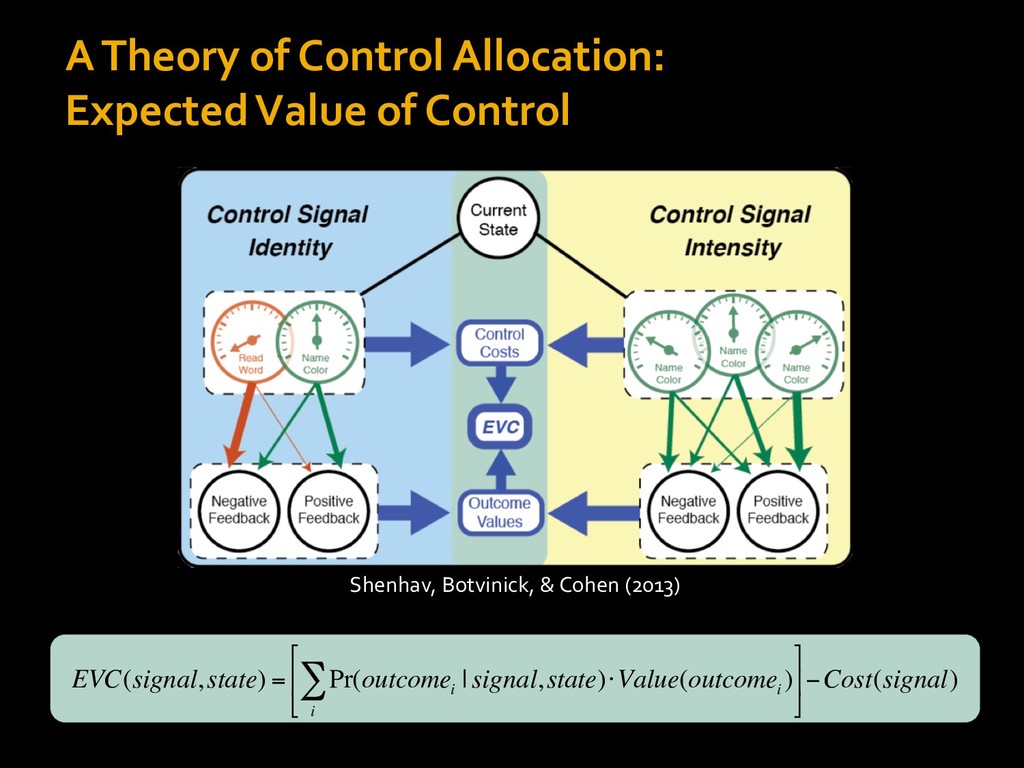
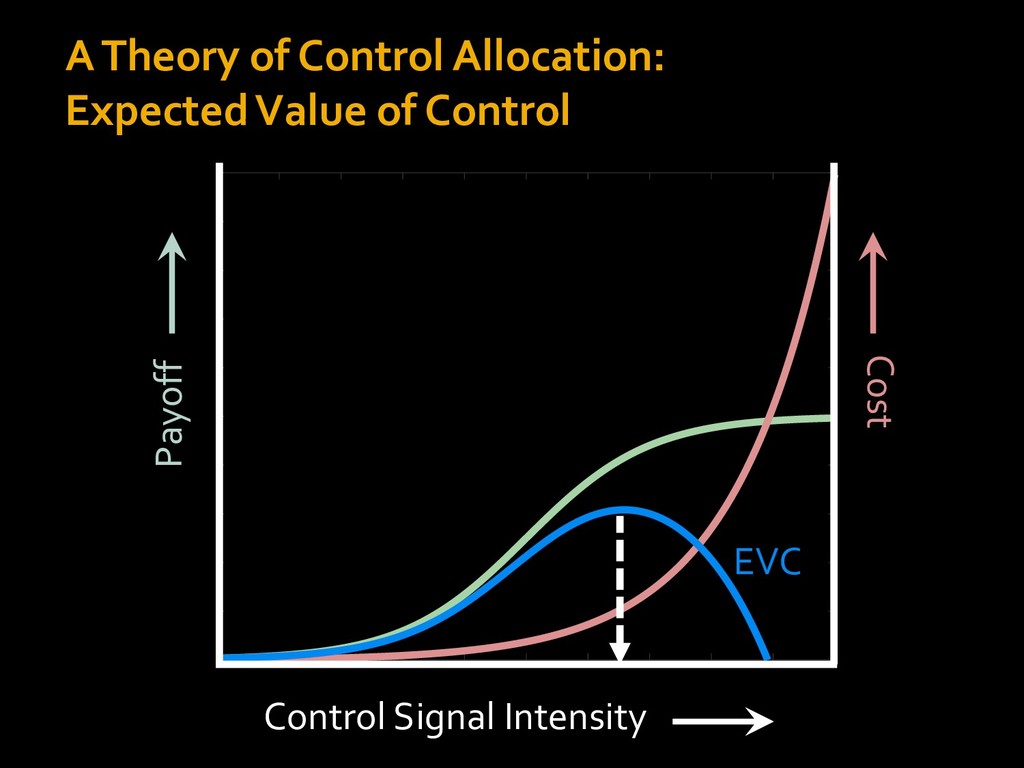
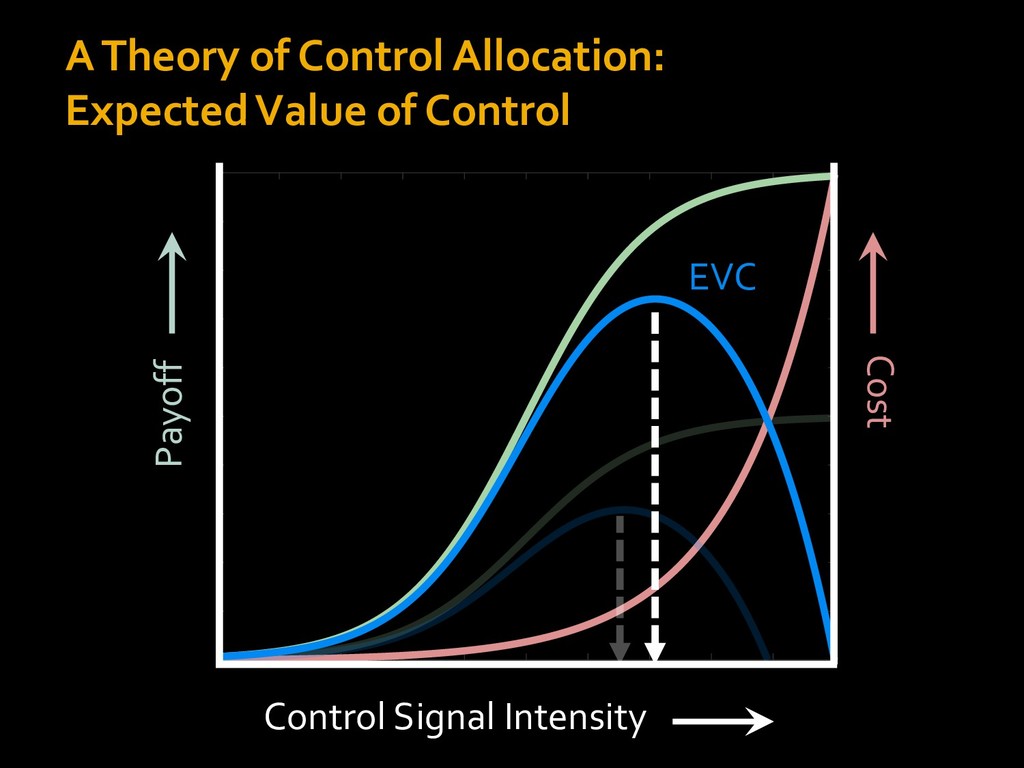
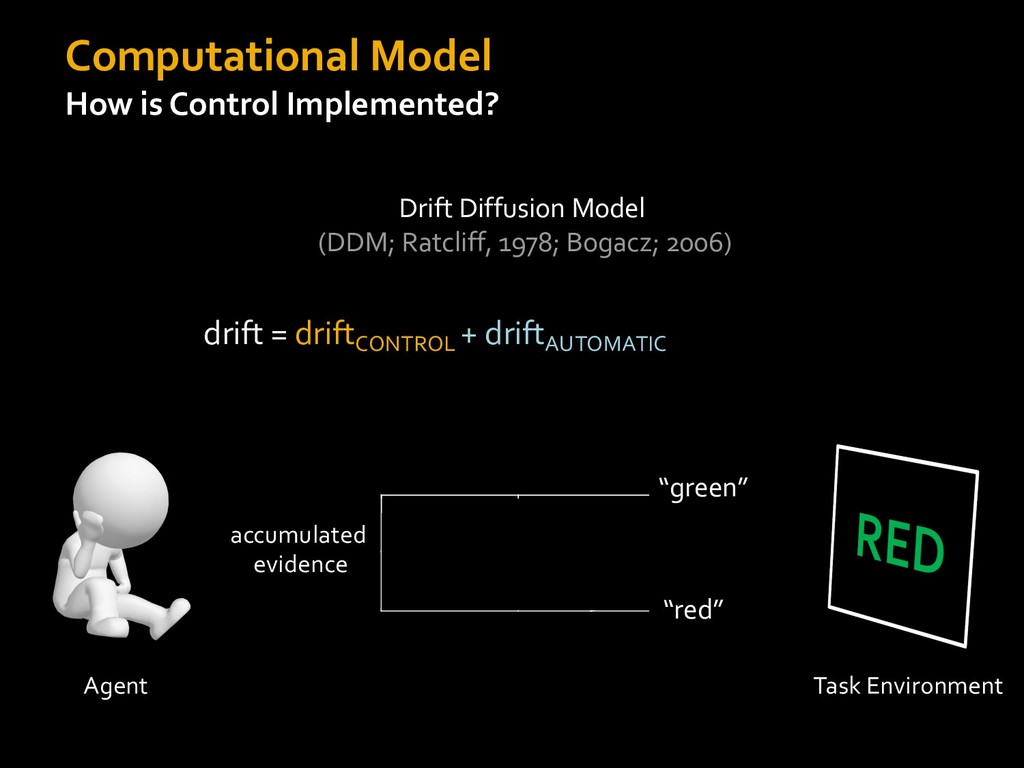
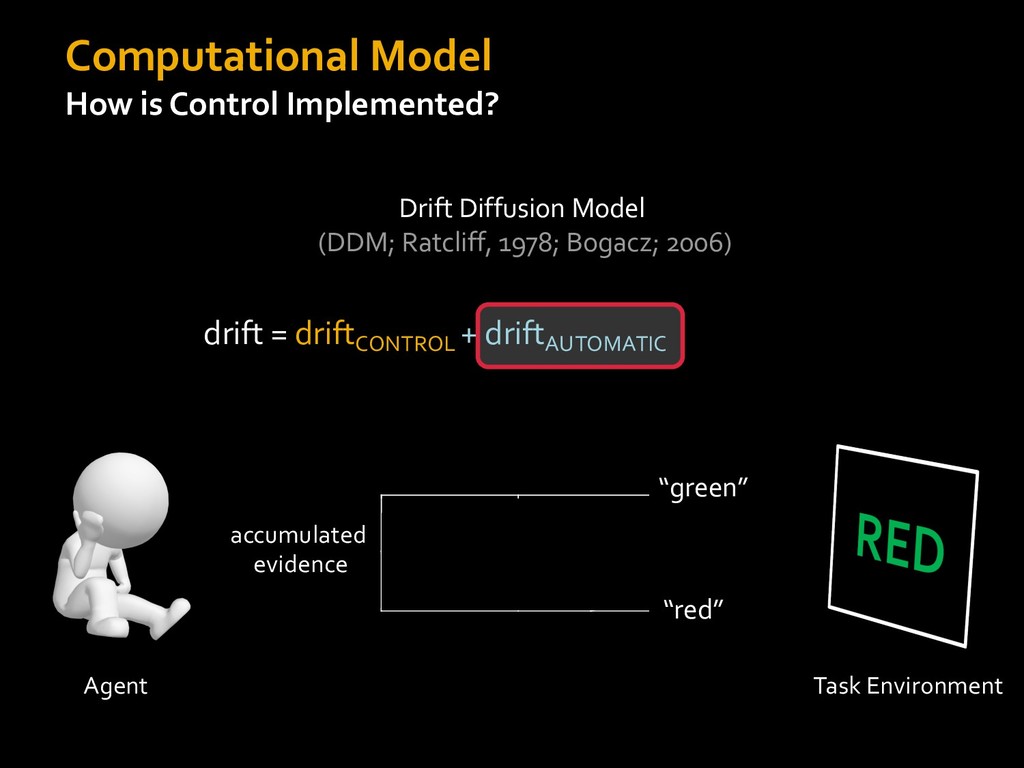
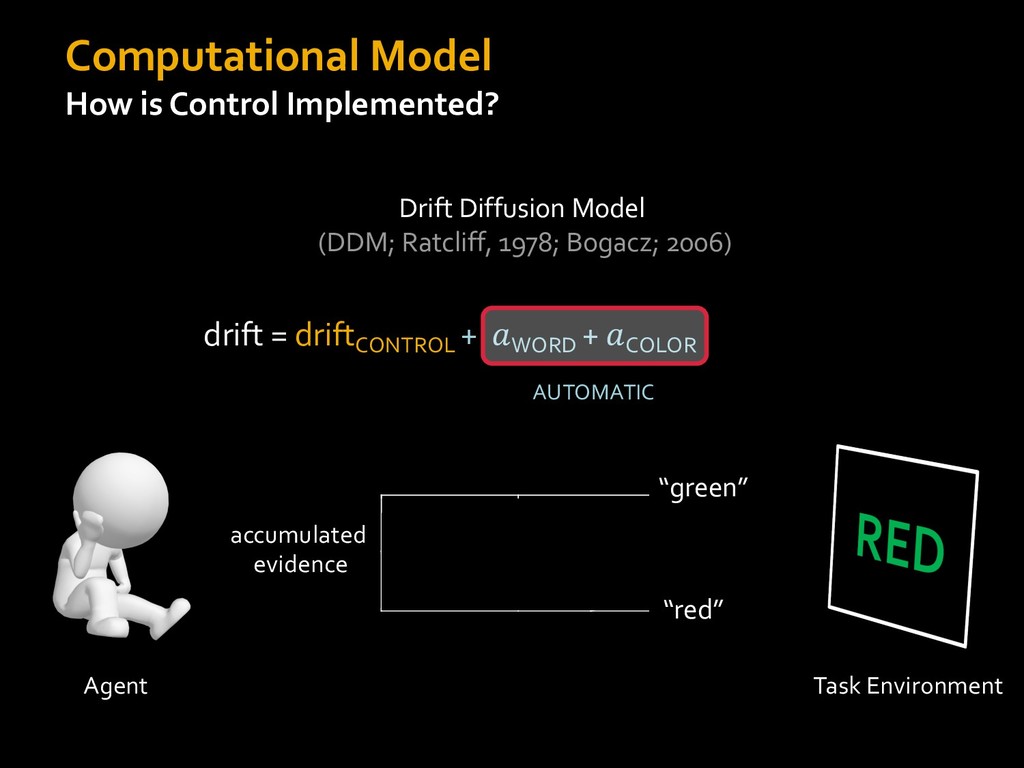
