This presentation distills critical insights and lessons from using Kafka in a large-scale project involving 100 developers. We will delve into common misunderstandings and pitfalls that teams encounter when integrating Kafka into their workflows, highlighting practical examples and solutions. The focus will be on the most important learnings garnered from our experiences, offering attendees a roadmap to navigate the complexities of using Kafka effectively in big projects
{kind=link}
{kind=link}
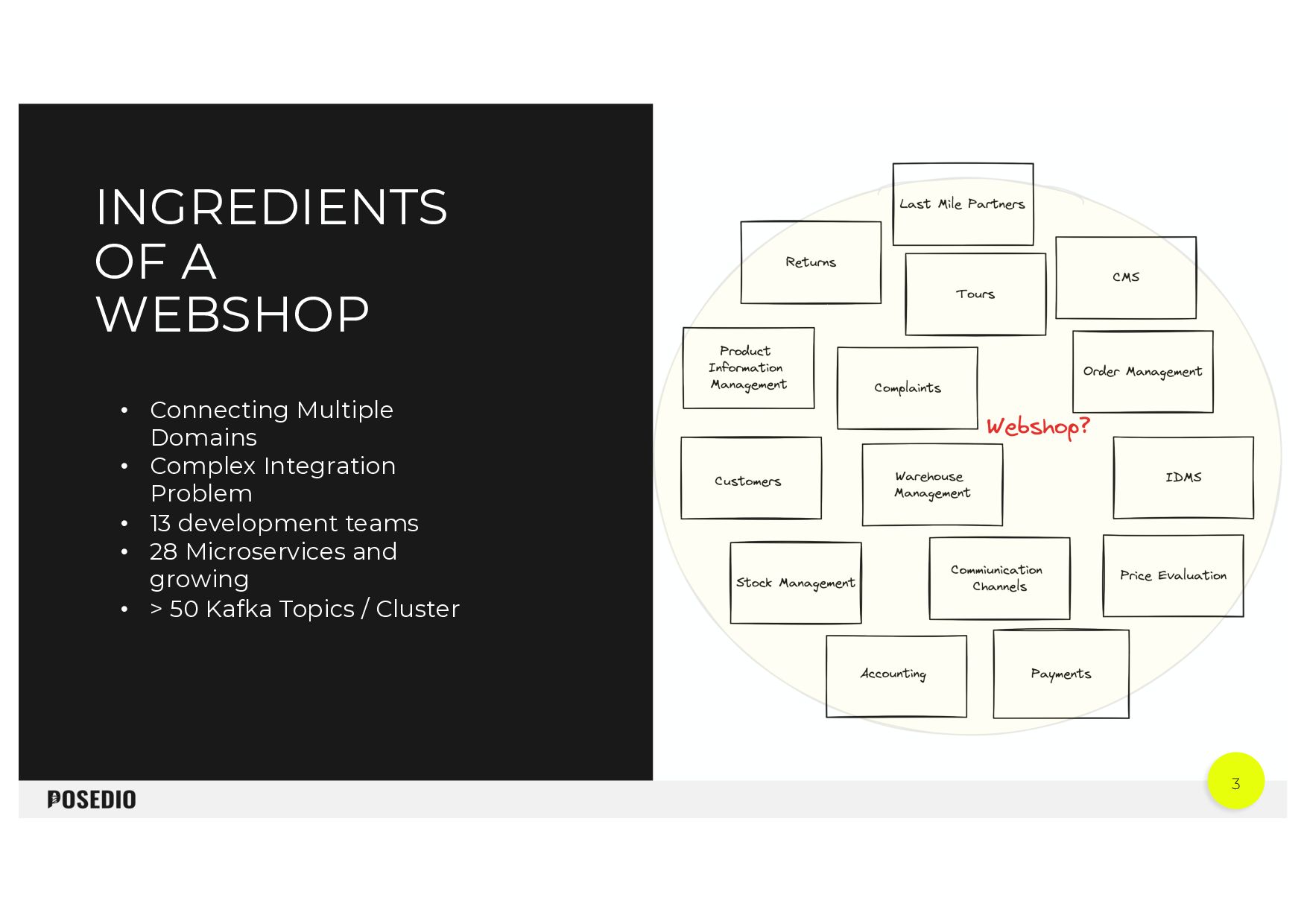{kind=link}
