benchmarking variant calling algorithms - For once one tells how synthetic data is created - Benchmarking valid for alignment / variant calling - Smart ‘niche’ targeting from the authors - Performance (tool robustness) is also important - Authors concerned about reproducibility
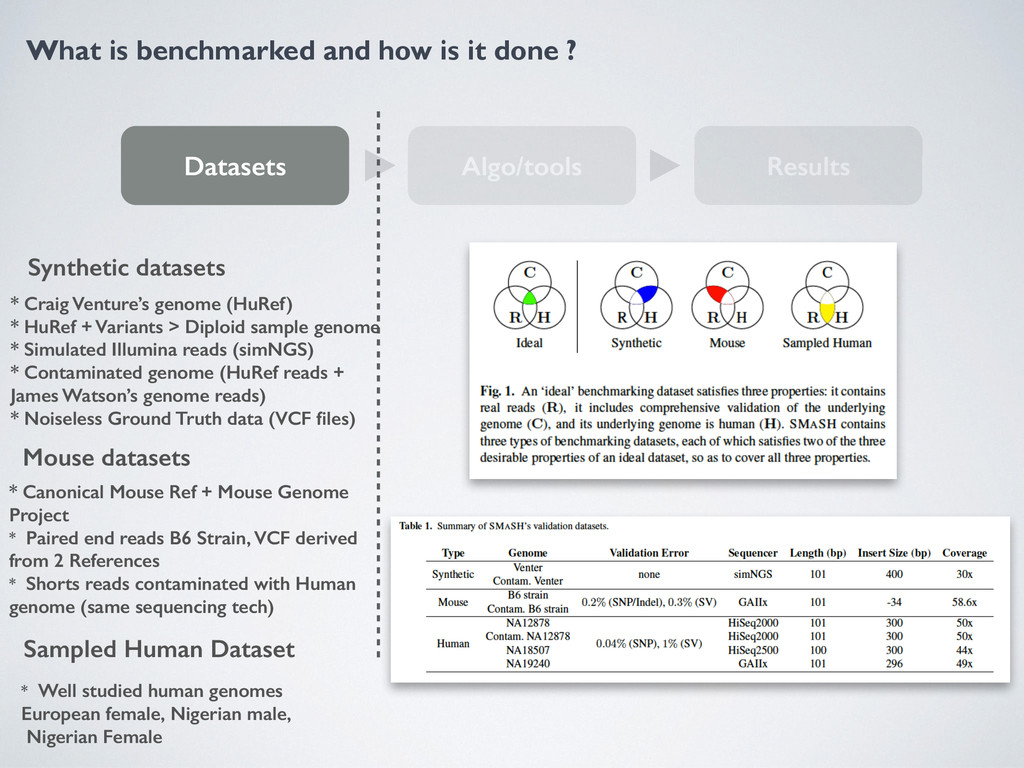
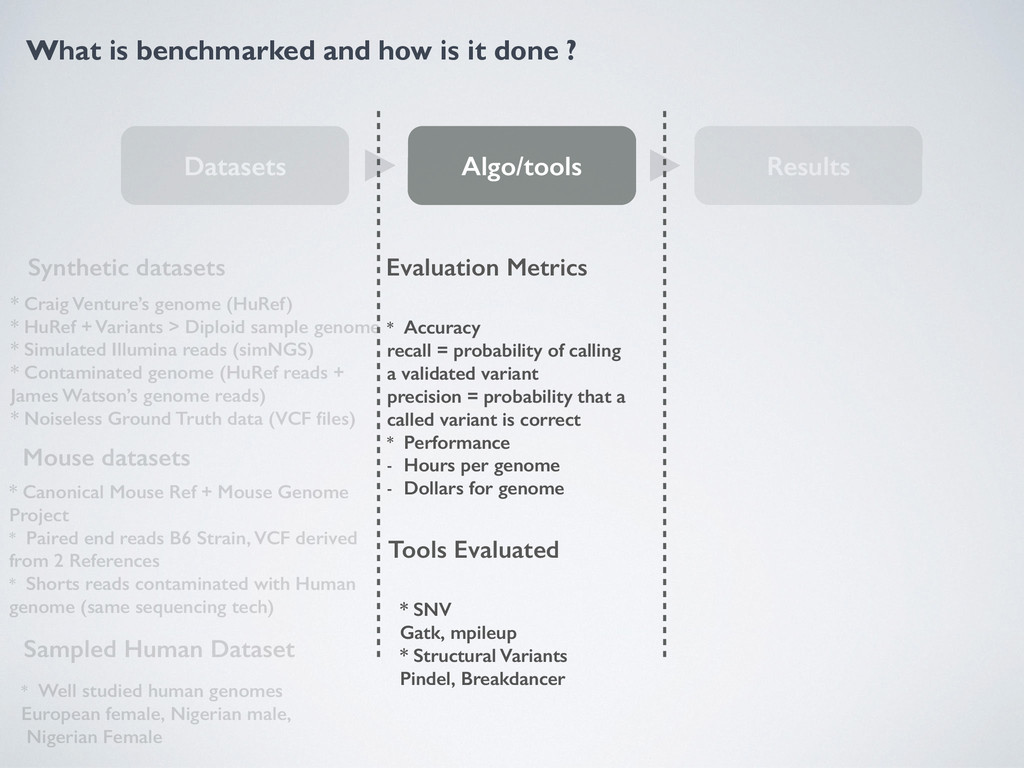
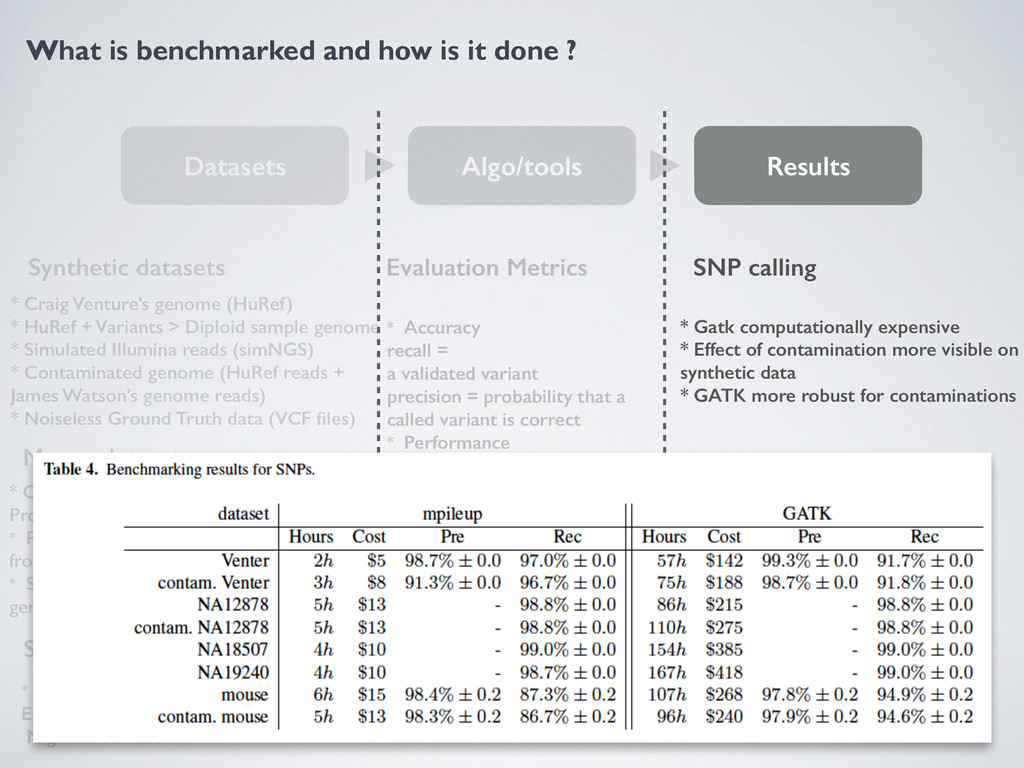
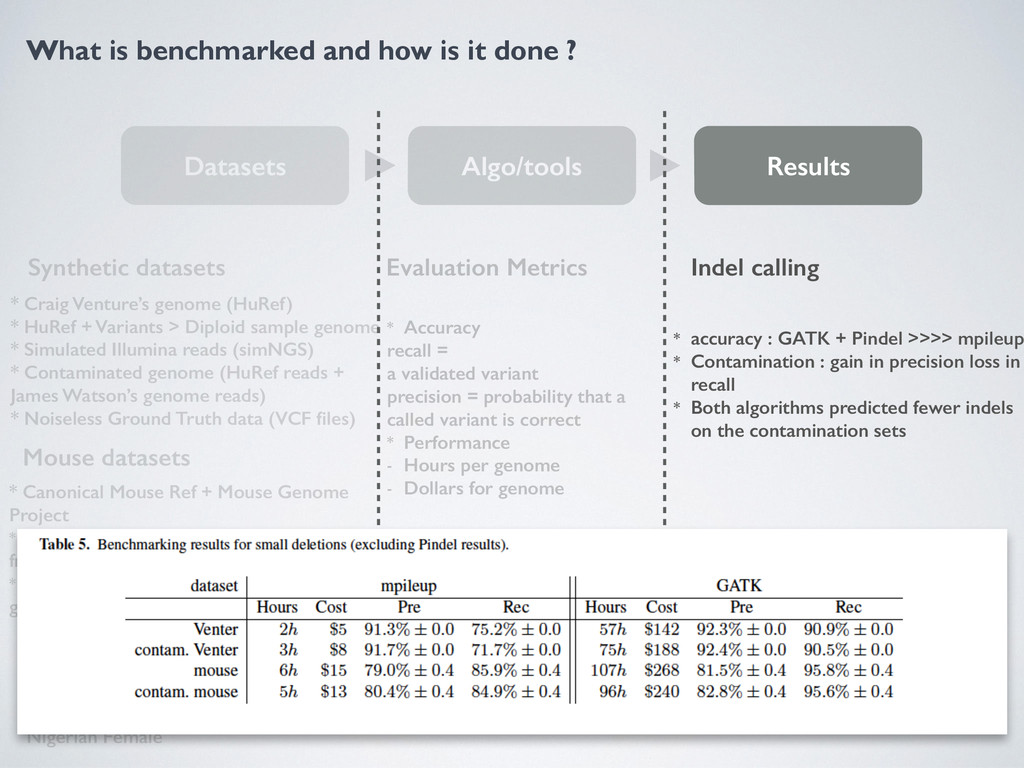
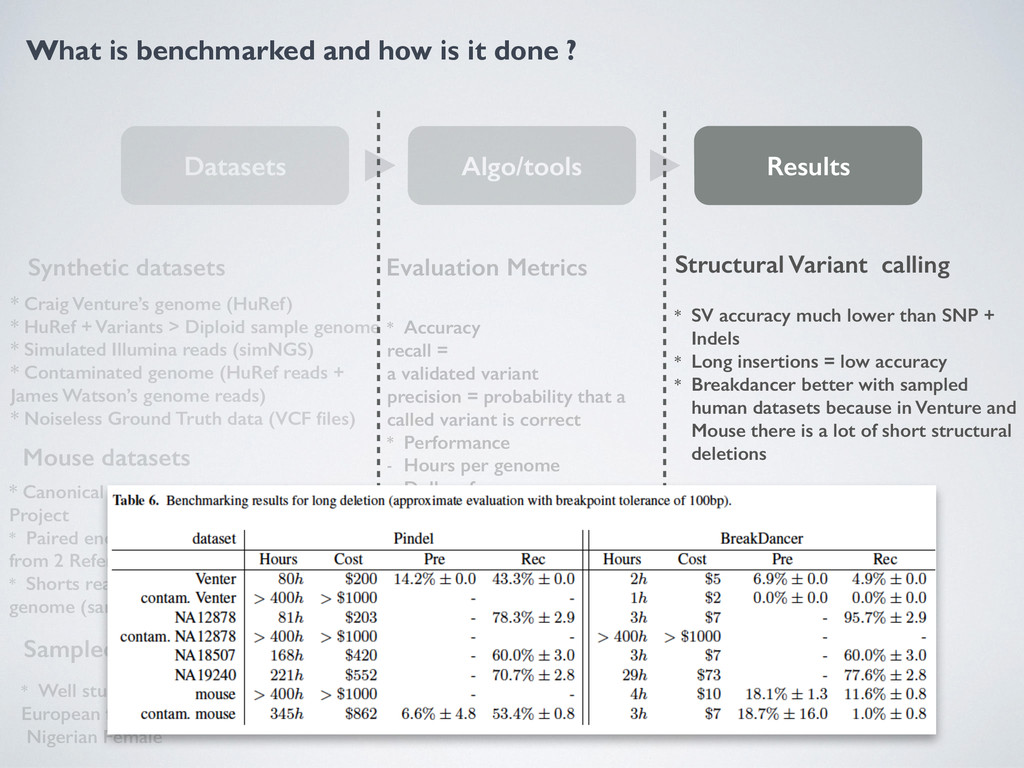
