
➢ 気温、気圧 などが挙げられる。 • 時系列データの利用先は ➢ 予測(Forecasting) ➢ 分類(Classification) の2つである 図-1 時系列データの例※ 北川源四郎、「4-4 時系列データ解析」、東京大学 数理・情報教育研究センター、2020、 http://www.mi.u-tokyo.ac.jp/consortium2/pdf/4-4_literacy_level_note.pdfから引用
2.今回の時系列データと問題点について(1) • 出典 ➢引用 Dua, D. and Graff, C. (2019).
UCI Machine Learning Repository, [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science. ➢データソース:https://archive.ics.uci.edu/ml/datasets/Ozone+Level+Detection • 内容 ➢73個の特徴量がある時系列データ(説明変数72個、目的変数1個) ➢1267(行)×73(列) 日付 各時刻、最大及 び平均風速 各時刻、最大及 び平均気温 各種Hp面での 気候データ 雷雨になる 可能性の指数 嵐の強さ (指数) 海面気圧 海面気圧の前日 からの変化 降水量 データ型 date float float float float float float float float 数 1 26 26 14 1 1 1 1 1 オゾンレベル bit 1
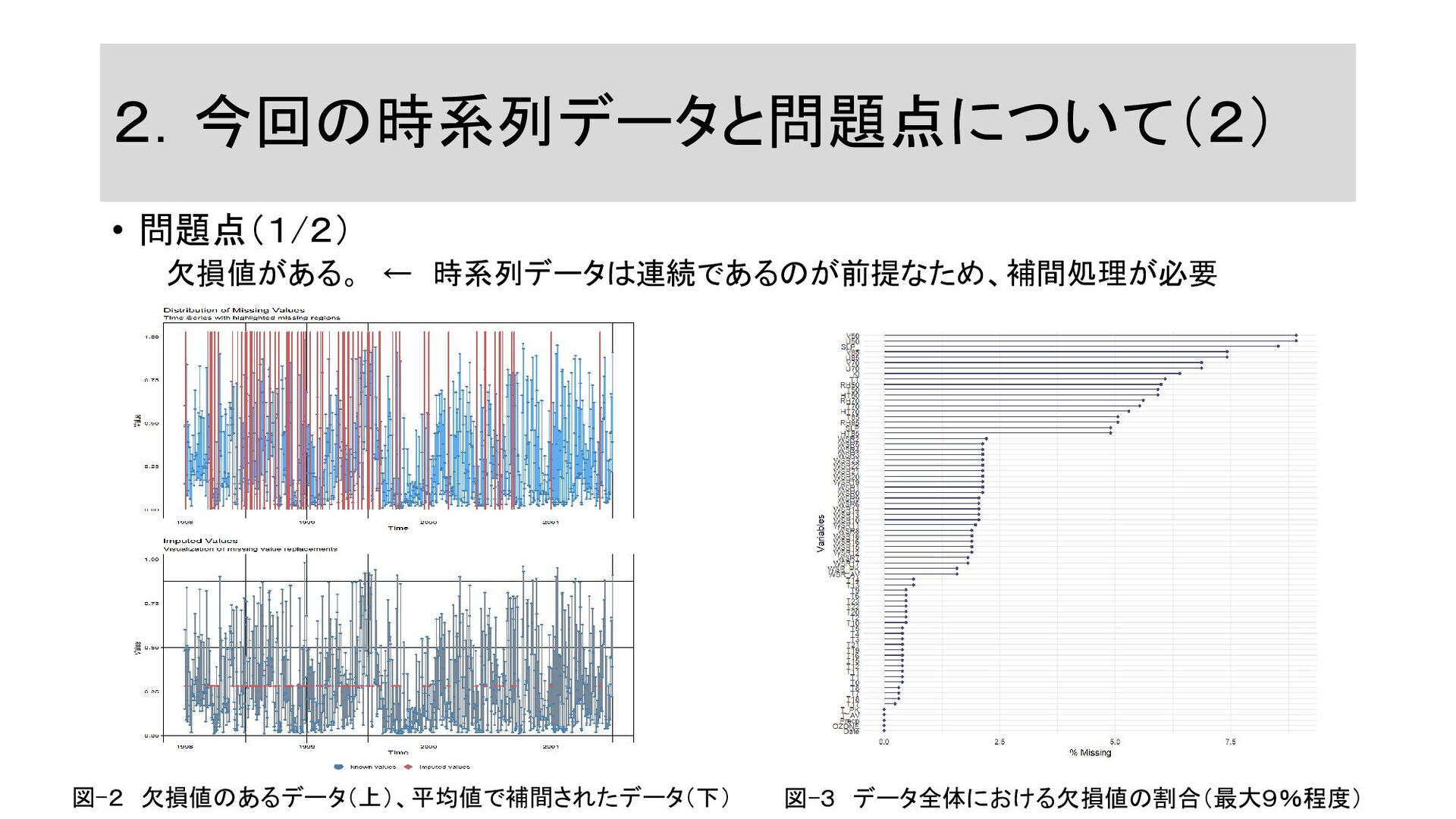
2.今回の時系列データと問題点について(2) • 問題点(1/2) 欠損値がある。 ← 時系列データは連続であるのが前提なため、補間処理が必要 図-2 欠損値のあるデータ(上)、平均値で補間されたデータ(下) 図-3 データ全体における欠損値の割合(最大9%程度)
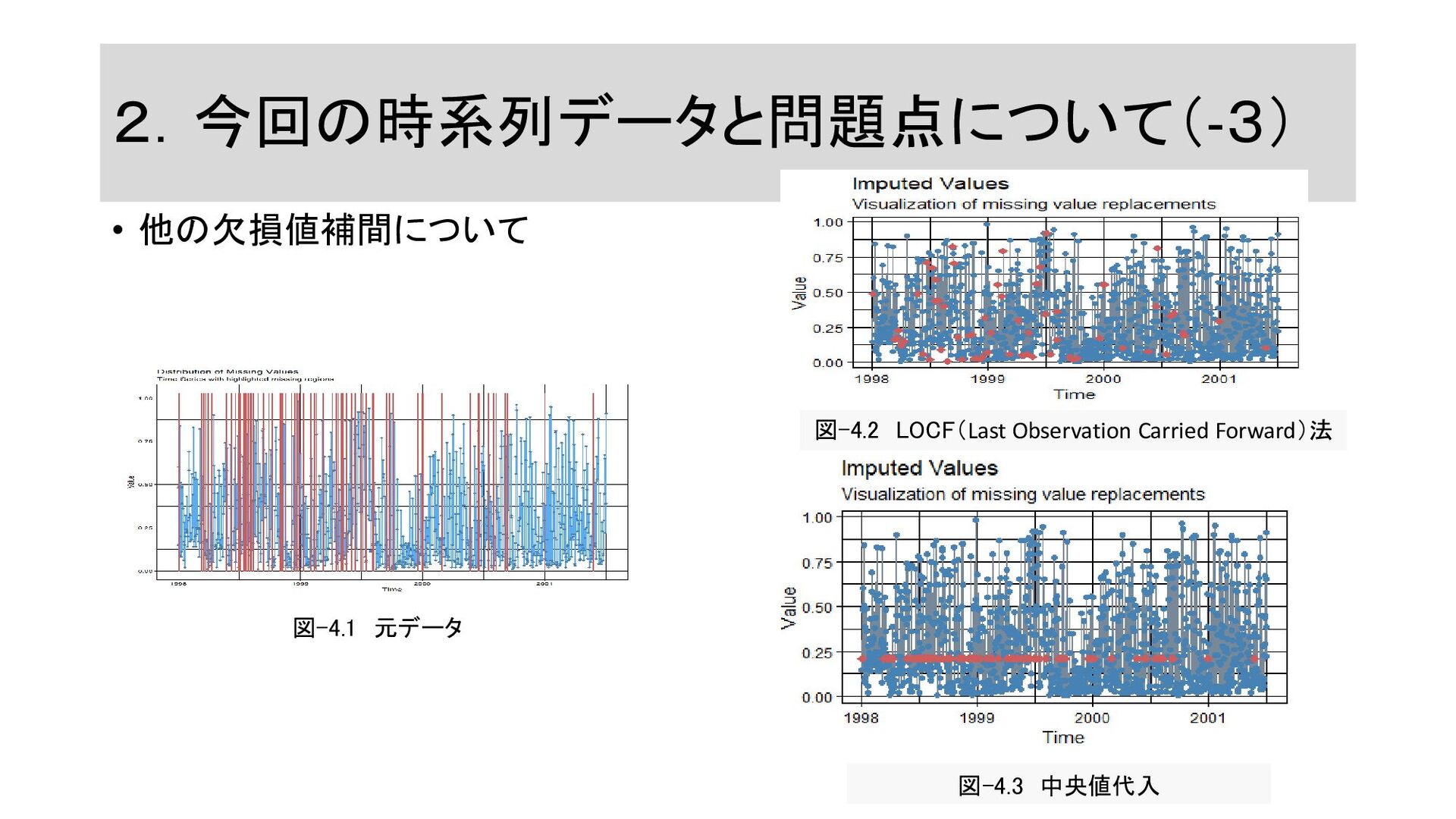
2.今回の時系列データと問題点について(-3) • 他の欠損値補間について 図-4.1 元データ 図-4.2 LOCF(Last Observation Carried Forward)法
図-4.3 中央値代入
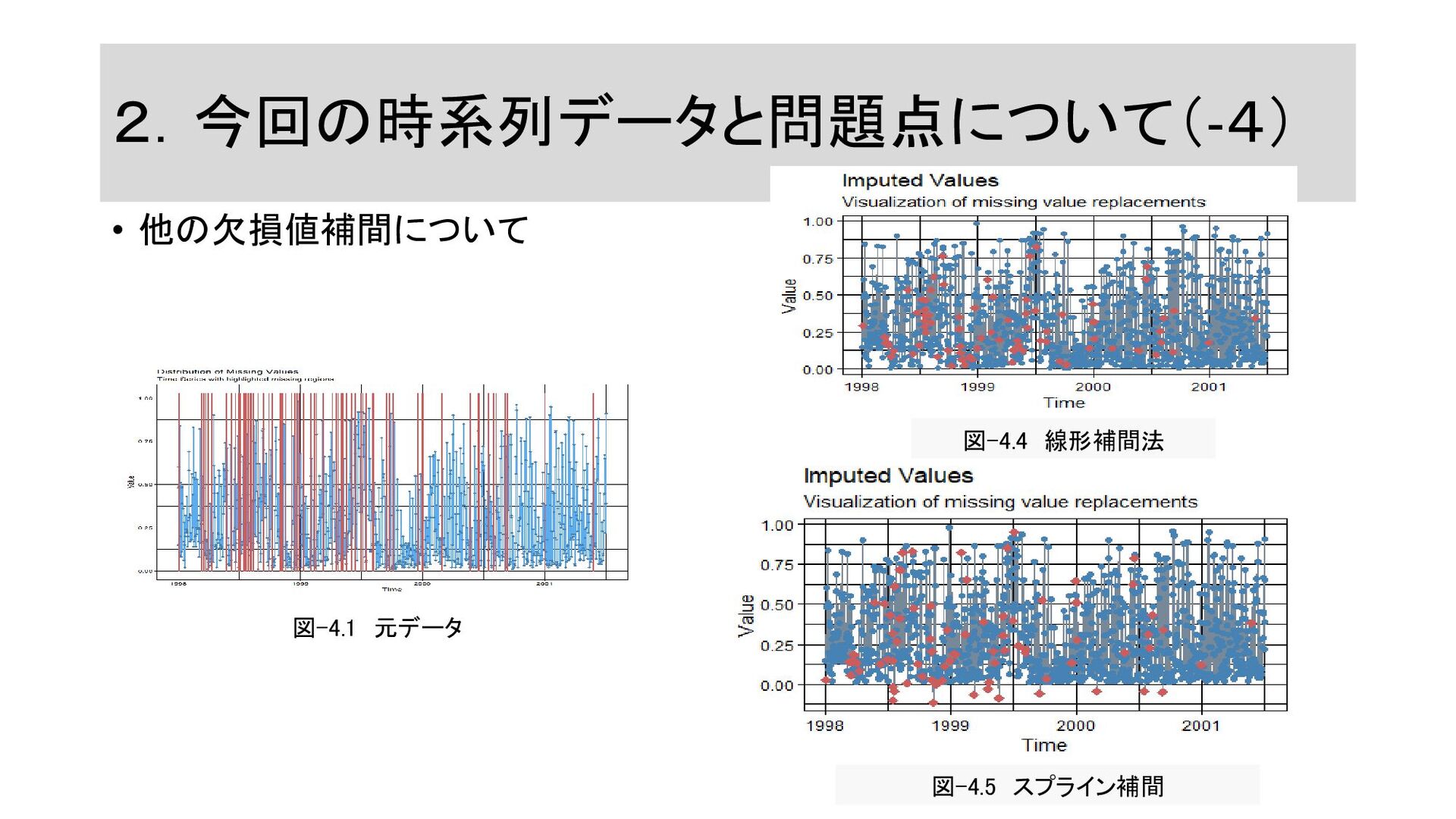