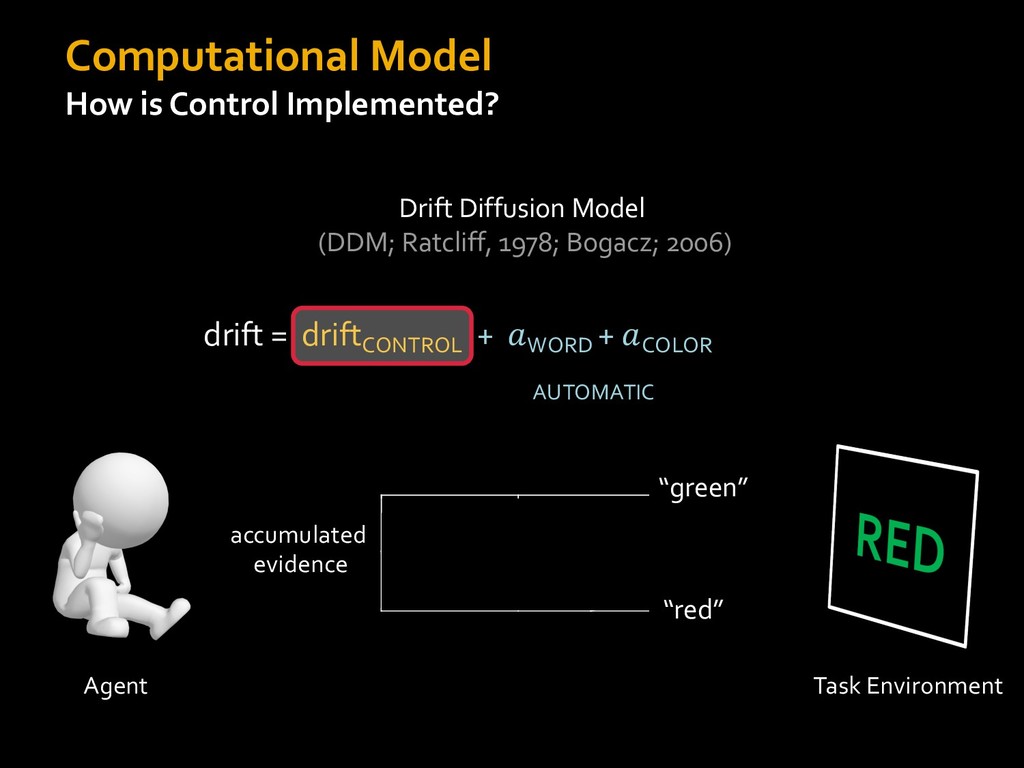
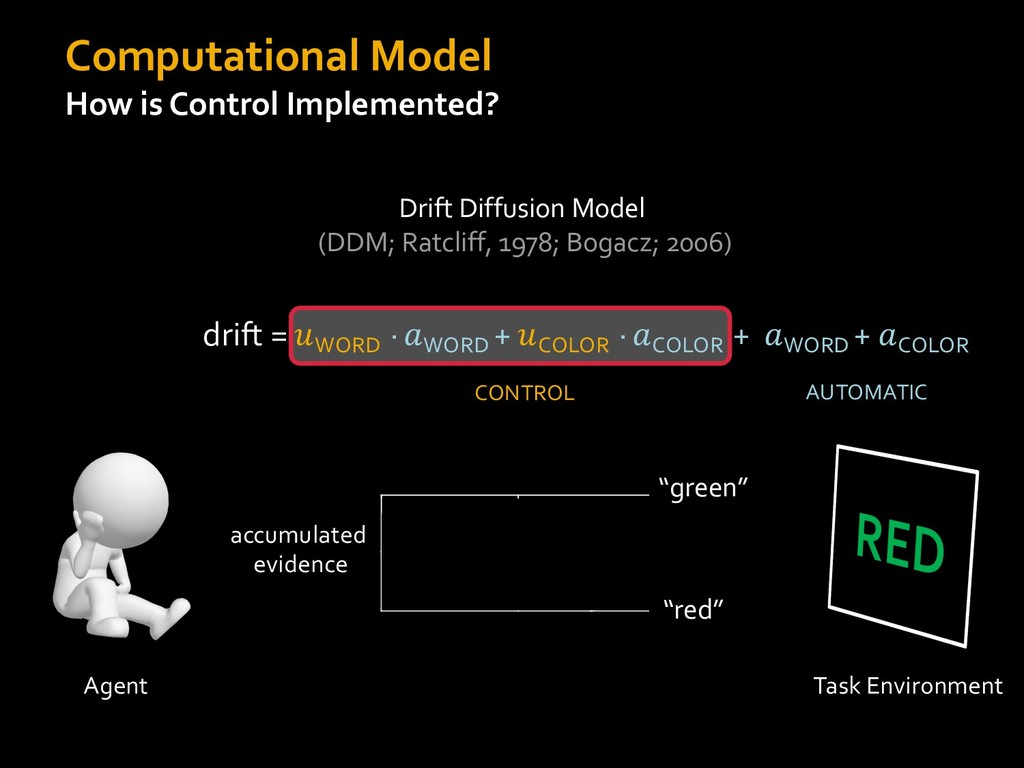
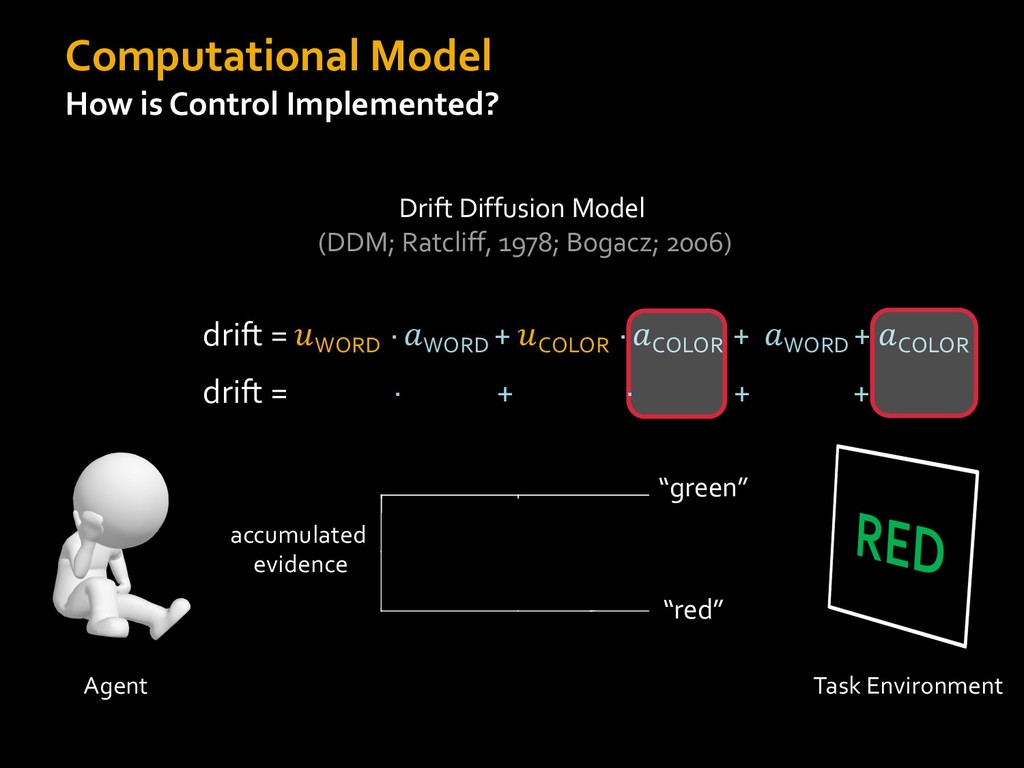
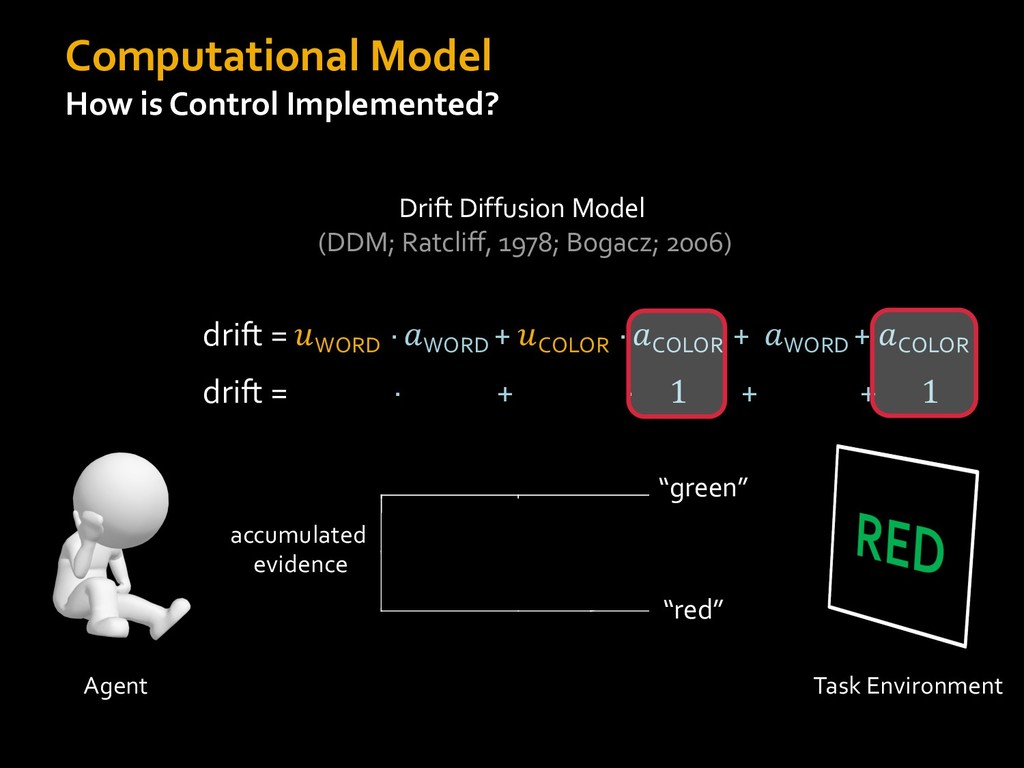
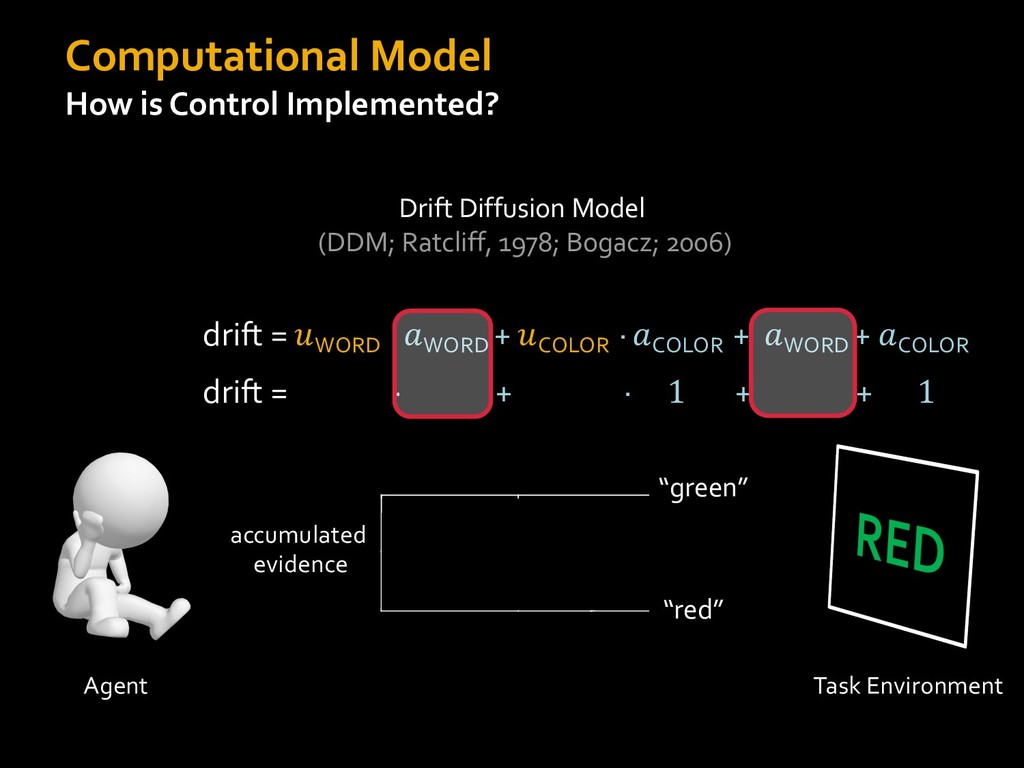
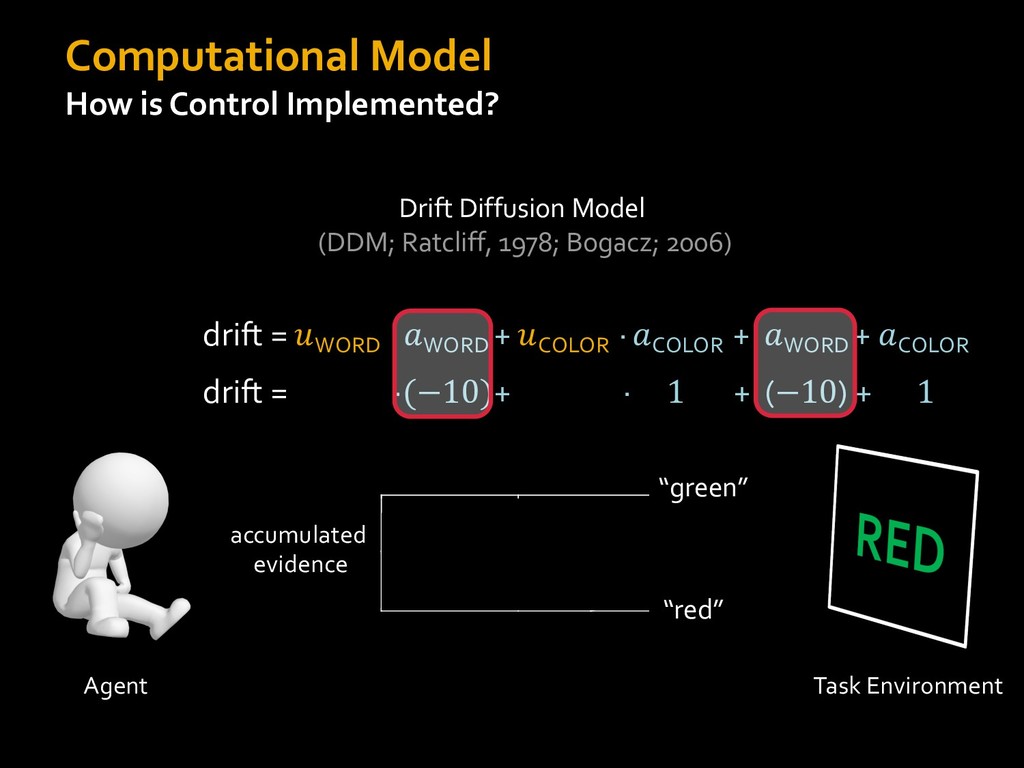