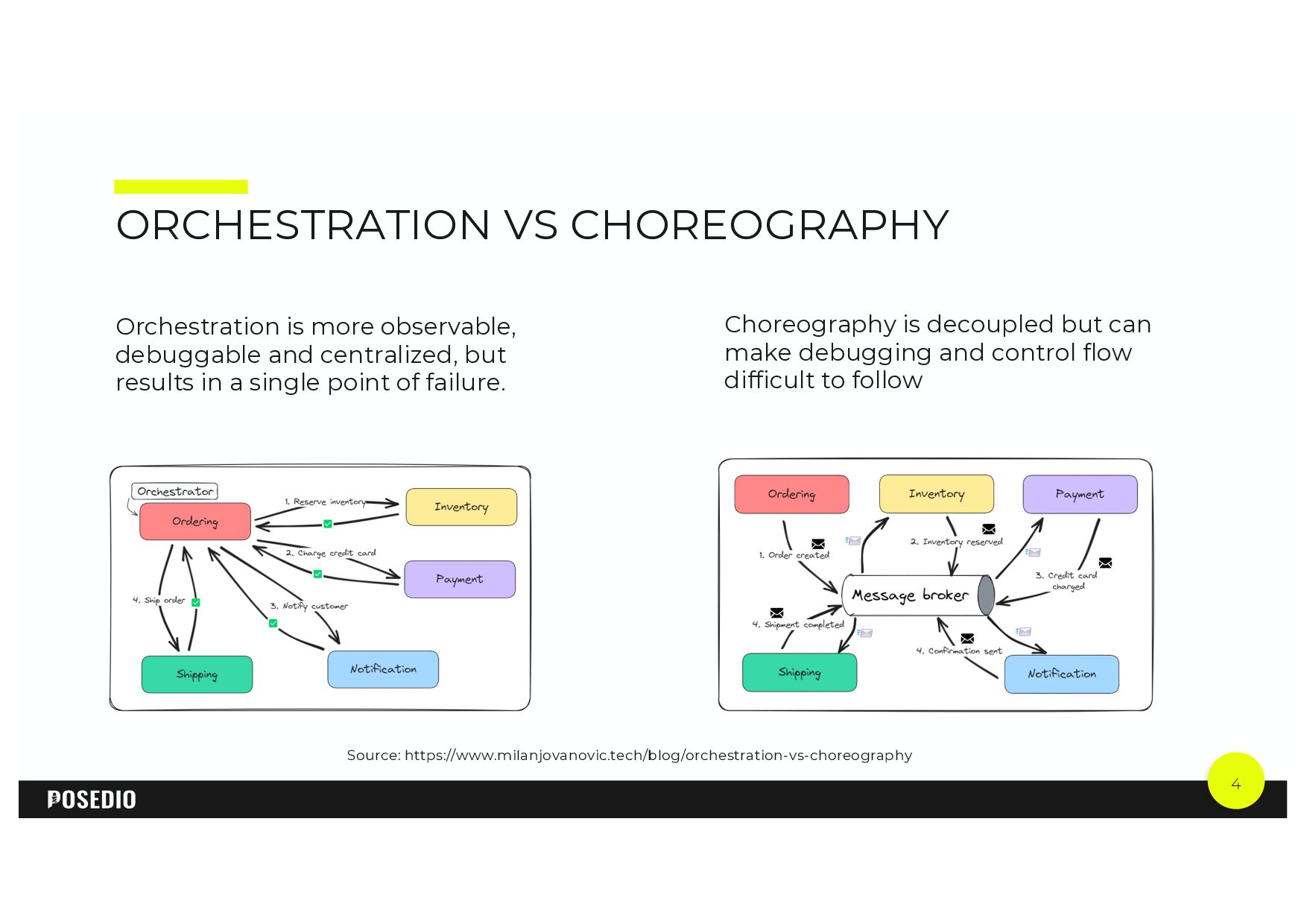{kind=link}
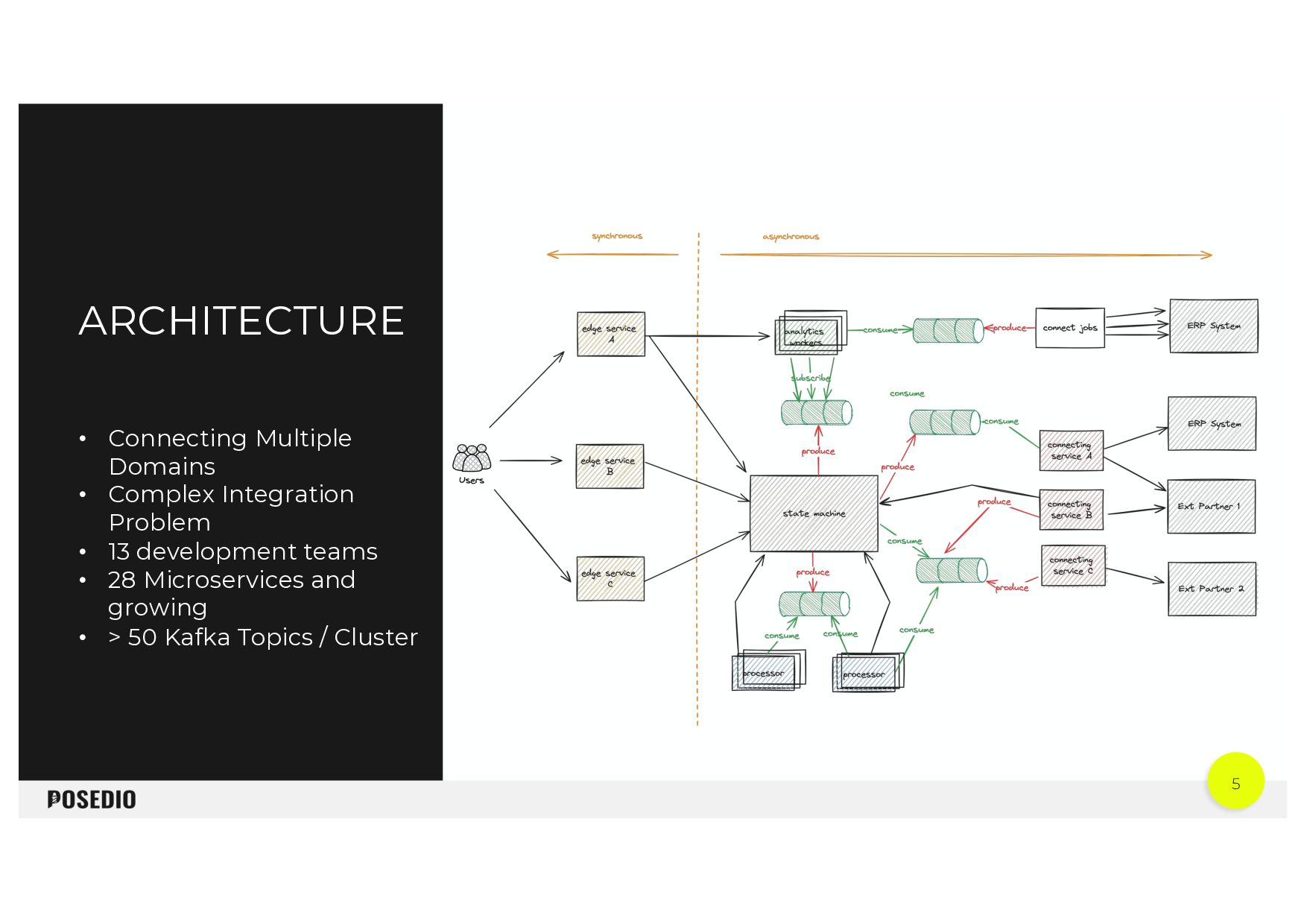{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
