Além de mostrar a inviabilidade de resolver sistemas lineares por Crammer, apresentamos a SciPy, suas rotinas básícas (cálculo de determ., normas e inversas). Exploramos geometricamente matrizes como transformações lineares (em R2), etc.
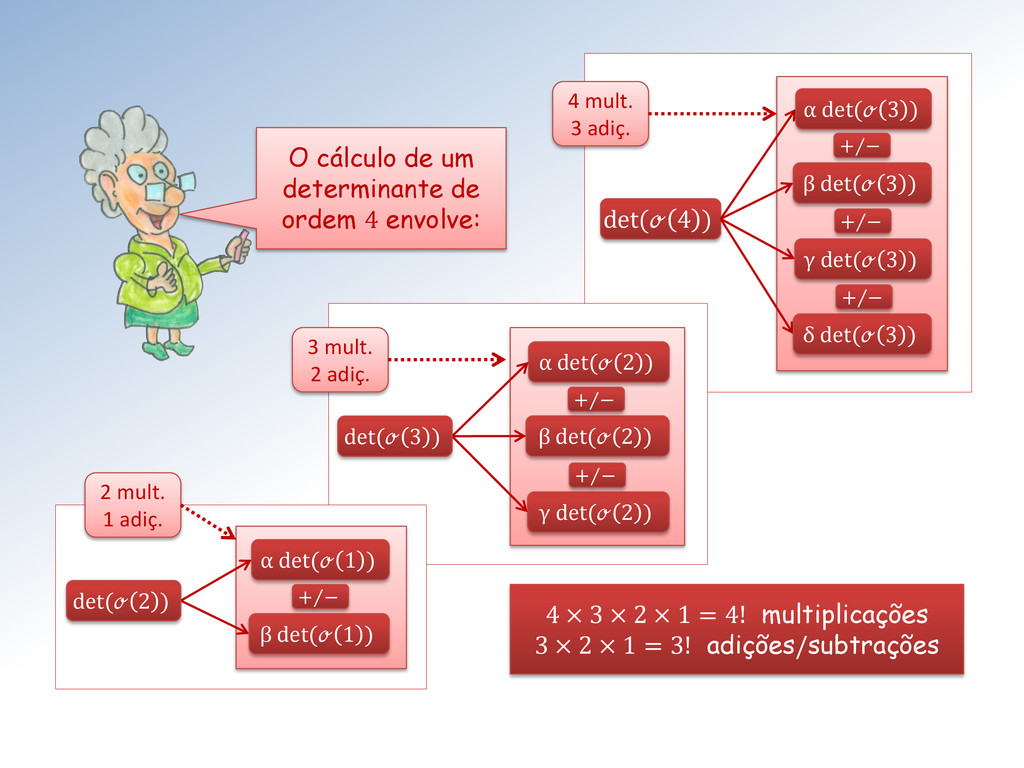
são necessárias: (3/2)4! multiplicações, 4!-4 adições e 3 divisões. Notem o fatorial no número de flops. Foram necessárias (3/2)3! multiplicações e 3!-1 adições/subtrações para cada determinante 3x3.
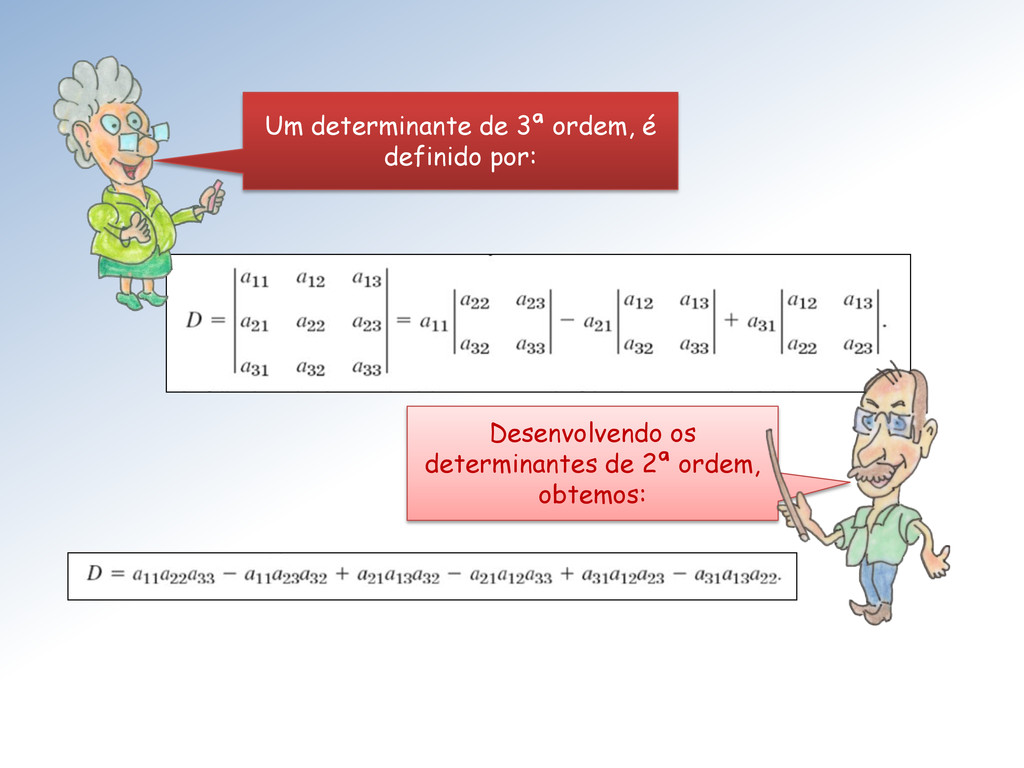
do det é dado por det = 1 1 + 2 2 + ⋯ + onde = (−1)+ e é o determinante de ordem n-1 obtido a partir da matriz A excluindo-se sua − é linha e − é coluna. Há um desenvolvimento semelhante a partir da − é coluna. Para n = 1, det A = a 11 .
