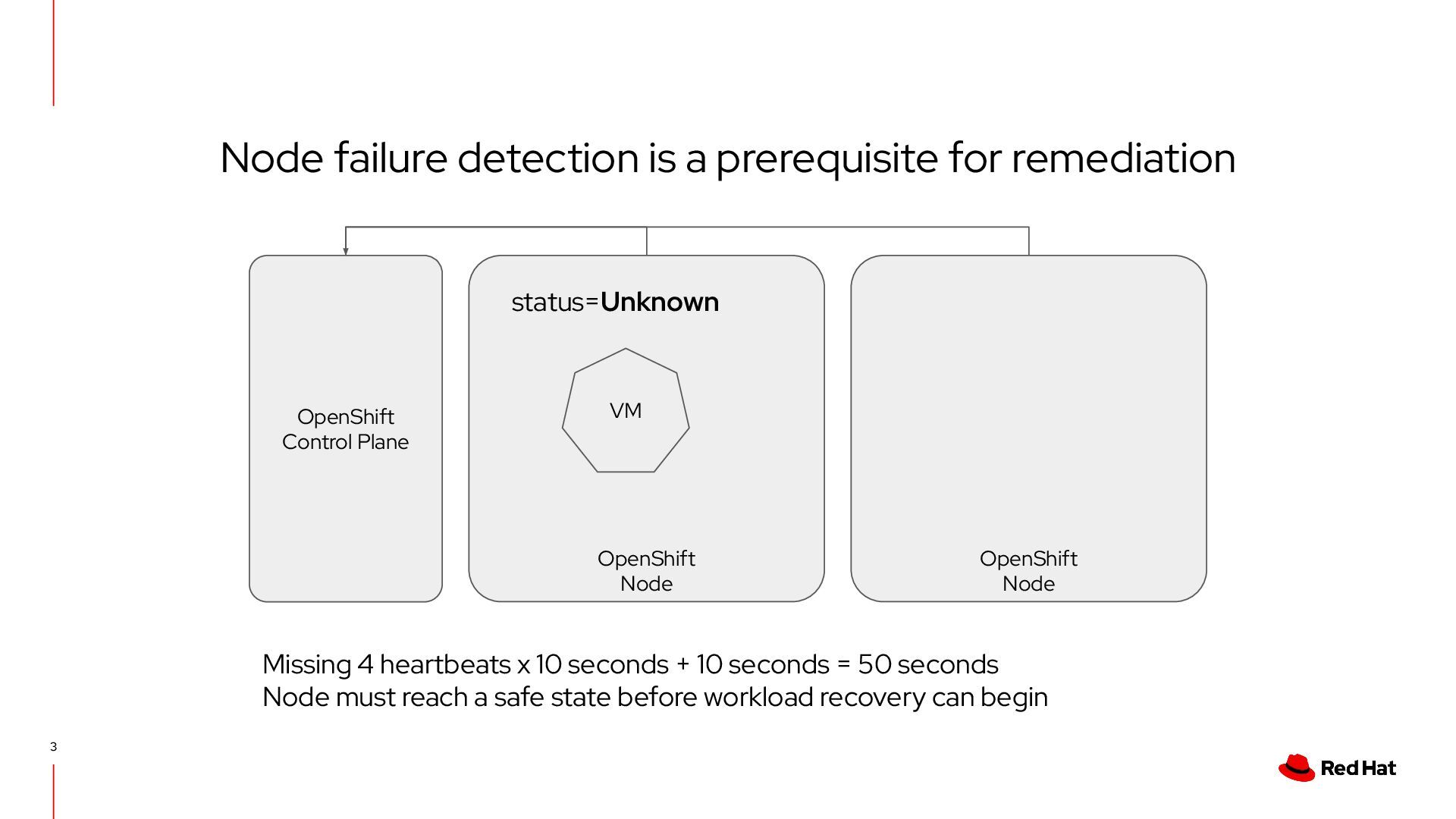
heartbeats x 10 seconds + 10 seconds = 50 seconds Node must reach a safe state before workload recovery can begin status=Unknown Node failure detection is a prerequisite for remediation VM
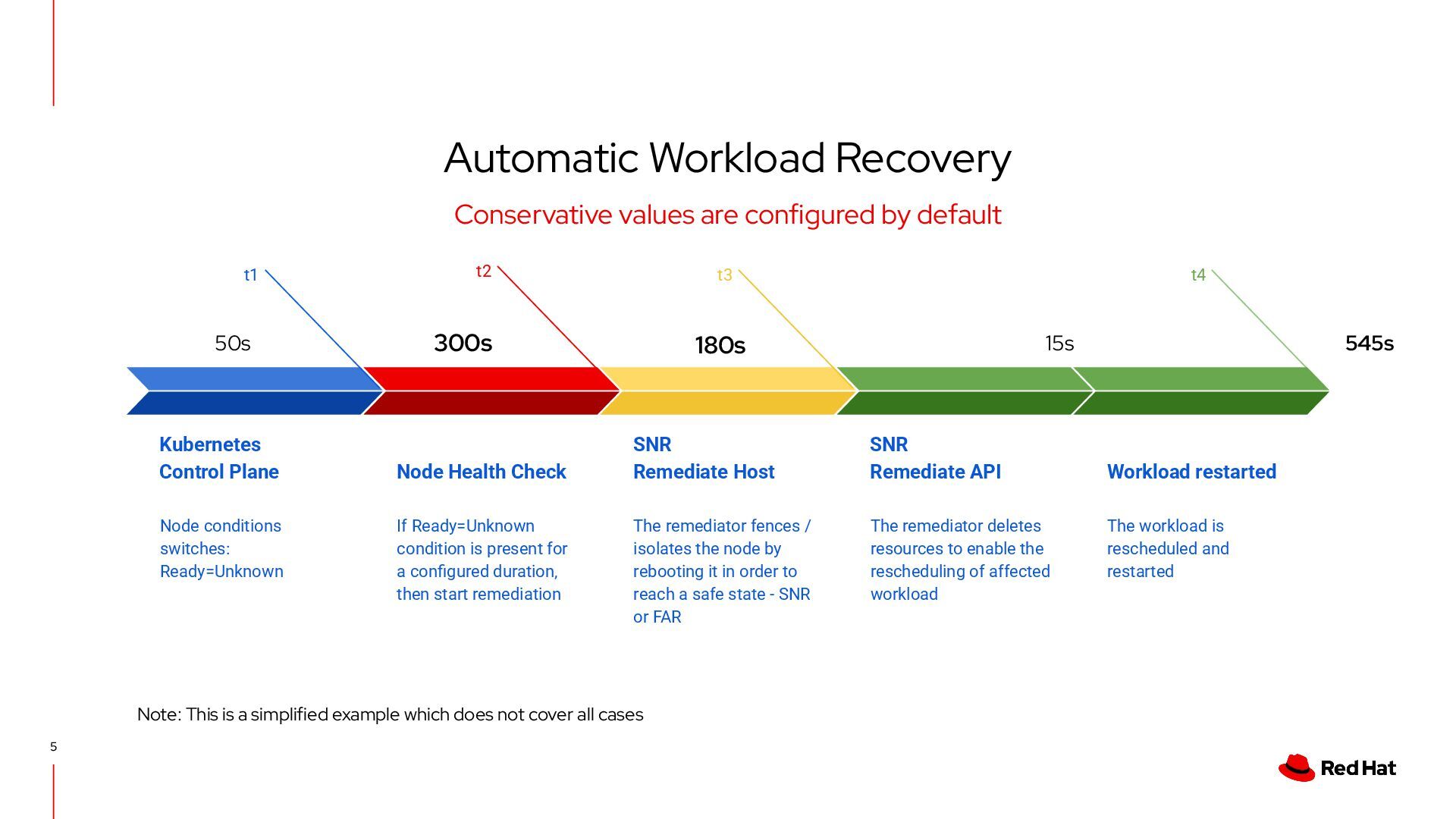
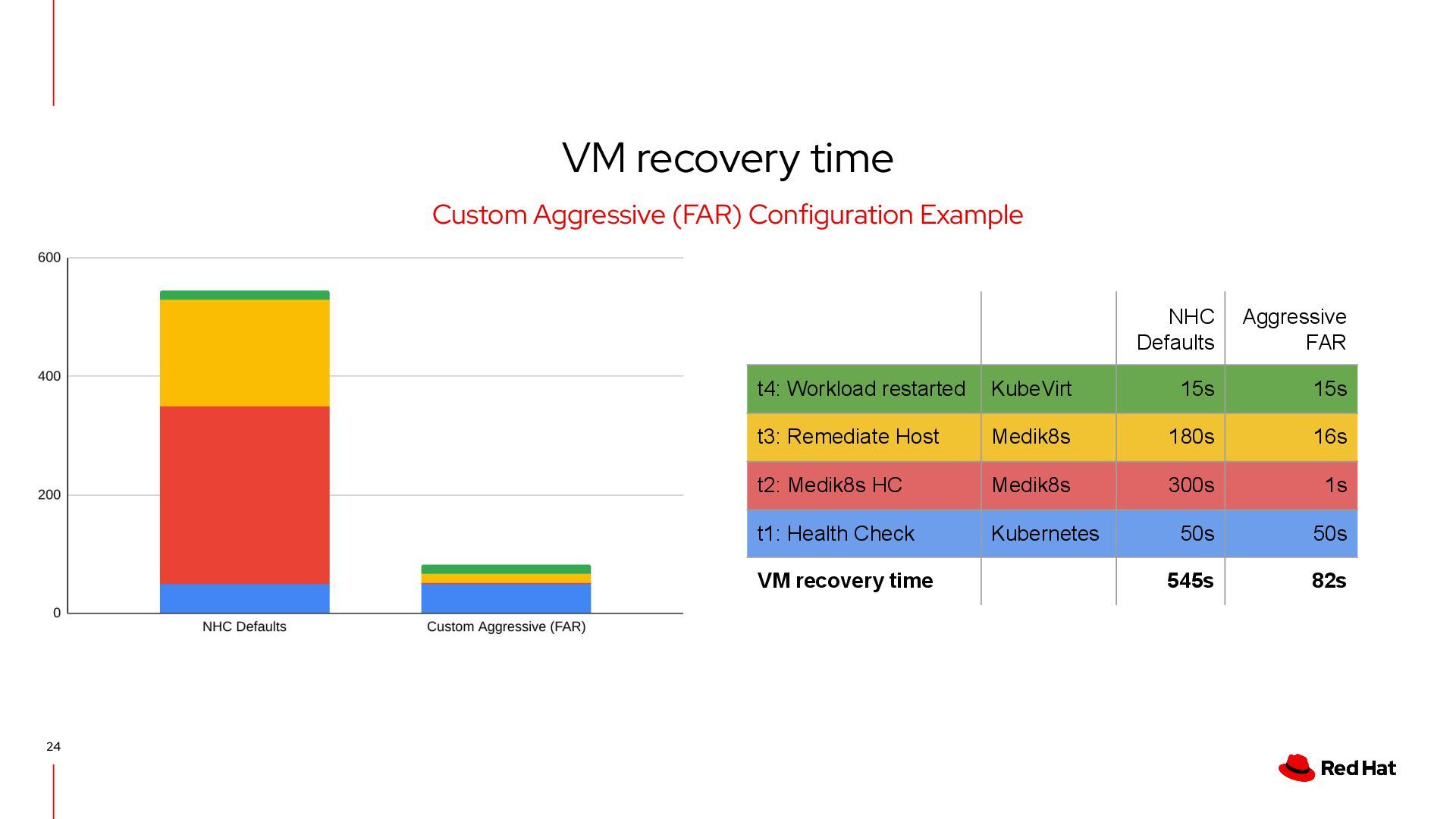
Kubernetes Control Plane Node conditions switches: Ready=Unknown Node Health Check If Ready=Unknown condition is present for a configured duration, then start remediation t1 SNR Remediate Host The remediator fences / isolates the node by rebooting it in order to reach a safe state - SNR or FAR t2 SNR Remediate API The remediator deletes resources to enable the rescheduling of affected workload t3 Workload restarted The workload is rescheduled and restarted t4 Note: This is a simplified example which does not cover all cases 50s 300s 180s 15s 545s
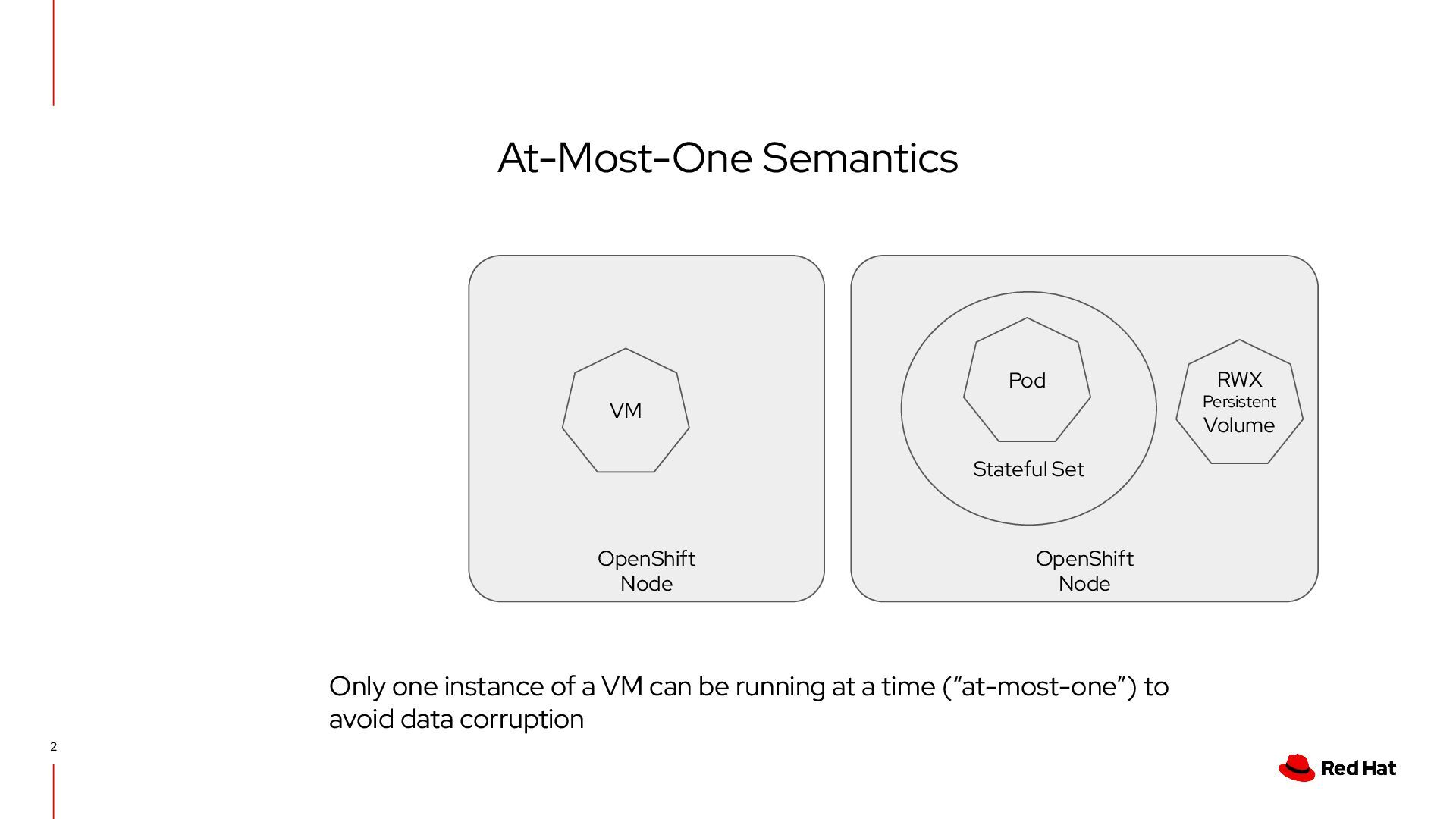
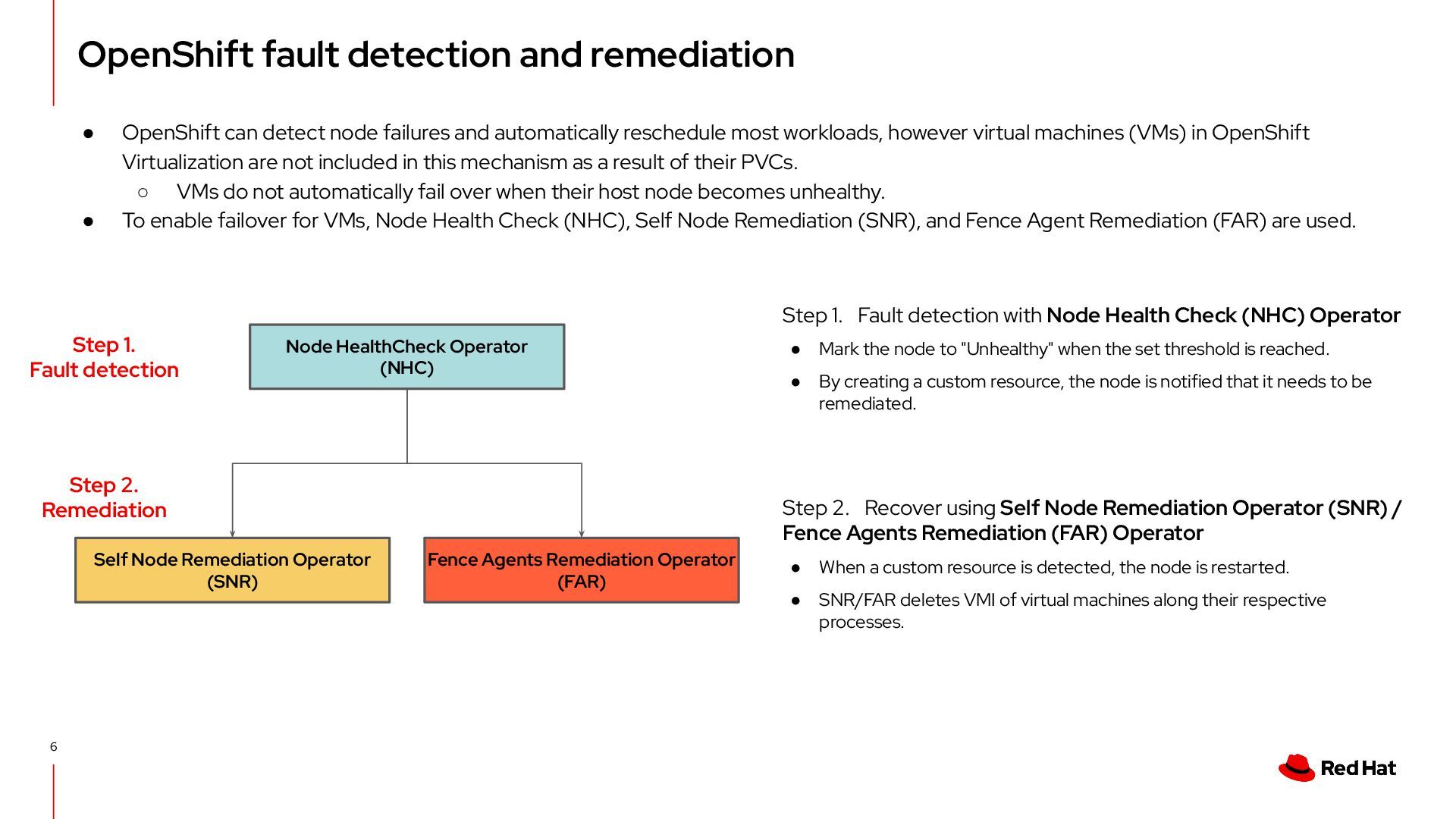