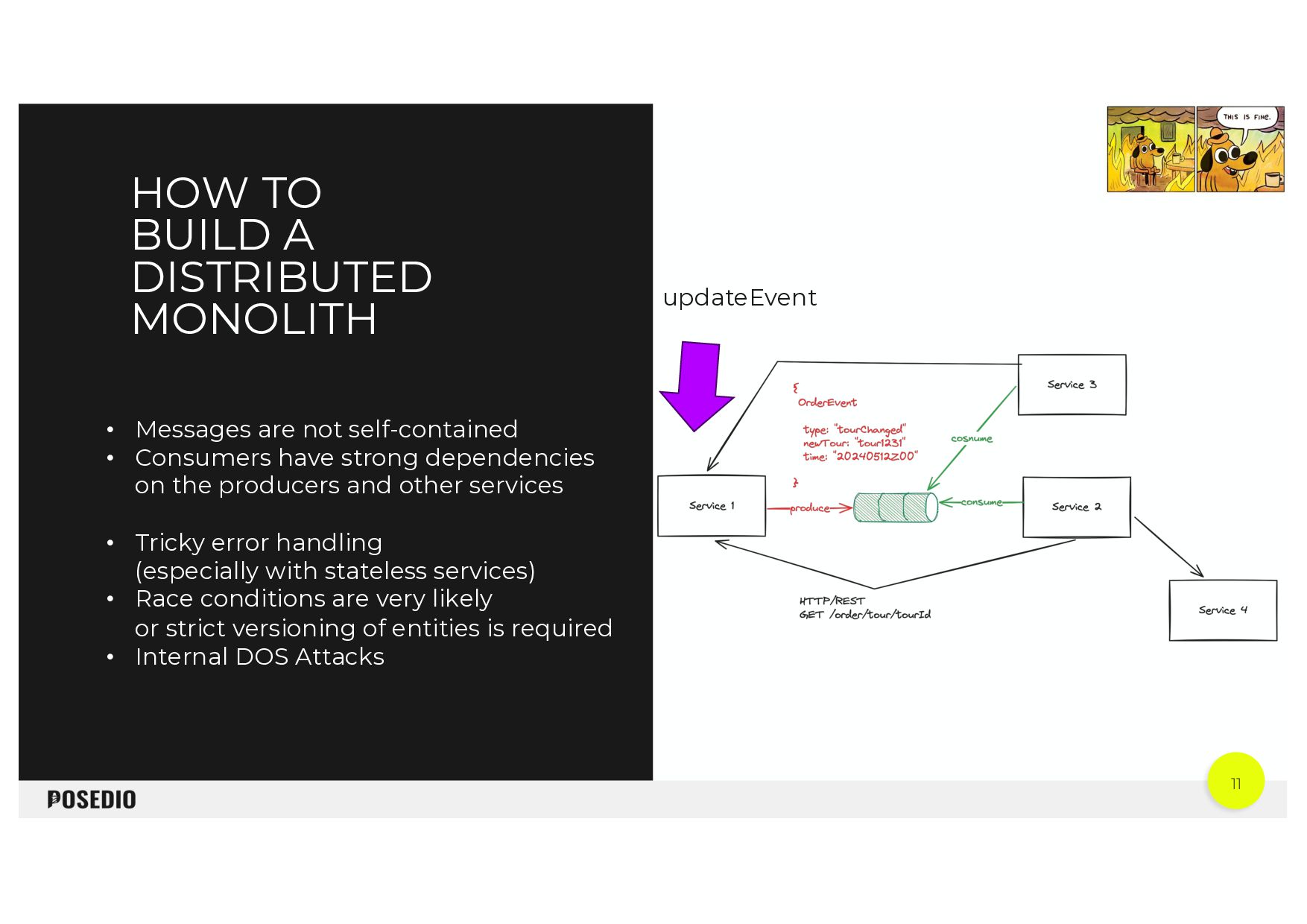{kind=link}
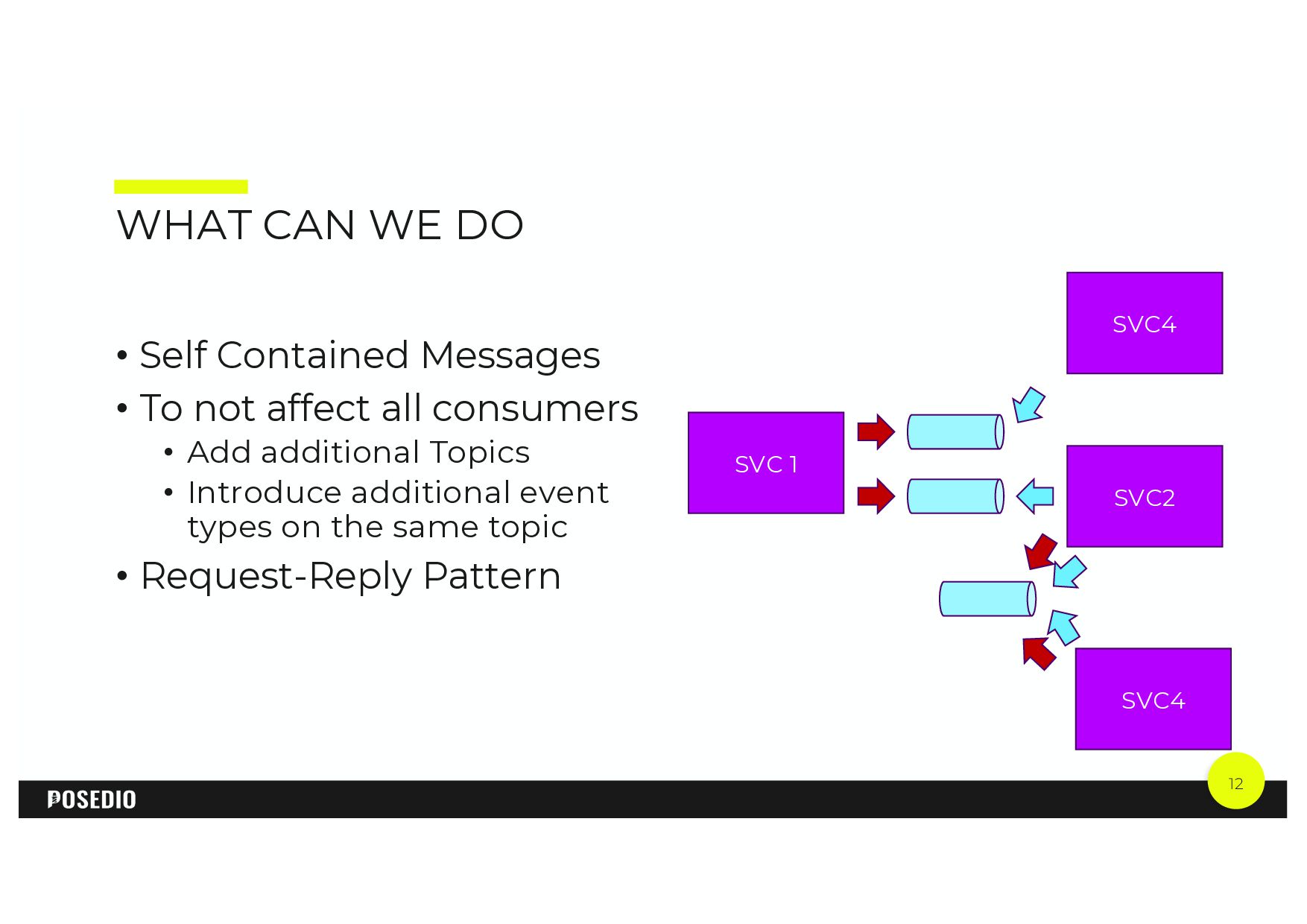{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
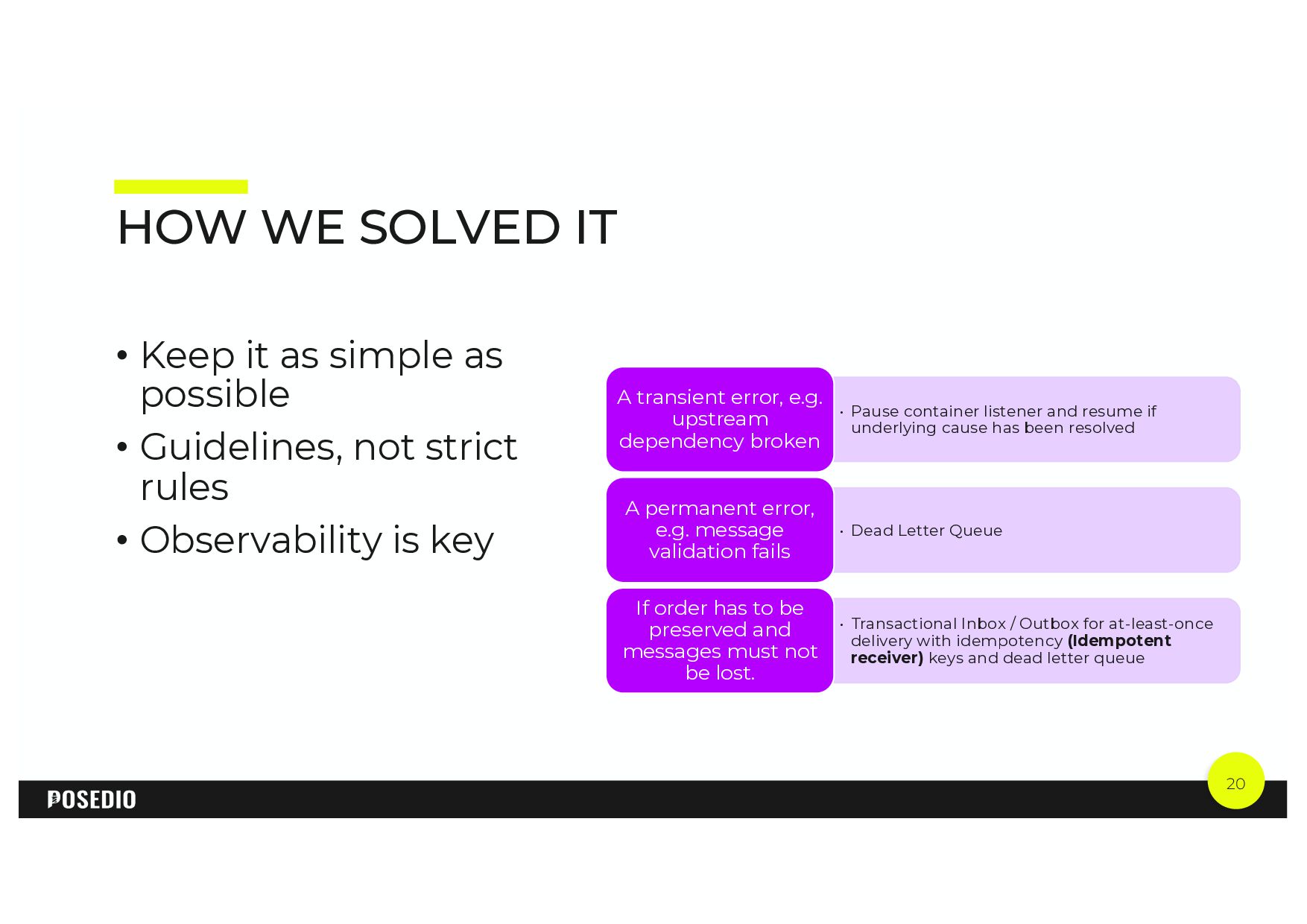{kind=link}