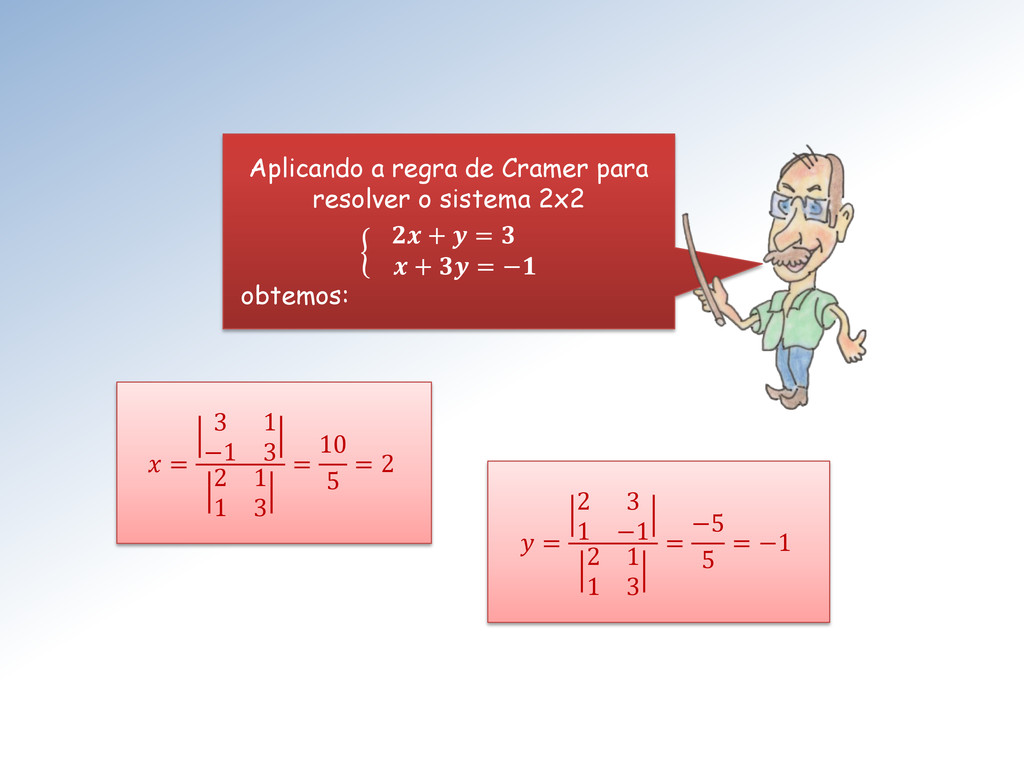
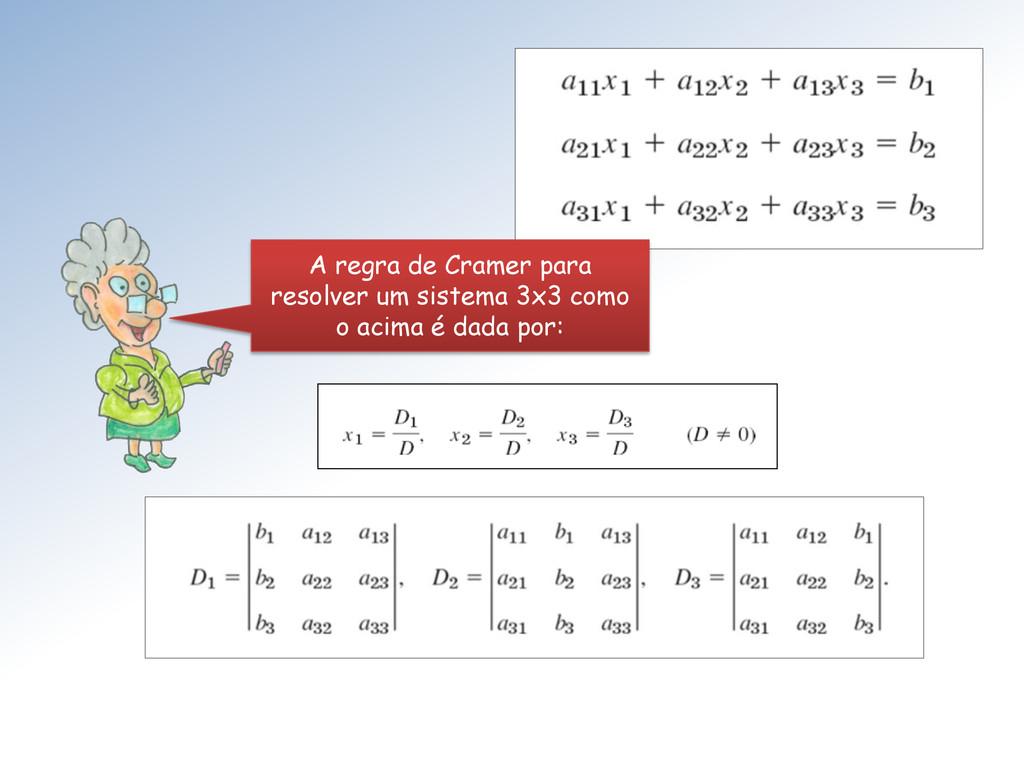
x n como este é: Se = det ≠ 0 a solução é dada por 1 = 1 , 2 = 2 , ⋯ , = onde é o determinante da matriz A com a coluna k subtituída pelo termo independente b.
efetuar o cálculo de n+1 determinantes de ordem n e n divisões. Assim, o total de operações envolvidas é: • + 1 ! multiplicações • da ordem de n! adições • n divisões
resolver um sistema n x n: n tempo 20 48.41 min. 25 7.37 séculos 30 1.076 idade univ. Surfista querido, para um sistema 30x30 ele demora um pouco mais que a idade do universo!
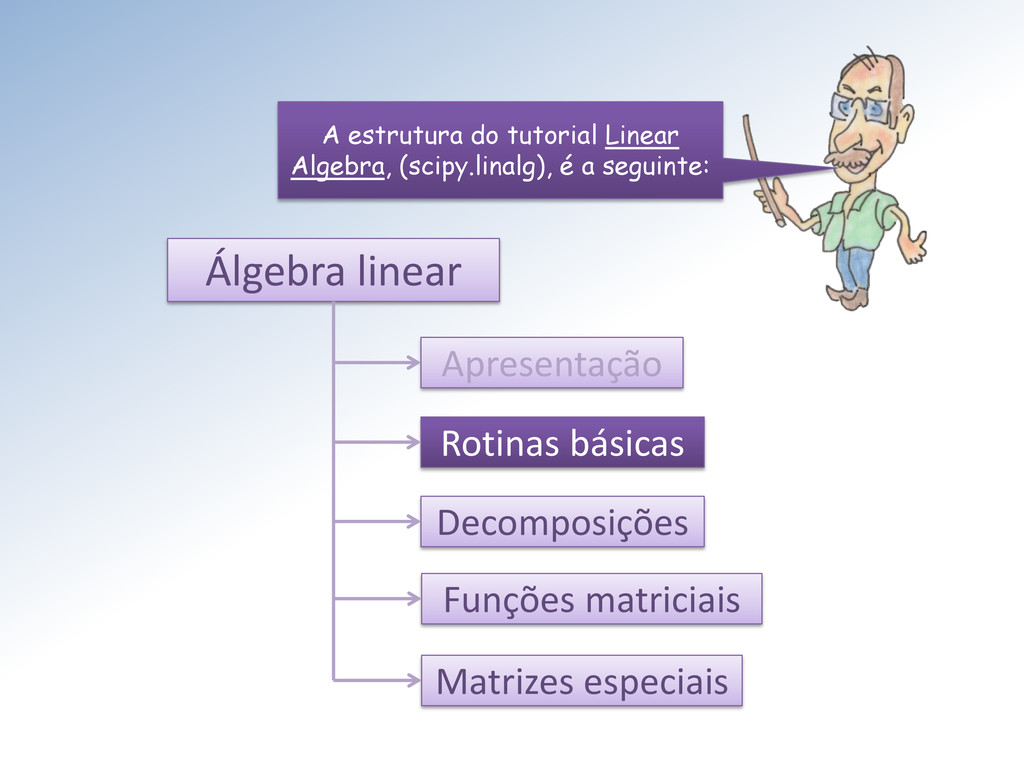
a inversa Resolvendo sistemas lineares Achando o determinante Calculando normas Resolvendo problemas lineares de mínimos quadrados e pseudo-inversas Inversa generalizada Vamos começar pelos determinantes.
normas matriciais mais adiante. Para elas precisaremos de um pouco mais de teoria. É importantíssimo observar que todas aquelas cujo parâmetro ord é negativo não são normas.