node failures and automatically reschedule most workloads, however virtual machines (VMs) in OpenShift Virtualization are not included in this mechanism as a result of their PVCs. ◦ VMs do not automatically fail over when their host node becomes unhealthy. • To enable failover for VMs, Node Health Check (NHC), Self Node Remediation (SNR), and Fence Agent Remediation (FAR) are used. Node HealthCheck Operator (NHC) Self Node Remediation Operator (SNR) Fence Agents Remediation Operator (FAR) Step 1. Fault detection with Node Health Check (NHC) Operator • Mark the node to "Unhealthy" when the set threshold is reached. • By creating a custom resource, the node is notified that it needs to be remediated. Step 2. Recover using Self Node Remediation Operator (SNR) / Fence Agents Remediation (FAR) Operator • When a custom resource is detected, the node is restarted. • SNR/FAR deletes VMI of virtual machines along their respective processes. Step 1. Fault detection Step 2. Remediation
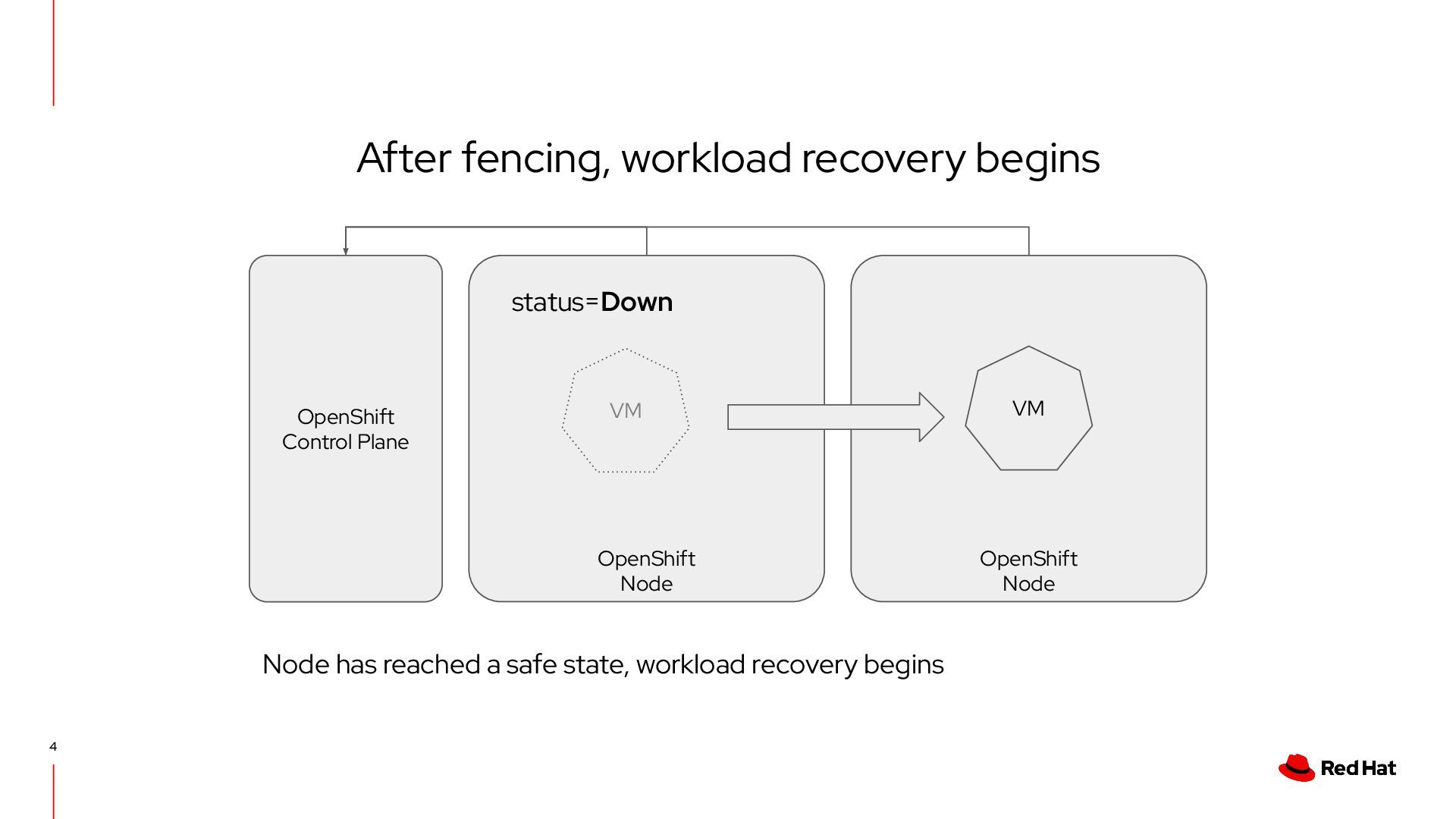
Cluster decides to fence • Confirmed when the node has reached the safe state (down) • fence-agent is power-cycling via BMC API ◦ Intelligent Platform Management Interface (IPMI) ◦ RedFish Remediation Implementations FAR is