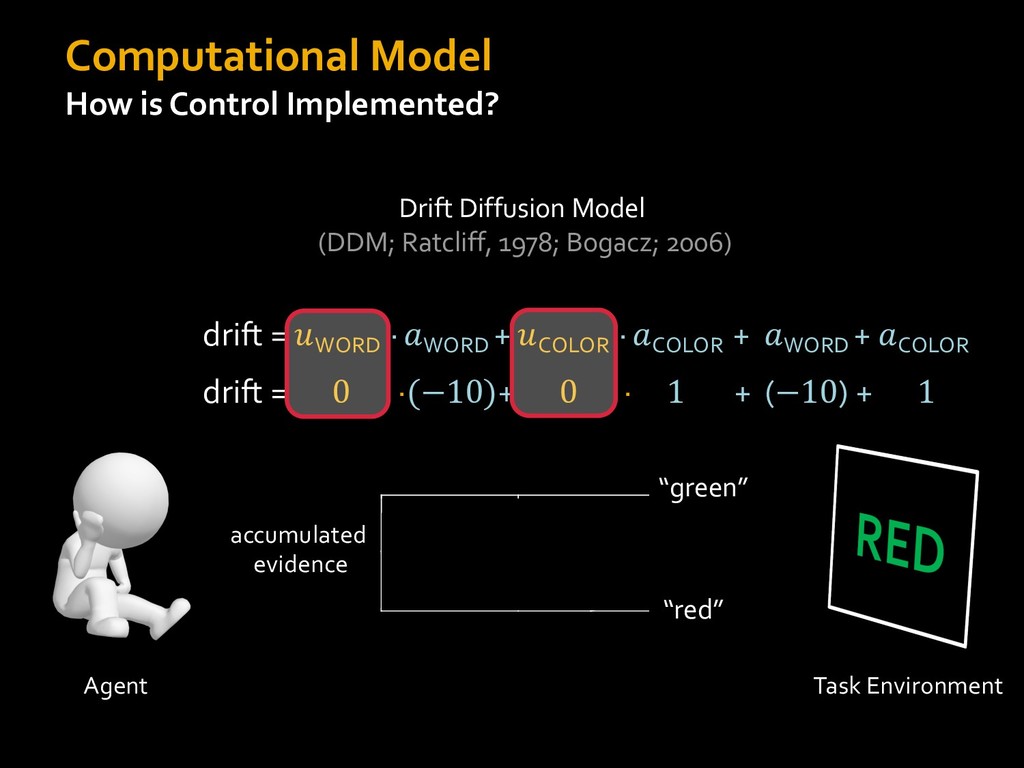
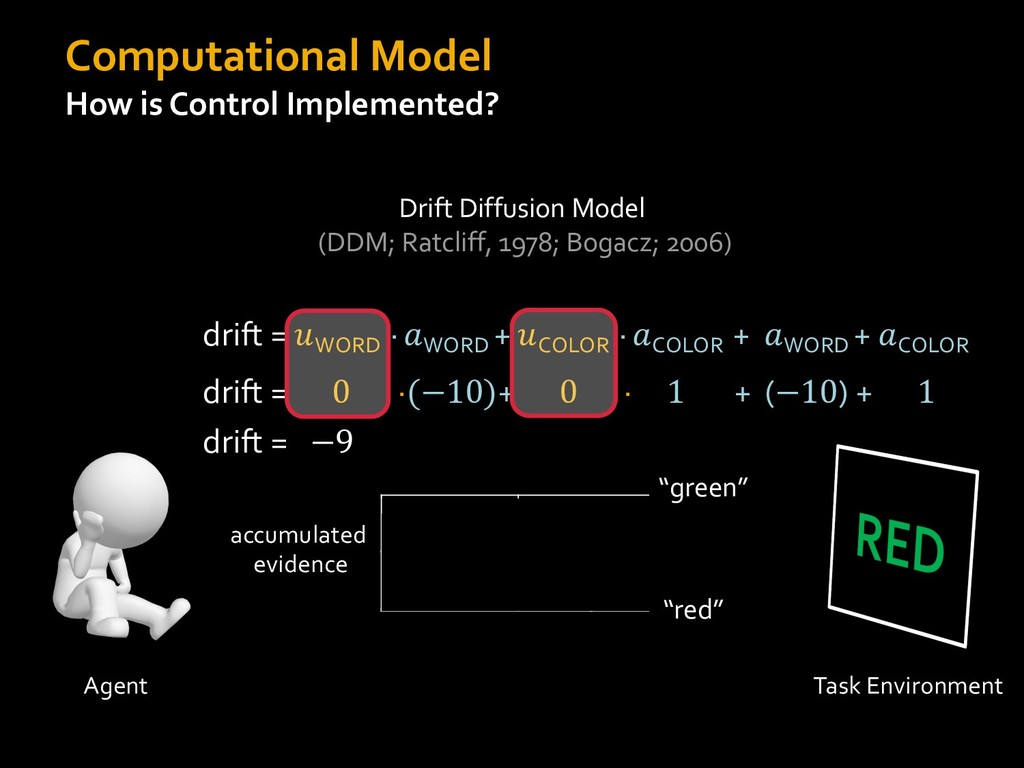
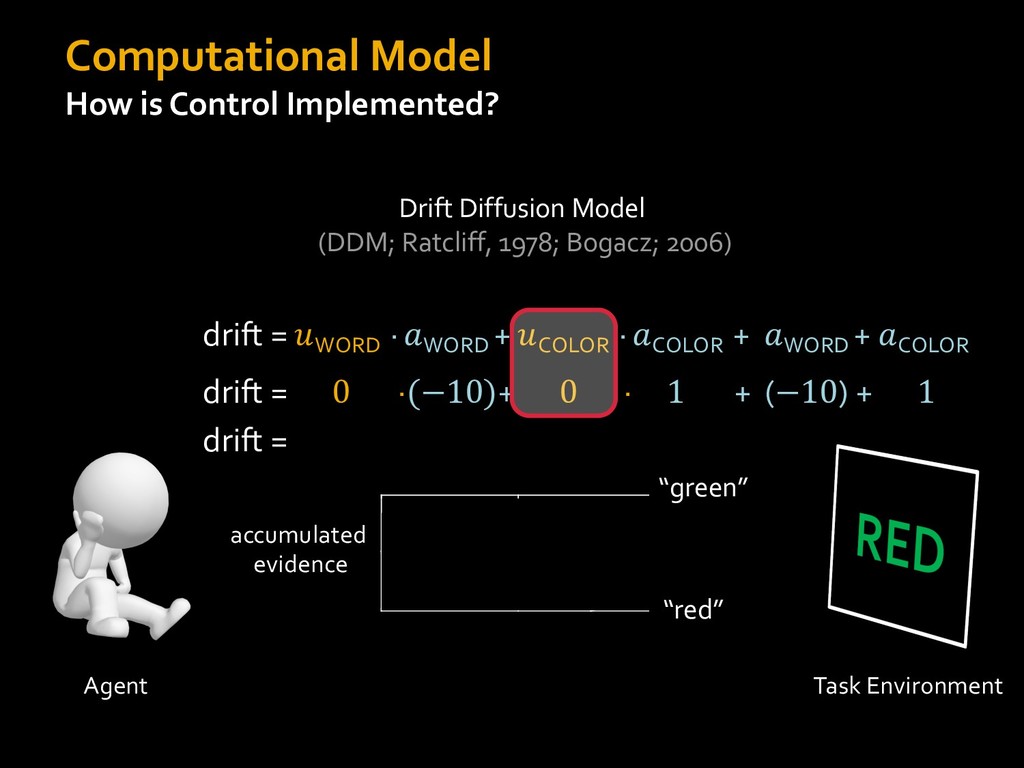
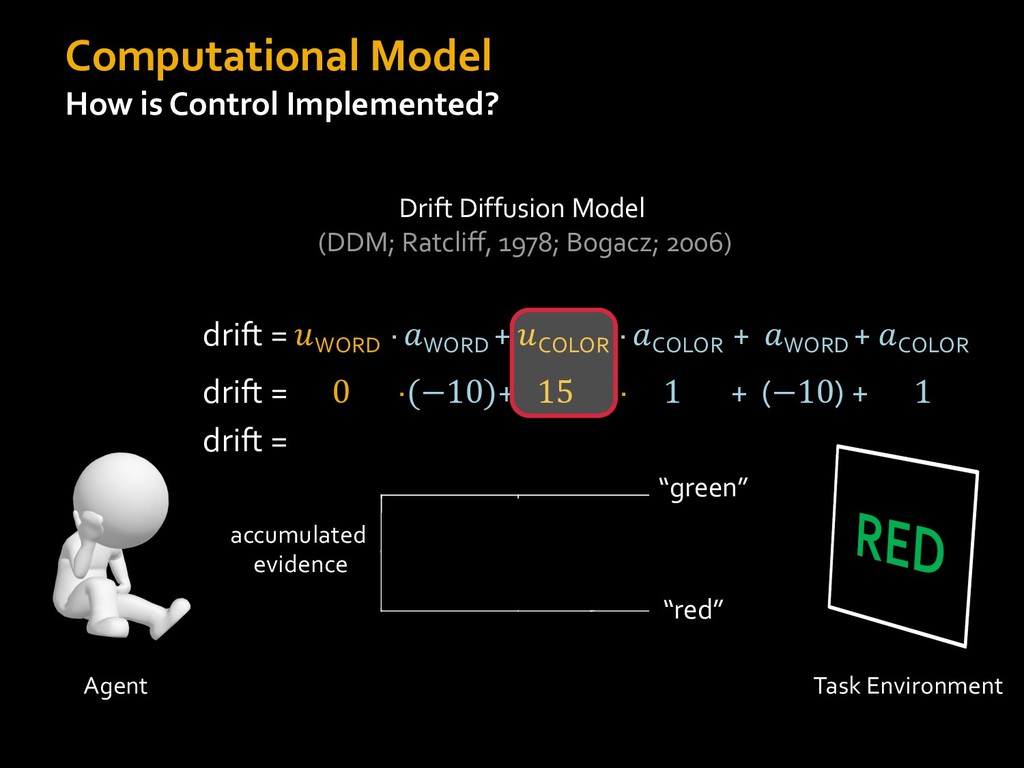
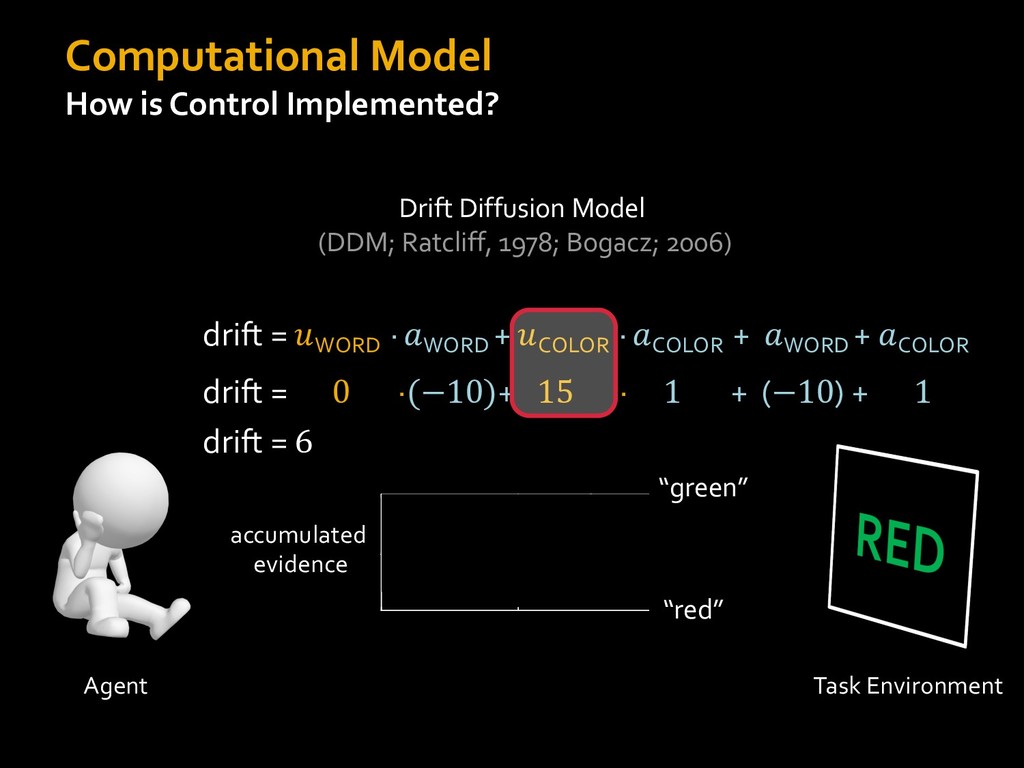
