PURDUE UNIVERSITY APPLICATIONS IN HIGH-DIMENSIONAL UNCERTAINTY PROPAGATION 1 ROHIT TRIPATHY MAJOR PROFESSOR: PROF. ILIAS BILIONIS COMMITTEE MEMBERS: PROF. ALINA ALEXEENKO PROF. MARISOL KOSLOWSKI IN COLLABORATION WITH: PROF. MARCIAL GONZALEZ.
fact that experiments are usually surrogates used to study actual phenomena. • Ex: Wind tunnel testing for flight simulations. MODEL FORM UNCERTAINTIES • Uncertainties arising out of inaccurate or approximate description of the physical problem. • Ex: LJ Potentials in MD simulations. PARAMETRIC UNCERTAINTIES • Uncertainties in model parameters, IC / BCs , forcing functions • Ex: Uncertainties in porosity coefficients in porous media problems, uncertainties in thermal conductivity in HT problems etc. NUMERICAL ERRORS • Uncertainties in model parameters, IC / BCs , forcing functions • Ex: Grid sizes, round-off errors etc.
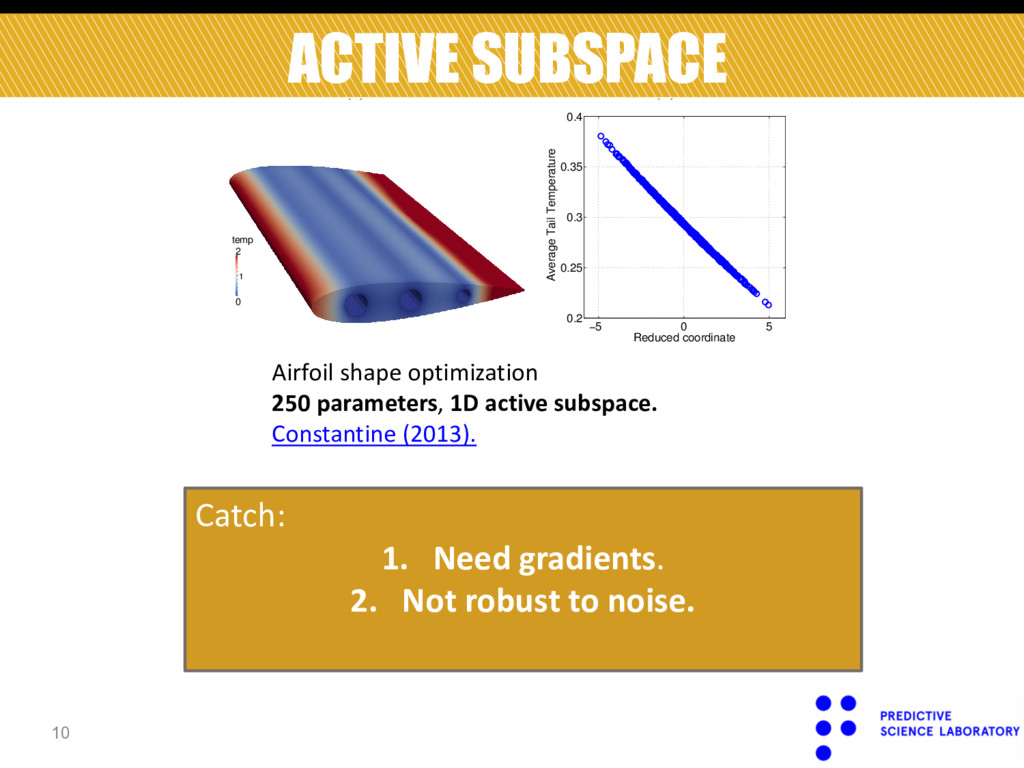
5 0.2 0.25 0.3 0.35 0.4 Reduced coordinate Average Tail Temperature Figure 2: We examined a model for heat transfer in a turbine blade given a parameterized model for the heat flux boundary condition representing unknown transition to turbulence. There are 250 parameters characterizing a Karhunen-Loeve model of the heat flux, and the quantity of interest is the average tem- perature over the trailing edge of the blade. The leftmost figure shows the