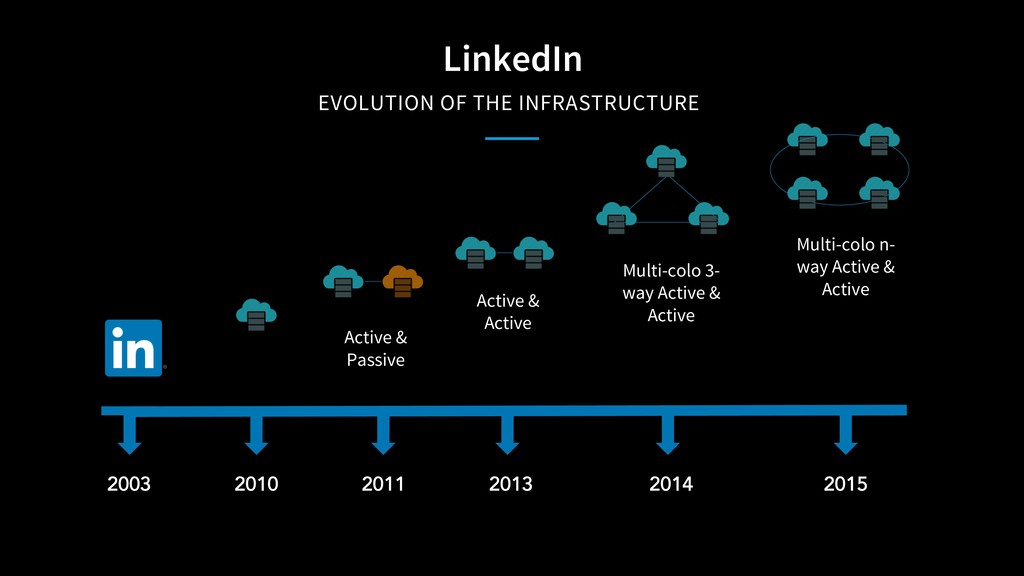
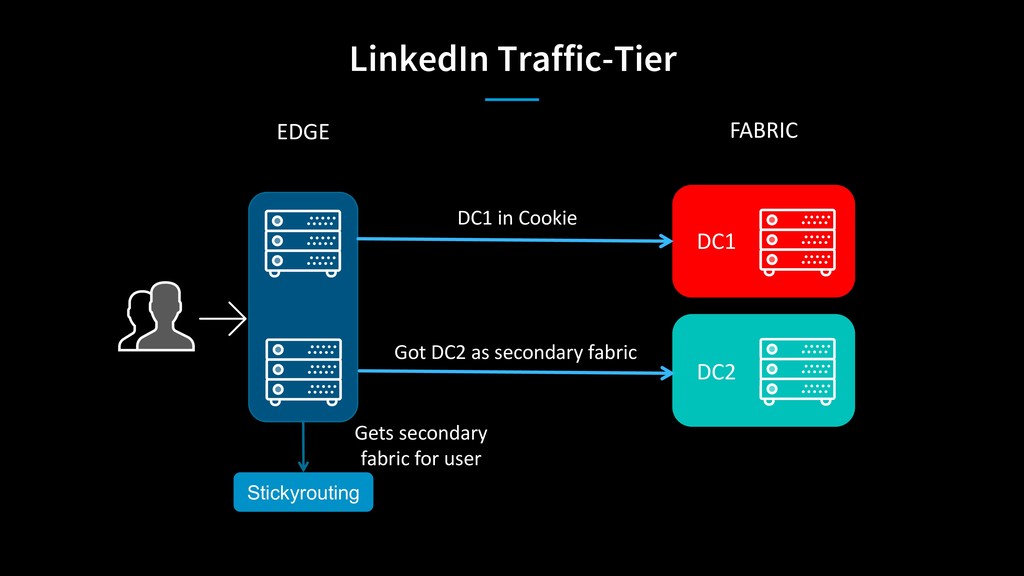
How often have you heard stories where someone thought they had a disaster strategy, never tested it and it fails when you need it the most? LinkedIn has evolved from serving live traffic out of one data center to four data centers spread geographically. Serving live traffic from four data centers at the same time has taken the company from a disaster recovery model to a disaster avoidance model, where an unhealthy data center can be taken out of rotation and its traffic redistributed to the healthy data centers within minutes, with virtually no visible impact to users.