2.今回の時系列データと問題点について(-4) • 他の欠損値補間について 図-4.1 元データ 図-4.5 スプライン補間 図-4.4 線形補間法
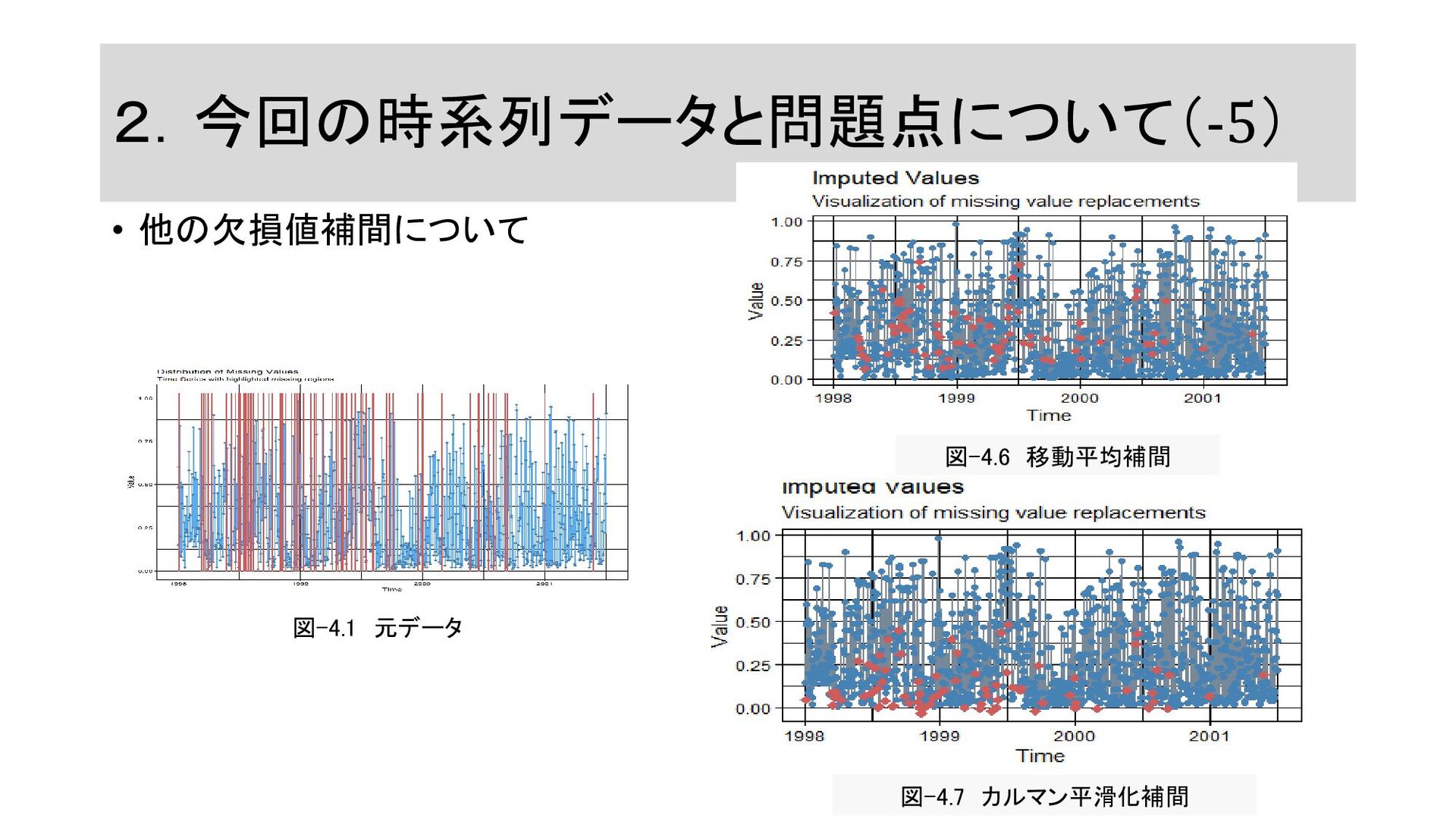
2.今回の時系列データと問題点について(-5) • 他の欠損値補間について 図-4.1 元データ 図-4.7 カルマン平滑化補間 図-4.6 移動平均補間
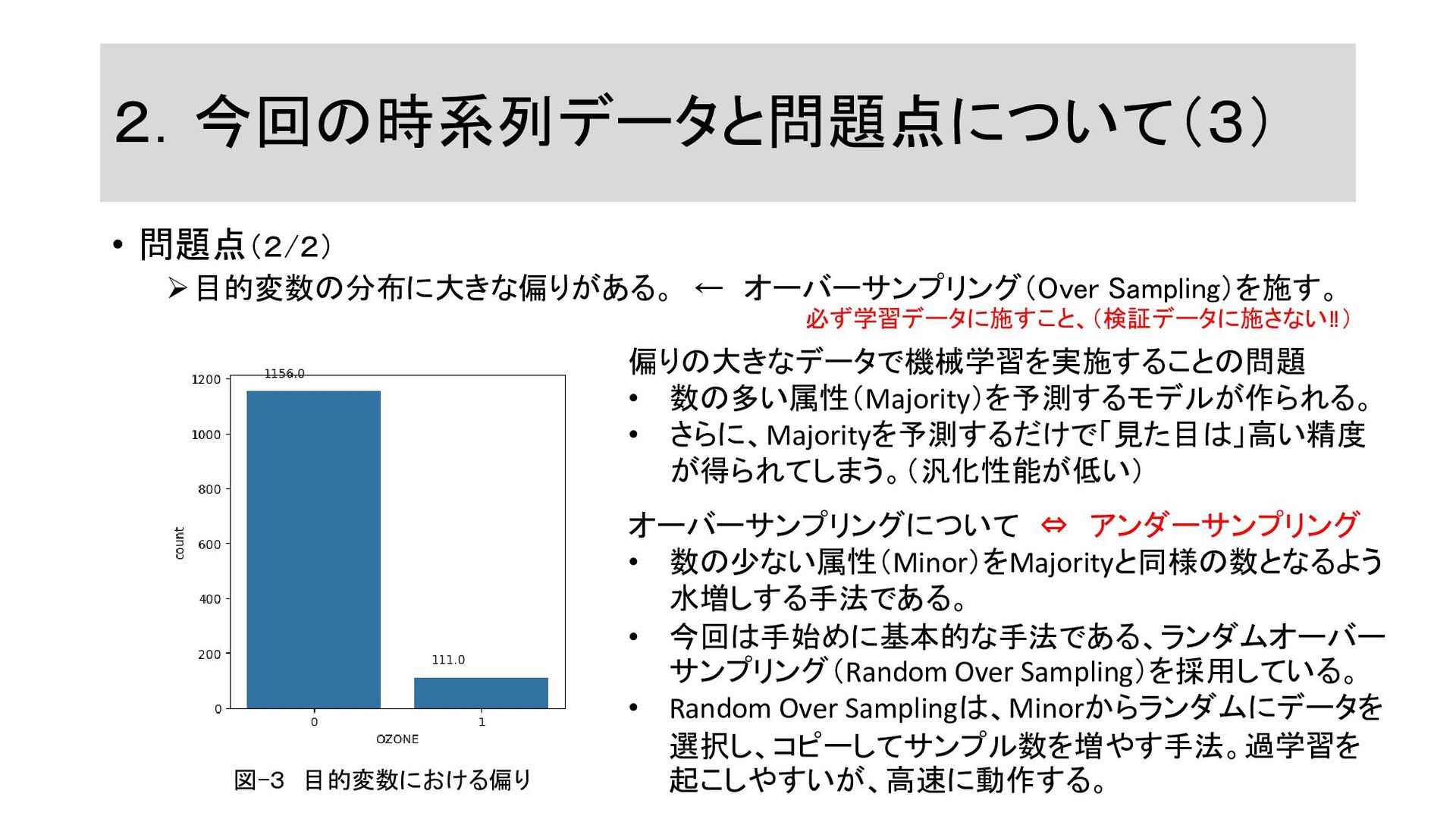
2.今回の時系列データと問題点について(3) • 問題点(2/2) ➢目的変数の分布に大きな偏りがある。 ← オーバーサンプリング(Over Sampling)を施す。 図-3 目的変数における偏り 偏りの大きなデータで機械学習を実施することの問題
• 数の多い属性(Majority)を予測するモデルが作られる。 • さらに、Majorityを予測するだけで「見た目は」高い精度 が得られてしまう。(汎化性能が低い) オーバーサンプリングについて ⇔ アンダーサンプリング • 数の少ない属性(Minor)をMajorityと同様の数となるよう 水増しする手法である。 • 今回は手始めに基本的な手法である、ランダムオーバー サンプリング(Random Over Sampling)を採用している。 • Random Over Samplingは、Minorからランダムにデータを 選択し、コピーしてサンプル数を増やす手法。過学習を 起こしやすいが、高速に動作する。 必ず学習データに施すこと、(検証データに施さない‼)
4.開発環境 • Python 3.10 • Tensorflow 2.15 • Anaconda3 ➢Python
3.11 ✓matplot lib 3.5 ✓numpy 1.21 ✓Pandas 2.0 ✓Scikit-learn 1.4 ✓imbalanced-learn 0.12 ✓LightGBM 3.3 ➢R 4.3.2 • Google Colab(無課金、T4GPU)× 2 (Linux) • Lenovo 「IdeaPad Flex 5 14ALC7 (2022年製)」 (Windows11 HOME) 演算装置:AMD Ryzen 7 5700U with Radeon Graphics 1.80 GHz ➢Frequency ( Base:1.8GHz, Max 4.3GHz ) ➢Cores : 8, Threads : 16, Cache : 4MB L2 / 8MB L3 ソフトウェア ハードウェア
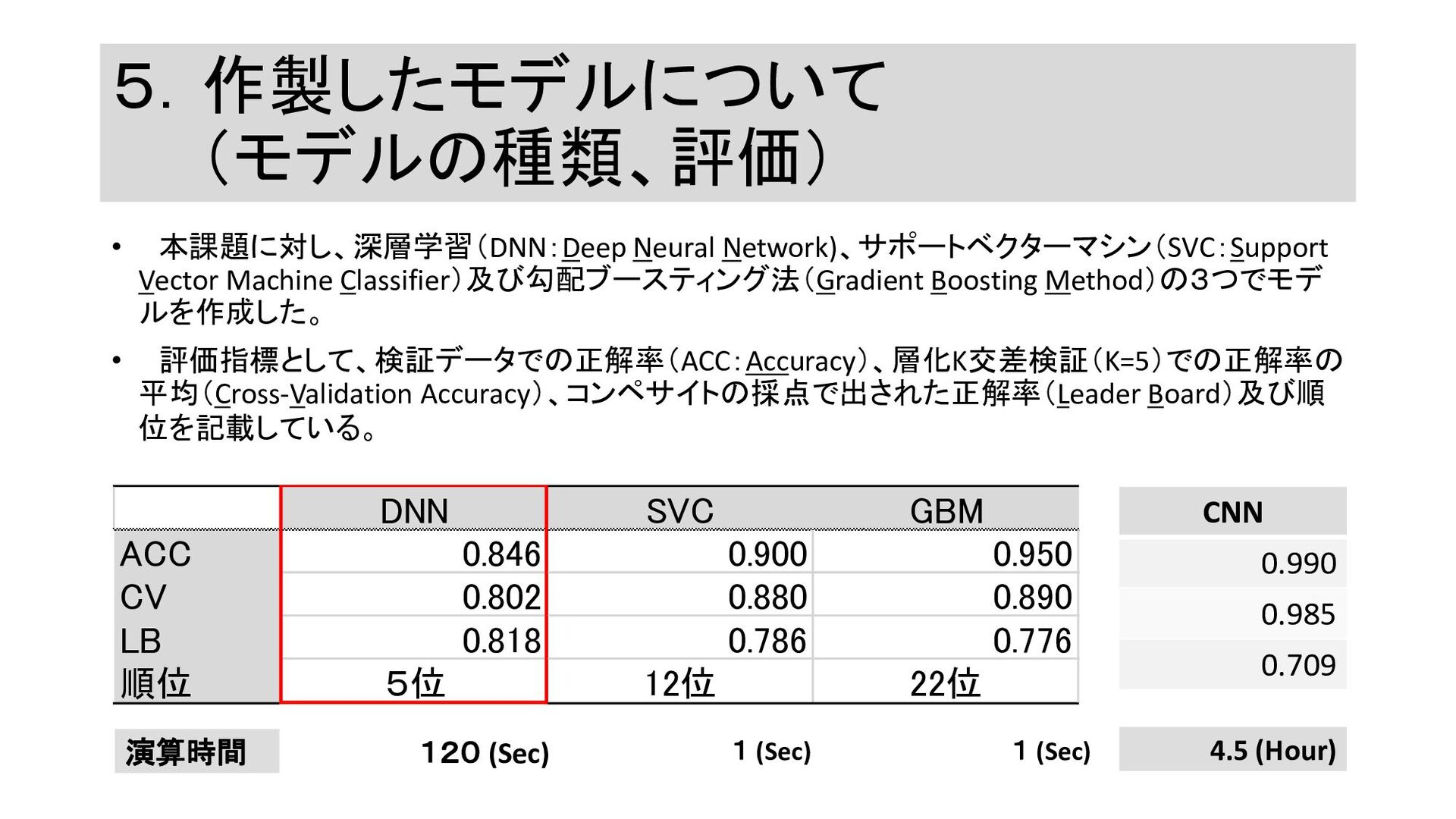
5.作製したモデルについて (モデルの種類、評価) • 本課題に対し、深層学習(DNN:Deep Neural Network)、サポートベクターマシン(SVC:Support Vector Machine Classifier)及び勾配ブースティング法(Gradient Boosting
Method)の3つでモデ ルを作成した。 • 評価指標として、検証データでの正解率(ACC:Accuracy)、層化K交差検証(K=5)での正解率の 平均(Cross-Validation Accuracy)、コンペサイトの採点で出された正解率(Leader Board)及び順 位を記載している。 CNN 0.990 0.985 0.709 演算時間 120 (Sec) 1 (Sec) 1 (Sec) 4.5 (Hour) DNN SVC GBM ACC 0.846 0.900 0.950 CV 0.802 0.880 0.890 LB 0.818 0.786 0.776 順位 5位 12位 22位
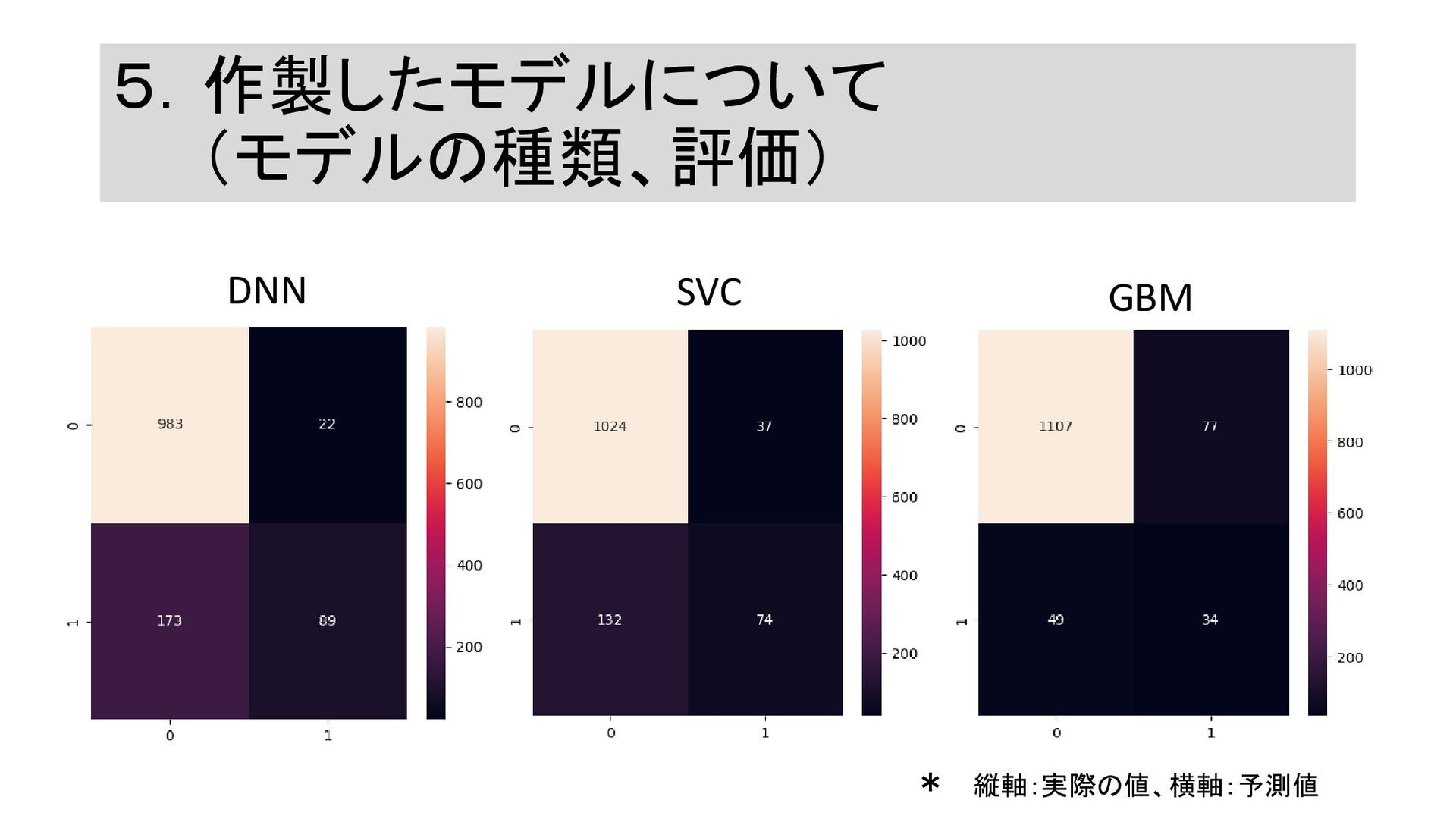