faster, SNR is (potentially) safer for workloads Self Node Remediation (SNR) • Software based fencing • Node decides to fence • Unconfirmed when node has reached the safe state (down) • Runs as a Daemonset - one pod per node • Can utilize hardware watchdog
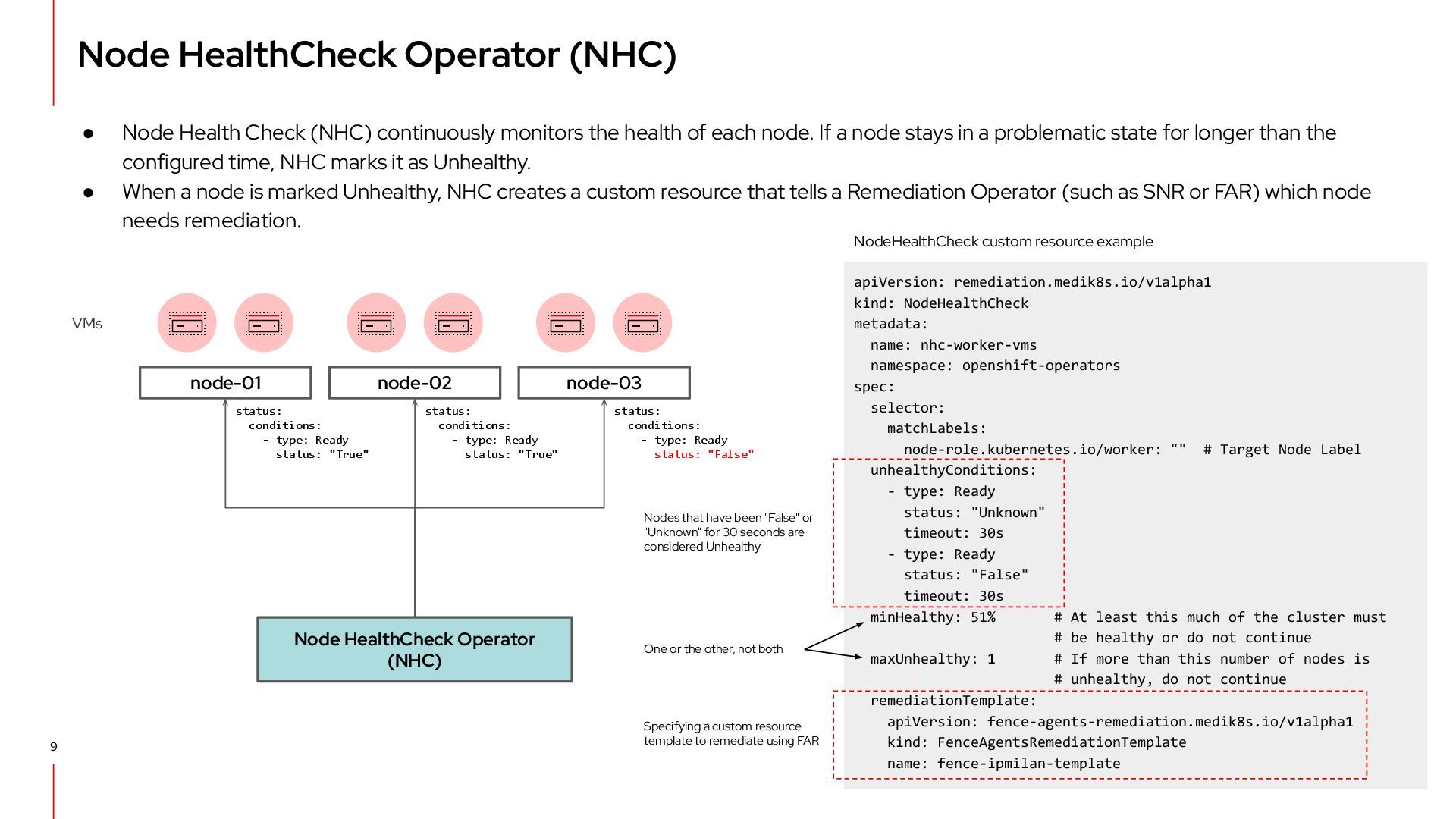
continuously monitors the health of each node. If a node stays in a problematic state for longer than the configured time, NHC marks it as Unhealthy. • When a node is marked Unhealthy, NHC creates a custom resource that tells a Remediation Operator (such as SNR or FAR) which node needs remediation. Node HealthCheck Operator (NHC) node-01 node-02 node-03 VMs status: conditions: - type: Ready status: "False" Nodes that have been "False" or "Unknown" for 30 seconds are considered Unhealthy status: conditions: - type: Ready status: "True" status: conditions: - type: Ready status: "True" Specifying a custom resource template to remediate using FAR apiVersion: remediation.medik8s.io/v1alpha1 kind: NodeHealthCheck metadata: name: nhc-worker-vms namespace: openshift-operators spec: selector: matchLabels: