Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSでデータ解析を始めたーい
Search
koara
September 16, 2023
Technology
350
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSでデータ解析を始めたーい
四国クラウドお遍路 2023
koara
September 16, 2023
More Decks by koara
See All by koara
SST ( Serverless Stack Toolkit ) 使ってみた
ra1211
0
250
もめんと会 Momento Cache
ra1211
0
79
JAWS-UG 名古屋 AVAハンズオン+re:Inforceの復習
ra1211
0
130
JAWS ミート 2023
ra1211
0
78
JAWS-UG大阪 AWS re:Invent 2022 re:Cap
ra1211
0
130
20221112_四国クラウドお遍路.pdf
ra1211
0
360
Other Decks in Technology
See All in Technology
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
230
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
DatabricksにおけるMCPソリューション
taka_aki
1
250
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
810
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.3k
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
2
280
SRE Lounge Hiroshimaへの招待
grimoh
0
640
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.2k
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
240
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Featured
See All Featured
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Six Lessons from altMBA
skipperchong
29
4.3k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Technical Leadership for Architectural Decision Making
baasie
3
440
30 Presentation Tips
portentint
PRO
1
350
Building AI with AI
inesmontani
PRO
1
1.1k
Paper Plane
katiecoart
PRO
2
52k
The browser strikes back
jonoalderson
0
1.4k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
200
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Transcript
AWSでデータ分析を始めたーい クラウドお遍路 2023/09/16
Who am I ? { "name": "古賀巧", "X_id": "@koara__fftr", "age":
27, "career": [ “C”, ”C++”, ”C#”, ”JavaScript”, ”PHP”], "hobbies": ["音楽"], "certifications": [ ], "favorite_AWS_service": "AWS Lambda", "other": [ ] }
・はじめに ・データ分析の流れ ・AWSのデータ分析サービス ・Amazon AthenaでNo ETLで、分析してみる ・AWS Glue DataBrewでETLして、分析してみる ・まとめ
Contents