domain and a representative temperature distribution. The rightmost figure plots 750 samples of the quantity of interest against the projected coordinate. The strong appearance of the linear relationship verifies the quality of the subspace approximation. (a) (b) 2.55 2.6 2.65 e [bar] Airfoil shape optimization 250 parameters, 1D active subspace. Constantine (2013). Catch: 1. Need gradients. 2. Not robust to noise. 10
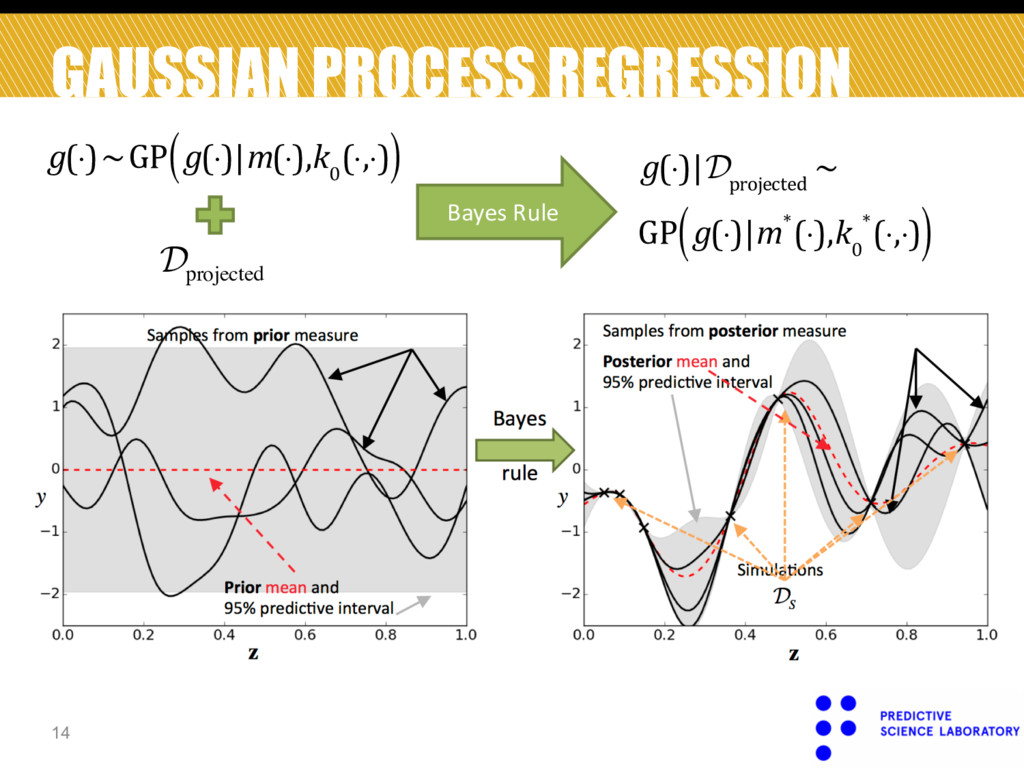
) D projected Bayes Rule ! ! g(⋅)|D projected ~ GP g(⋅)|m*(⋅),k 0 *(⋅,⋅) ( ) Figure 6 - Prior (a) and posterior (b) on the space of 1D functions using Gaussian processes. The red dashed-line indicates the mean of the prior (a) and posterior (b) probability measures. The grey shaded area indicates 95% predictive intervals within which the true law is believed to be. The solid black lines are functional samples from th prior (a) and posterior (b) probability measures. The ‘x’ symbols in (b) indicate simulations, !!, on which we condition 14
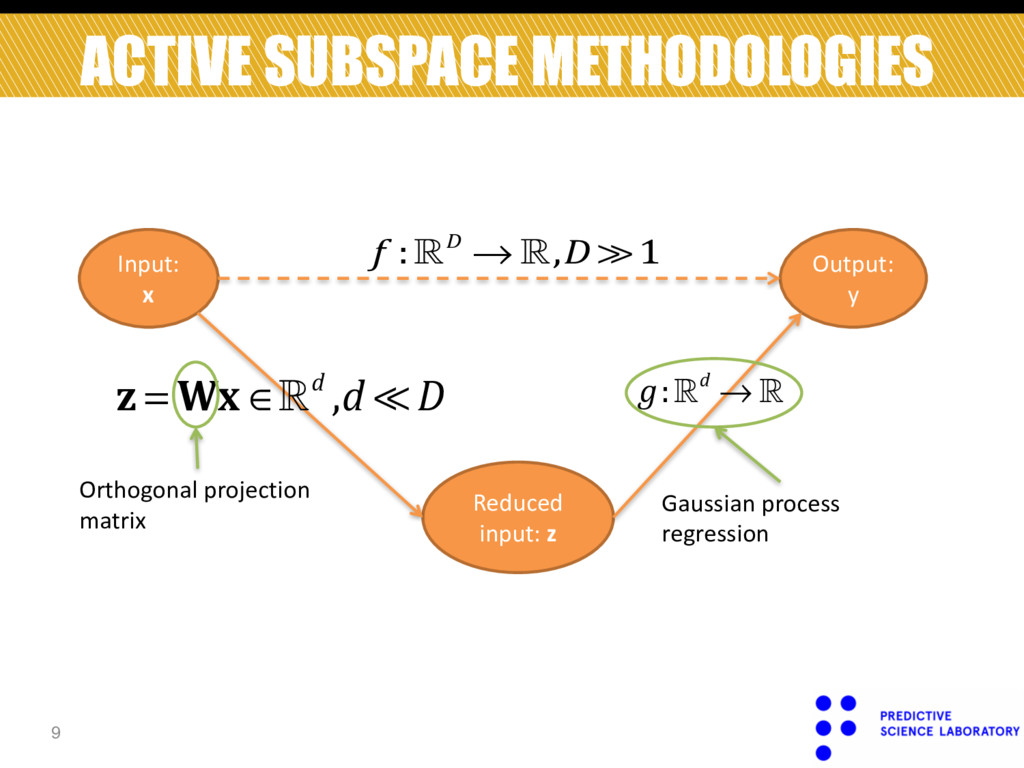
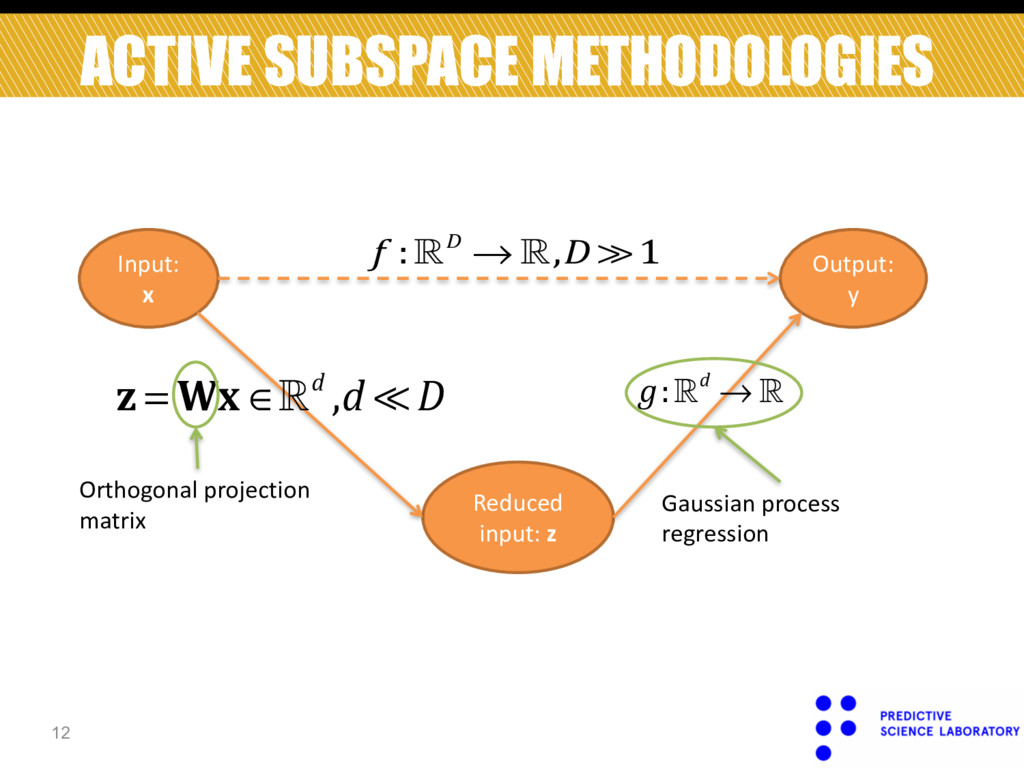
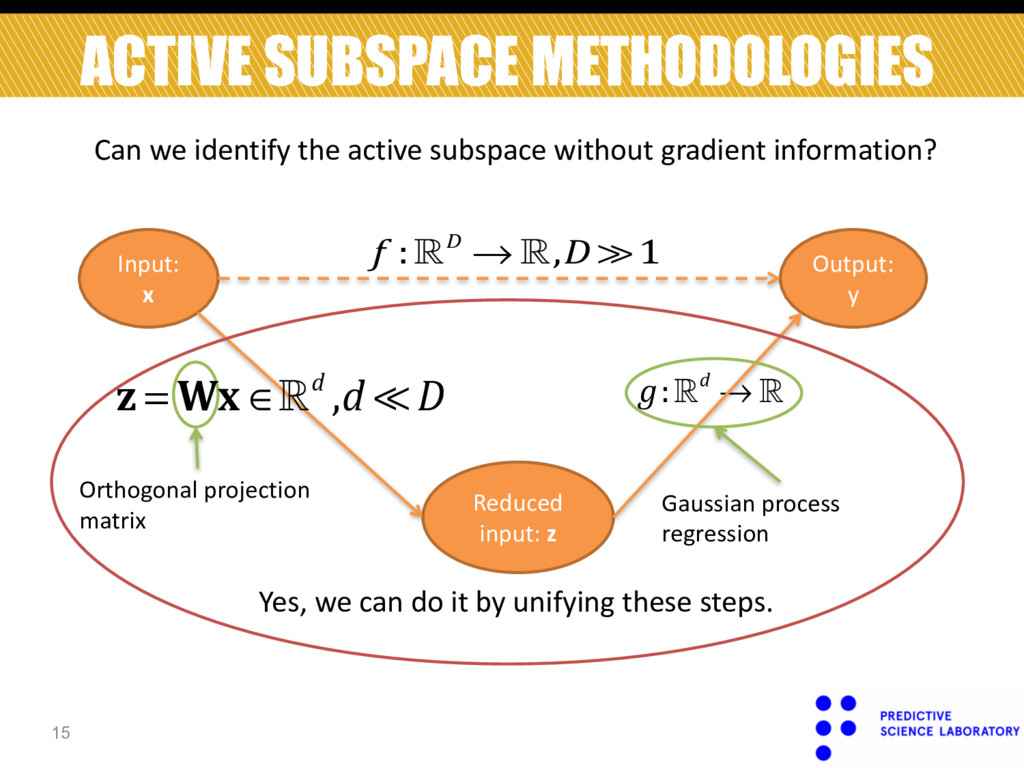
Output: y ! !f :!D → !,D ≫1 Reduced input: z Orthogonal projection matrix Gaussian process regression ! ! !z = Wx ∈!d ,d ≪ D Can we identify the active subspace without gradient information? Yes, we can do it by unifying these steps.