node-role.kubernetes.io/worker: "" # Target Node Label unhealthyConditions: - type: Ready status: "Unknown" timeout: 30s - type: Ready status: "False" timeout: 30s minHealthy: 51% # At least this much of the cluster must # be healthy or do not continue maxUnhealthy: 1 # If more than this number of nodes is # unhealthy, do not continue remediationTemplate: apiVersion: fence-agents-remediation.medik8s.io/v1alpha1 kind: FenceAgentsRemediationTemplate name: fence-ipmilan-template NodeHealthCheck custom resource example One or the other, not both
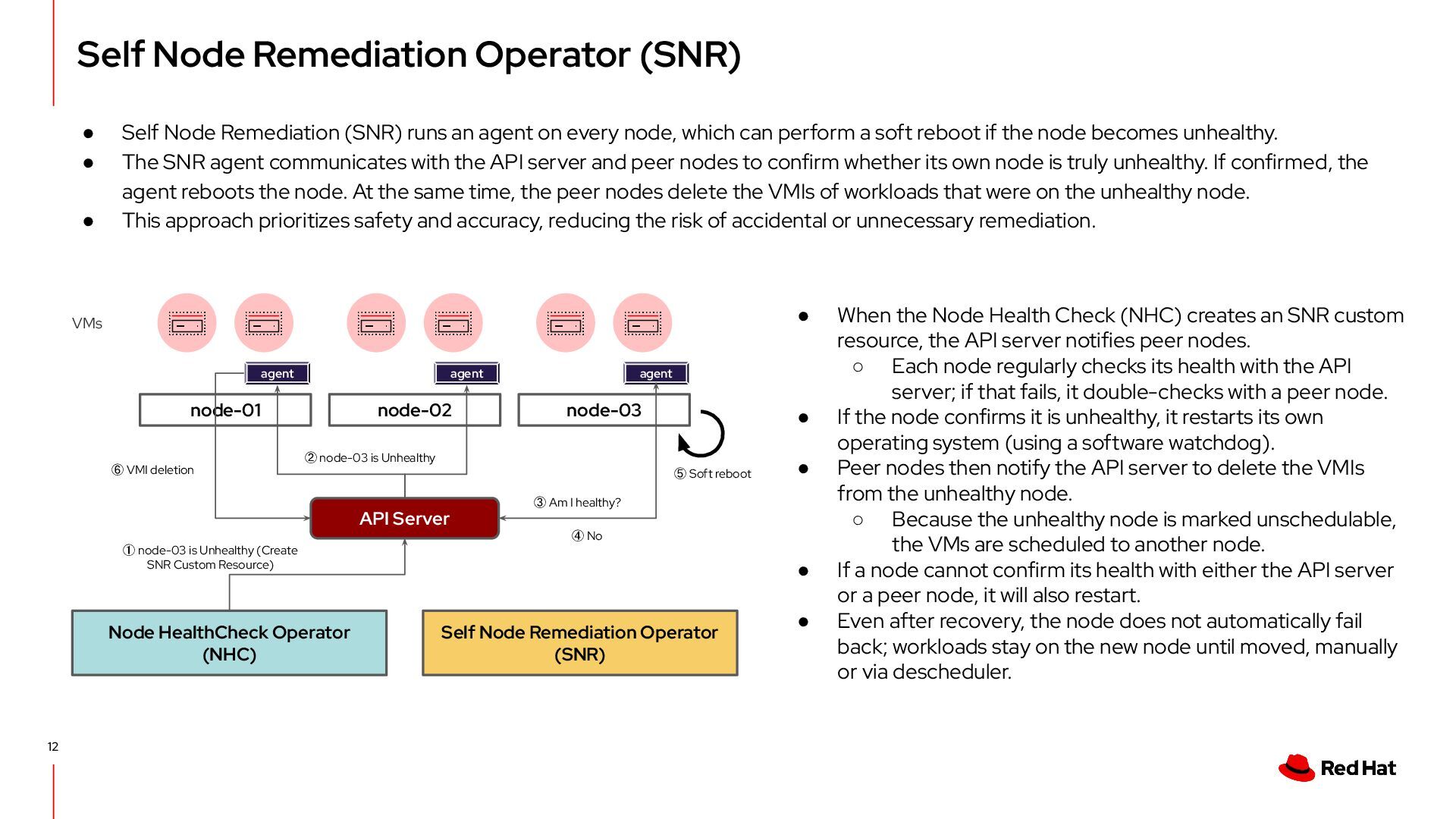
(SNR) runs an agent on every node, which can perform a soft reboot if the node becomes unhealthy. • The SNR agent communicates with the API server and peer nodes to confirm whether its own node is truly unhealthy. If confirmed, the agent reboots the node. At the same time, the peer nodes delete the VMIs of workloads that were on the unhealthy node. • This approach prioritizes safety and accuracy, reducing the risk of accidental or unnecessary remediation. Self Node Remediation Operator (SNR) • When the Node