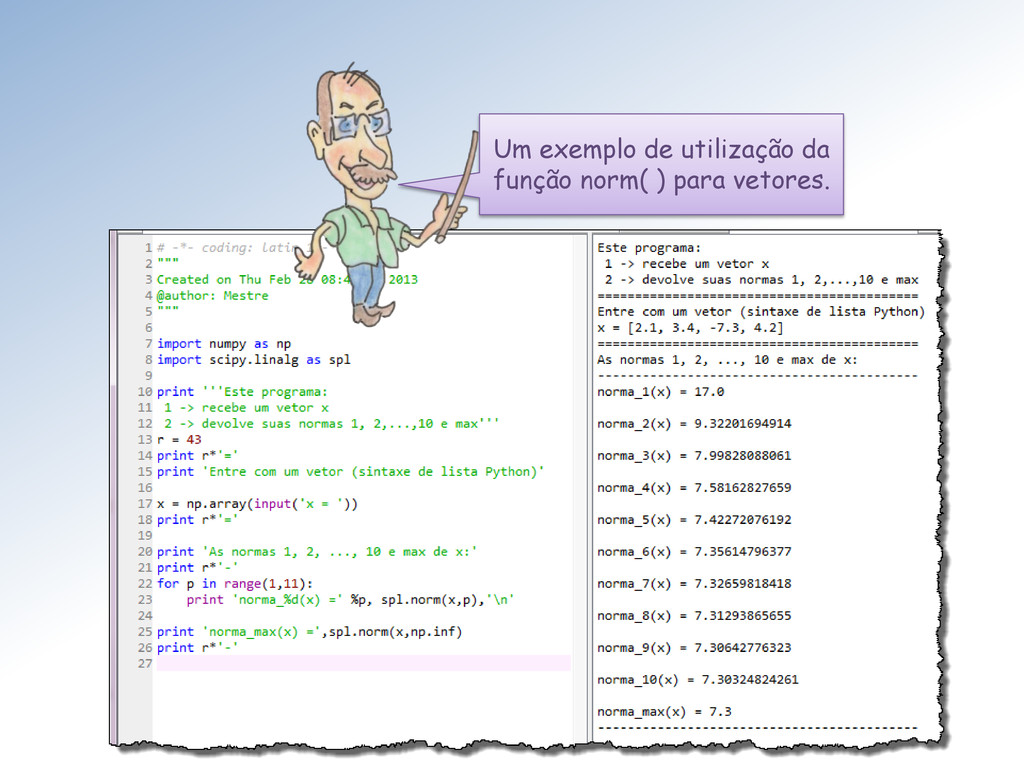
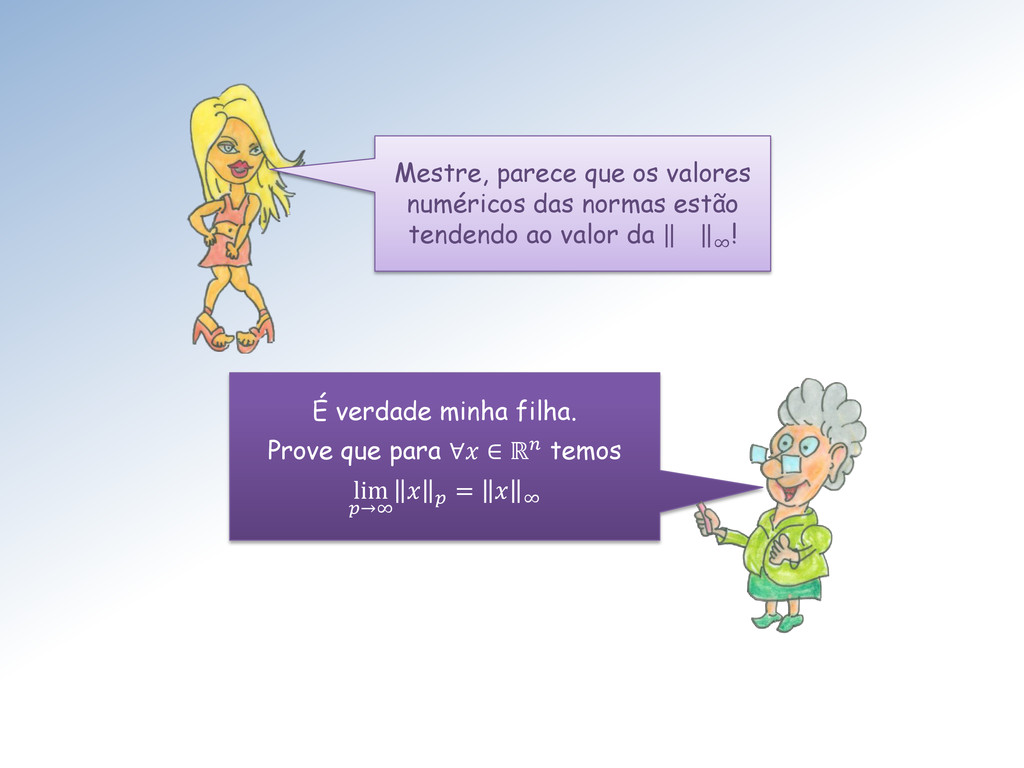
Mestre! Quando ord = inf temos a norma do máximo. Para ord = 1 temos a norma da soma e para ord = 2 temos norma euclidiana. Elas são anotadas ∞ , 1 e 2 respectivamente. As outras são anotadas , ( = ).
+ ⋯ + 2 define uma norma. A verificação que 1 = 1 + 2 + ⋯ + é uma norma é óbvia. Da mesma forma, a comprovar que ∞ = max { 1 , 2 , ⋯ , } define uma norma também é fácil.
com ′ = −1 . A dificuldade para provar que = |1 | + |2 | + ⋯ + | | é uma norma está na desigualdade triangular: + ≤ + . Ela é conhecida na literatura como desigualdade de Minkowski.
ao da desigualdade de Cauchy-Schwarz. Não vamos provar nenhuma das duas. Porém, se você estiver interessado, Surfista, já sabe as palavras-chave para buscar as demonstrações.
é o conjunto 2 = ∈ ℝ | 2 ≤ 1 . Ela descreve o conjunto 2 + 2 + 2 ≤ 1, que nossa intuição entende por uma bola (de futebol) no espaço euclidiano ℝ3. No plano seria como um CD (dos Beatles).
espaço ℝ com a norma do máximo é o conjunto ∞ = ∈ ℝ | ∞ ≤ 1 . No ℝ2 ela corresponde ao conjunto definido pela desigualdade max { , } ≤ 1, mostrado na figura.
da matemática. Elas são o objeto do Cálculo diferencial e integral. Em particular, vamos considerar funções de um espaço vetorial U em um outro espaço vetorial V : : → , ∈ ⟼ = () ∈ .