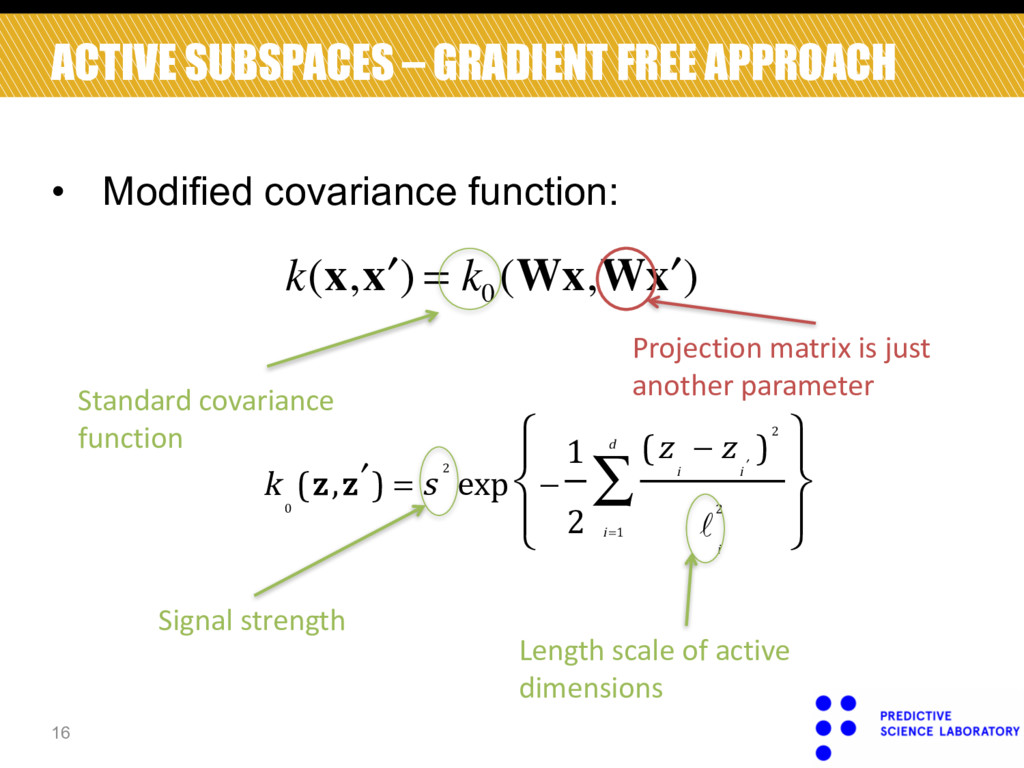
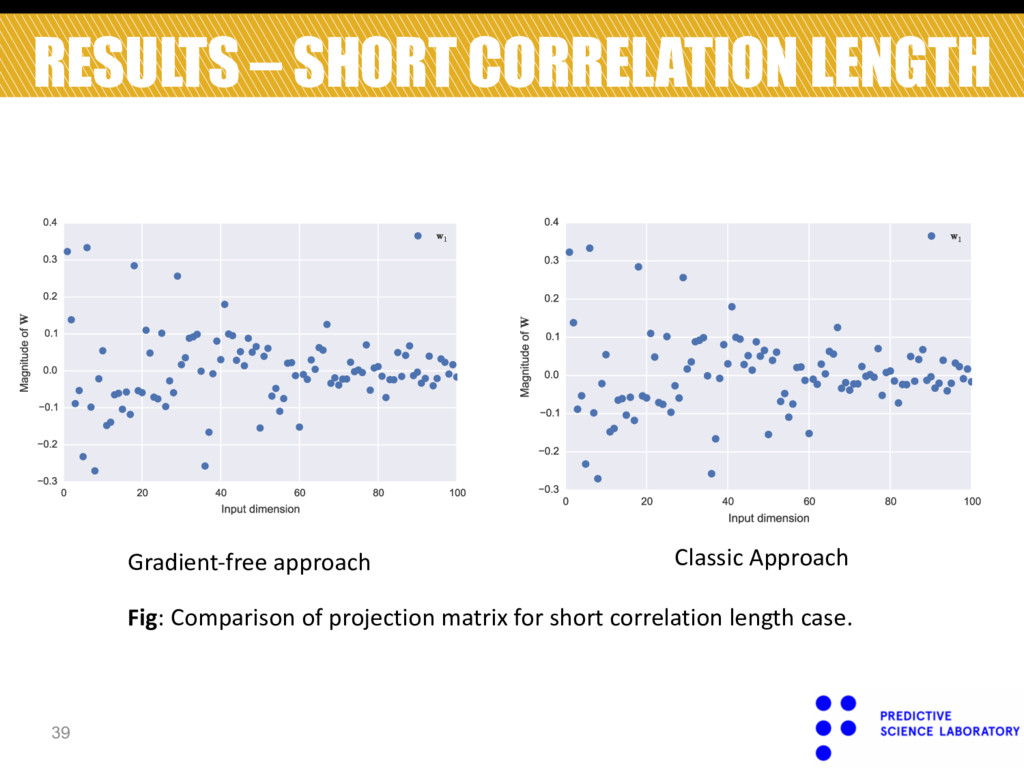
) ACTIVE SUBSPACES – GRADIENT FREE APPROACH • Modified covariance function: Standard covariance function ! ! ! k 0 $z, ′ z ' = s 2 exp − 1 2 $z i − z ′ i '2 ℓ i 2 i =1 d ∑ ⎧ ⎨ ⎩ ⎫ ⎬ ⎭ Signal strength Length scale of active dimensions 16 Projection matrix is just another parameter
! θ = "s,ℓ 1 ,…,ℓ d ' Hyper-parameters of covariance Needs to have orthogonal columns (optimization over Stiefel manifold) 17 logp(y|X,θ,s n 2 ,W) [1] [1] Eq. 31 of paper.
a hard problem because: • Non-convexity (multiple local minima and maxima). • Difficulty in preserving orthogonality constraints. V d (!D ):= {W:W ∈!D×d ;WTW = I d }
τ 2 A(W))−1(I D + τ 2 A(W))W τ where, is the gradient-ascent step-size, A(W):= ∇ W F(W)W − W(∇ W F(W))T [1] Wen, Zaiwen, and Wotao Yin. "A feasible method for optimization with orthogonality constraints." Mathematical Programming 142.1-2 (2013) [2] Williams, Christopher KI, and Carl Edward Rasmussen. "Gaussian processes for machine learning." the MIT Press(2006)
: Jones, Donald R., Matthias Schonlau, and William J. Welch. "Efficient global optimization of expensive black-box functions." Journal of Global optimization 13.4 (1998)
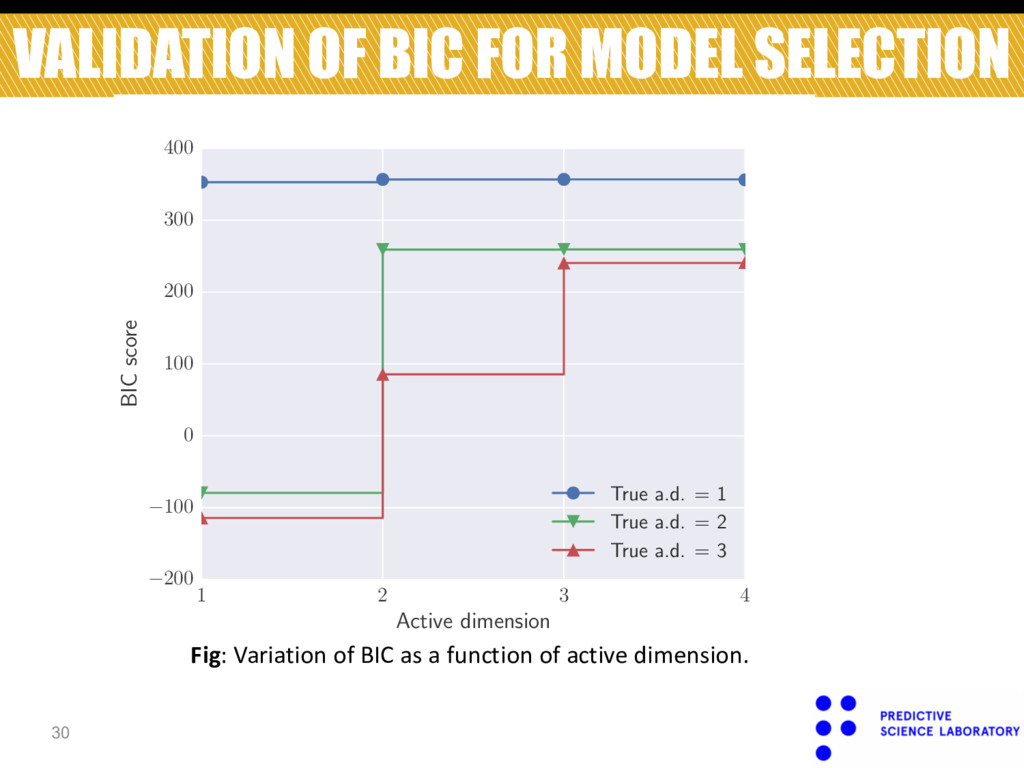
4 Active dimension 200 100 0 100 200 300 400 BIC score True a.d. = 1 True a.d. = 2 True a.d. = 3 Fig: Variation of BIC as a function of active dimension.