Health Check (NHC) creates an SNR custom resource, the API server notifies peer nodes. ◦ Each node regularly checks its health with the API server; if that fails, it double-checks with a peer node. • If the node confirms it is unhealthy, it restarts its own operating system (using a software watchdog). • Peer nodes then notify the API server to delete the VMIs from the unhealthy node. ◦ Because the unhealthy node is marked unschedulable, the VMs are scheduled to another node. • If a node cannot confirm its health with either the API server or a peer node, it will also restart. • Even after recovery, the node does not automatically fail back; workloads stay on the new node until moved, manually or via descheduler. node-01 node-02 node-03 VMs agent agent agent API Server Node HealthCheck Operator (NHC) ① node-03 is Unhealthy (Create SNR Custom Resource) ② node-03 is Unhealthy ③ Am I healthy? ⑤ Soft reboot ④ No ⑥ VMI deletion
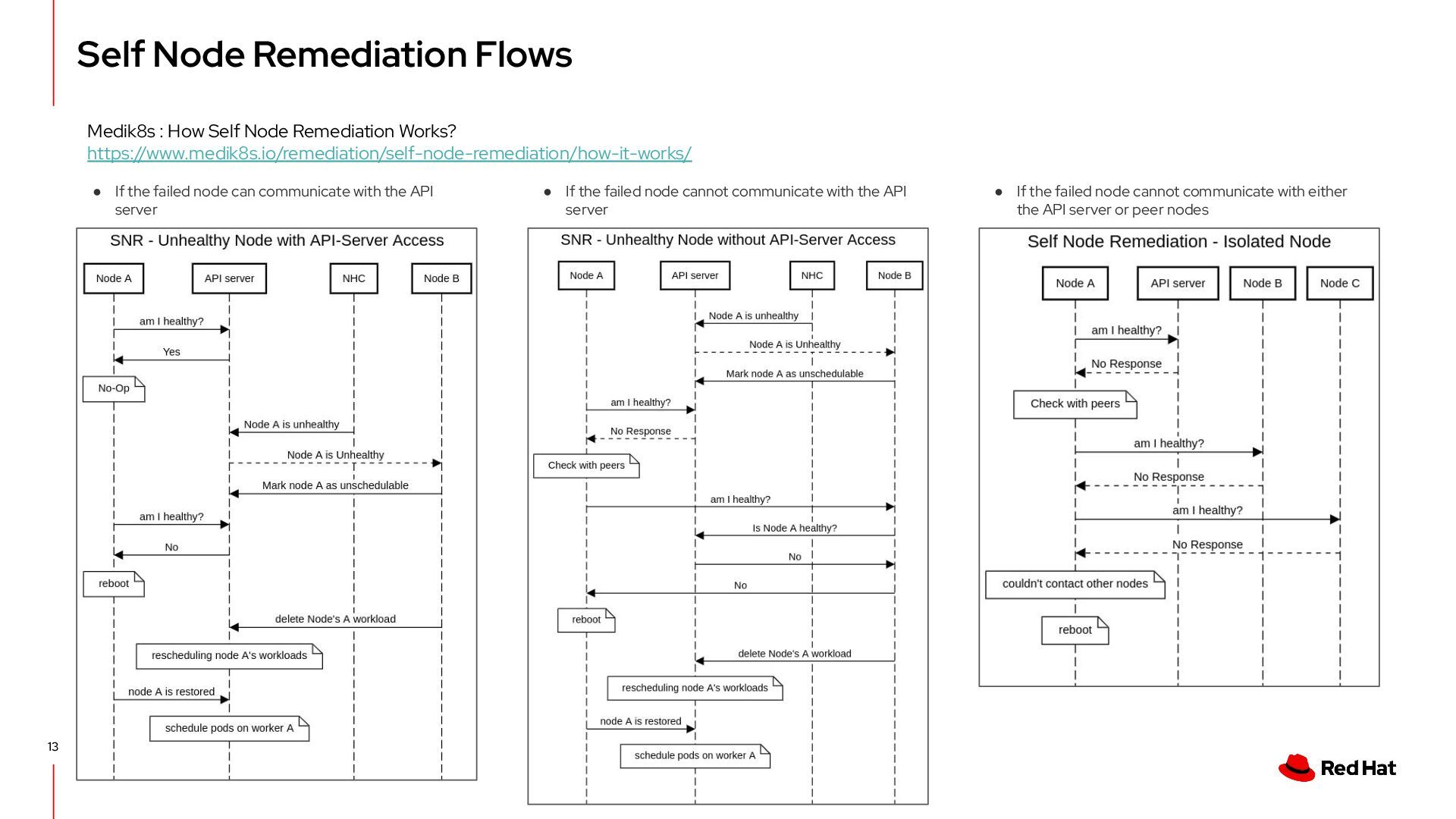