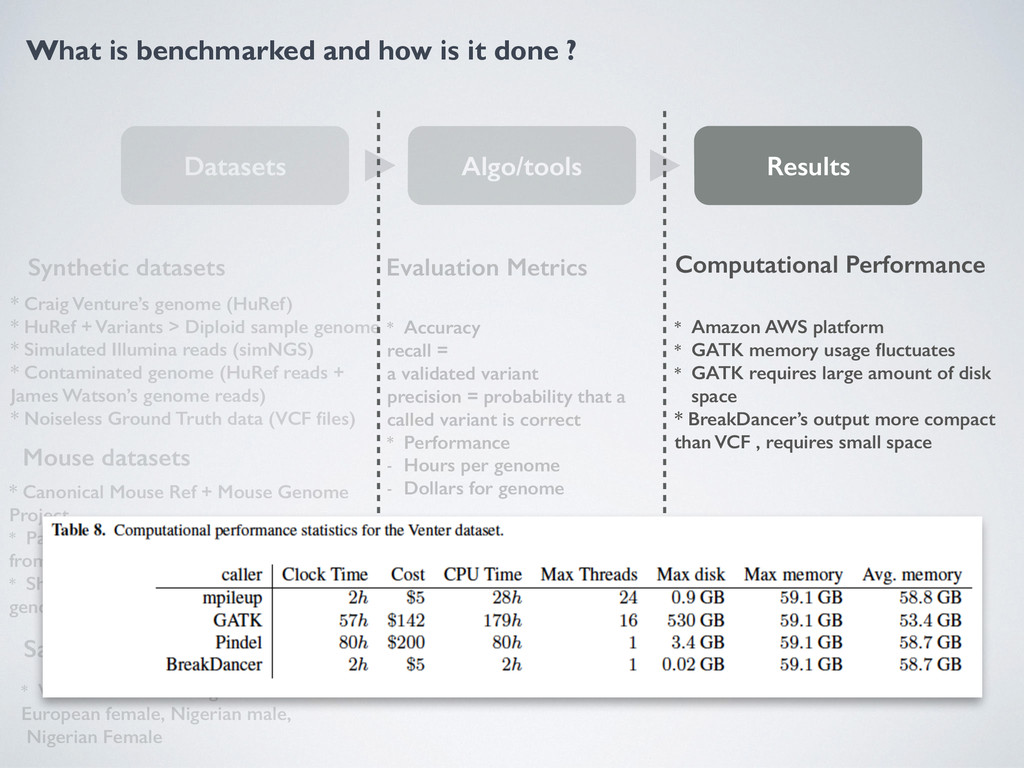
Algo/tools Results Synthetic datasets Mouse datasets Sampled Human Dataset * Craig Venture’s genome (HuRef) * HuRef + Variants > Diploid sample genome * Simulated Illumina reads (simNGS) * Contaminated genome (HuRef reads + James Watson’s genome reads) * Noiseless Ground Truth data (VCF files) * Canonical Mouse Ref + Mouse Genome Project * Paired end reads B6 Strain, VCF derived from 2 References * Shorts reads contaminated with Human genome (same sequencing tech) * Well studied human genomes European female, Nigerian male, Nigerian Female Evaluation Metrics * Accuracy recall = a validated variant precision = probability that a called variant is correct * Performance - Hours per genome - Dollars for genome Tools Evaluated * SNV Gatk, mpileup * Structural Variants Pindel, Breakdancer Structural Variant calling * SV accuracy much lower than SNP + Indels * Long insertions = low accuracy * Breakdancer better with sampled human datasets because in Venture and Mouse there is a lot of short structural deletions
like - The paper could be more valuable if other tools were involved - Performance could be proven differently - AWS is not intended to measure performance : authors tried to be fancy ? - You can tell authors are not visual ! Overall ! - More effort is needed to benchmark callers - Sounds very similar to Dream - Authors listed benchmarking efforts I didn’t know
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}