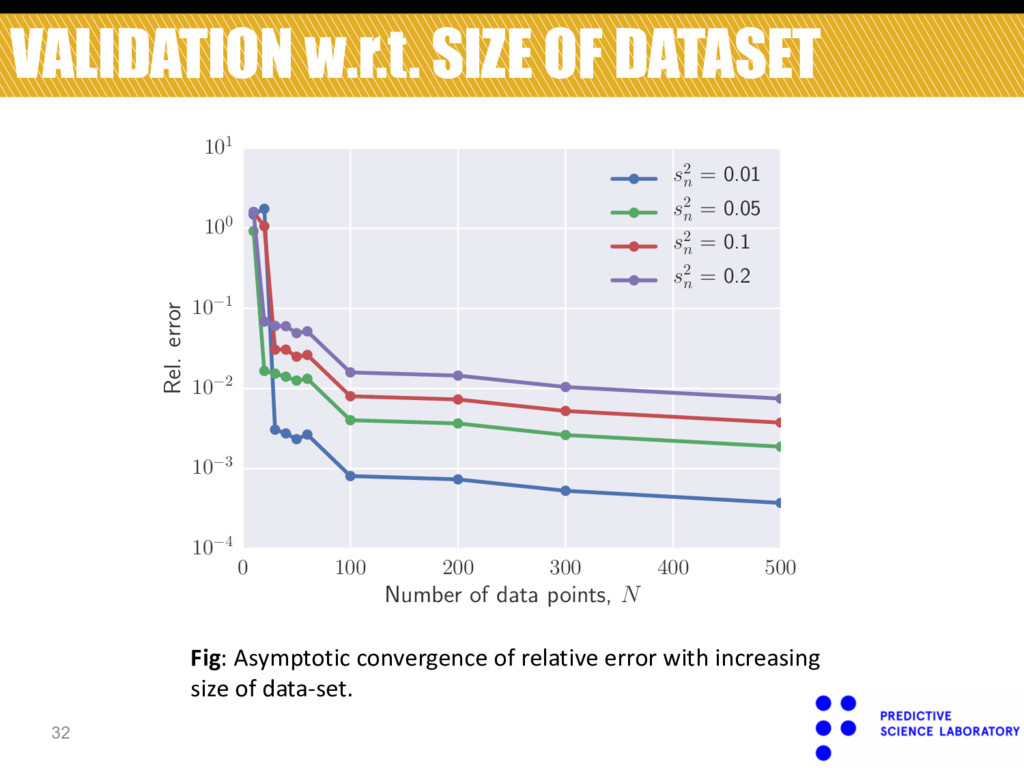
400 500 Number of data points, N 10 4 10 3 10 2 10 1 100 101 Rel. error s2 n = 0.01 s2 n = 0.05 s2 n = 0.1 s2 n = 0.2 Fig: Asymptotic convergence of relative error with increasing size of data-set.
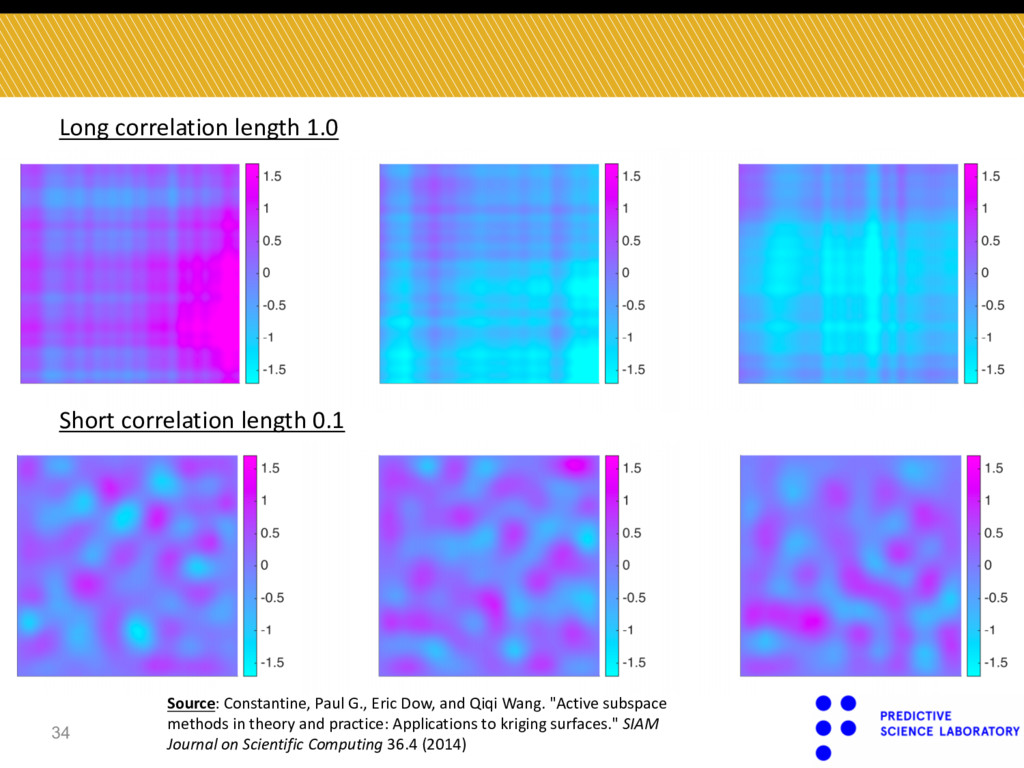
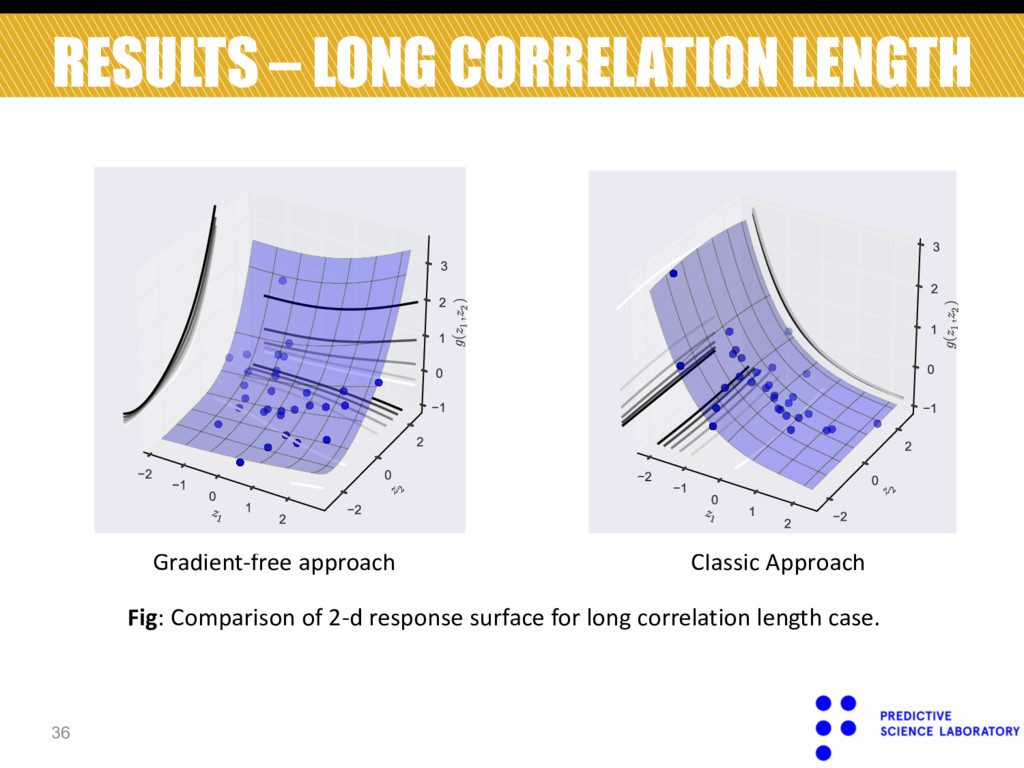
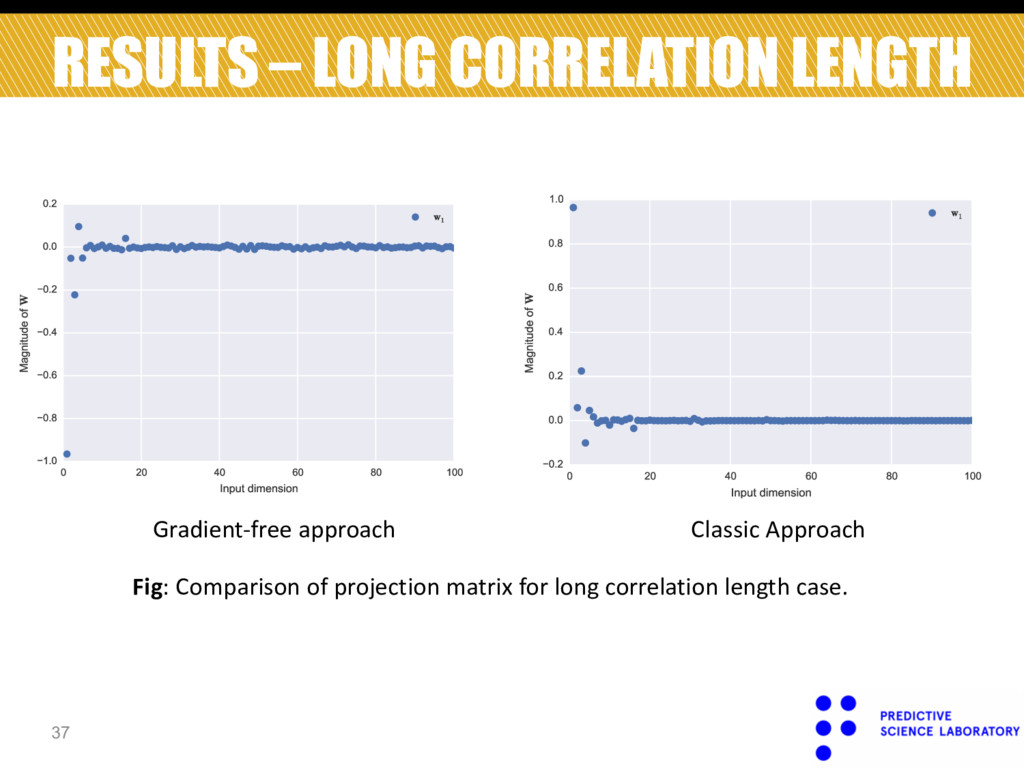
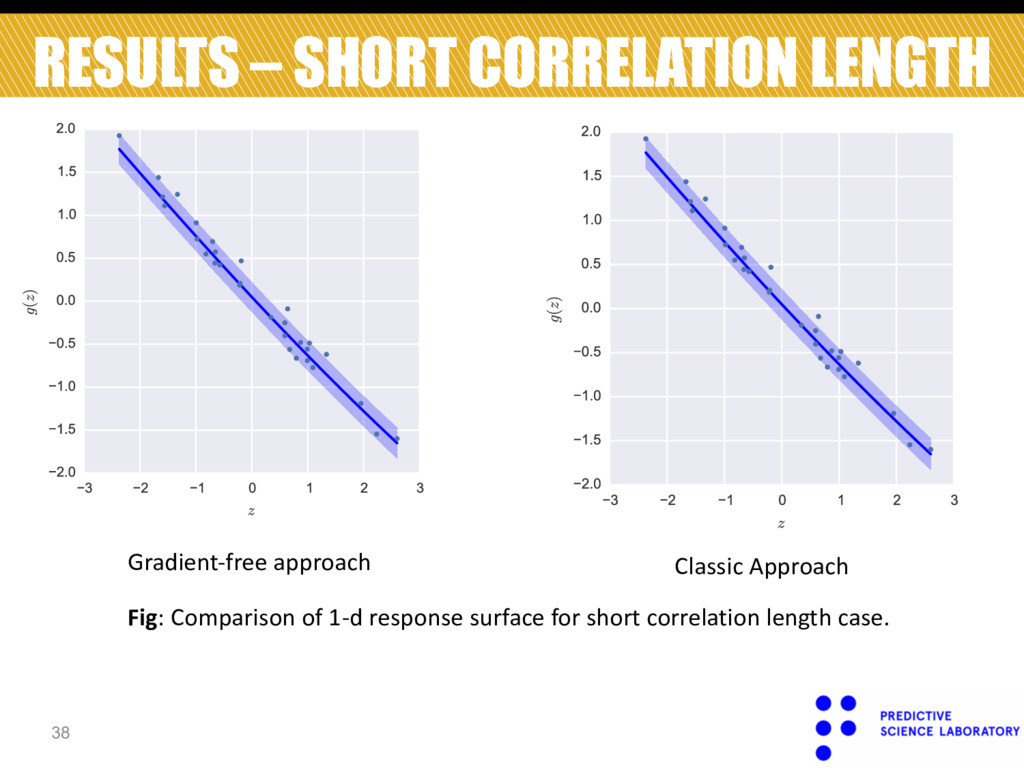
Constantine, Paul G., Eric Dow, and Qiqi Wang. "Active subspace methods in theory and practice: Applications to kriging surfaces." SIAM Journal on Scientific Computing 36.4 (2014)
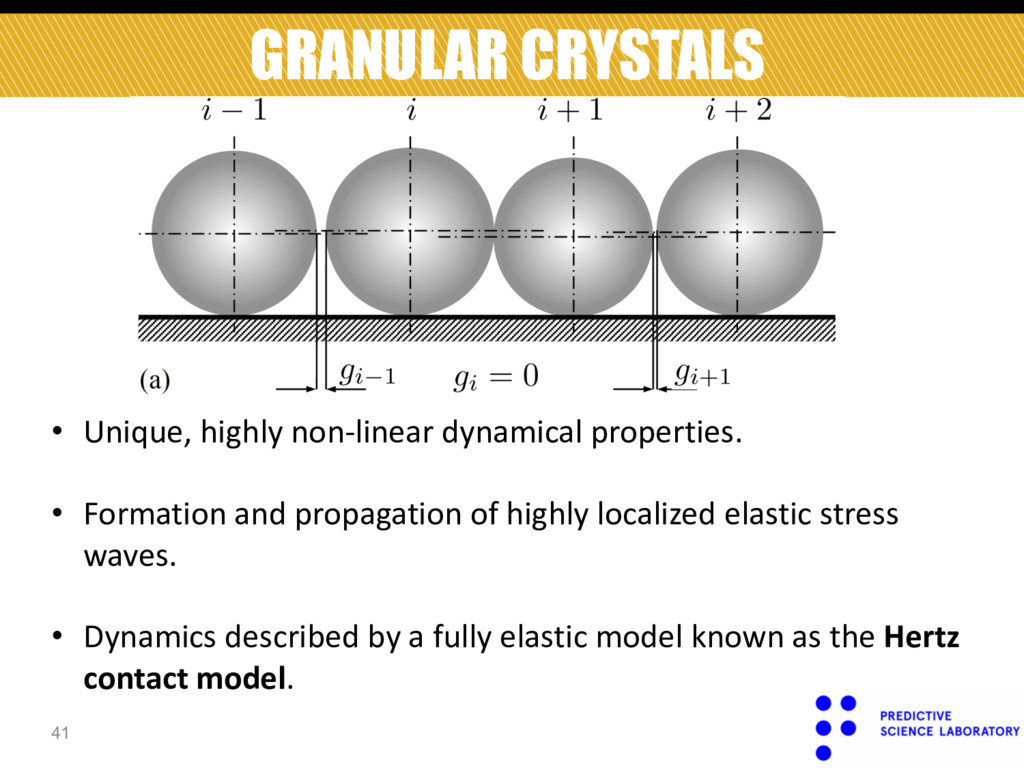
Each bead has radius Ri and Young’s modulus Ei . • Striker velocity : vs . • Parameter vector: q = q 1 , q 2 ,…,q n p ( ) x = R 1 ,R 2 ,…,R n p ,E 1 ,E 2 ,…,E n p ,v s ( )
= F i (q;x) Initial conditions: q i (0)=(0,0,0), ! q i (0)=(0,0,0), ∀i = {1,2,3,…,n p −1}, ! q n p (0)=(−v s ,0,0). • We want to characterize the properties of the force wave propagating through the granular crystal. ˆ F i (t;x)≡ F i (q(t;x);x)