can communicate with the API server • If the failed node cannot communicate with the API server • If the failed node cannot communicate with either the API server or peer nodes Medik8s : How Self Node Remediation Works? https://www.medik8s.io/remediation/self-node-remediation/how-it-works/
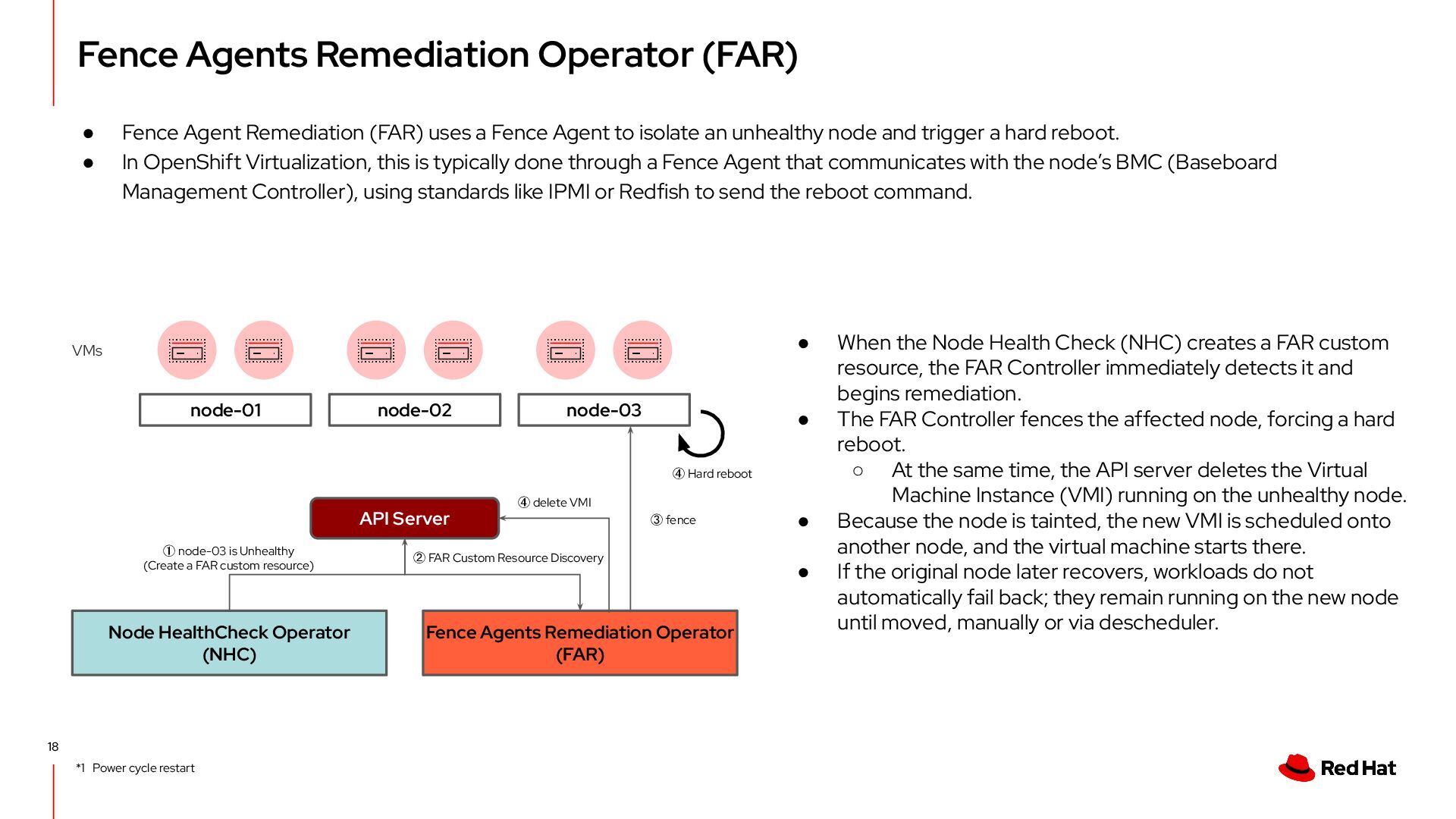
(FAR) uses a Fence Agent to isolate an unhealthy node and trigger a hard reboot. • In OpenShift Virtualization, this is typically done through a Fence Agent that communicates with the node’s BMC (Baseboard Management Controller), using standards like IPMI or Redfish to send the reboot command. Fence Agents Remediation Operator (FAR) • When the Node Health Check (NHC) creates a FAR custom resource, the FAR Controller immediately detects it and begins remediation. • The FAR Controller fences the affected node, forcing a hard reboot. ◦ At the same time, the API server deletes the Virtual Machine Instance (VMI) running on the unhealthy node. • Because the node is tainted, the new VMI is scheduled onto another node, and the virtual machine starts there. • If the original node later recovers, workloads do not automatically fail back; they remain running on the new node until moved, manually