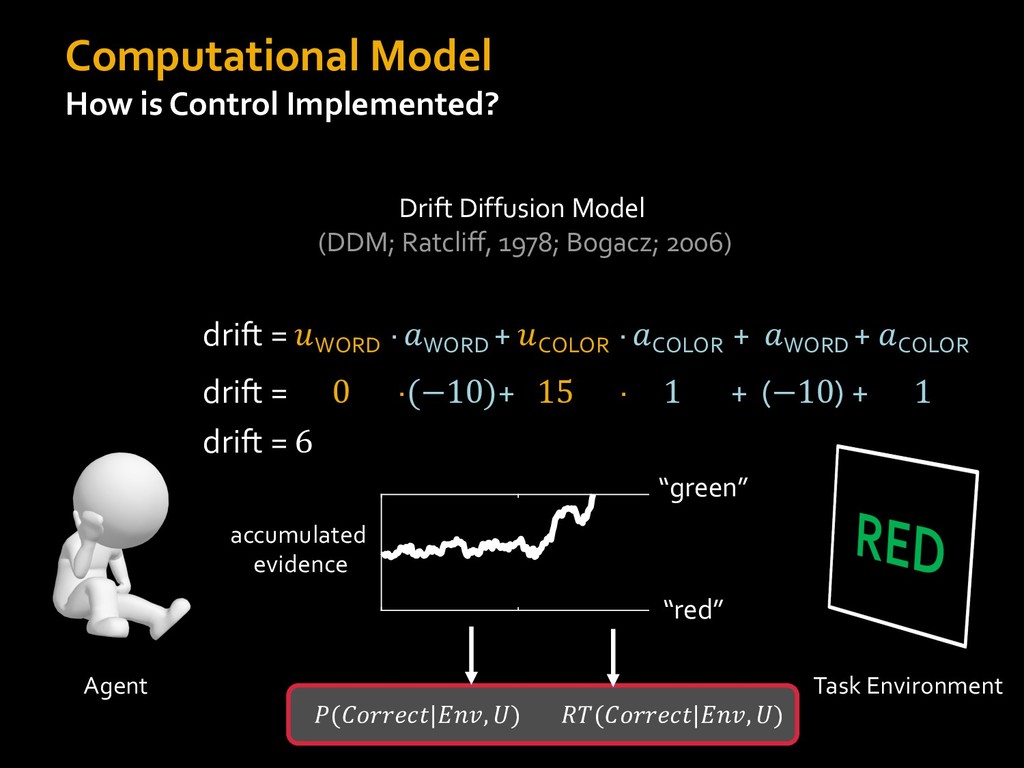
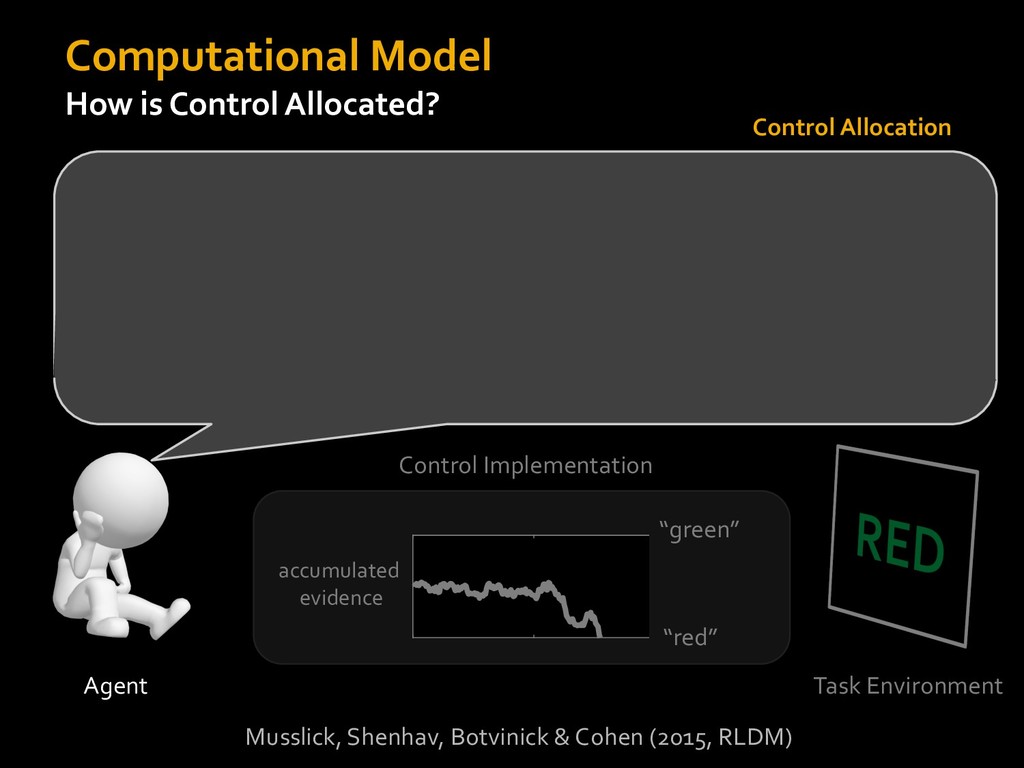
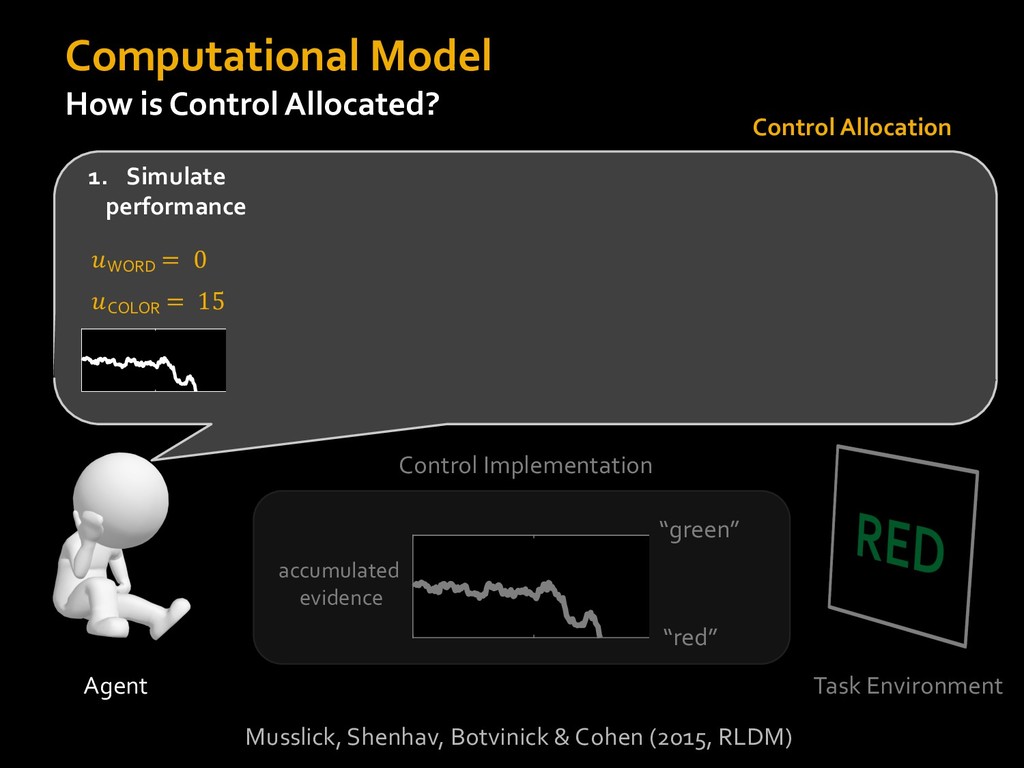
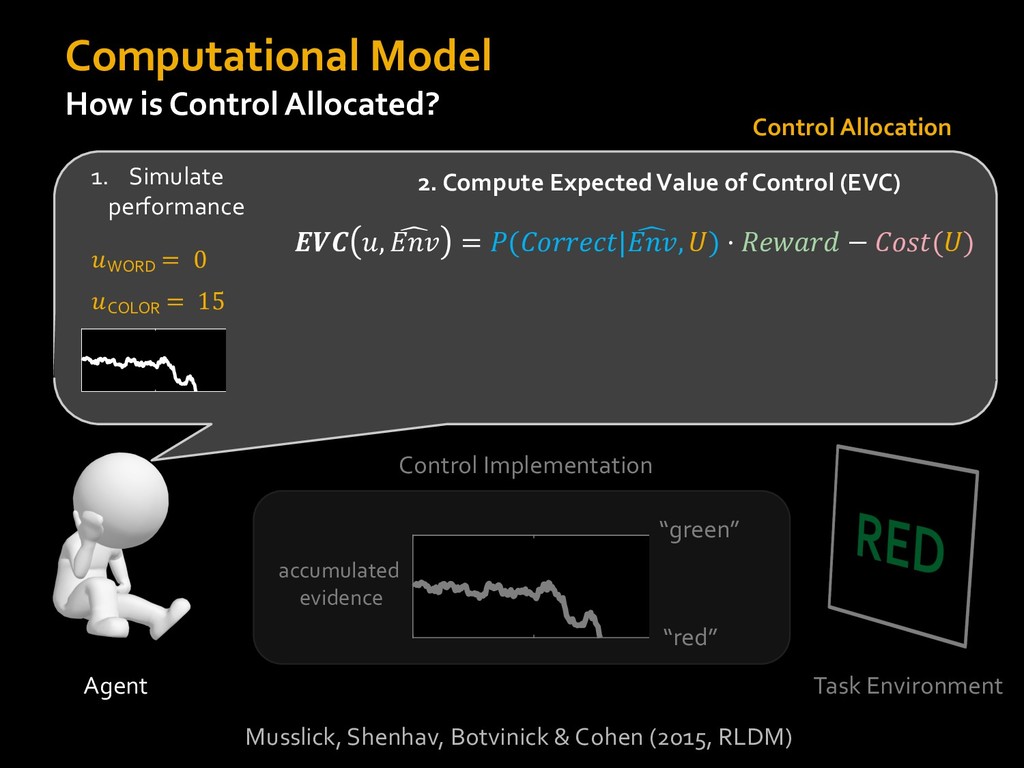
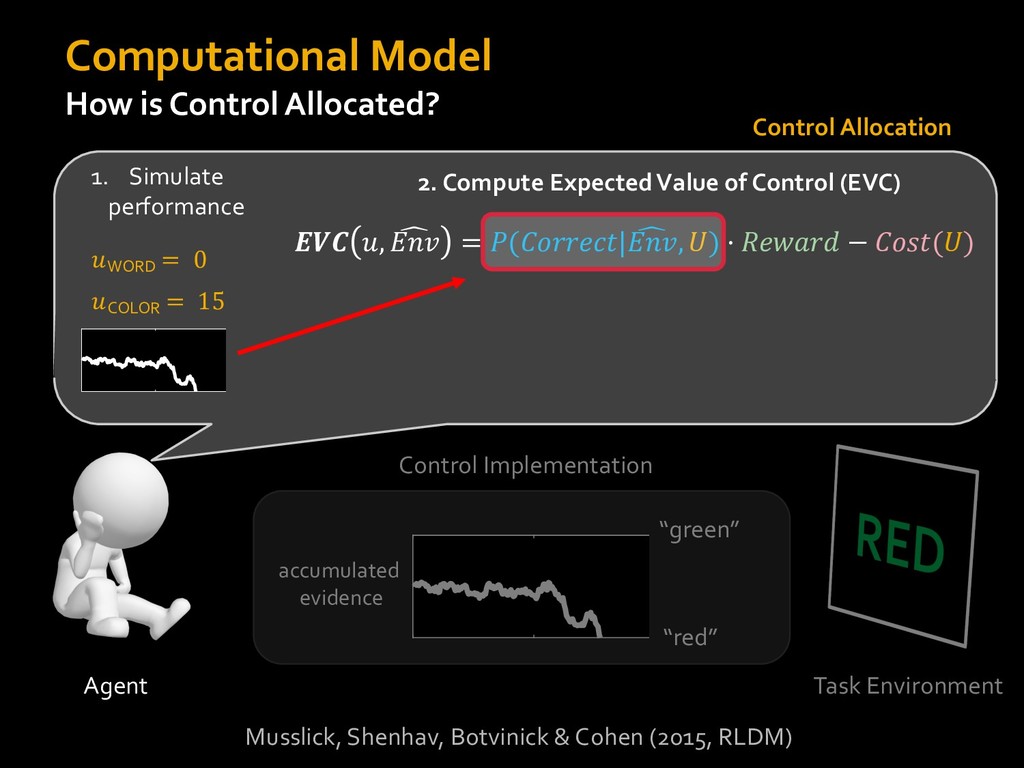
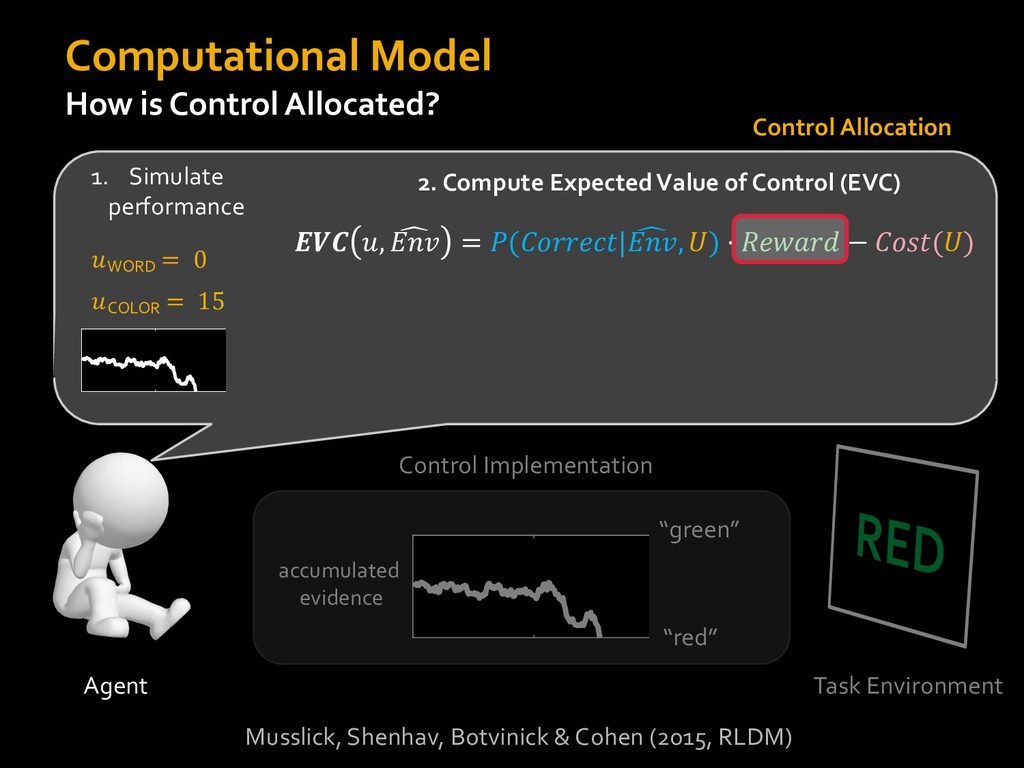