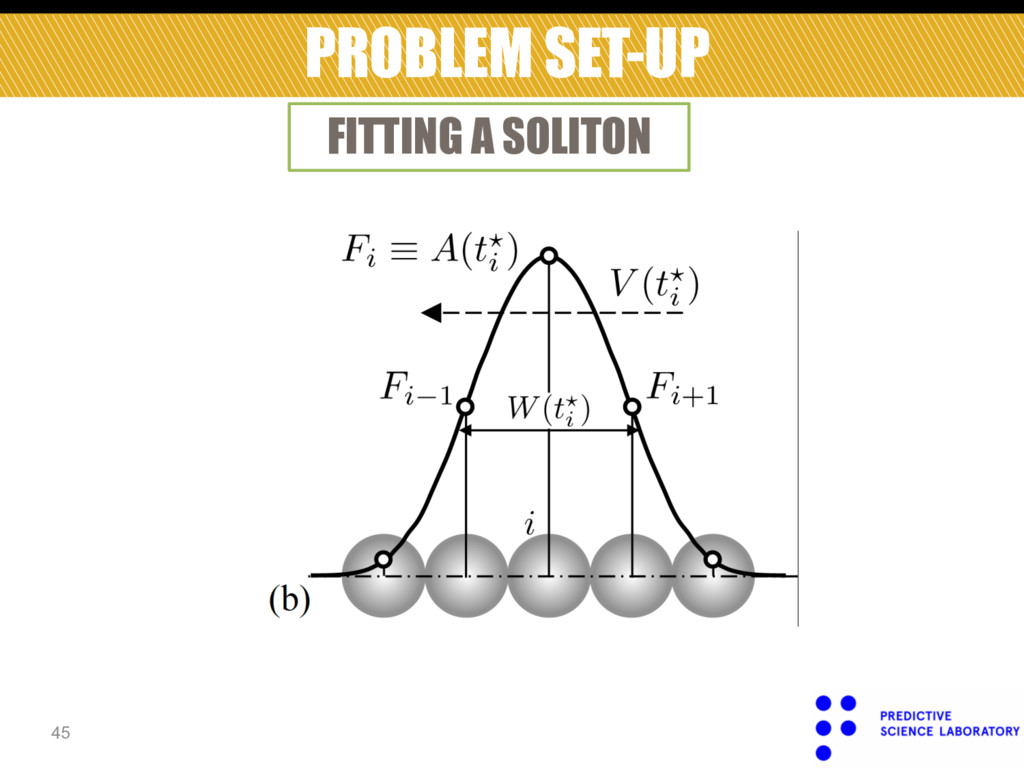
number of time steps: • Output of the simulation : Force • Dimensionality of output : 0=t 1 <…<t n t F !(x) n p ×n t TOO HIGH !!! Reduce output dimensionality by fitting a soliton.
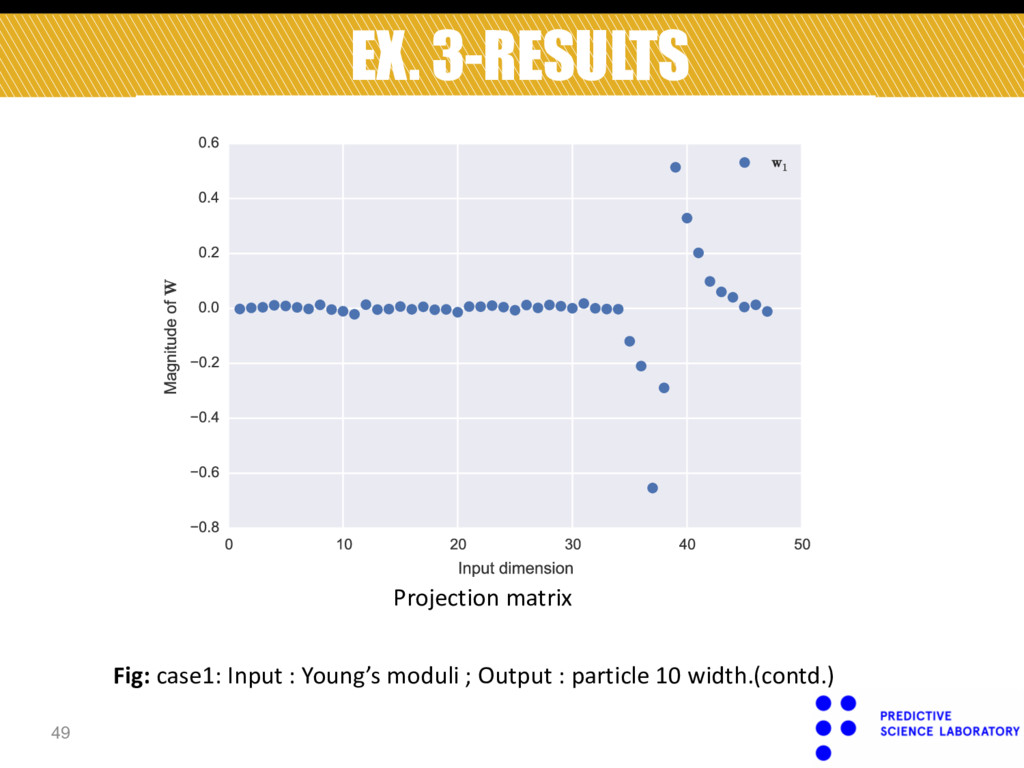
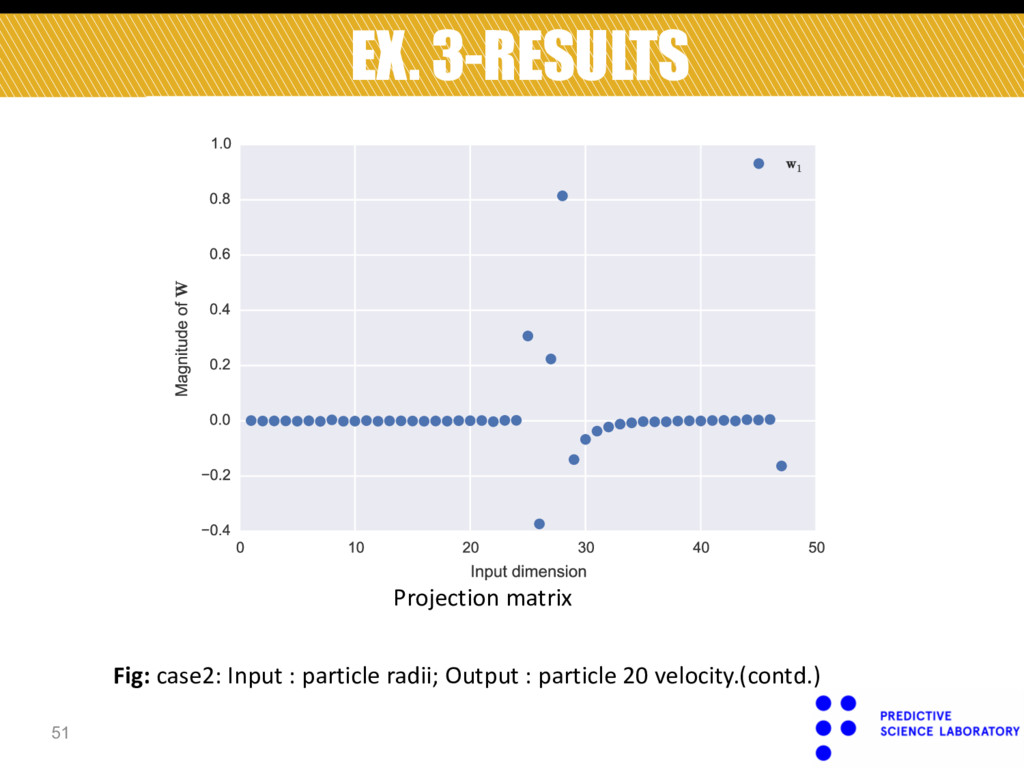
we show results for the following 3 cases: § Input=Young’s modulus, Output=width over 10th particle. § Input=particle radii, Output=velocity over 20th particle.
