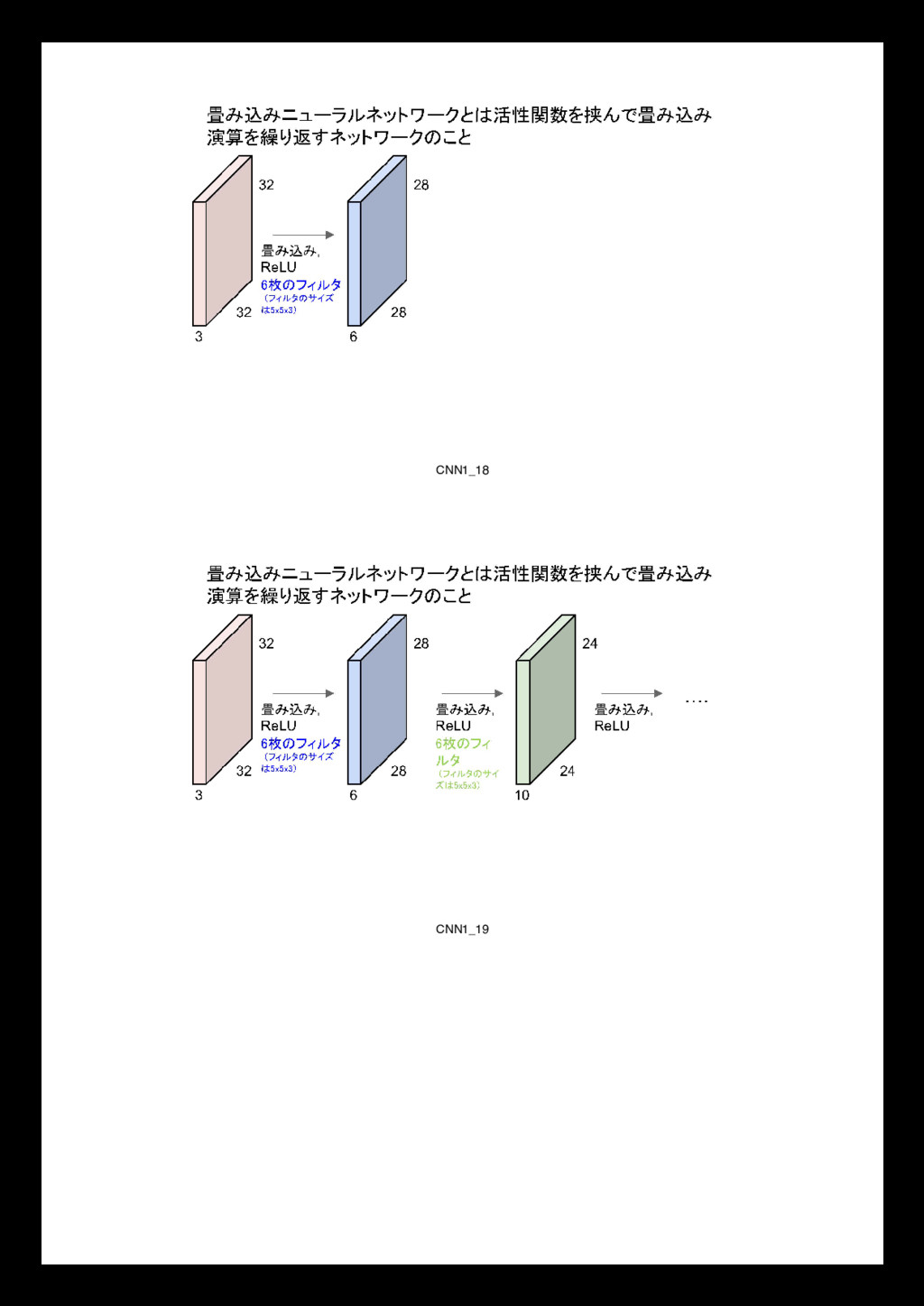
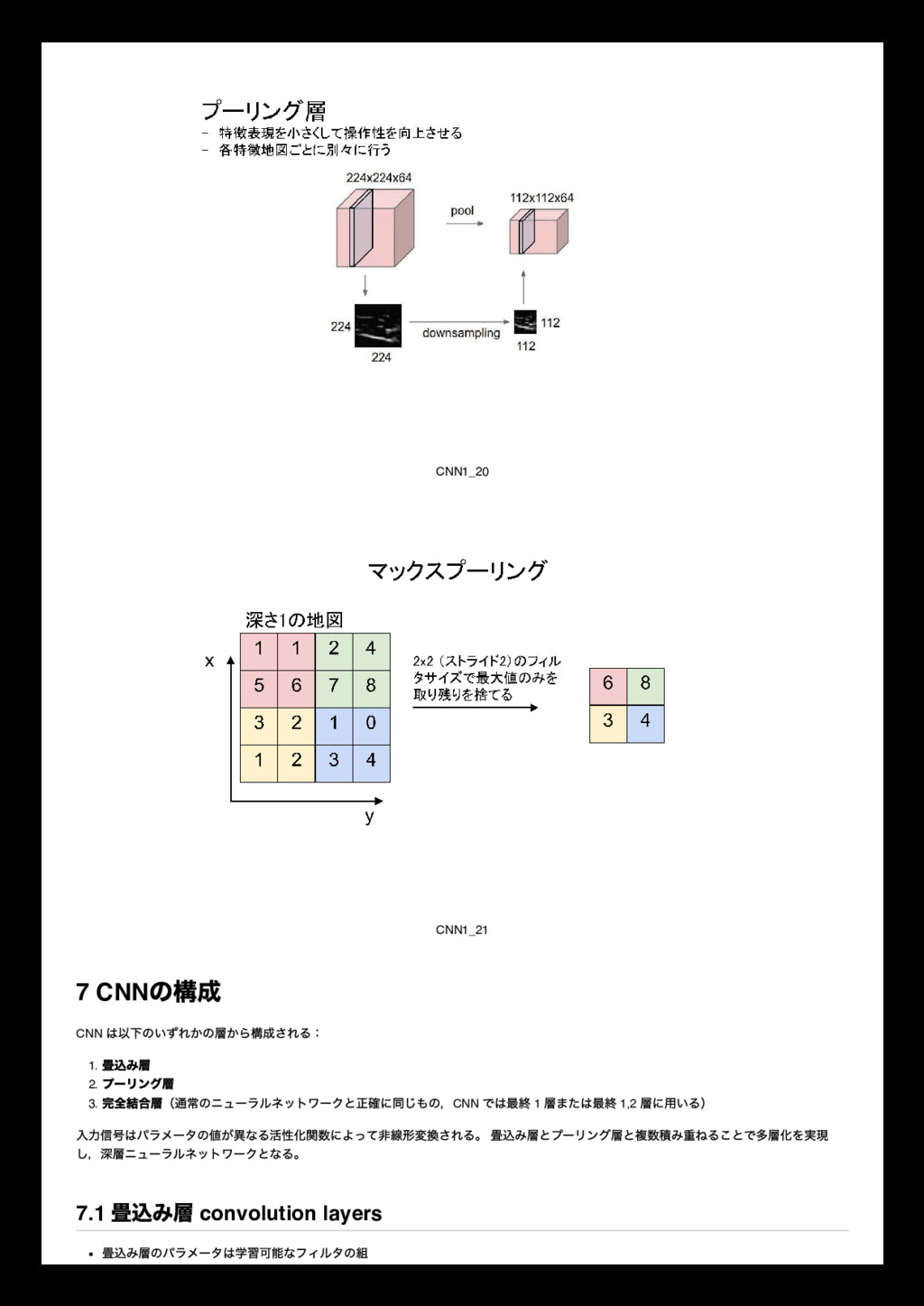
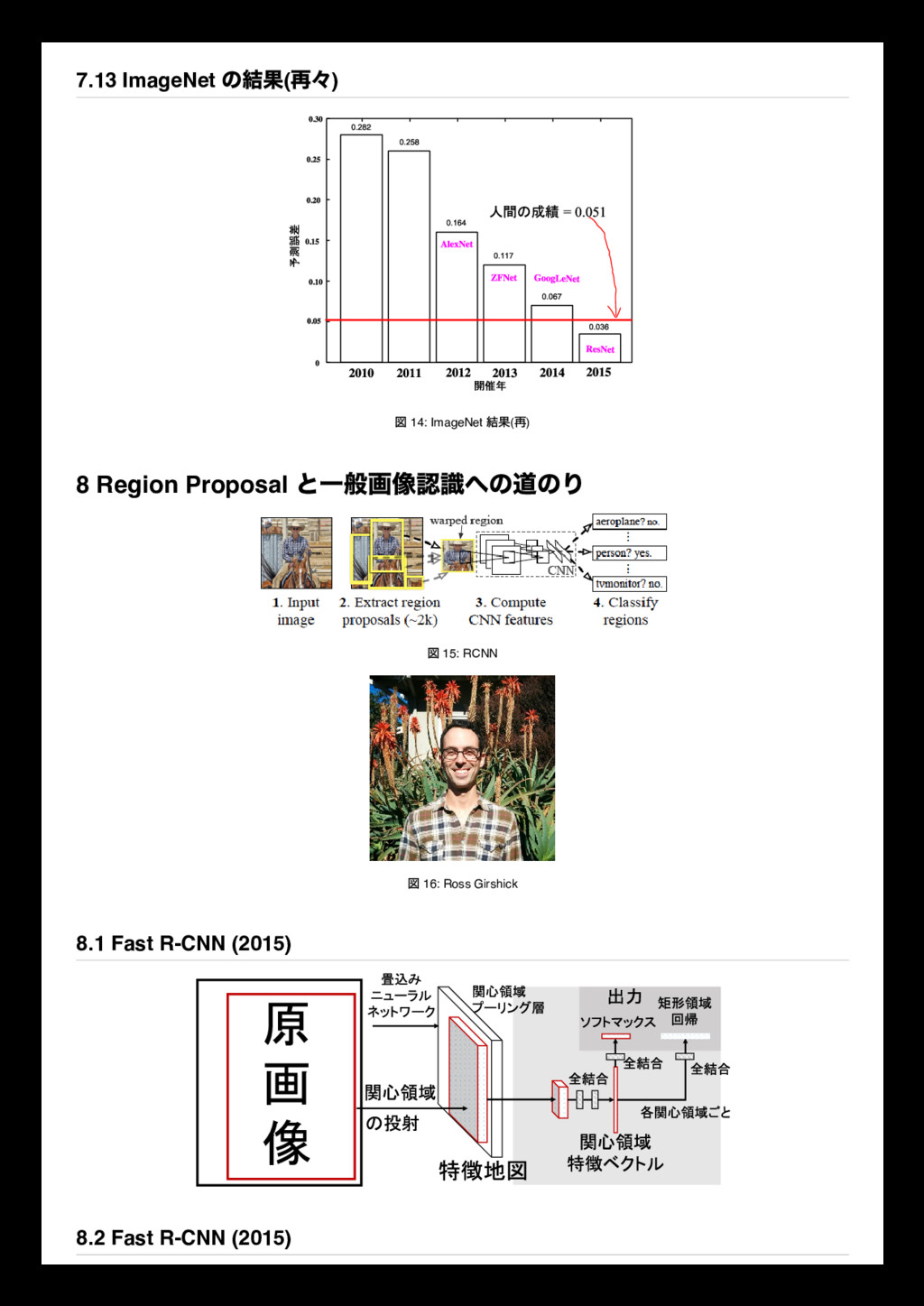
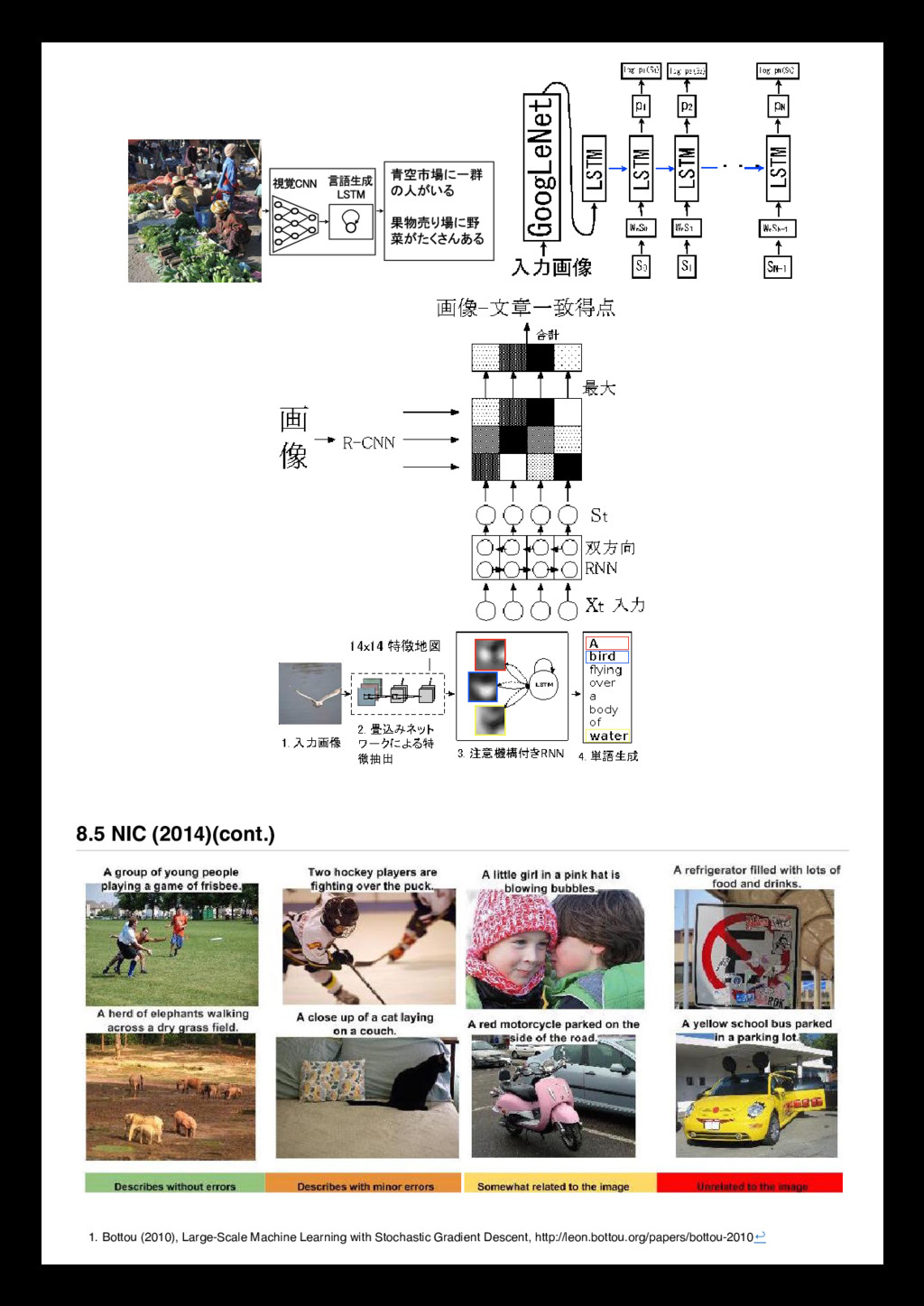
0 0 0 0 0 1 0 0 1 0 0 2 1 0 1 2 0 0 1 1 1 2 0 0 0 1 1 0 0 2 0 0 2 0 2 1 0 0 0 0 0 0 0 0 0 x[:,:,1] 0 0 0 0 0 0 0 0 2 1 1 1 0 0 0 0 1 2 1 0 0 0 2 2 0 2 1 0 0 2 0 0 1 1 0 0 0 2 0 0 1 0 0 0 0 0 0 0 0 x[:,:,2] 0 0 0 0 0 0 0 2 0 1 1 1 0 1 1 1 0 2 0 1 