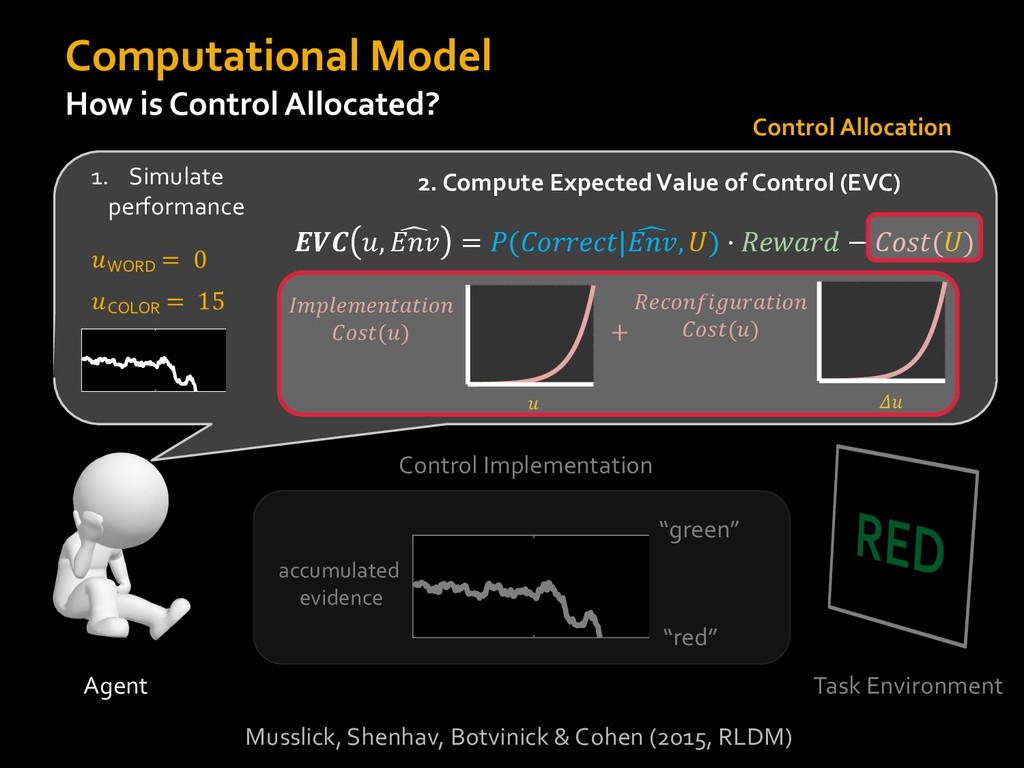
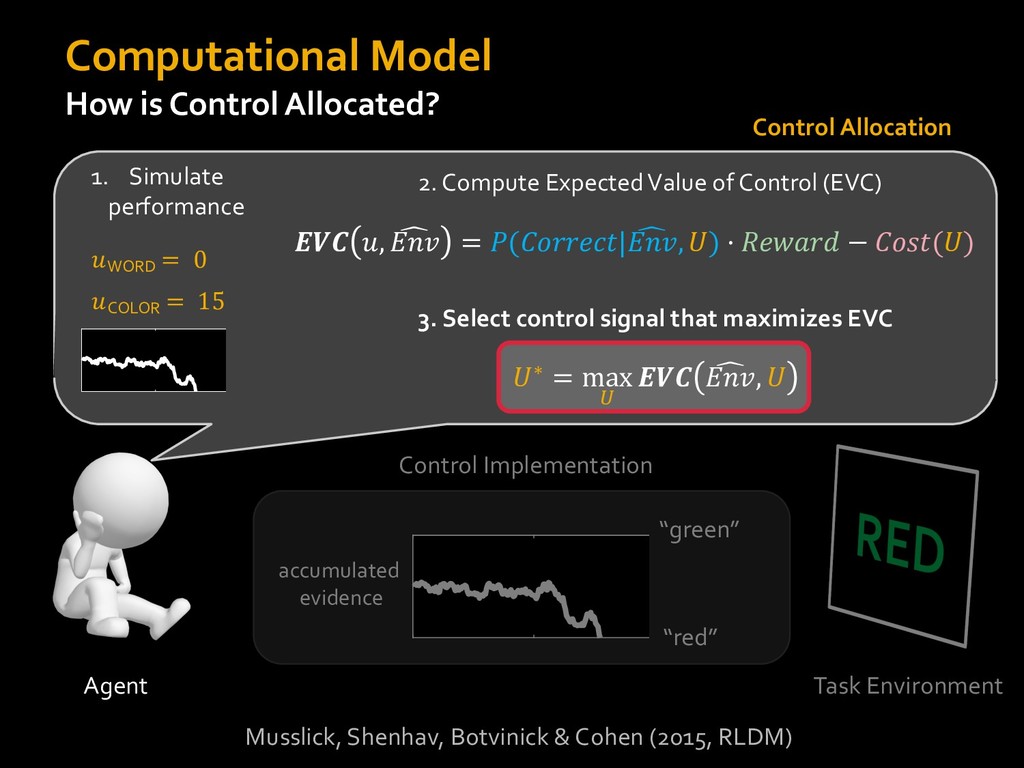
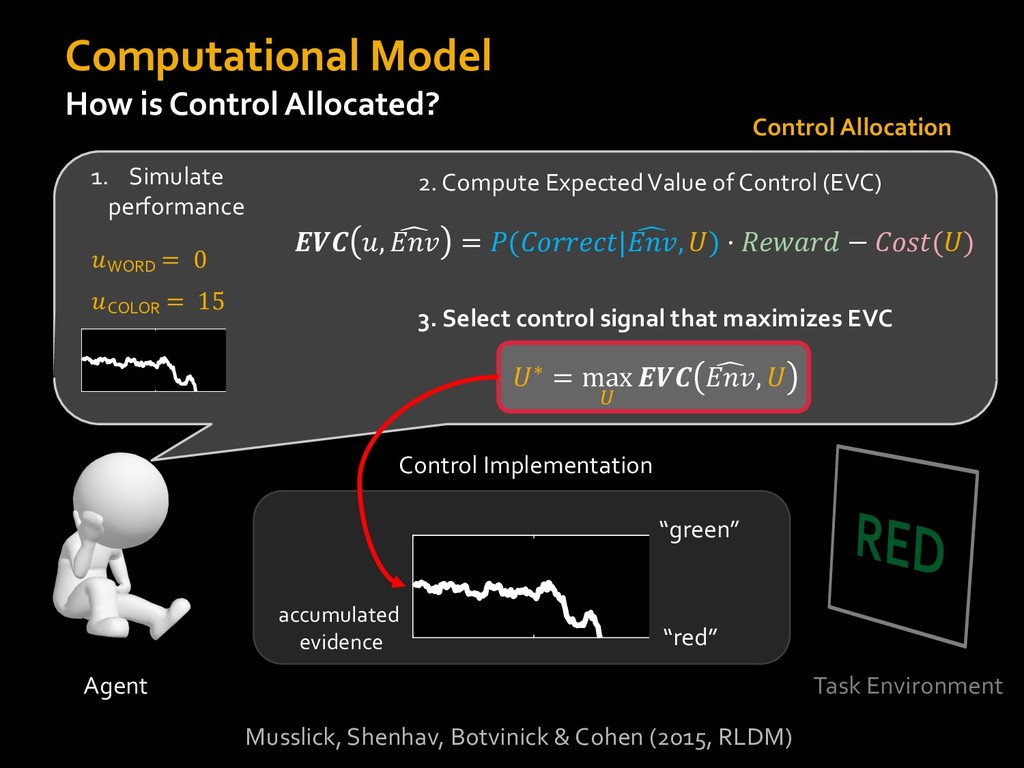
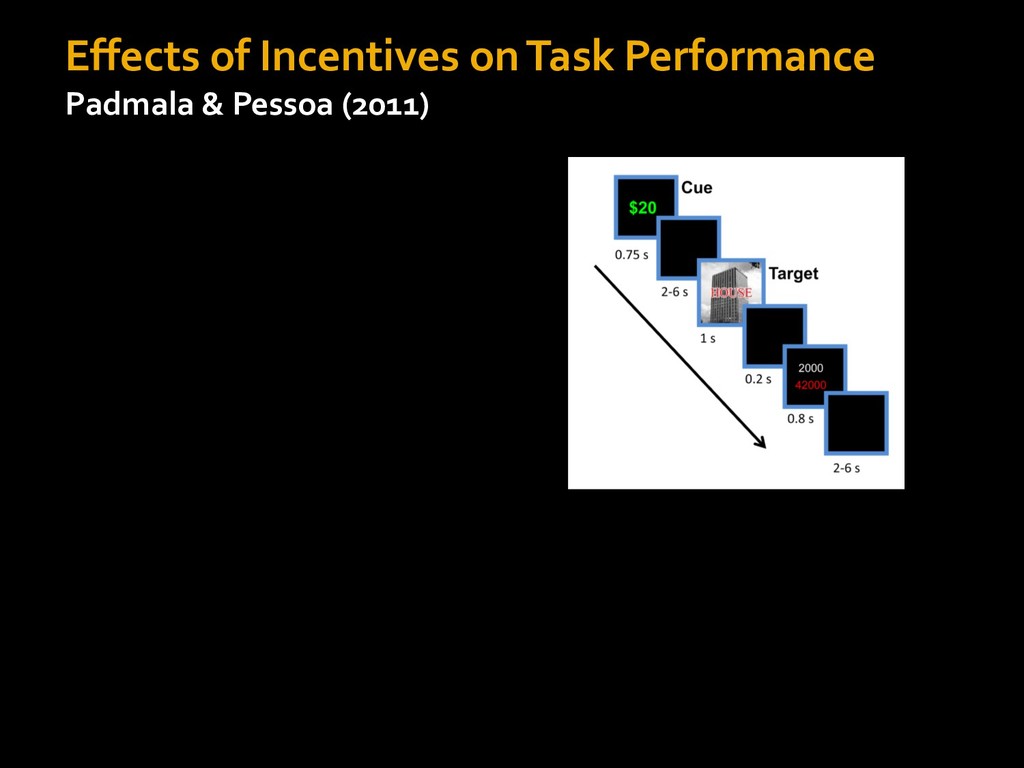
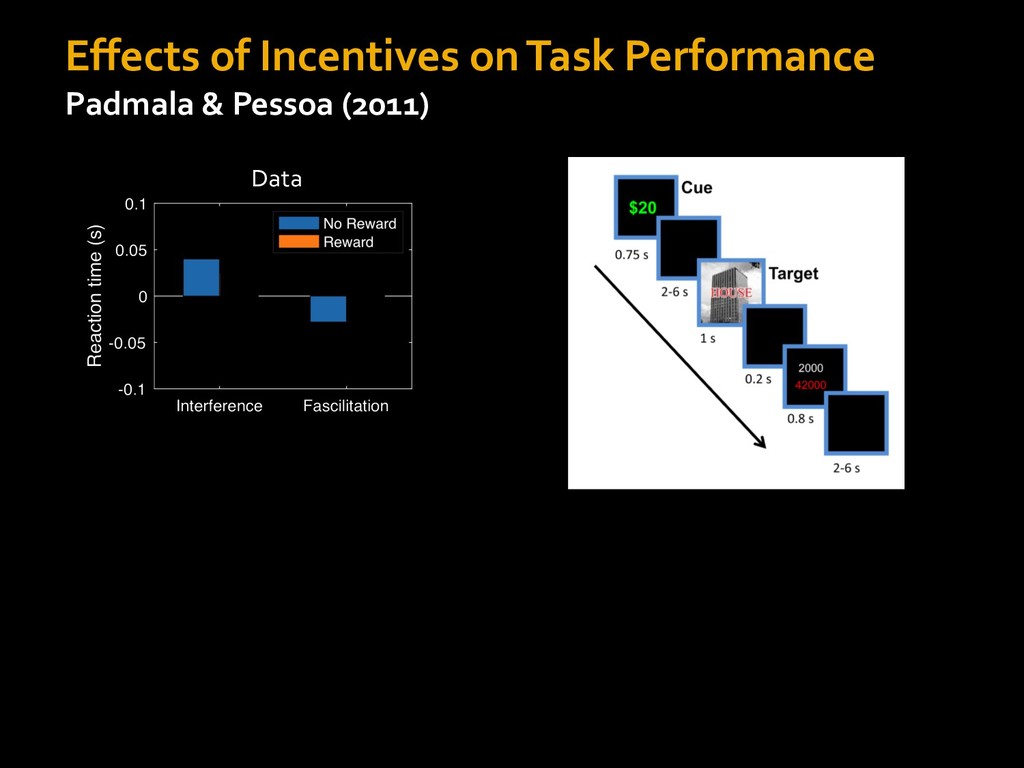
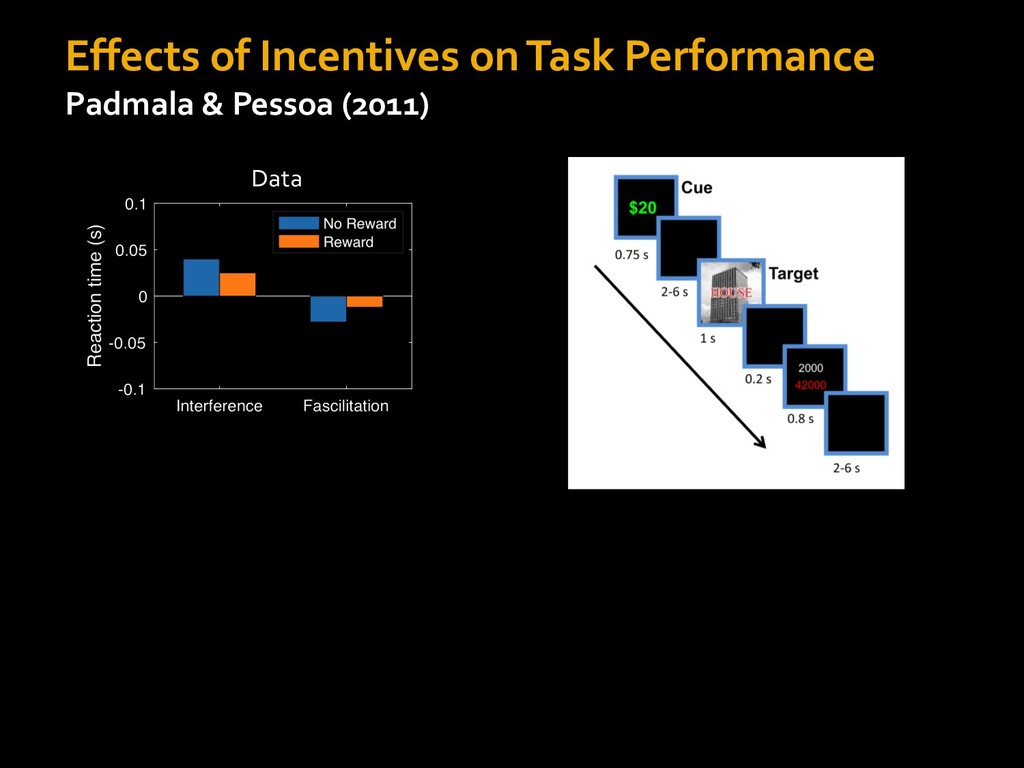