{kind=link}
{kind=link}
{kind=link}
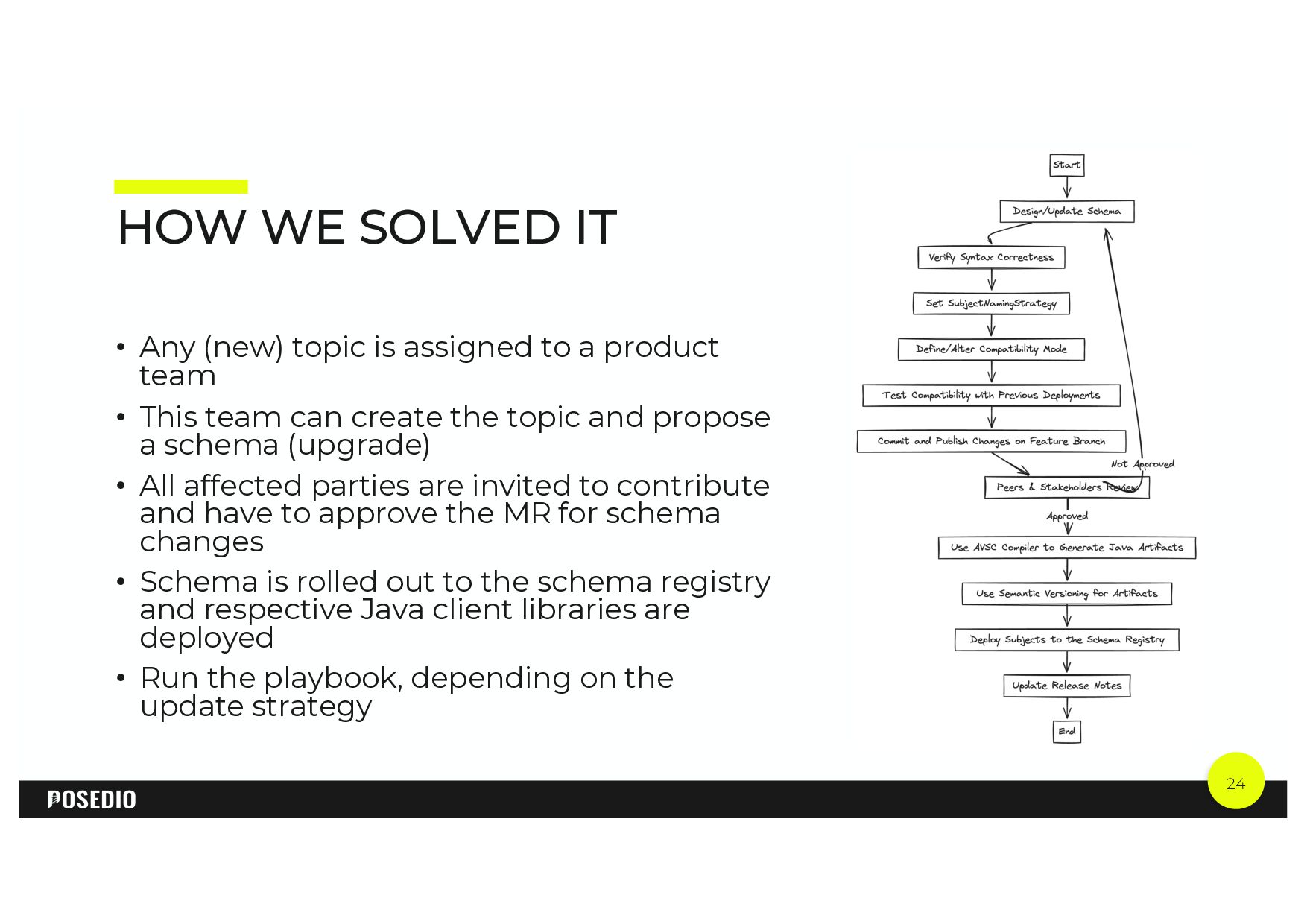{kind=link}
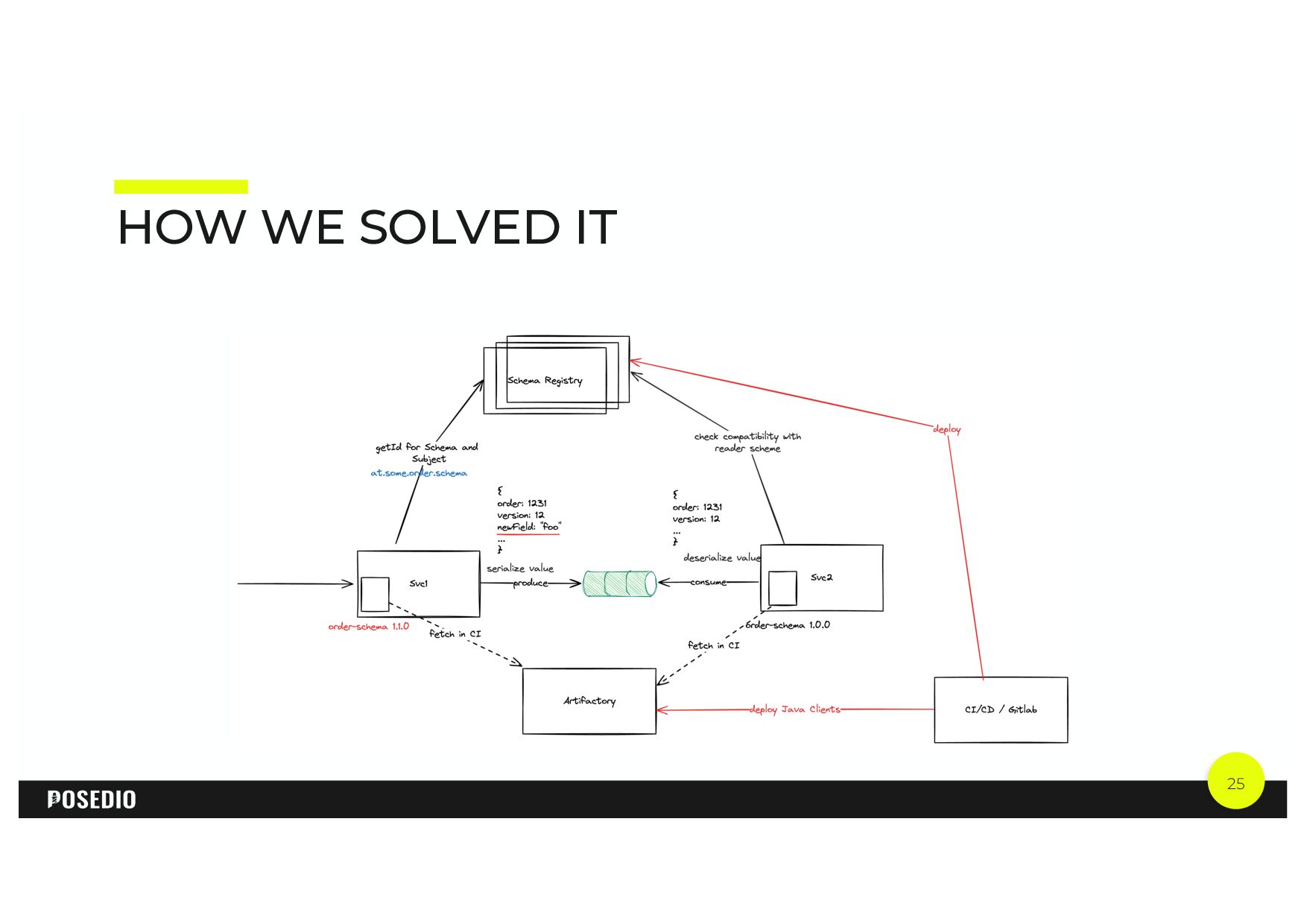{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