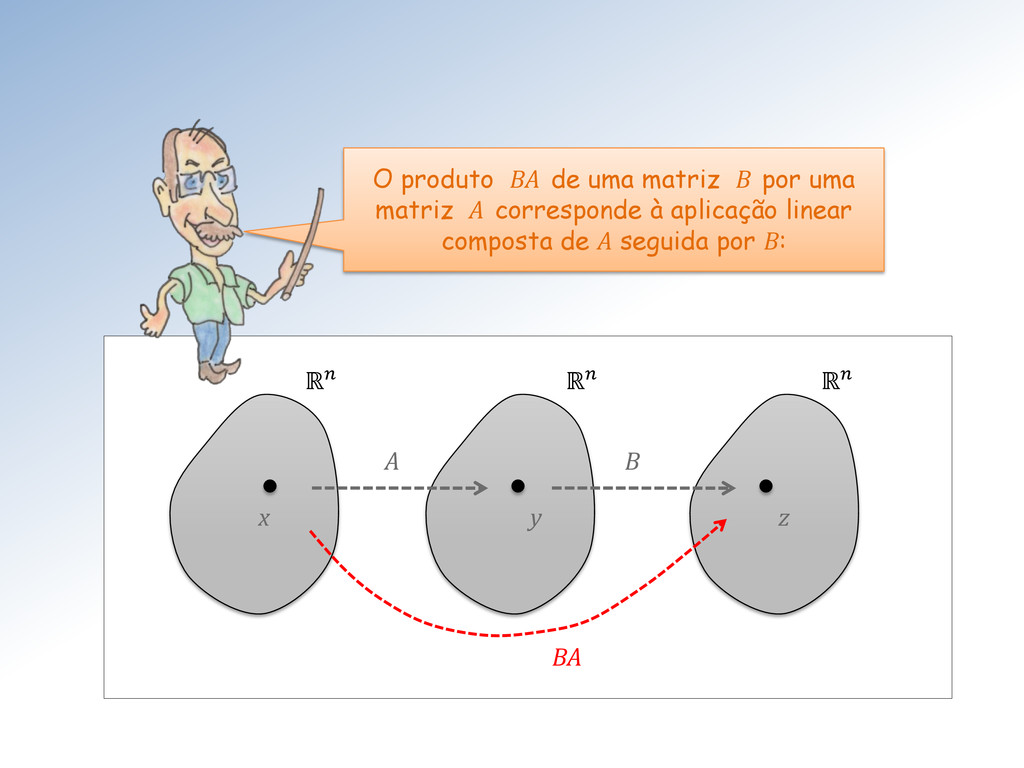
⟼ ( + ) = + , • ⟼ = (). Tais funções recebem o nome especial de transformações lineares. Particularizando ainda mais: funções : → de um espaço vetorial U para outro V que preservam as operações nativas de U e V.
ℝ em ℝ através da multiplicação matriz x vetor. Uma matriz 3 x 4 define uma transformação linear ∶ ℝ4 → ℝ3, através da multiplicação: 