or via descheduler. node-01 node-02 node-03 VMs API Server *1 Power cycle restart Node HealthCheck Operator (NHC) ① node-03 is Unhealthy (Create a FAR custom resource) ④ Hard reboot ② FAR Custom Resource Discovery ③ fence ④ delete VMI
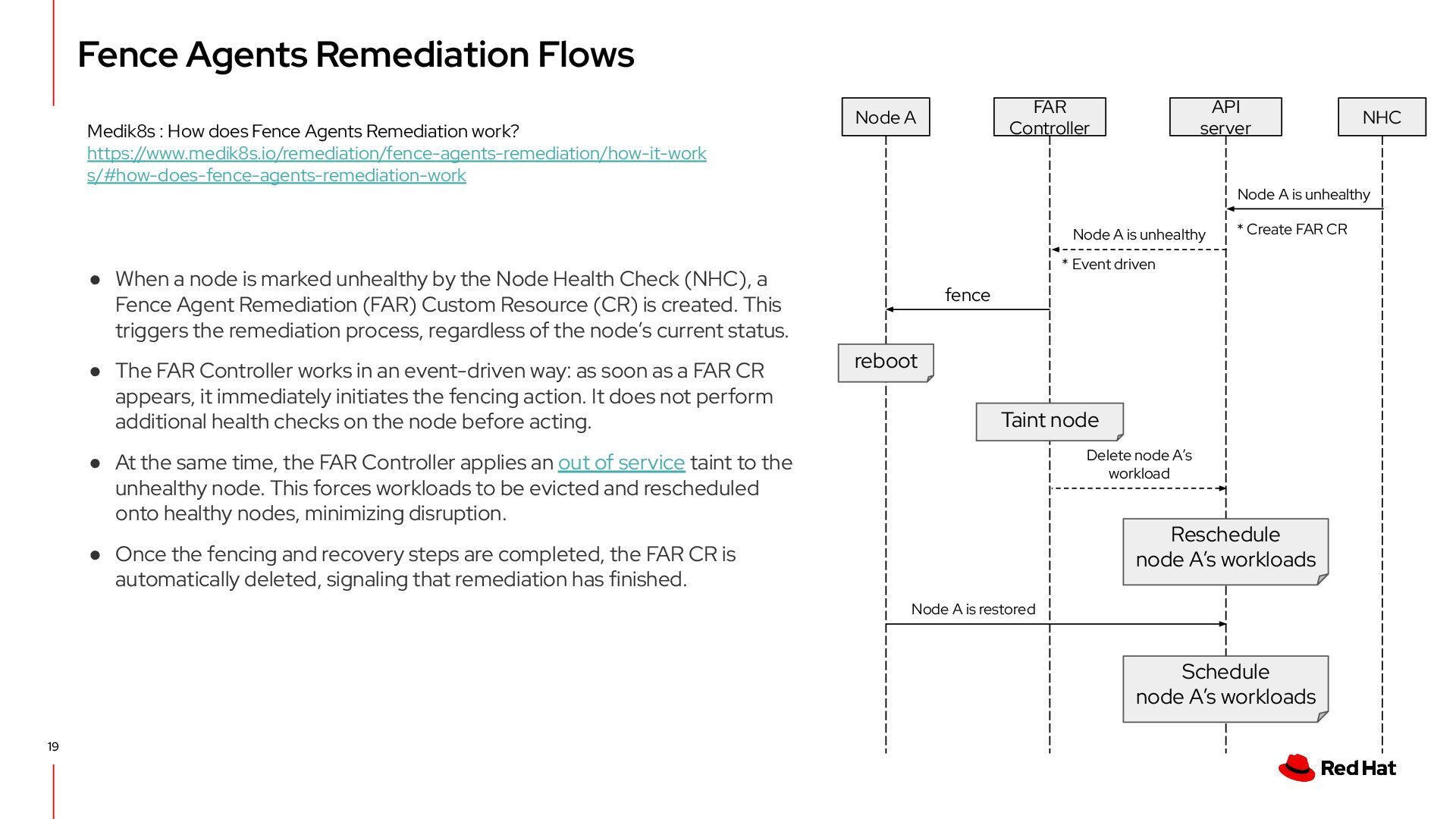
Agents Remediation work? https://www.medik8s.io/remediation/fence-agents-remediation/how-it-work s/#how-does-fence-agents-remediation-work Node A FAR Controller API server NHC reboot fence Node A is unhealthy Node A is unhealthy * Event driven Taint node Reschedule node A’s workloads Schedule node A’s workloads Delete node A’s workload Node A is restored • When a node is marked unhealthy by the Node Health Check (NHC), a Fence Agent Remediation (FAR) Custom Resource (CR) is created. This triggers the remediation process, regardless of the node’s current status. • The FAR Controller works in an event-driven way: as soon as a FAR CR appears, it immediately initiates the fencing action. It does not perform additional health checks on the node before acting. • At the same time, the FAR Controller applies an out of