はじめに AWSを使いたい動機 オンプレで大量のデータを扱うためのリソースの調達や管理などが難しい したくない サクッと試して、今あるデータでどんなことをできるか知りたい 小さく作って、早く失敗して、改善していきたい
はじめに データ分析の流れ データ収集 蓄積・加工 可視化・分析
データ分析の流れ 1° 収集 データを集める 例) システムのアクセスログ IoTセンサーのデータ 購買履歴 音声データ SNSデータ
データ分析の流れ 部門や地域で サイロ化したデータを DLに集める 2°-1 蓄積・加工 DWH、DMに格納 分析しやすい形式に加工 ETL処理
データ分析の流れ Extraxt 2°-2 加工処理 データ分析全体の8割くらいを占める Transform Load Extraxt Load Transform
データを加工してから、書き出す →非構造化データにも対応 データを書き出してから、加工する
データ分析の流れ 2°で加工したデータを BIツールでの可視化や 機械学習の学習データとして活用 3° 可視化・分析
AWSのデータ分析サービス 収集 蓄積・加工 可視化・分析
Amazon AthenaでNo ETLで、分析してみる Amazon Athena サーバレスでインフラ管理不要 S3に保存・蓄積したログに対してSQLクエリを投げて データをロードせずに直接分析を行える
Amazon AthenaでNo ETLで、分析してみる 1°データをS3に保存する サポートしているデータ形式 Apache Parquet ORC CloudTrail ログ
CSV、TSV JSON など 行指向データ 行ごとにデータを保存 特定の列を扱う場合でも、行全体を読み込む必要がある 列指向データ 列ごとにデータを保存 特定の列だけ扱う処理では、行全体を読み込む必要がない
Amazon AthenaでNo ETLで、分析してみる 2°「データベース」と「テーブル」の作成 データベース・・・テーブルをグループにまとめる テーブル・・・列名、データ型などを定義 テーブル定義の作成 ・DDL(Data Define Language)で定義する
・Glue Crawlerで自動作成 列名やデータ型を推測して、作成してくれる
Amazon AthenaでNo ETLで、分析してみる 3°SQLでクエリ クエリ結果はS3に自動保存 コンソールから履歴も確認できる ANSI標準のSQLが使える(標準のSQL)