1 2 3 = 11 12 13 14 21 22 23 24 31 32 33 34 1 2 3 4
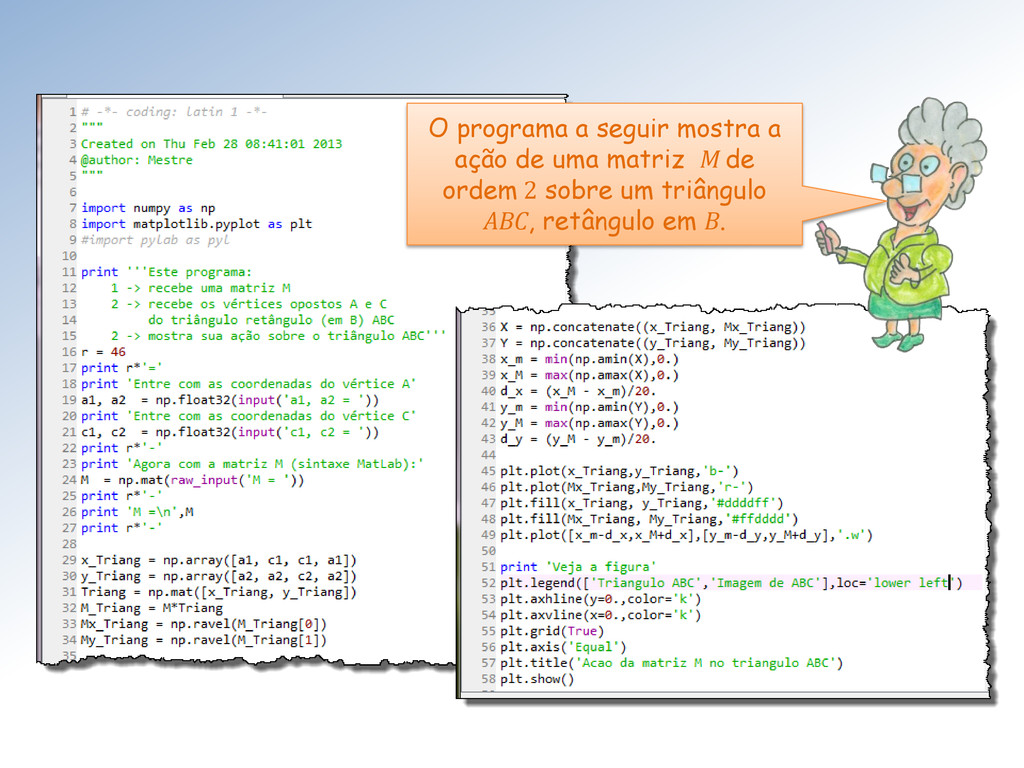
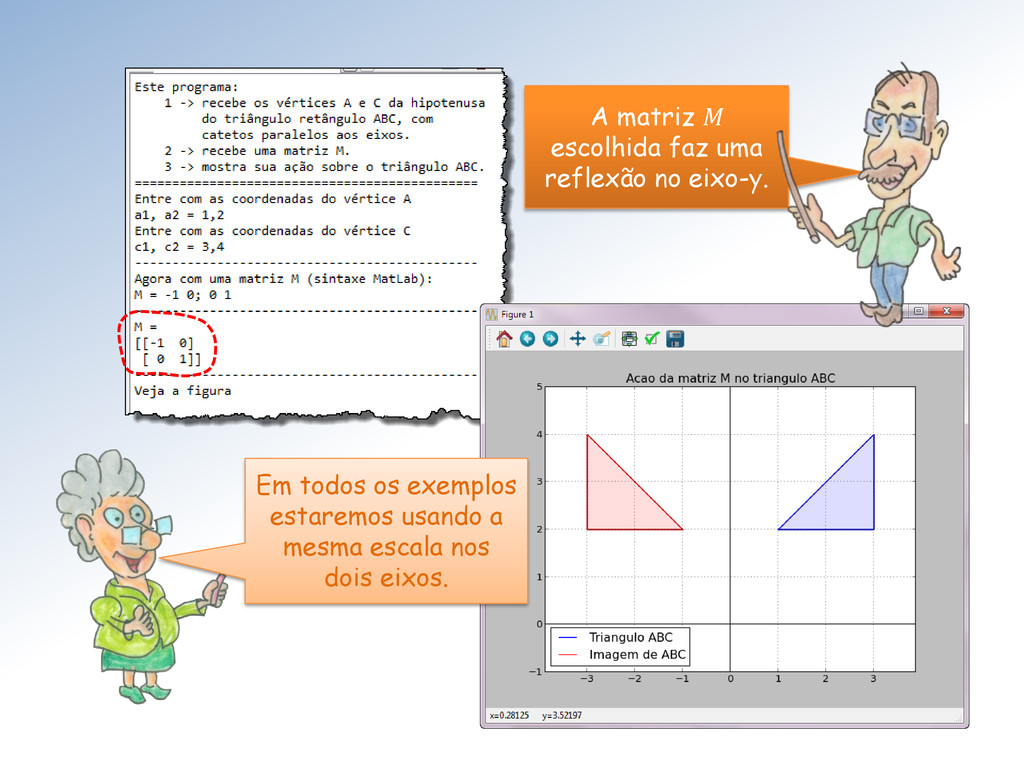
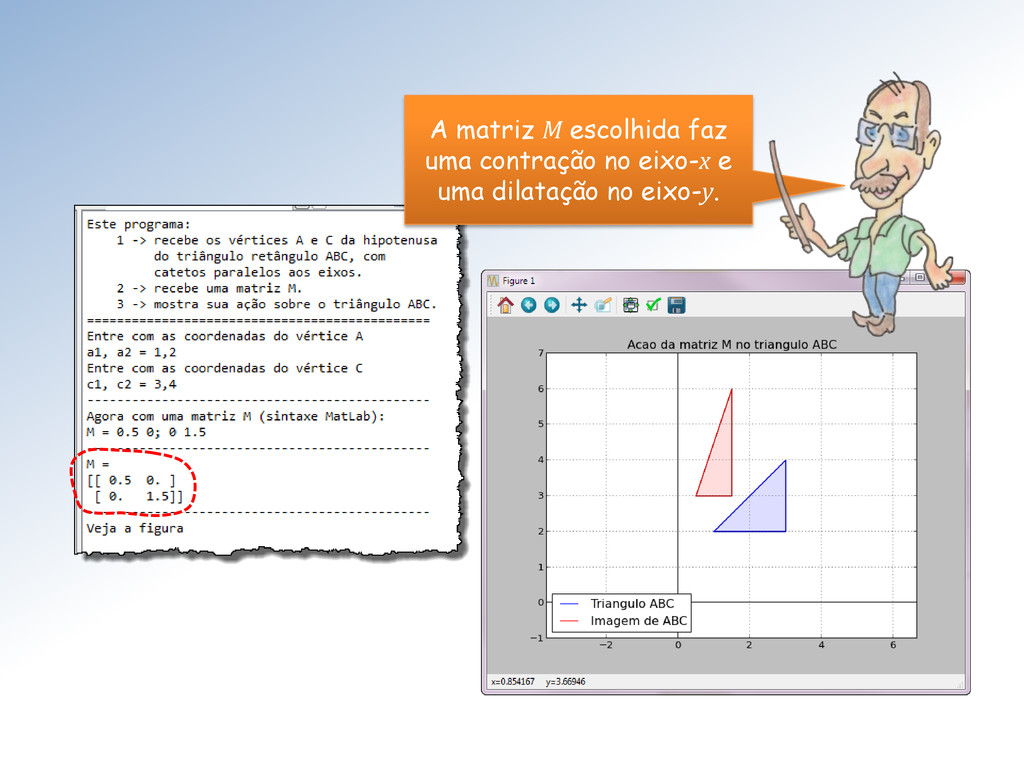
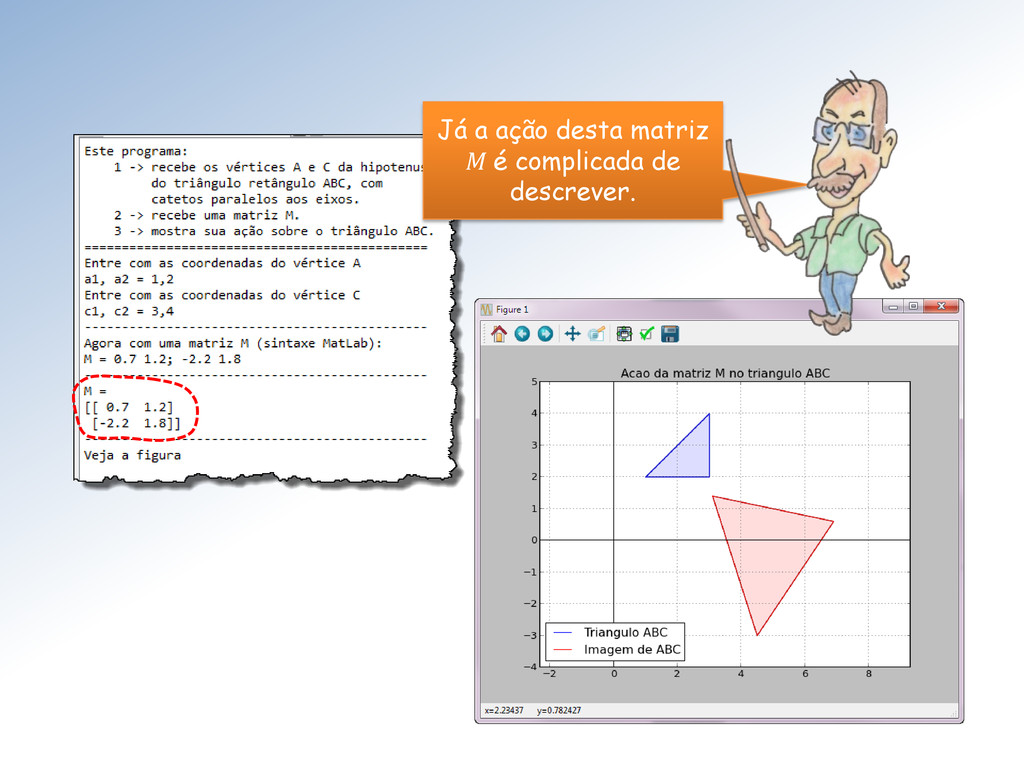
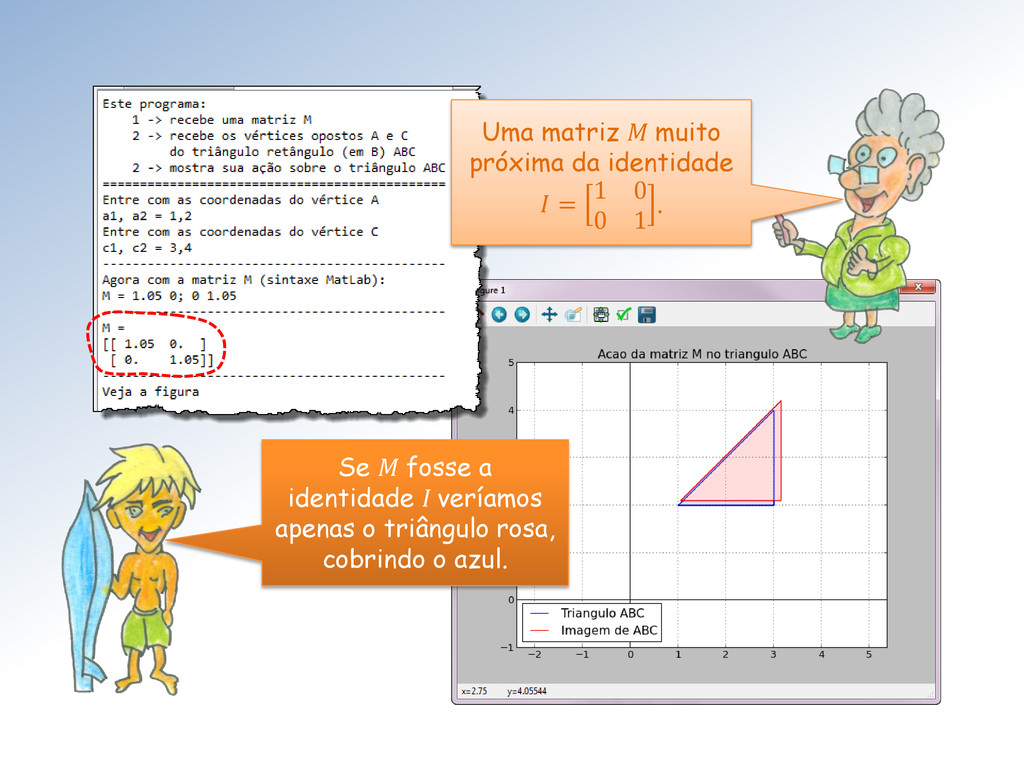
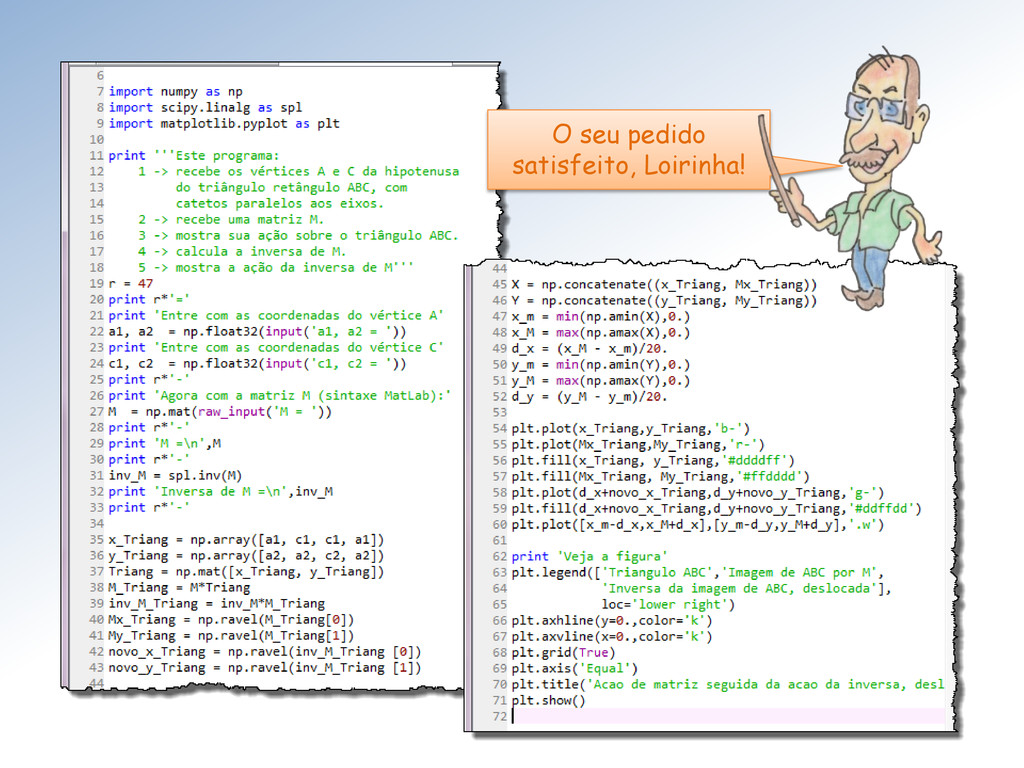
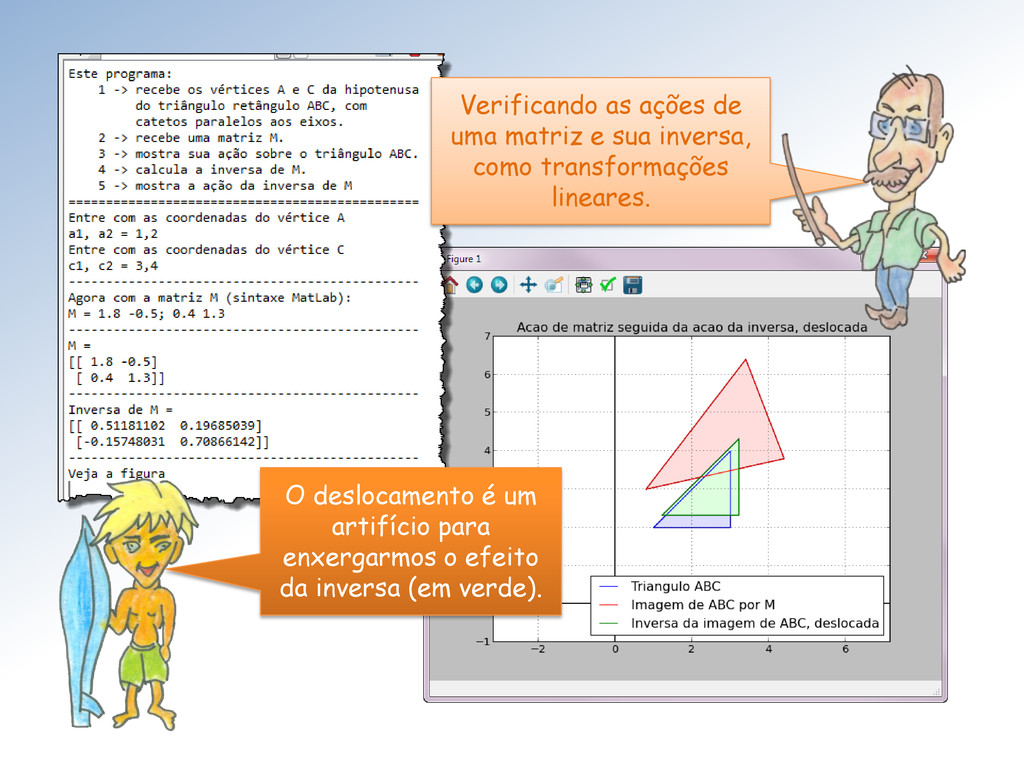
