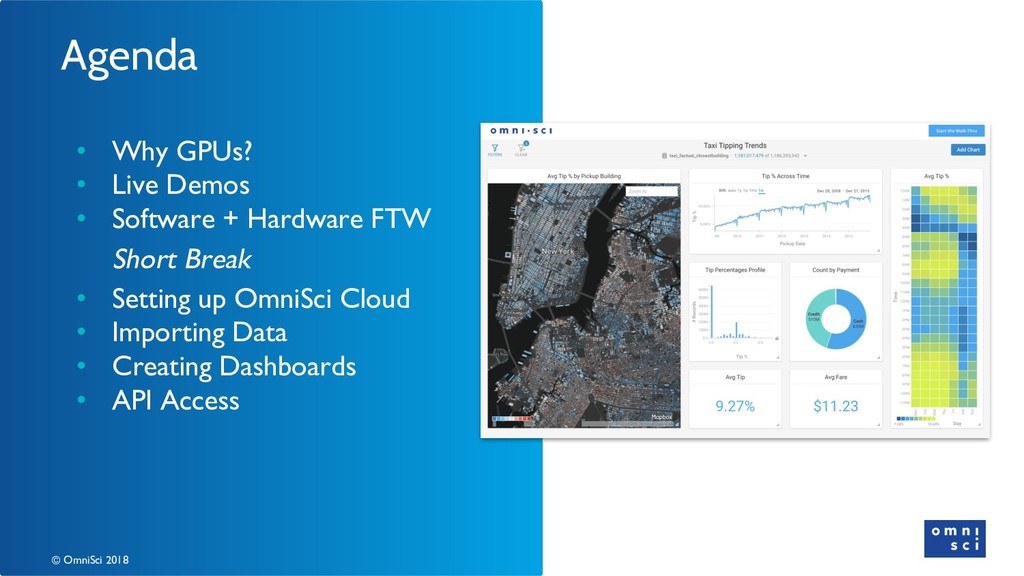
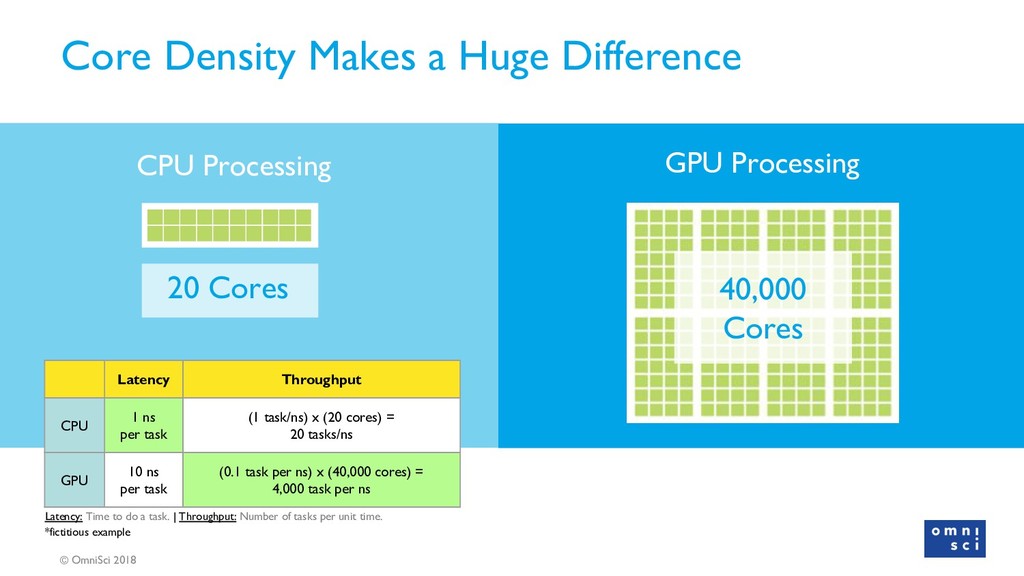
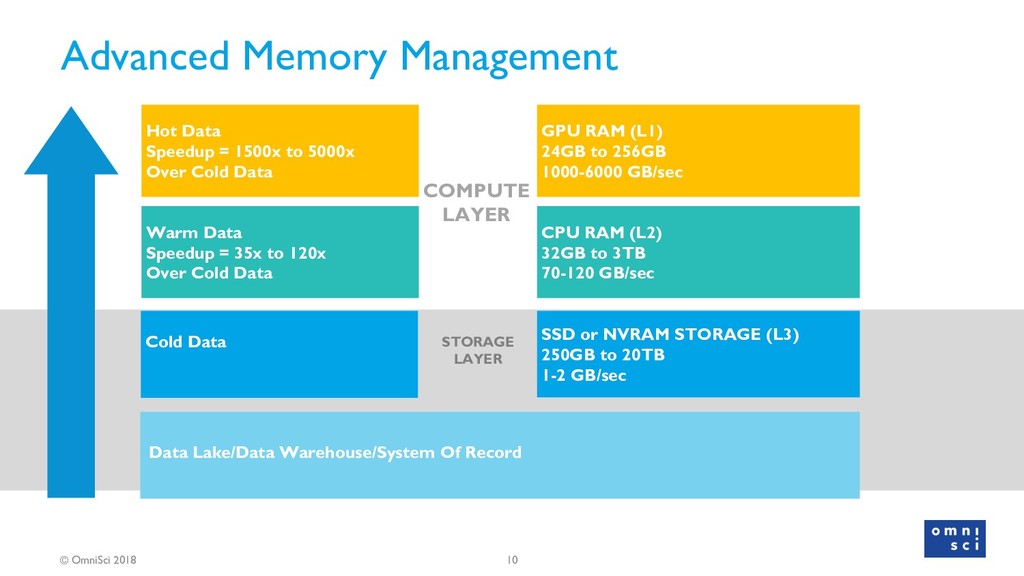
The goal of this talk is to deliver an introductory workshop to Graphical Processing Units (GPUs) and their application to general purpose analytics. The implications of GPU technology for machine and deep learning have already been enormous and there is a blossoming open source community to prove it. People are leveraging GPUs to make databases faster, complex geospatial analysis better, and to create visual analytics tools that work even with (literal) big data.
Aaron, VP of Global Community, will introduce OmniSci (Previously MapD), a startup based in San Francisco that builds open source and enterprise GPU-enabled SQL database solutions. Aaron will explain how OmniSci’s SQL engine and Immerse visualization platform were built from the ground up to harness all that GPU power. Bring your laptop if you'd like to follow along to the short workshop where we can use their web-based data visualization interface, which uses the GPU to accelerate speed and rendering capabilities.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}