What if we applied some of the most sophisticated, general-purpose data analytics tools, which are typically used by corporate, big data analysts, to our GA data? Could these tools help us unlock some insights that are hard to find using Google’s standard interface?
In this talk, Aaron, VP of Global Community at MapD, will start by talking about some of the most frustrating, hard to find, or just plain missing pieces of data in the Google Analytics web interface. Then, using MapD’s own web data, he’ll show how to import GA data into a big data analytics tool, create simple dashboards that fill in the gaps of GA’s web interface, and turn that GA data into something that is actionable and even predictive.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
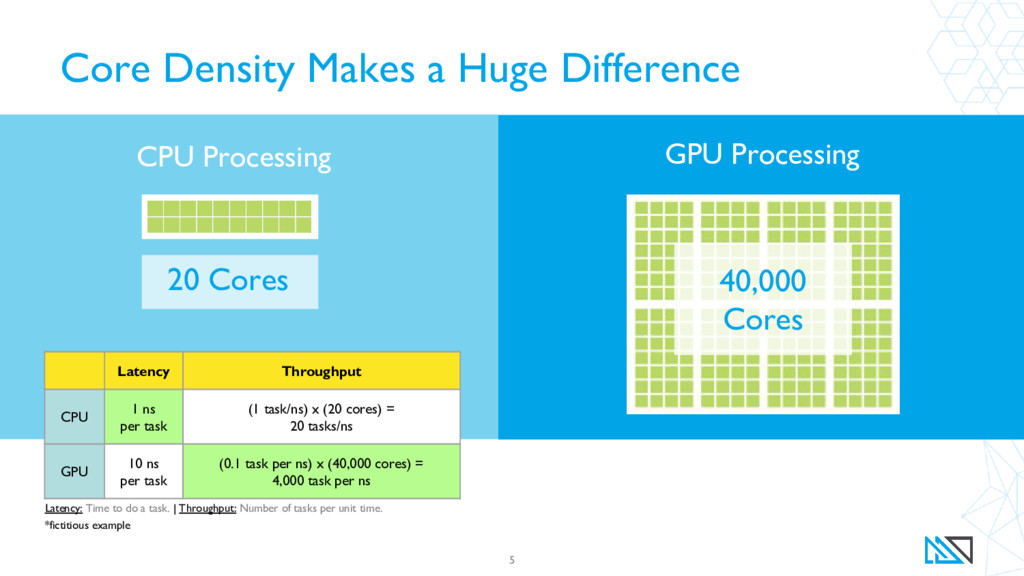{kind=link}
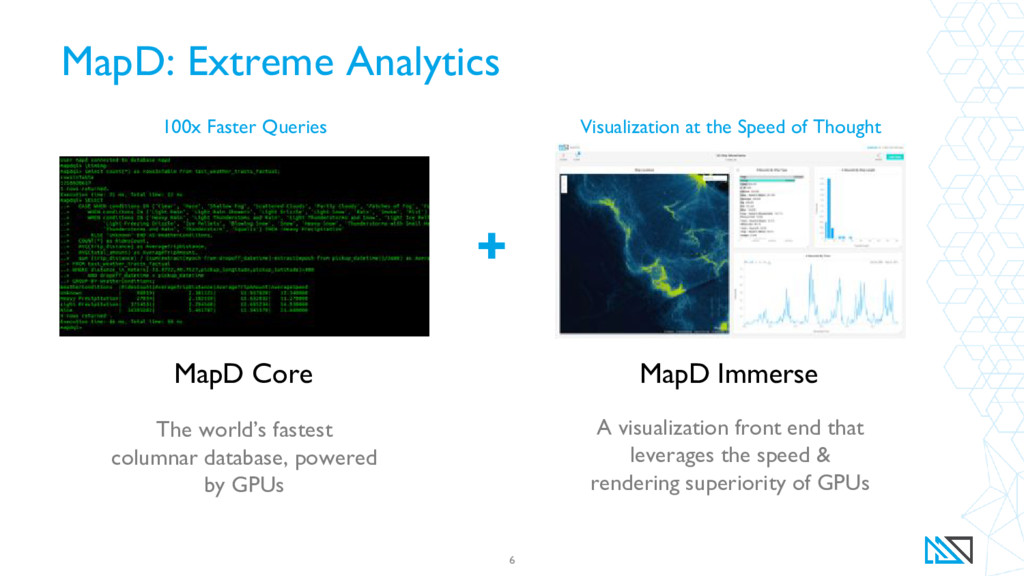{kind=link}
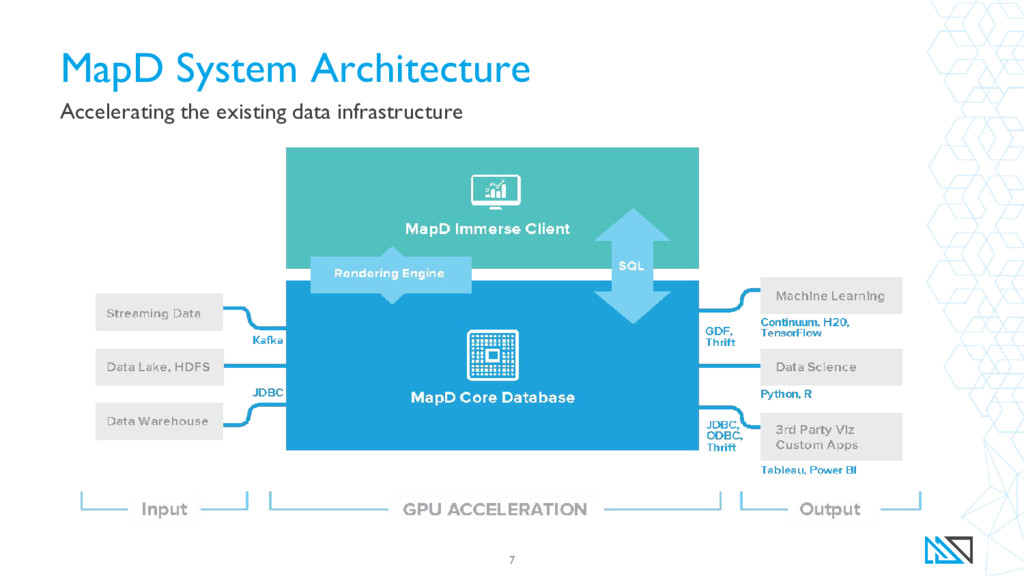{kind=link}
{kind=link}
{kind=link}
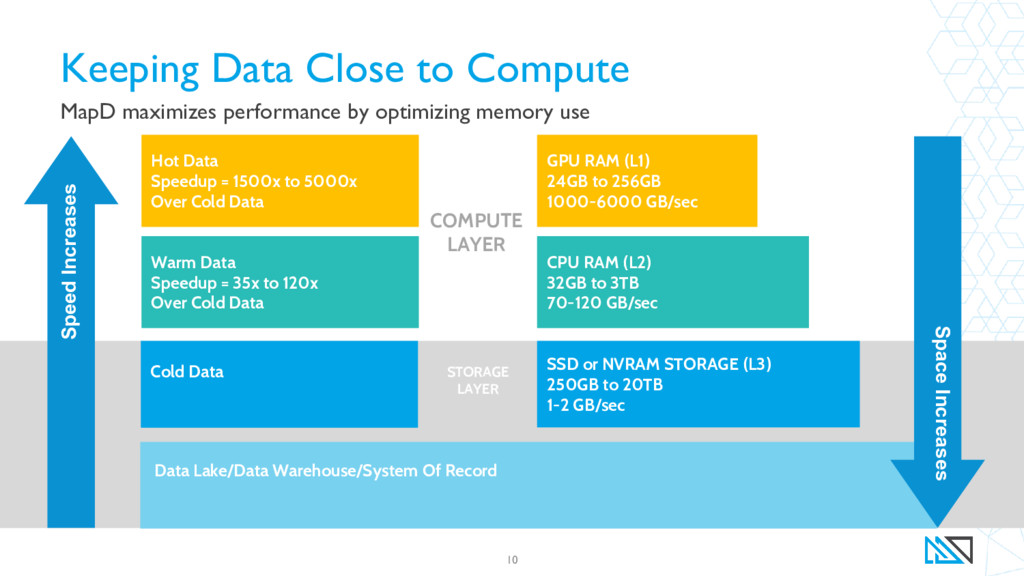{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Aaron Williams VP of Global Community @_arw_ [email protected] /in/aaronwilliams/ /williamsaaron](https://files.speakerdeck.com/presentations/f9249aeff47844328485687f35da3ed2/slide_14.jpg){kind=link}
{kind=link}