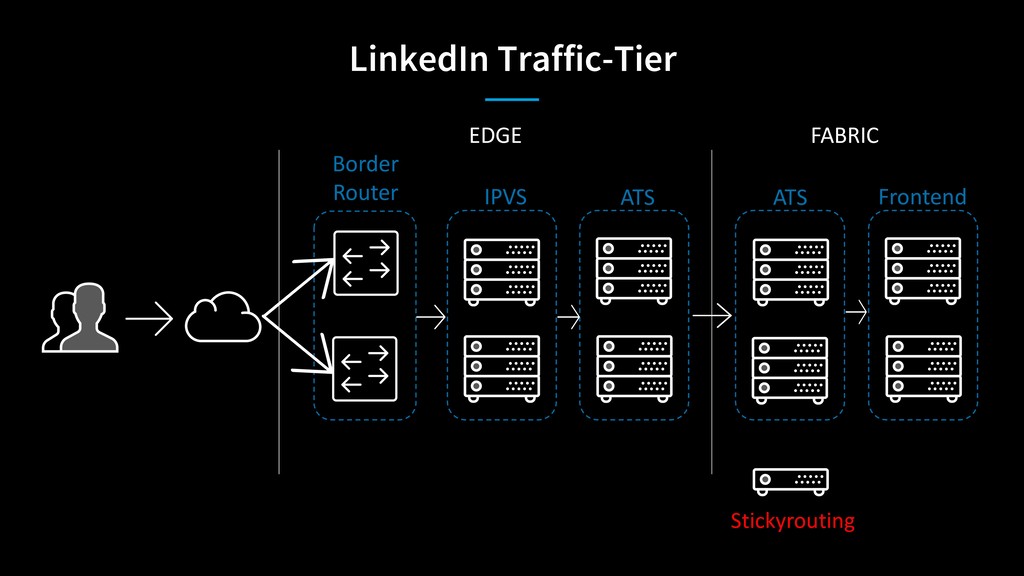
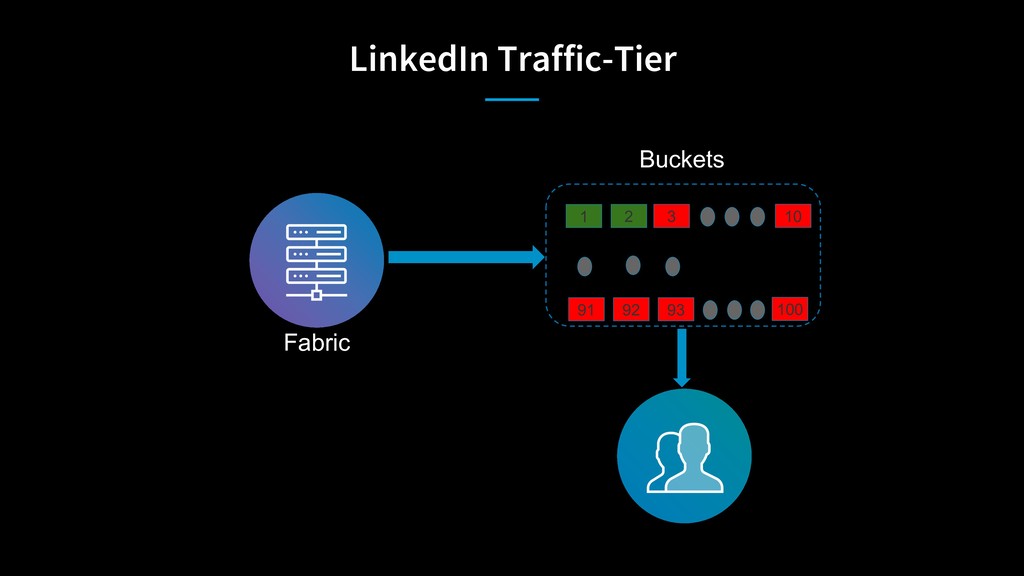
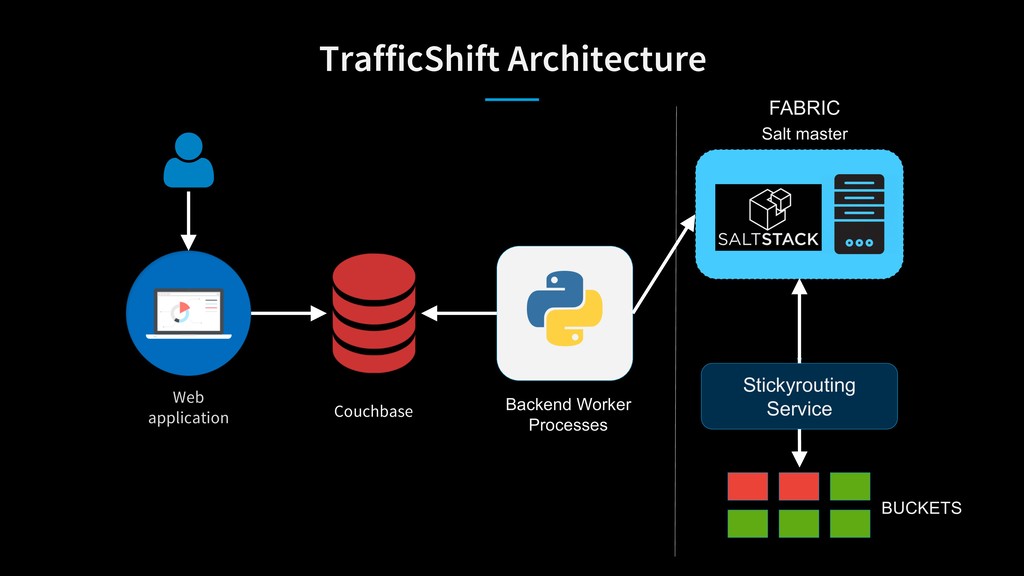
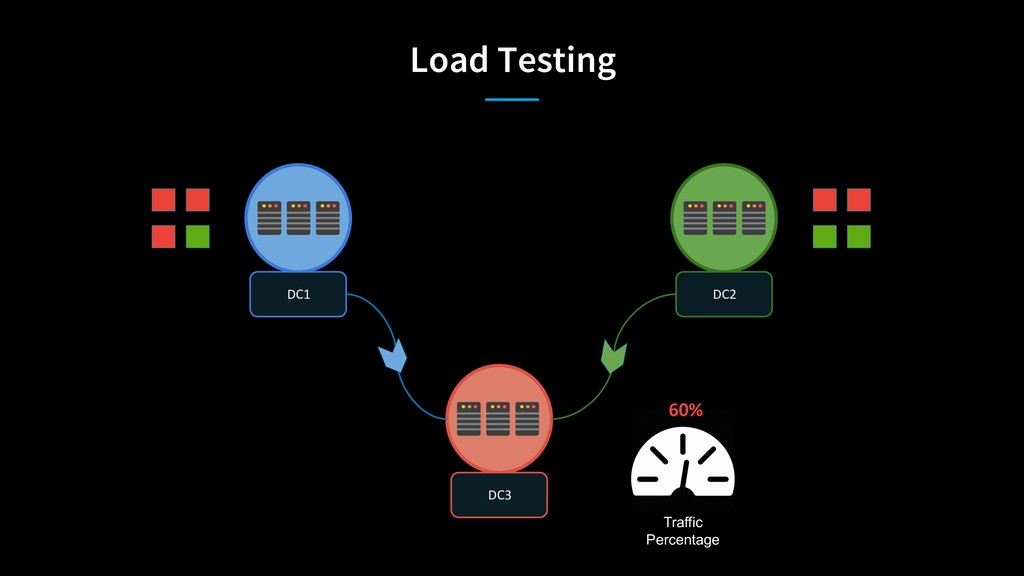
As LinkedIn transitioned from big monolithic applications to microservices, it was difficult to determine capacity constraints of individual services to handle extra load during disaster scenarios. Stress testing individual services using artificial load in a complex microservices architecture wasn’t sufficient to provide enough confidence in data center’s capacity. To solve this problem, LinkedIn moves live traffic to services site-wide by shifting traffic between datacenters to simulate a disaster every business day!
Michael Kehoe will discuss how LinkedIn shifts traffic between its data centers to chaos/ disaster test site-wide services for improved disaster recovery preparation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}