2 1 1 1 0 2 0 1 0 2 0 1 1 2 1 0 0 0 0 0 0 0 Filter W0 (3x3x3) w0[:,:,0] 1 -1 1 0 0 -1 -1 -1 -1 w0[:,:,1] -1 0 0 0 -1 -1 -1 0 -1 w0[:,:,2] 0 0 0 0 1 0 1 0 0 Bias b0 (1x1x1) b0[:,:,0] 1 Filter W1 (3x3x3) w1[:,:,0] 1 0 0 0 0 -1 0 1 1 w1[:,:,1] 1 -1 1 0 -1 0 -1 1 0 w1[:,:,2] -1 -1 1 -1 0 0 1 -1 0 Bias b1 (1x1x1) b1[:,:,0] 0 Output Volume (3x3x2) o[:,:,0] -5 -3 -2 -6 -3 -4 0 3 -3 o[:,:,1] -1 1 -2 0 -6 -2 -4 -1 -4 toggle movement Convolution is an operation from signal processing Filters, or kernels in machine learning, 理解を深めるためには have a look at http://colah.github.io/posts/2014-07-Understanding-Convolutions/ 1959 Receptive Fields of Single Neurones in the Cat's Striate Cortex 1962 Receptive Fields, Binocular Interaction and Functional Architecture in the Cat's Visual Cortex 1968 7.9 畳み込み演算 What is convolution? f ∗ g(t) = ∑ a+b=t f(t) ⋅ g(t) (6) f ∗ g(t) = ∑ a f(t) ⋅ g(t − a) (7) f ∗ g(t) = ∑ f(τ ) ⋅ g(t − τ ) (8) f ∗ g(t) = ∫ f(τ )g(t − τ ) dτ (9) 7.10 Hubel and Wiesel, a series of studies
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Input Volume (+pad 1) (7x7x3) x[:,:,0] 0 0 0 0](https://files.speakerdeck.com/presentations/668d7452143a45ee88ec7f036d30c7a4/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}