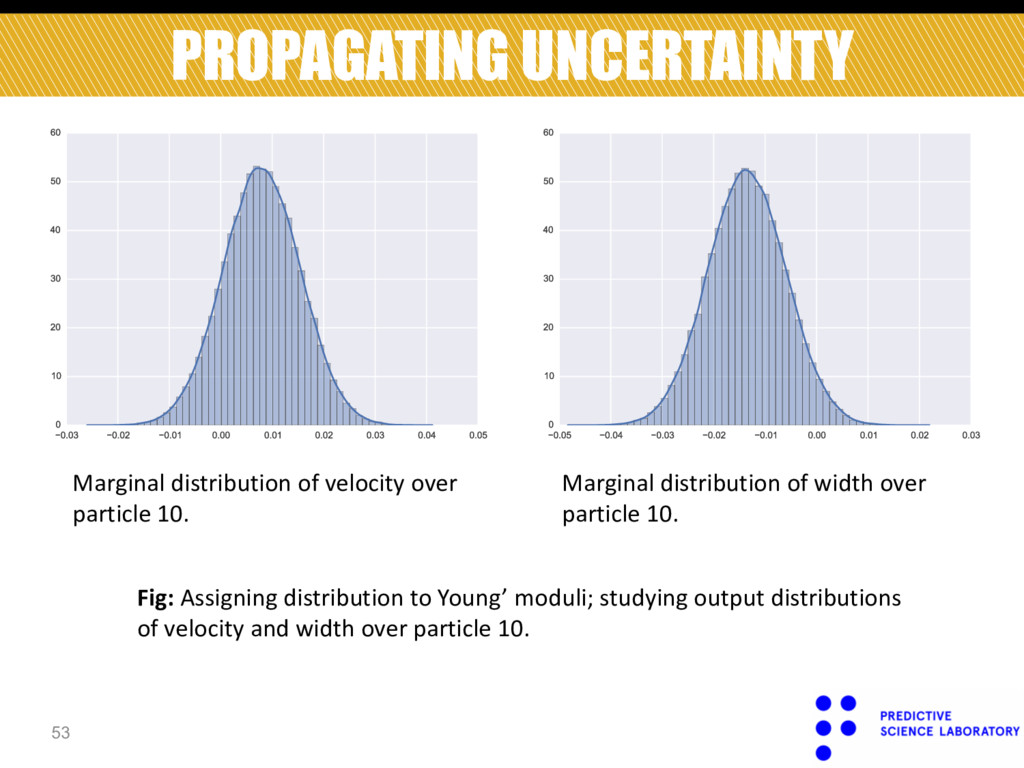
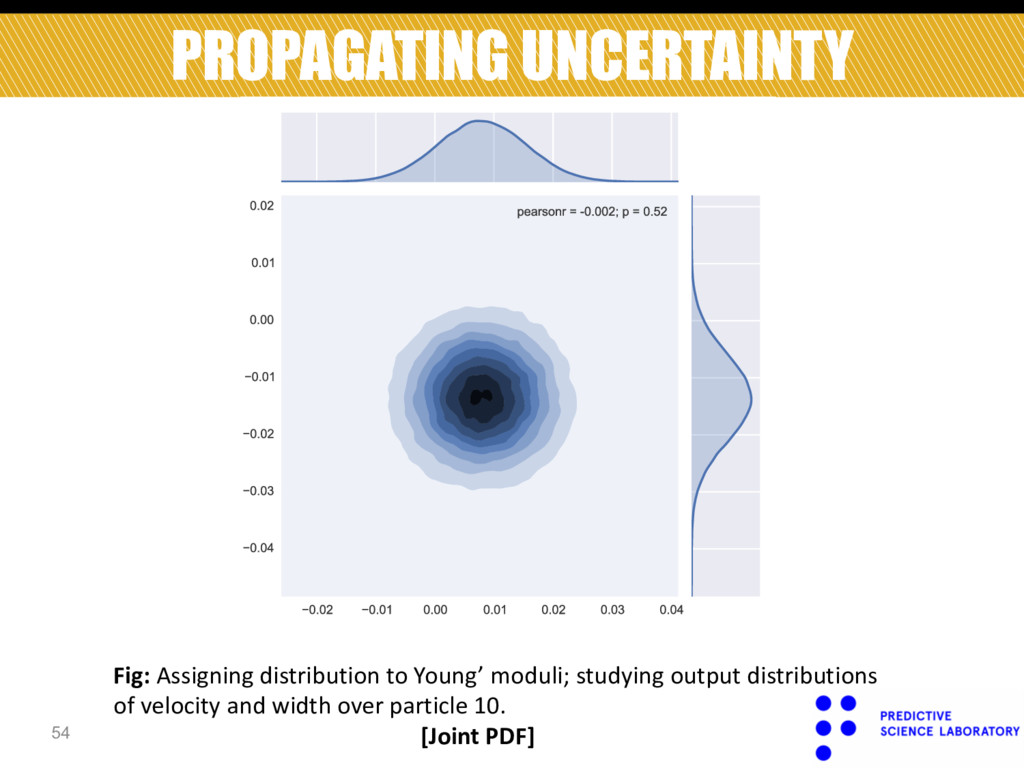
Marginal distribution of velocity over particle 10. Fig: Assigning distribution to Young’ moduli; studying output distributions of velocity and width over particle 10.