ação da matriz M sobre o triângulo ABC e marque os vértices correspondentes com o mesmo símbolo. Mestre, seu programa não mostra a correspondência entre os vértices originais e suas imagens!
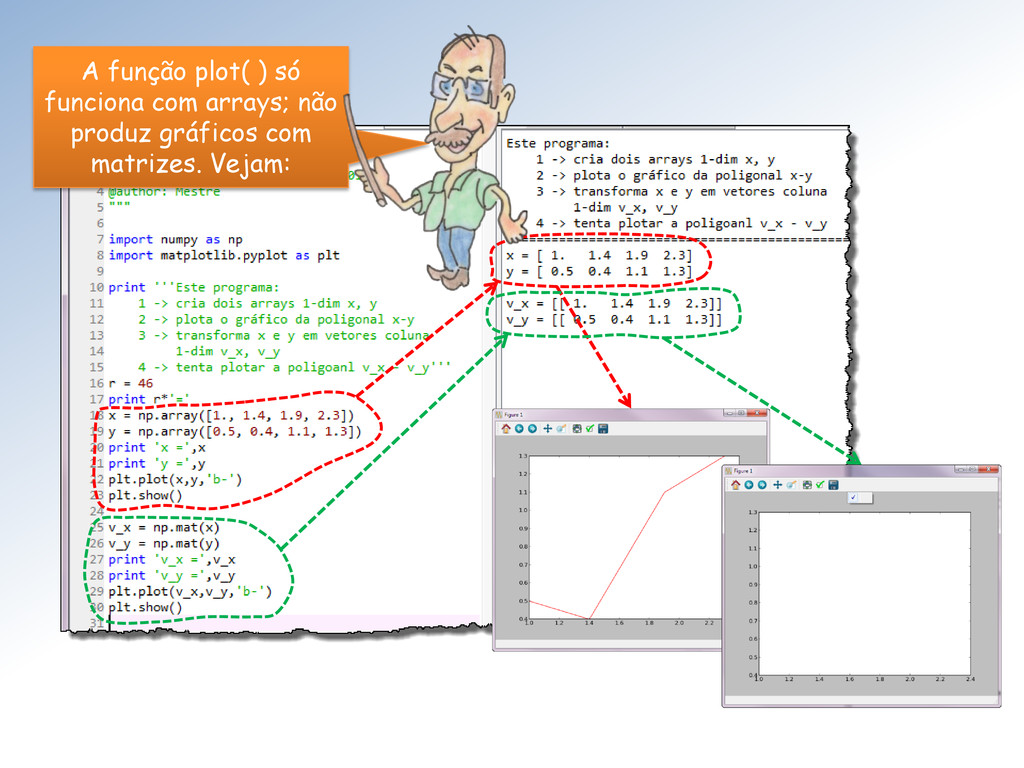
com a cor definida em rgb pela “string” hexadecimal ‘#rrggbb’. Assinalei um truque “sujo” do Mestre para centralizar o gráfico. Troque ‘.w’ por ‘+r’ e execute novamente para entender!