5.作製したモデルについて (モデルの種類、評価) SVC DNN GBM * 縦軸:実際の値、横軸:予測値
6.苦労、実践したこと • 時系列の予測(Forecasting)に関する情報は多いが、分類(Classification)に関する情報 は少ない。 ← 類似案件(時系列分類)の記事を参考にする。 Kaggleの「Credit Card Fraud Detection」(クレジットカードの不正検知)
← "Time-Series Classification"で英語圏のサイトを探索する 英語圏は優良な文献も多いが、情報量が多いので上図に取捨選択しなければならない。 • 欠損値の補間(実装ミスが起こりにくく適切な方法) ← Rとそのライブラリで、欠損値の分布や割合を可視化し、補間手法を検討した。 • 目的変数が大きく偏ったデータを分類するときに使える方法について ← Pythonのライブラリ"Imbalanced-learn"やTensorflowの"dataset"ライブラリで対応。
7.今後の施策(改良点) • 欠損値の補間について → 今回、補間の手法に平均値代入を使った。この方法は基本的なものだが、応用統計学の 分野からは、例えば多重代入法などの、より高精度な補間方法が考案及び実装されてい る。モデルが出来上がったら、こちらを導入して結果がどう変わっていくか検証していきたい。 • オーバーサンプリングの方法について →
今回のオーバーサンプリングはMinorに属するデータをコピーするという、一番単純な方 法だった。この方法は前述のとおり過学習しやすい欠点がある。そして、検証データでは高 い正解率であるモデルほど、反対にコンペでの正答率が低くなっていた。ここから考えられ るのは、与データに対して過学習をしており汎化性能が低くなっているということである。な ので、Minorからデータを合成するSMOTE(Synthetic Minority Over-sampling TEchnique)の 導入から考えている。 オーバーサンプリングの手法をランダムサンプリングからSMOTEに変えて分類(SVC)したが、結果はほぼ変わらず
ご清聴ありがとうございました
参考にした情報源 公式情報 • R 公式ドキュメント(英) ・・・ https://www.r-project.org/ • Tensorflow公式リファレンス(日、英) ・・・
https://www.tensorflow.org/ • Scikit-learn公式ドキュメント(英) ・・・ https://scikit-learn.org/stable/user_guide.html • Imbalanced-leaning 公式ドキュメント(英) ・・・ https://imbalanced-learn.org/stable/index.html ブログなど • Qiita(日) ・・・ https://qiita.com/ • teratail(日) ・・・ https://teratail.com/ • Stack Overflow(日、英) ・・・ https://stackoverflow.com/ • Kaggle(英) ・・・ https://www.kaggle.com/ • Analytics Vidhya(英) ・・・ https://www.analyticsvidhya.com/blog/ • Medium(英) ・・・ https://medium.com/ • GitHub(日、英) ・・・ https://github.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}