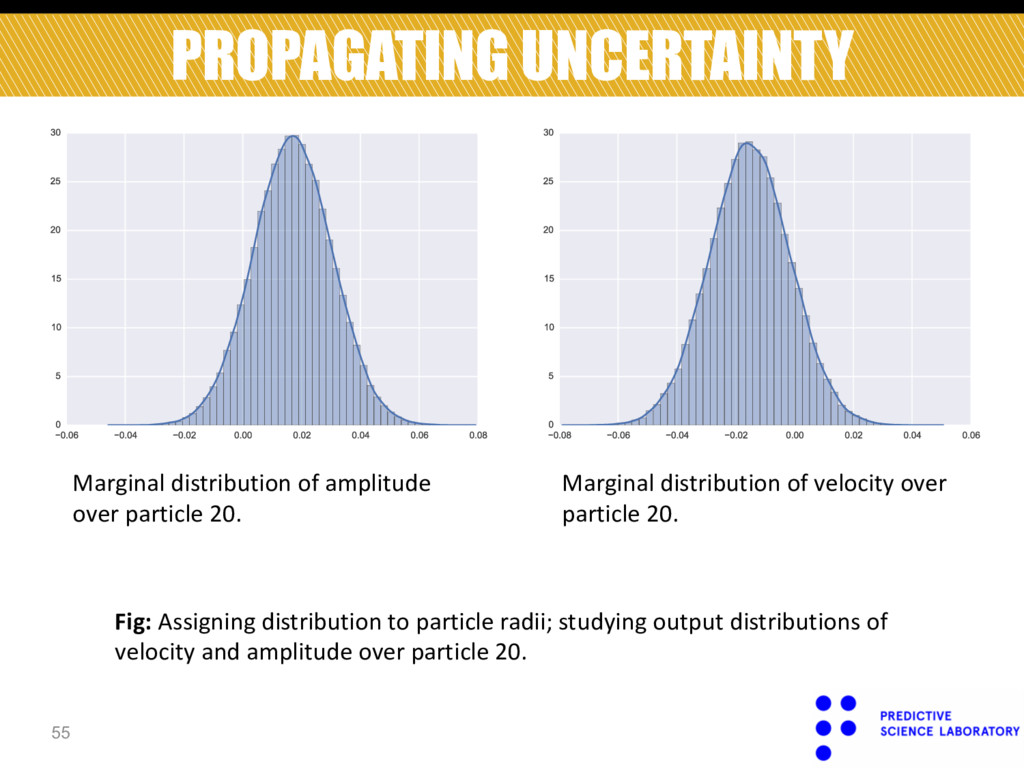
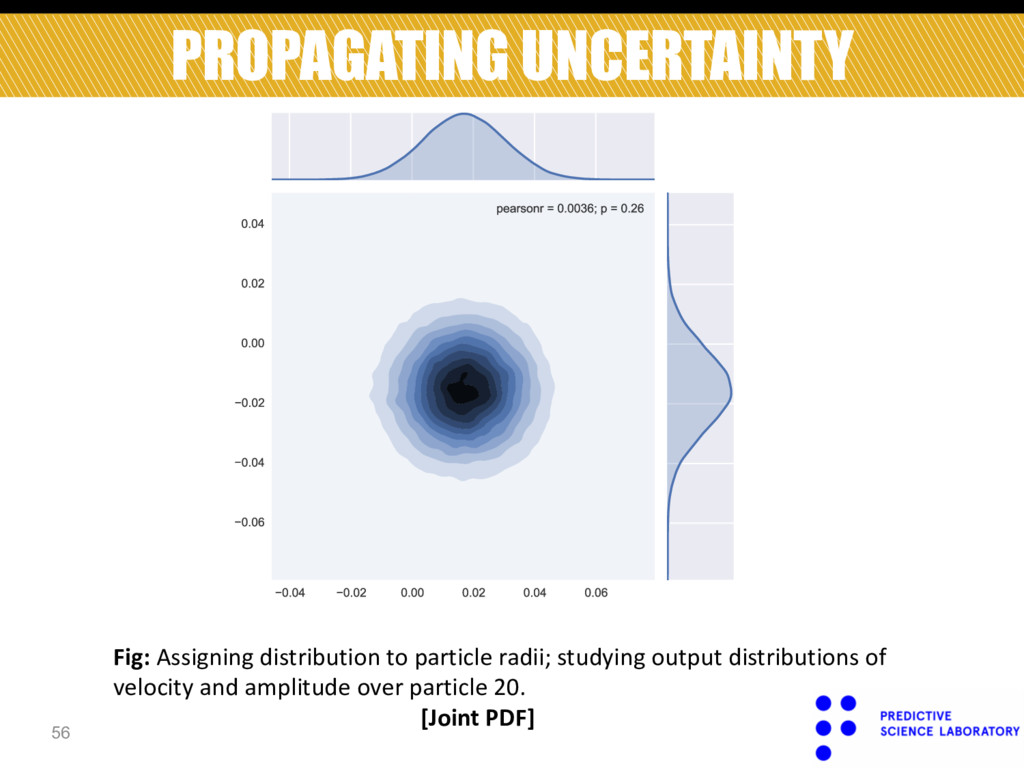
Marginal distribution of amplitude over particle 20. Fig: Assigning distribution to particle radii; studying output distributions of velocity and amplitude over particle 20.
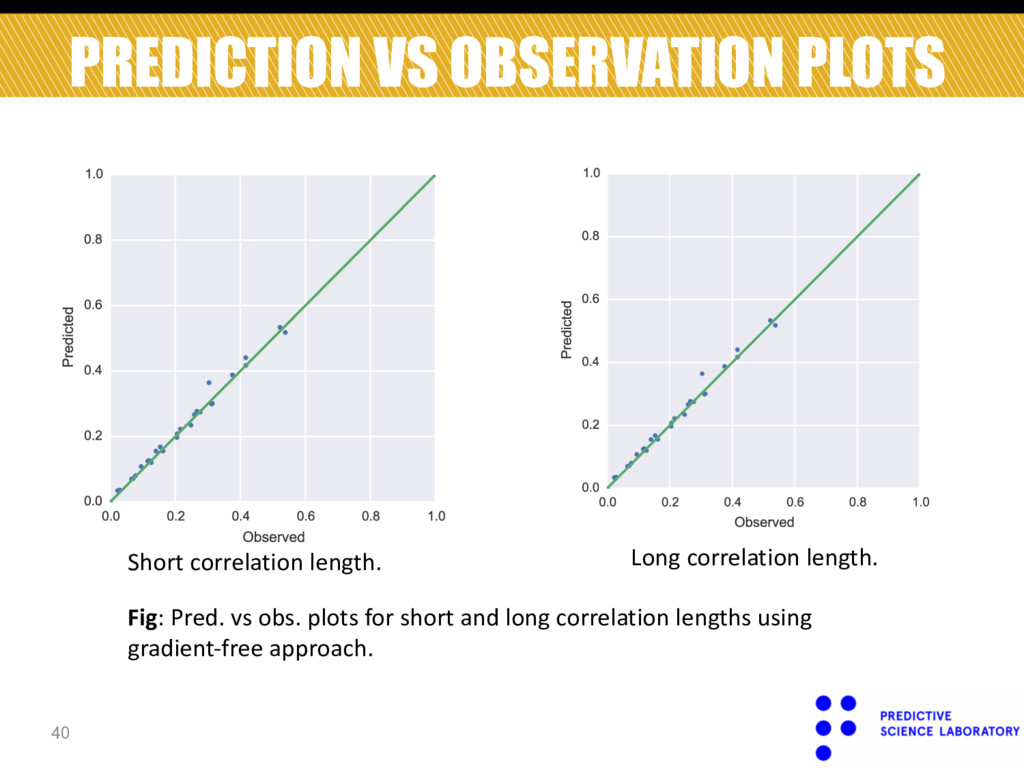
discovery. • Novel Gaussian process regression with built-in dimensionality reduction. • Orthogonal projection matrix which constitutes a hyper- parameter of the covariance kernel. • BIC score for model selection. • Validated methodology through 3 numerical examples.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![20 STIEFEL OPTIMIZATION Gradient Ascent curve[1]: γ (τ;W)=(I D −](https://files.speakerdeck.com/presentations/f7851a994bef447b8b67c0bfeea44e04/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}