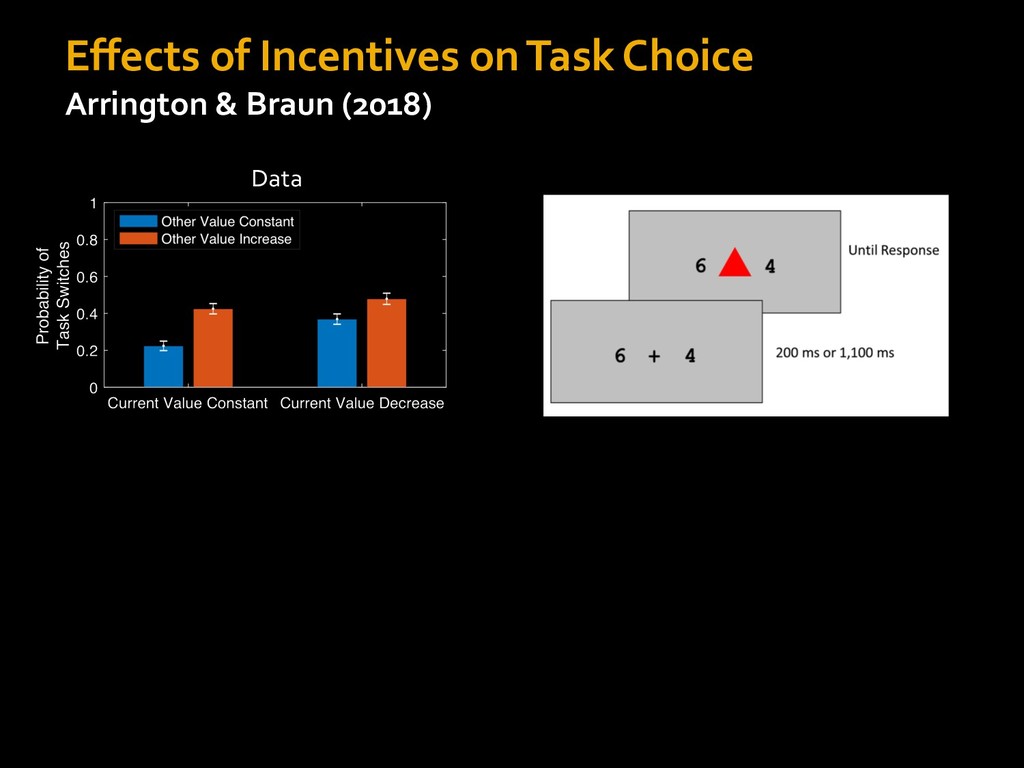
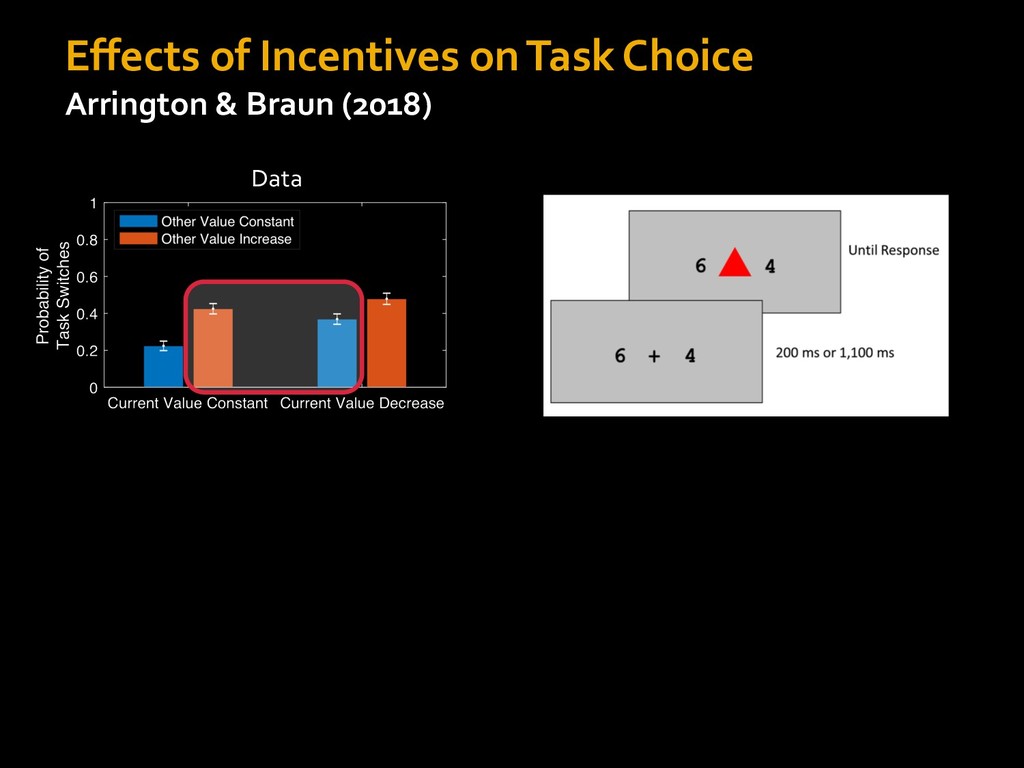
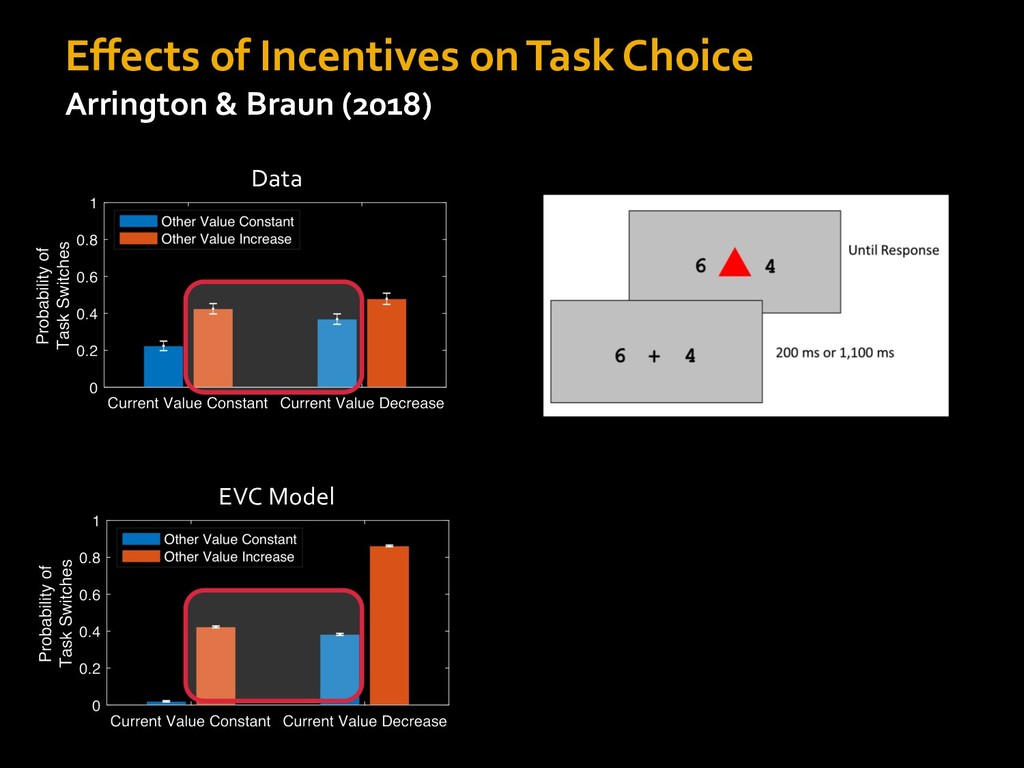
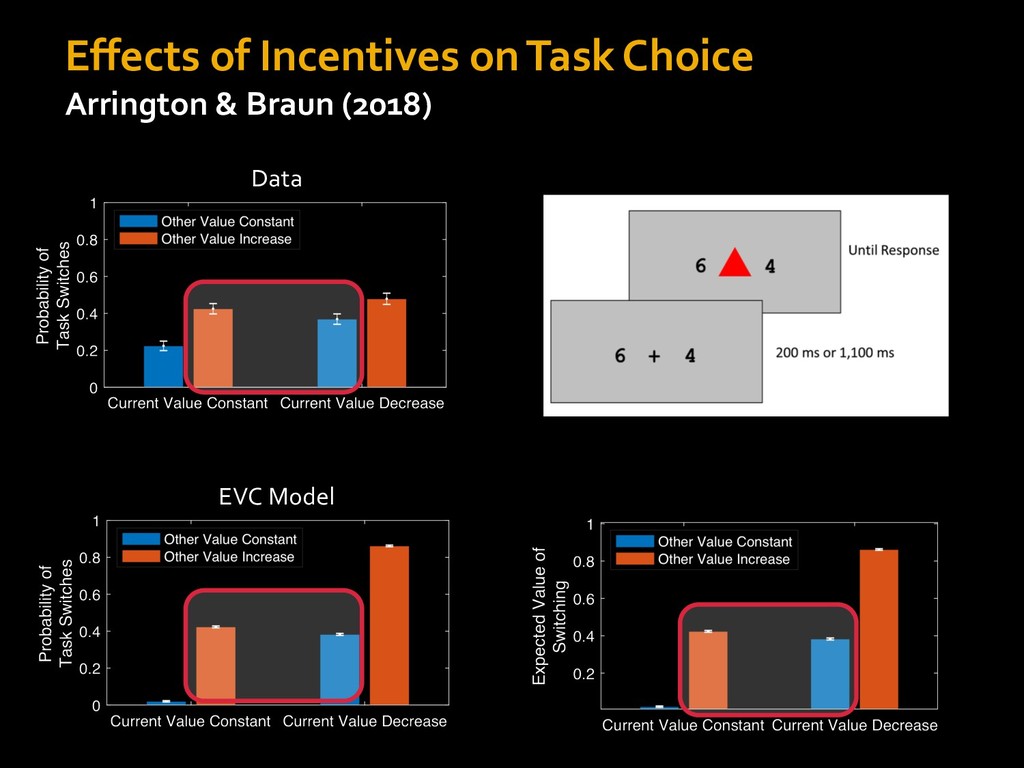
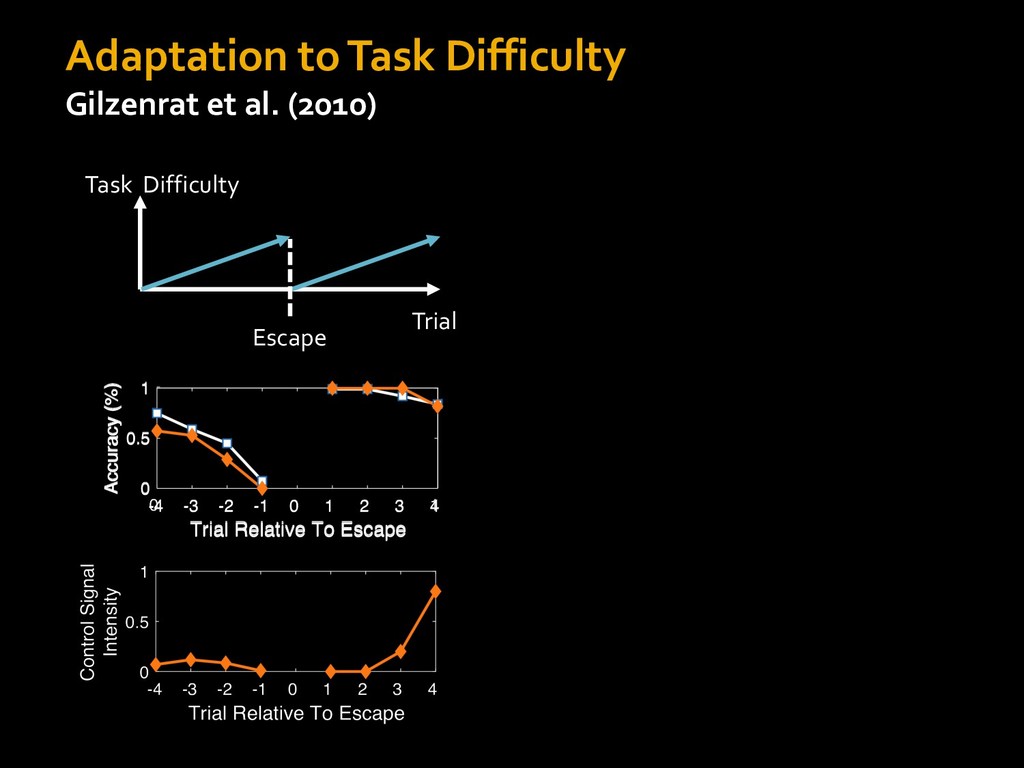
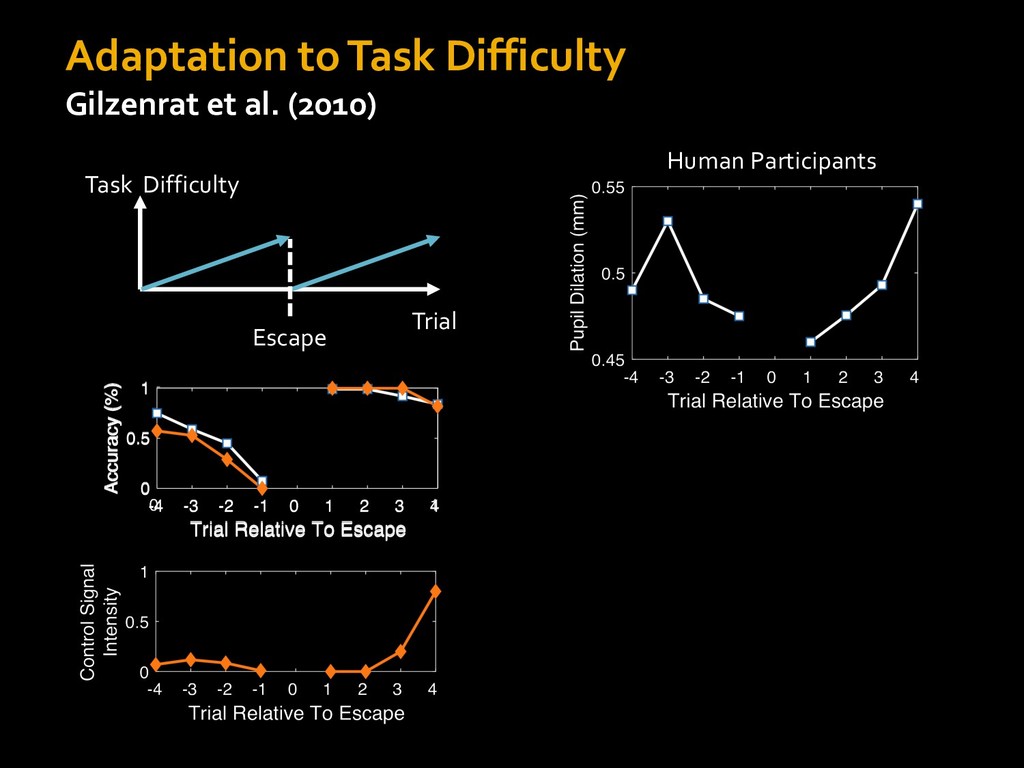