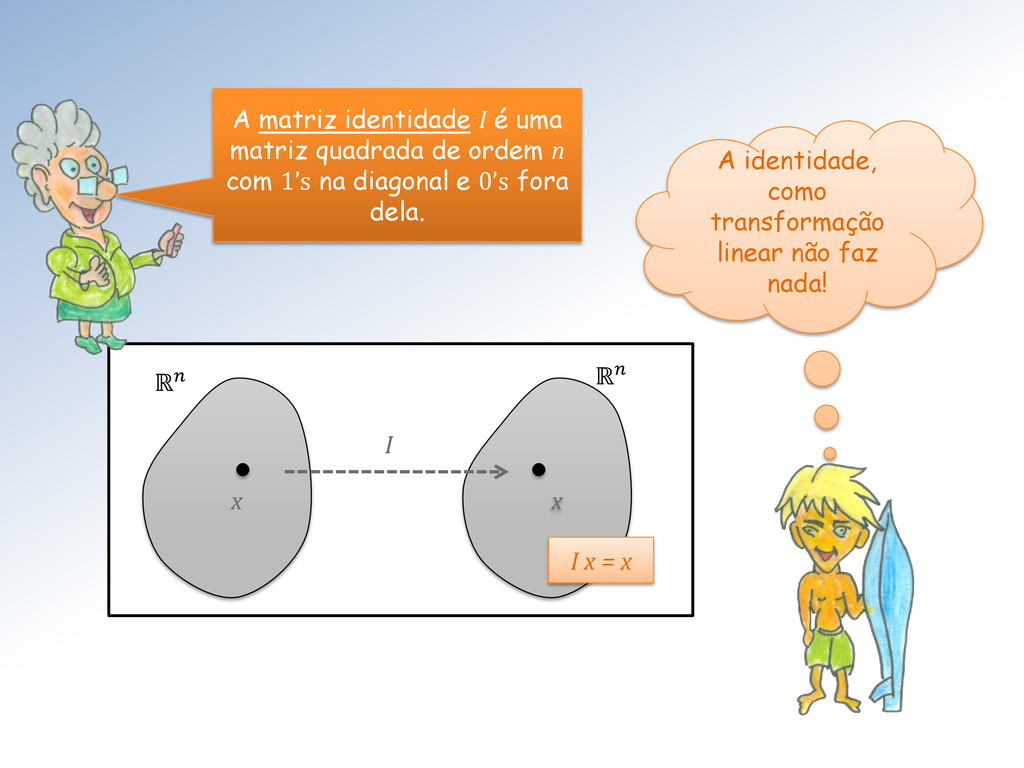
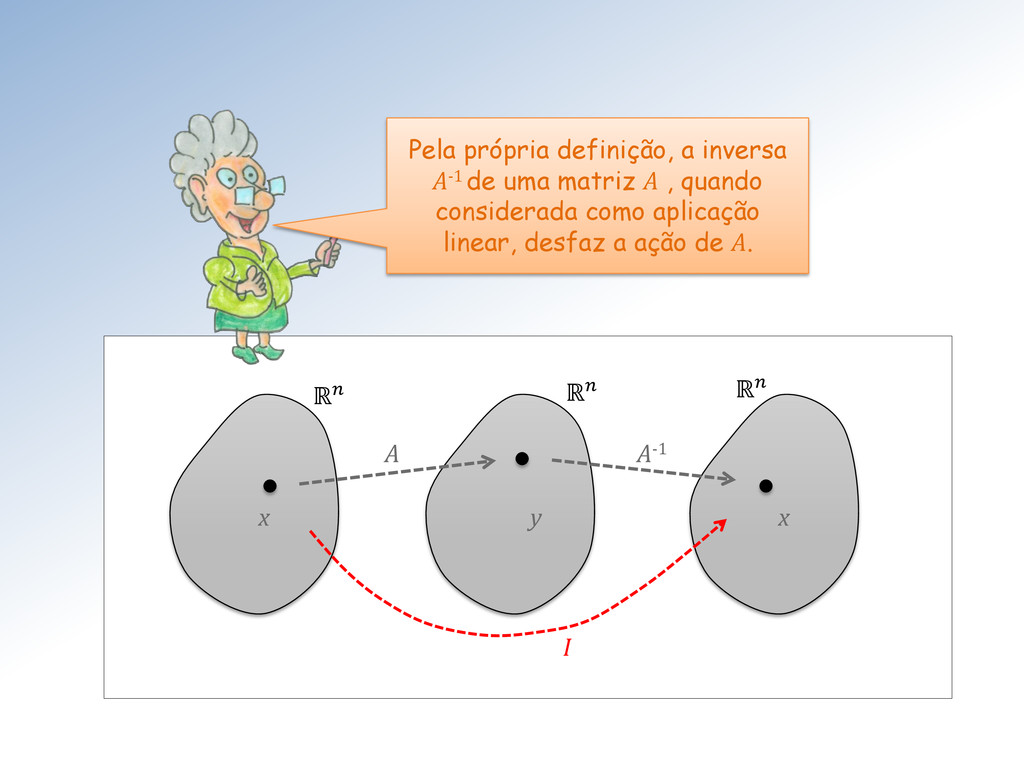
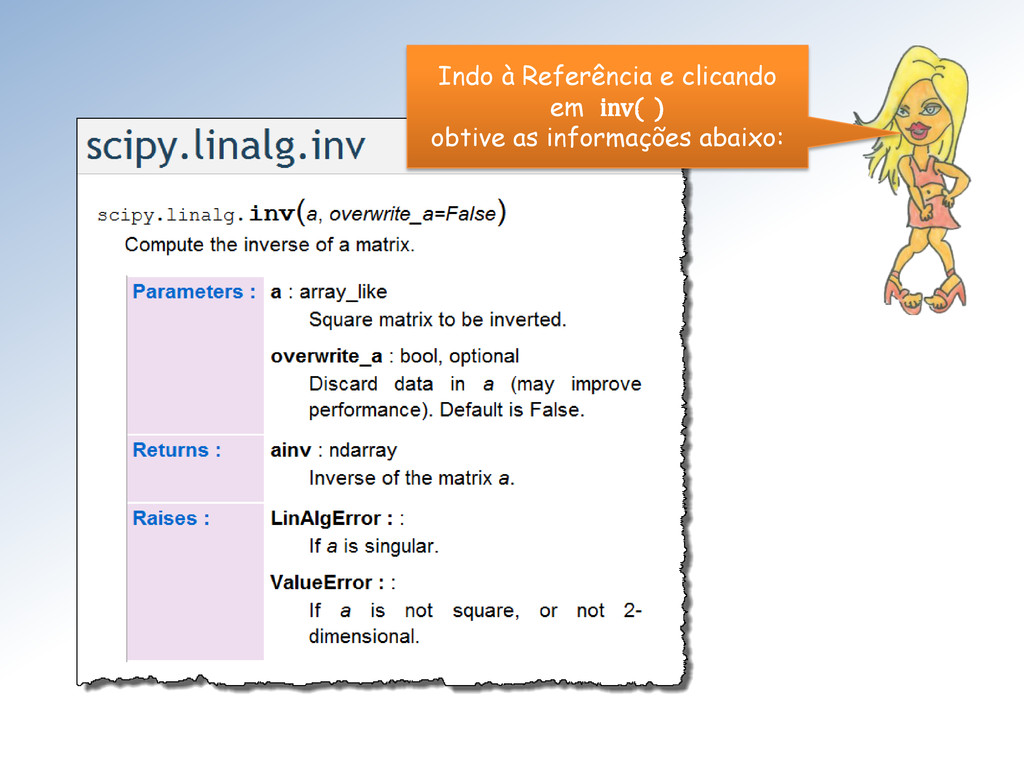
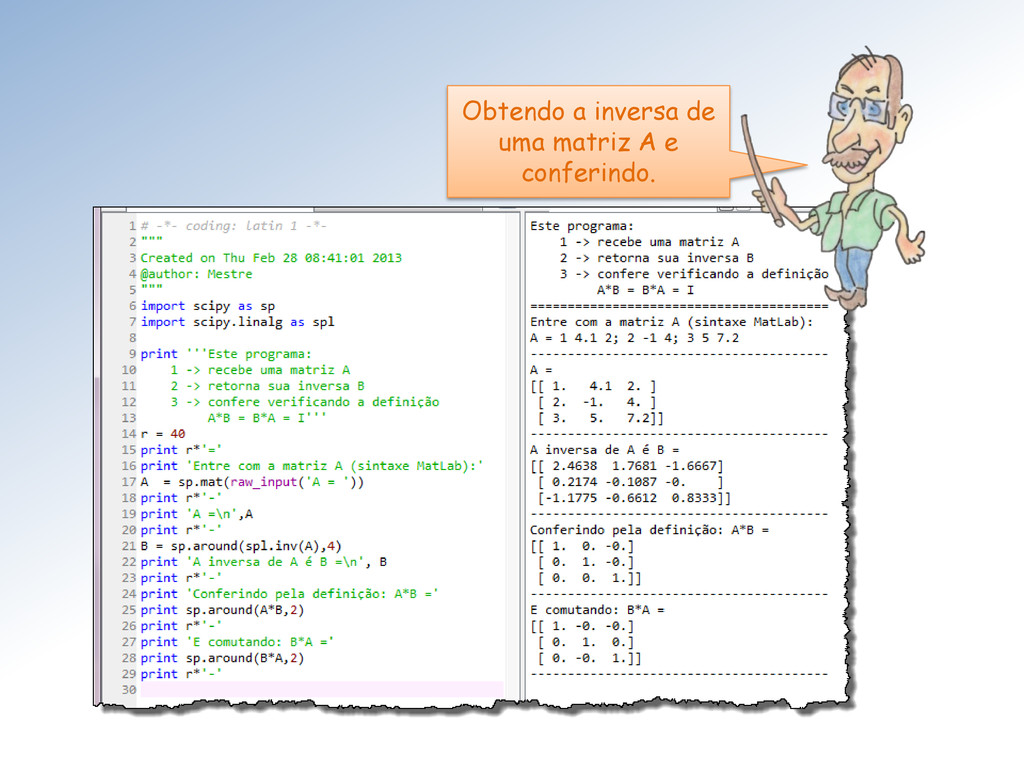
é uma matriz quadrada B de ordem n tal que ∙ = ∙ = Existem matrizes que não possuem inversa – são não-inversíveis. Uma matriz não possui mais que uma inversa. Além disso, a inversa da inversa é a própria!
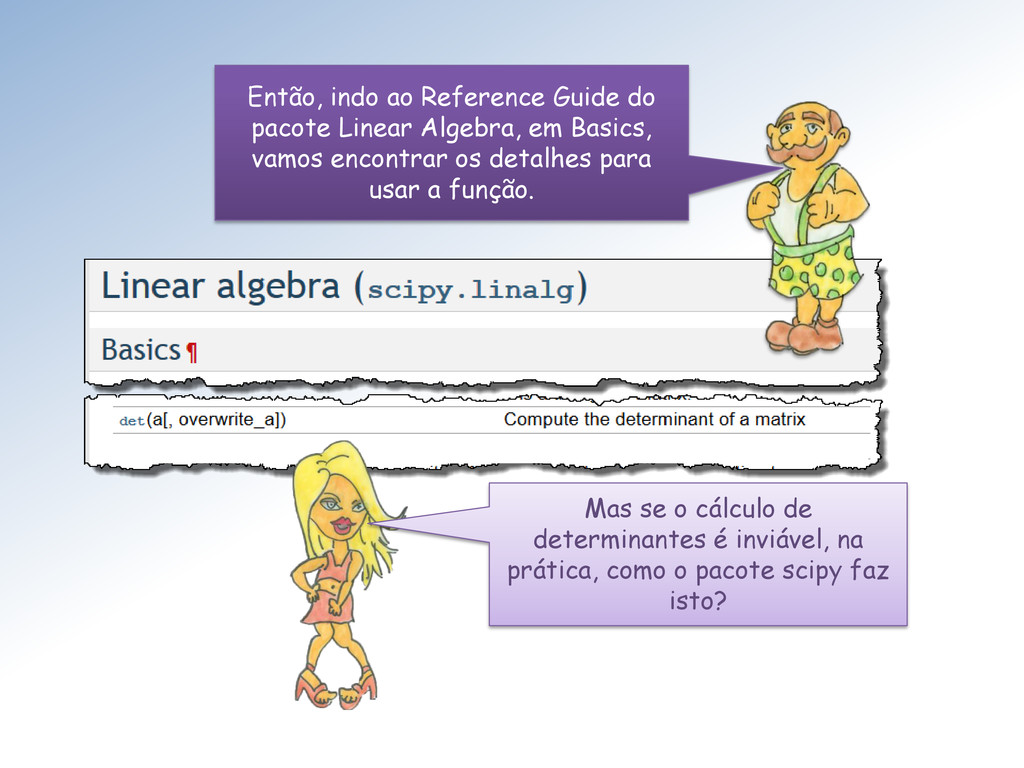
não-singular, i.é, det () ≠ 0 Entretanto, verificar se det () ≠ 0 para saber se A é inversível é uma técnica nunca utilizada em Álgebra linear computacional.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Face ao exposto na transparência anterior, precisamos transformar M_Triang[0] e](https://files.speakerdeck.com/presentations/cc1526e01376013167313a411ef422ce/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}