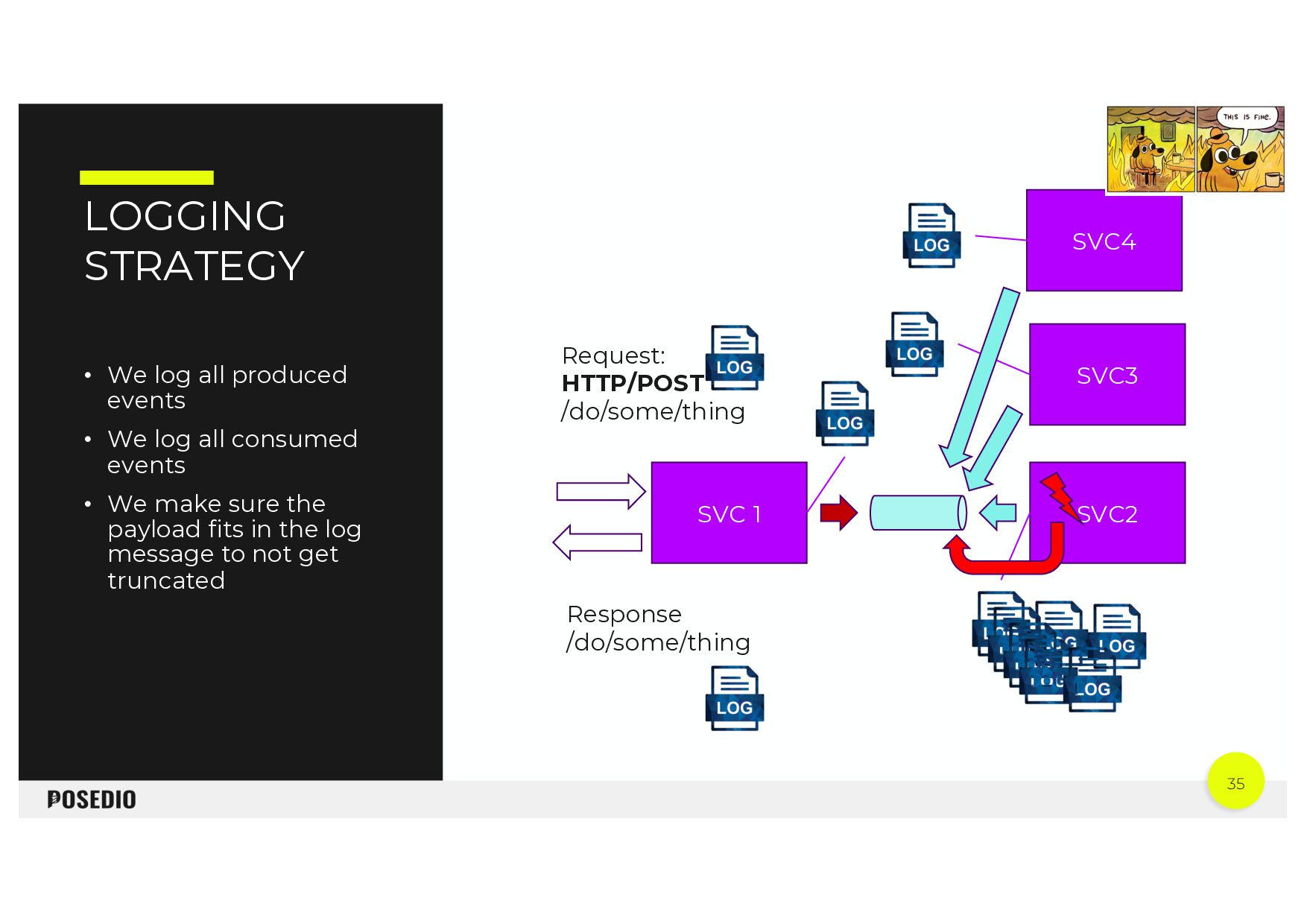{kind=link}
{kind=link}
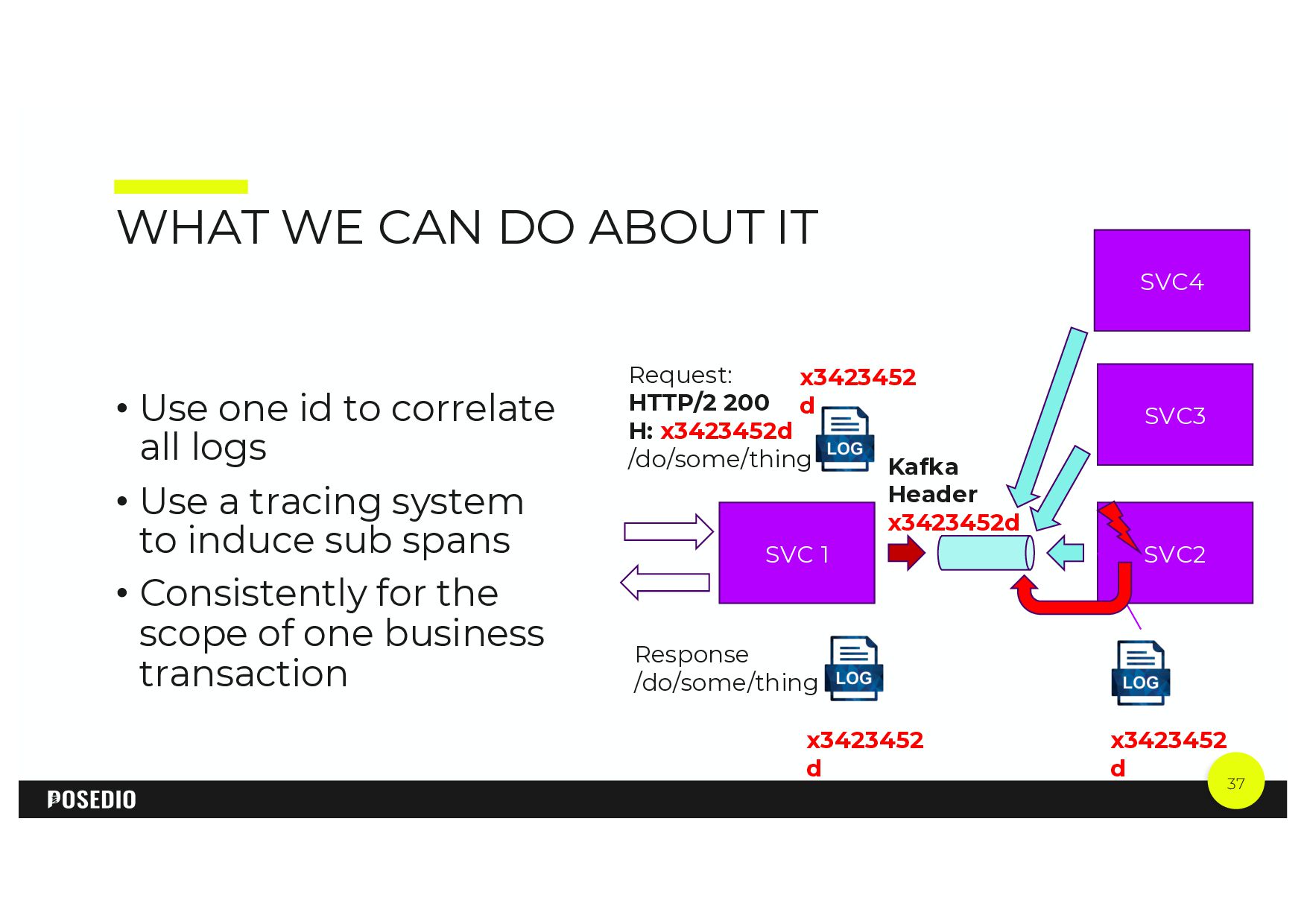{kind=link}
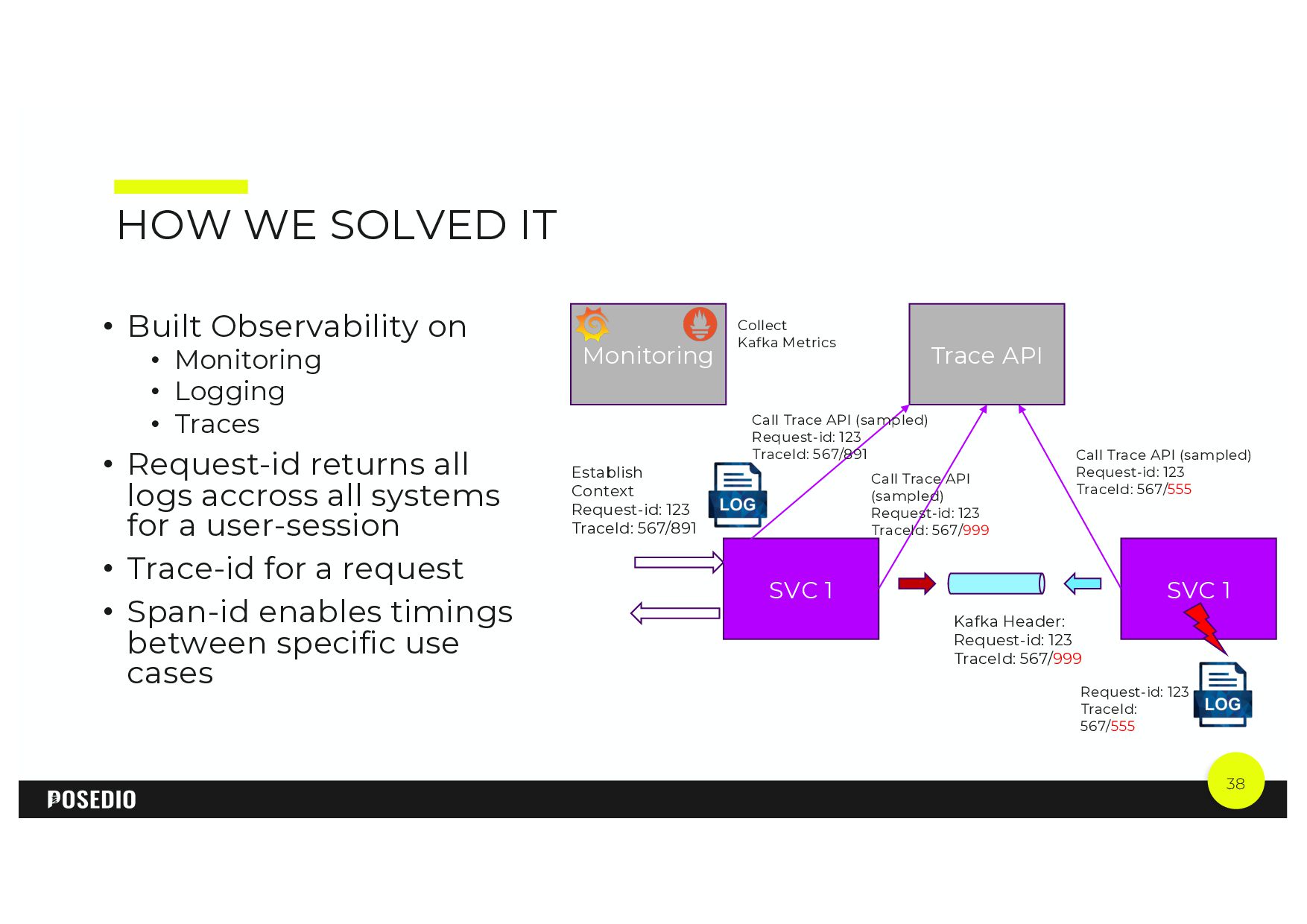{kind=link}