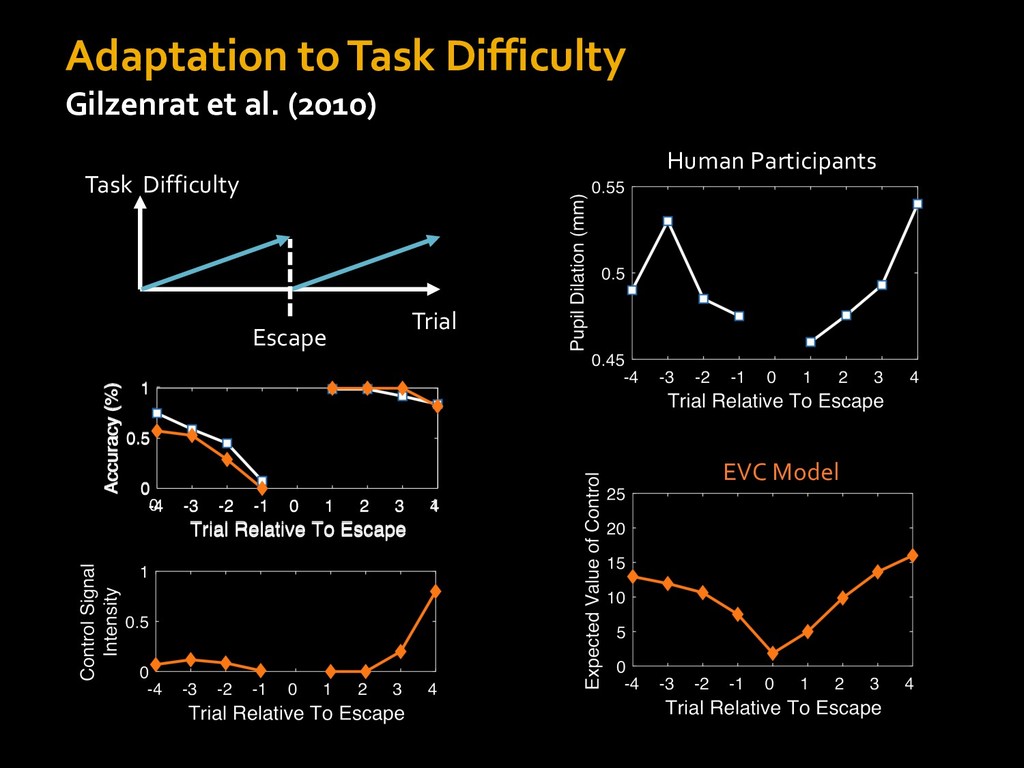
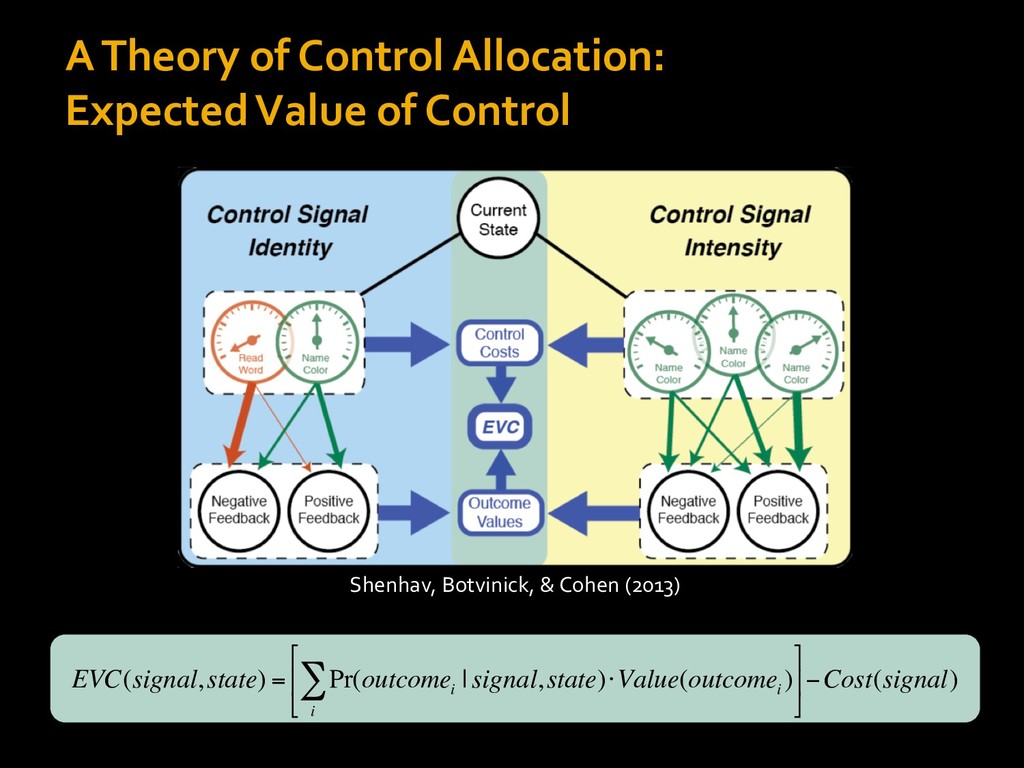
0 “red” “green” accumulated evidence Control Implementation Musslick, Shenhav, Botvinick & Cohen (2015, RLDM) !WORD = 0 !COLOR = 15 t 0 2. Compute Expected Value of Control (EVC) 1. Simulate performance Control Allocation &'()*'*+,-,./+ 0/1,(!) ! 4*5/+6.7!8-,./+ 0/1,(!) 9! + ;<= !, ? @+A = B(0/88*5,| ? @+A, D) · 4*F-8G − 0/1,(D)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}