Amazon AthenaでNo ETLで、分析してみる +α 横串検索(Federated Query) データコネクタを利用した、複数データソースに横断的なクエリを実行
Amazon Athenaのパフォーマンスチューニング その他 Amazon Athena のパフォーマンスチューニング Tips トップ 10 https://aws.amazon.com/jp/blogs/news/top-10-performance-tuning-tips-for-amazon-athena/
1° スキャンするデータ量を減らす →列指向データ(Apache Parquet、ORCなど)を使用する →データの圧縮(Snappy→圧縮/解凍が速い, LZOなど) 2° 小さいサイズをまとめる 128MB以上にする 3° データをパーティションで分割する 例)2023/09/13 /14 /15 Amazon Athena でのパーティション射影 https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partition-projection.html
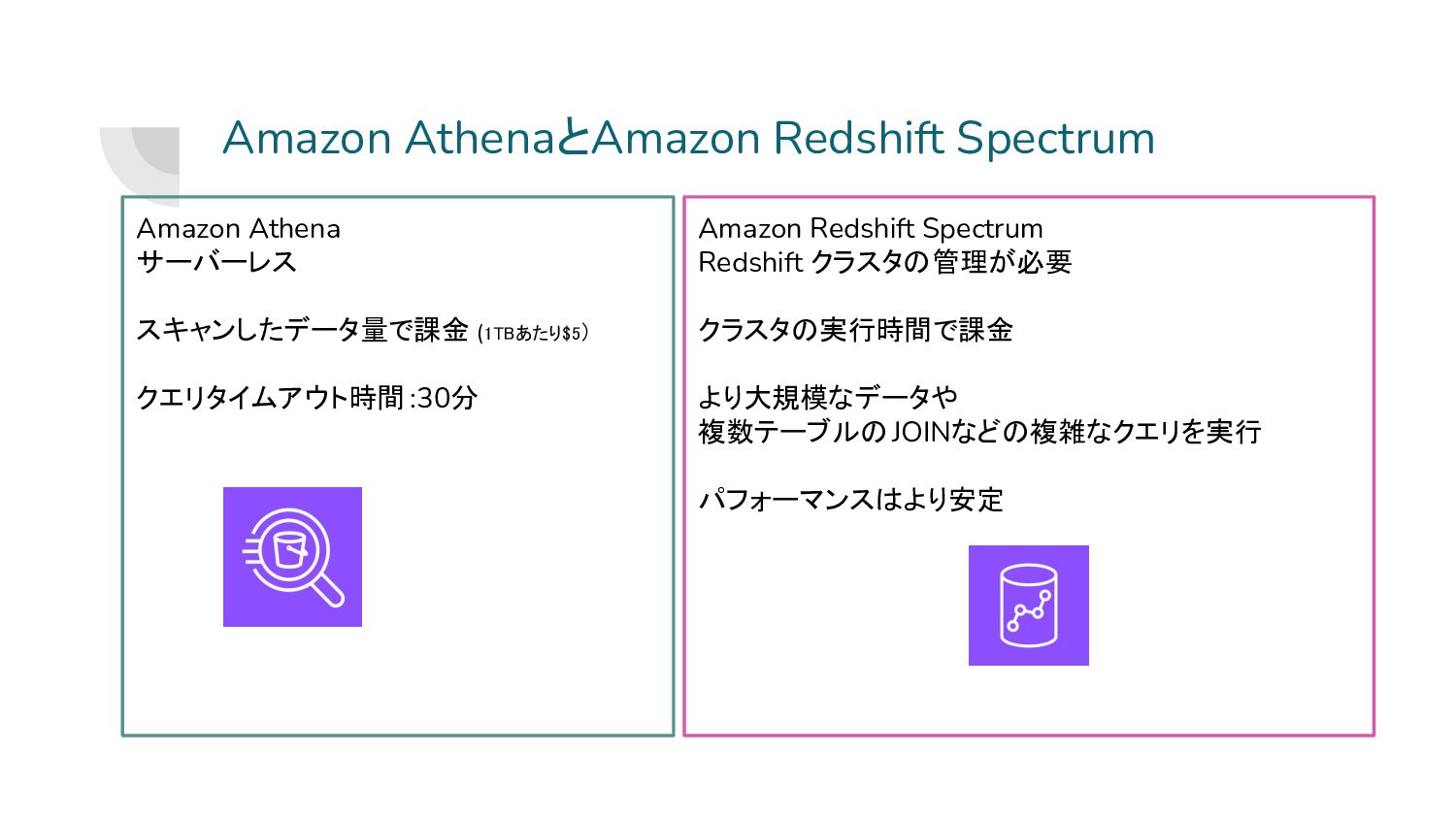
Amazon AthenaとAmazon Redshift Spectrum Amazon Athena サーバーレス スキャンしたデータ量で課金 (1TBあたり$5) クエリタイムアウト時間
:30分 Amazon Redshift Spectrum Redshift クラスタの管理が必要 クラスタの実行時間で課金 より大規模なデータや 複数テーブルのJOINなどの複雑なクエリを実行 パフォーマンスはより安定
簡単に(?) AWS Glue DataBrewでETLして、分析してみる AWS Glue DataBrew は視覚的なデータ準備ツール であり、データアナリストやデー タサイエンティストはデータをより簡単にクリーンアップおよび正規化し、分析や機