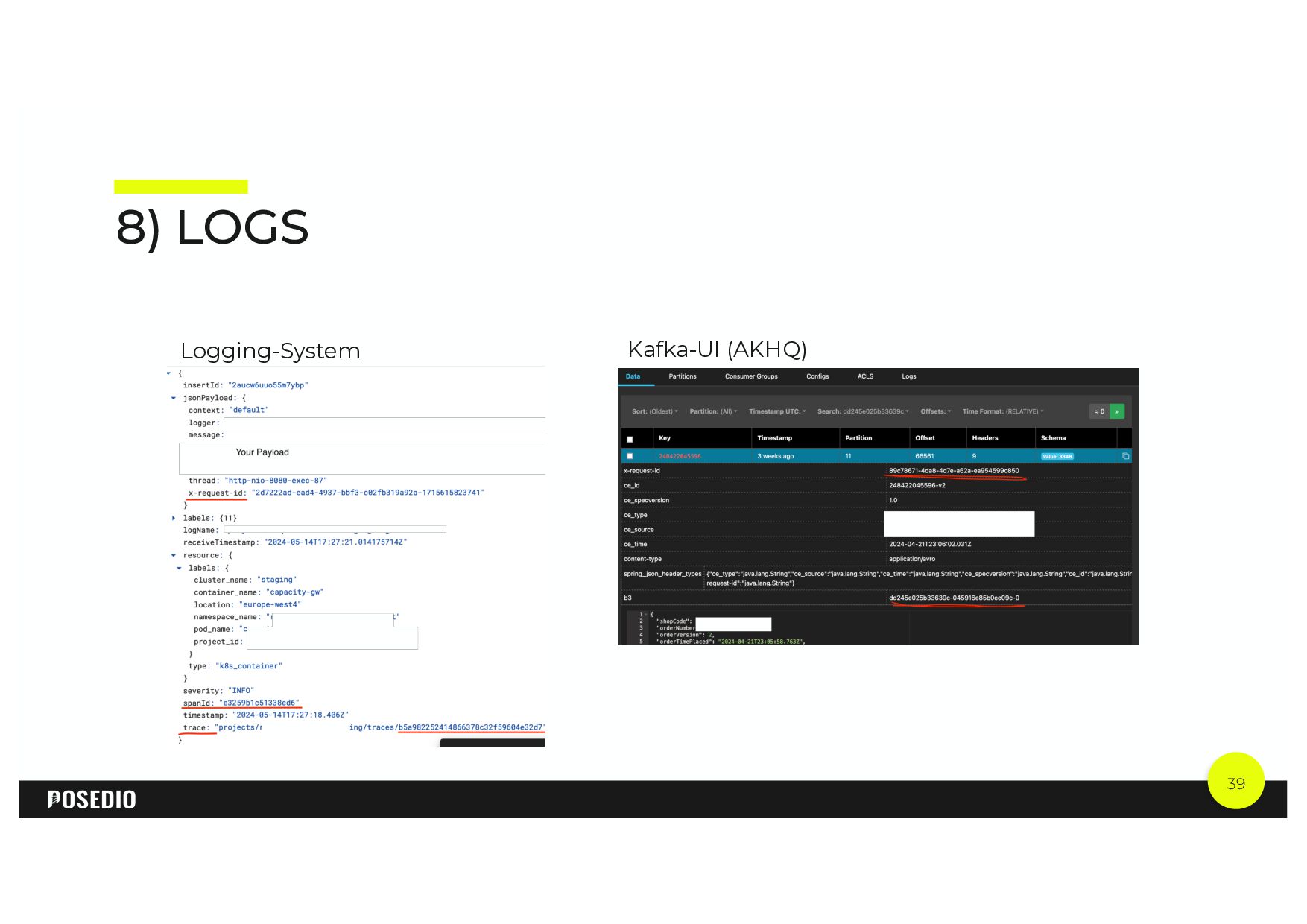{kind=link}
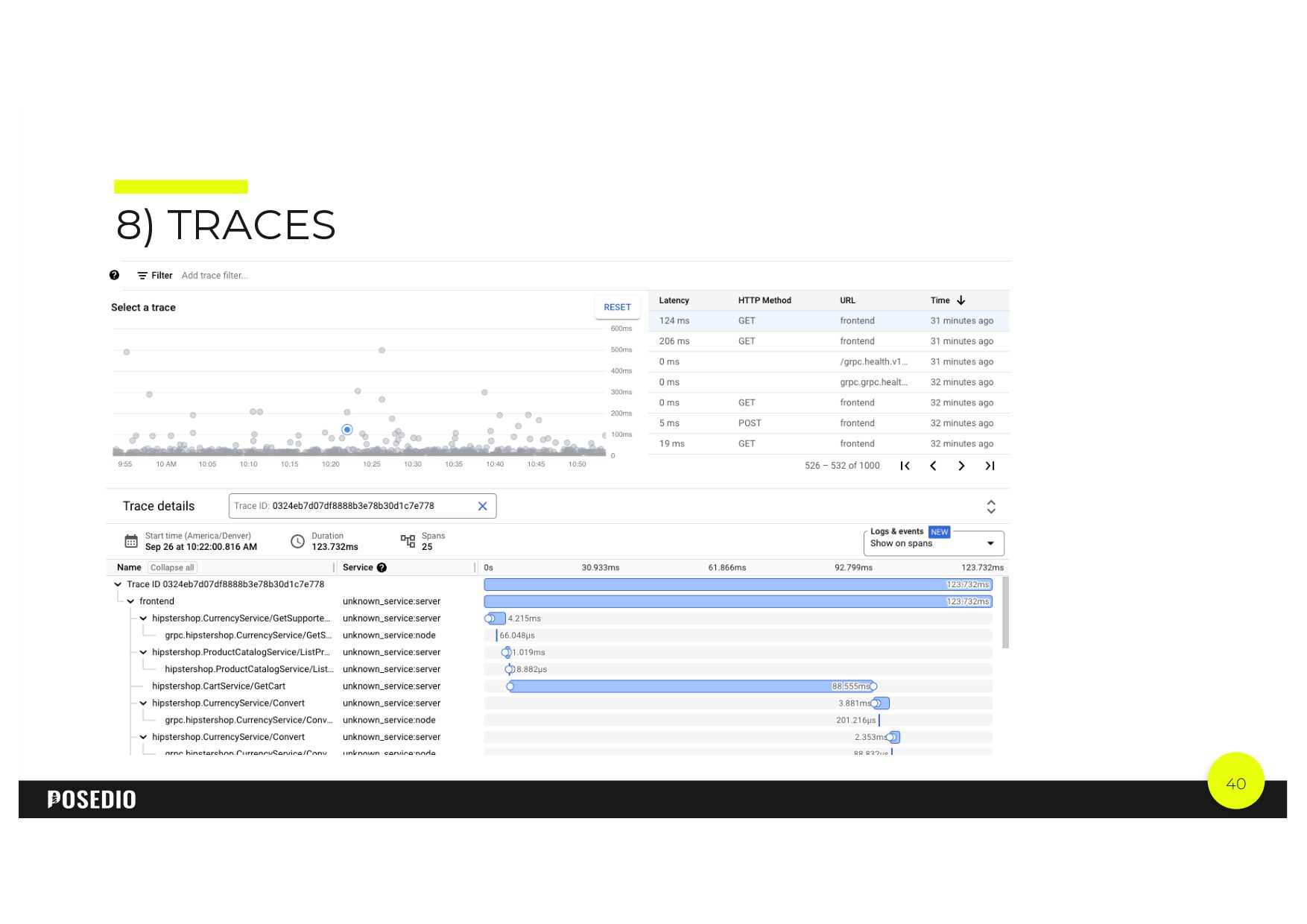{kind=link}
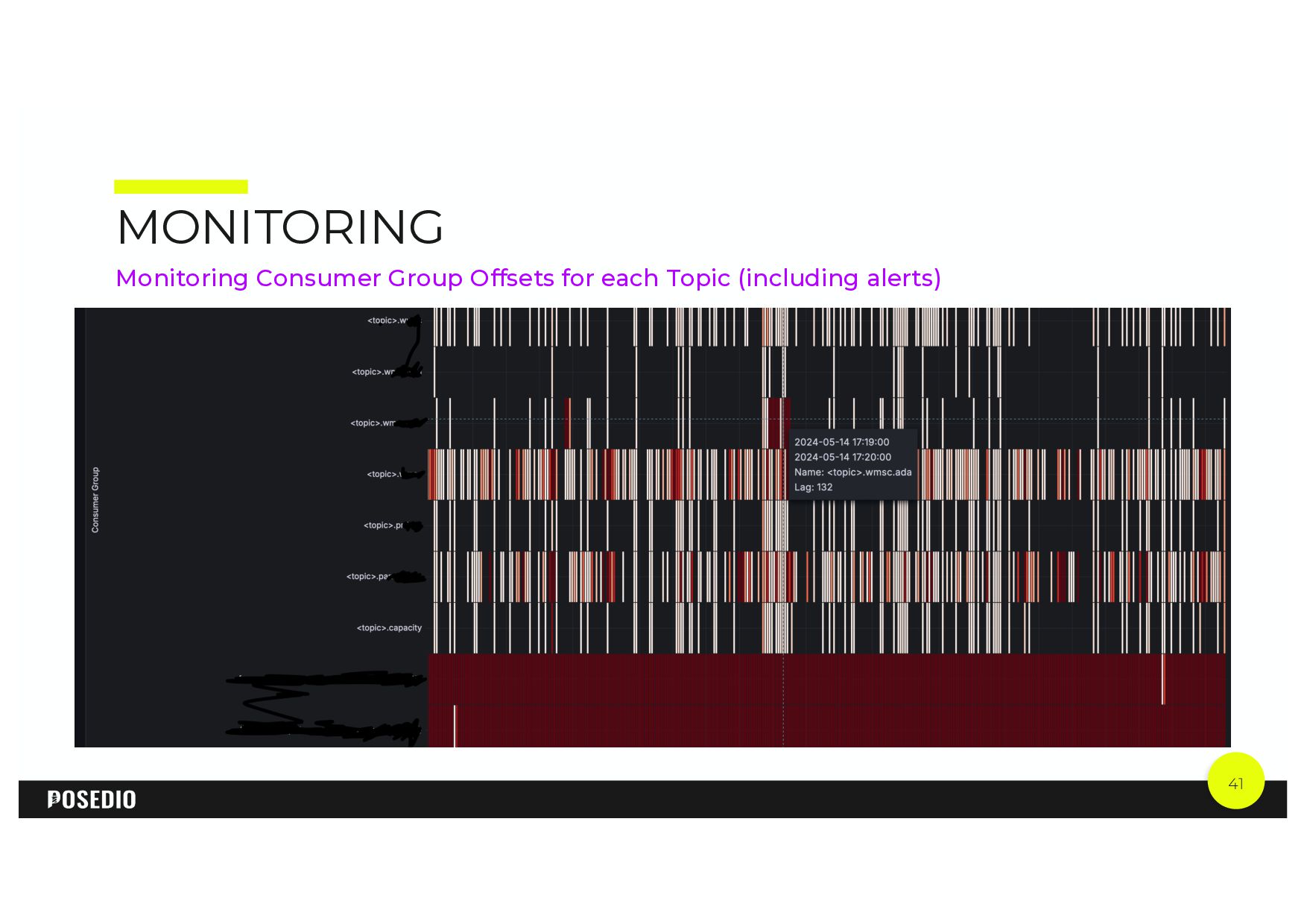{kind=link}
{kind=link}