service taint to the unhealthy node. This forces workloads to be evicted and rescheduled onto healthy nodes, minimizing disruption. • Once the fencing and recovery steps are completed, the FAR CR is automatically deleted, signaling that remediation has finished. * Create FAR CR
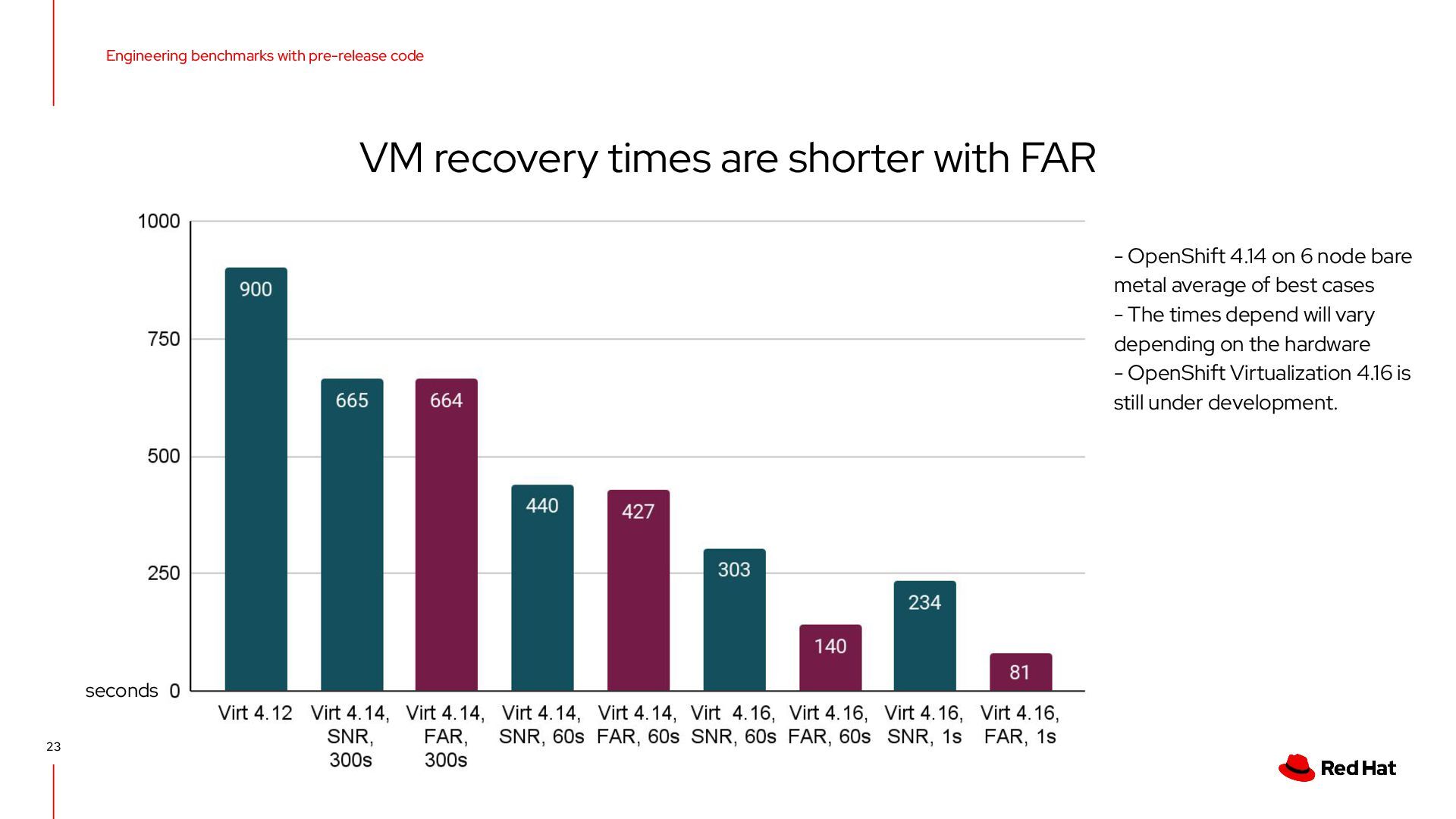
shorter with FAR seconds - OpenShift 4.14 on 6 node bare metal average of best cases - The times depend will vary depending on the hardware - OpenShift Virtualization 4.16 is still under development. seconds
from the API + Robustness + Speed: Reboot is acked by the API - Access to the BMC via network is required - Increases configuration complexity - The BMC being unresponsive can delay recovery - The FAR agent pod being affected by node failure can delay recovery Self Node Remediation vs Fence Agents Remediation Self Node Remediation (SNR) + does not require any management interface, fallback if FAR is not remediating - No quick feedback about the reboot request - No Ack, assume that the node is rebooting with buffer time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}