械学習 (ML) の準備をすることができます。250 を超える事前構築された変換から 選択して、コードを記述することなくデータ準備タスクを自動化 できます。異常のフィ ルタリング、標準形式へのデータの変換、無効な値の修正などのタスクを自動化で きます。データの準備が整ったら、 すぐに分析と ML プロジェクトに使用で きます。 実際に使用した分に対してのみ料金が発生します。前払いの義務はありません。 https://aws.amazon.com/jp/glue/features/databrew/
簡単に(?) AWS Glue DataBrewでETLして、分析してみる DataBrewプロジェクトを作成 DataBrew レシピにデータ加工処理を記録
簡単に(?) AWS Glue DataBrewでETLして、分析してみる 一旦、赤枠のデータ操作は無視してデータと向き合う (坐禅タイム
簡単に(?) AWS Glue DataBrewでETLして、分析してみる 列ごとに統計情報と それに対するレコメンドを確認できる
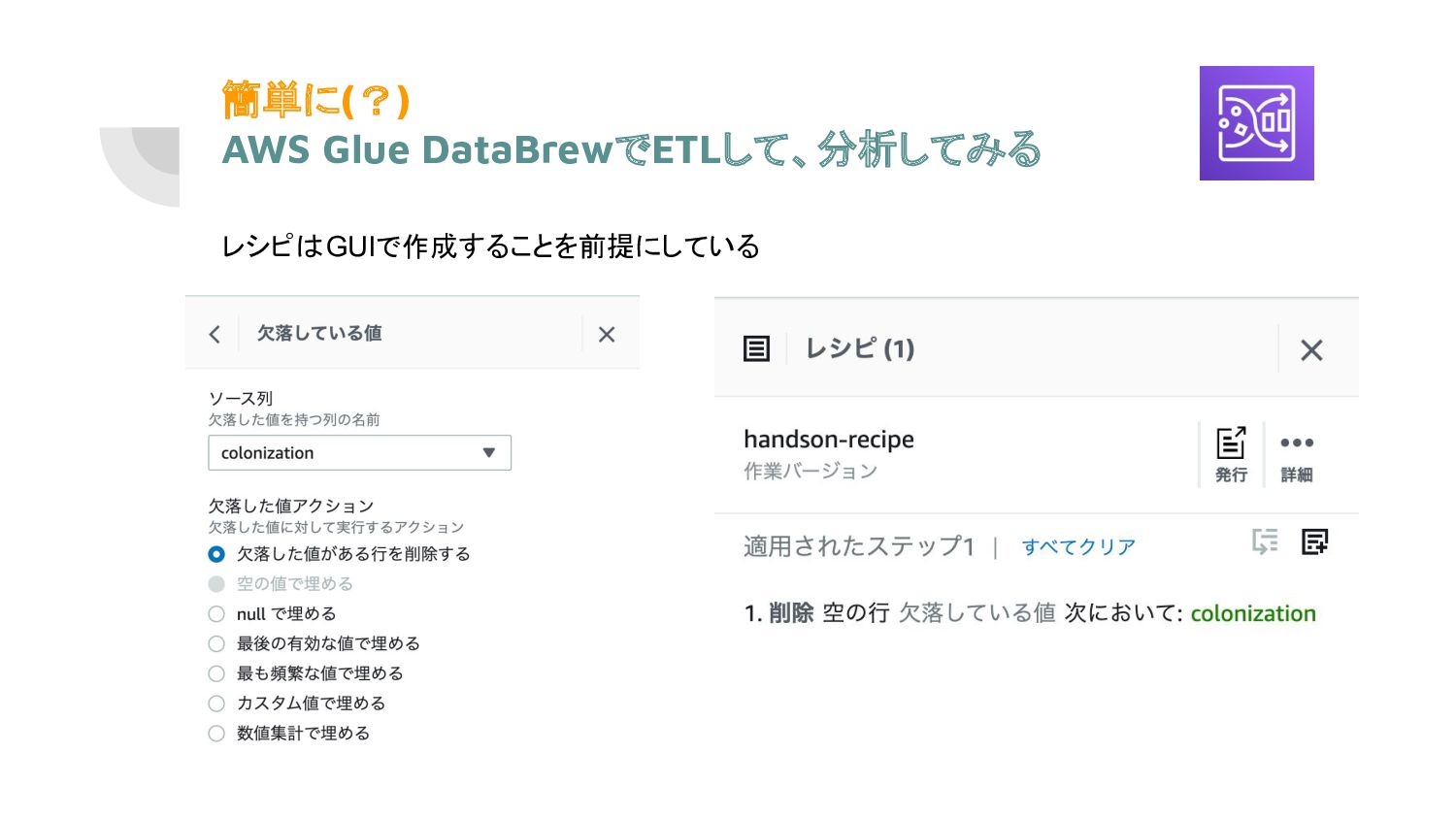
簡単に(?) AWS Glue DataBrewでETLして、分析してみる レシピはGUIで作成することを前提にしている
簡単に(?) AWS Glue DataBrewでETLして、分析してみる レシピからジョブを作成
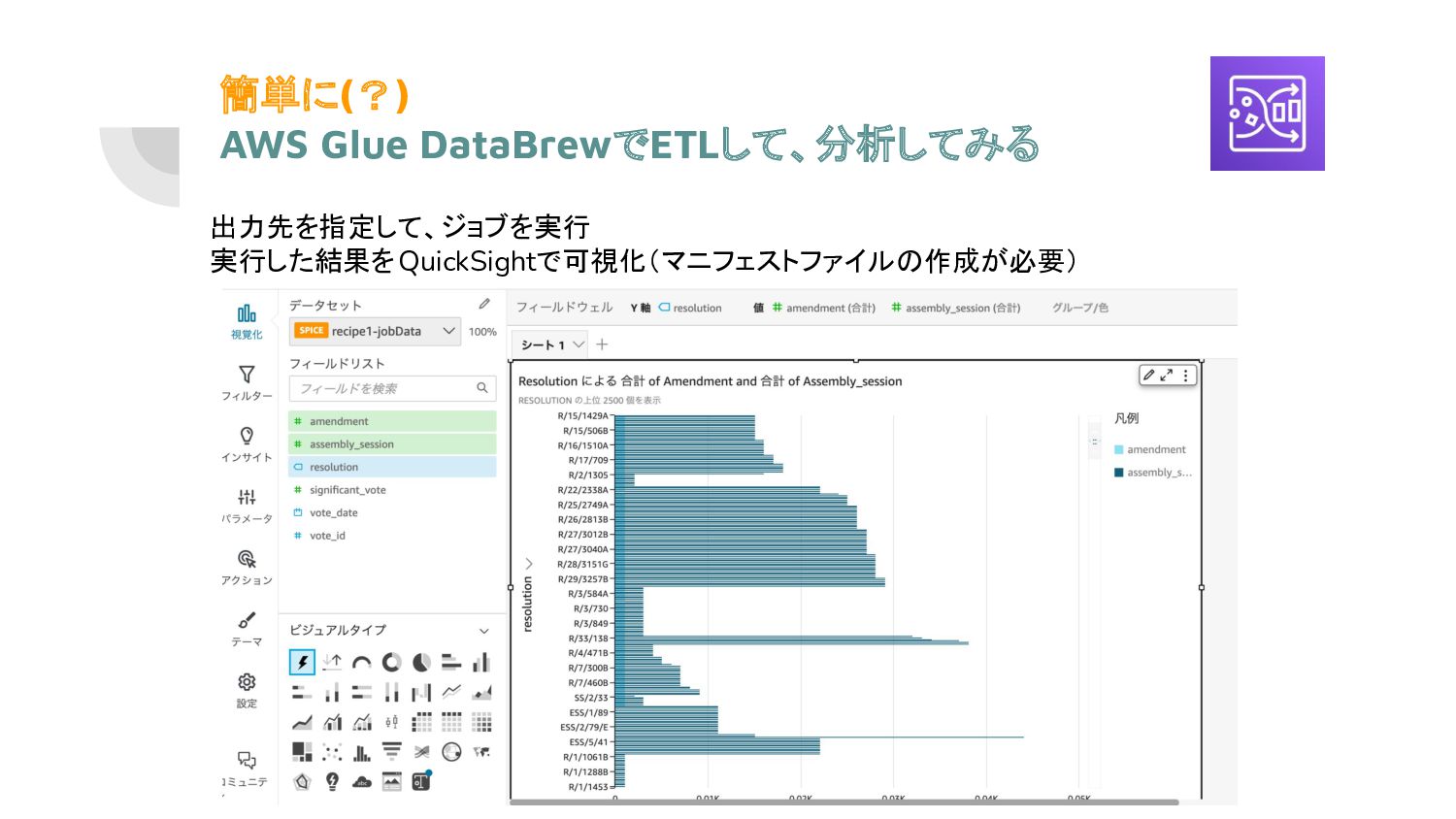
簡単に(?) AWS Glue DataBrewでETLして、分析してみる 出力先を指定して、ジョブを実行 実行した結果をQuickSightで可視化(マニフェストファイルの作成が必要)
Glue Databrew Glue Studio データを可視化して GUIでETLジョブの作成 用意された変換処理が200種類以上 GUIとコード両方を使用可能 ETLジョブの作成、実行、実行状況の監視
用意された変換処理は 40個 2つを組み合わせて使用することも可能 Glue DataBrewでデータの傾向把握と用意された変換処理を行い Glue DataBrewで足りない部分はGlue Studioでコードを書いて実現
まとめ AWSを使うことで ・データアクセスの民主化 + ・ツールの民主化 ・分析スキルの民主化へ
ちょっと宣伝
ちょっと宣伝2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}