Share
UnityとPython(TensorFlow)を連携させることで、シミュレータを利用した強化学習をおこなうことができます。 Unity社が公式に提供している「Unity ML-Agents Toolkit」を利用することで手軽に環境構築が可能です。 この発表を聞くことで強化学習やUnityに対する理解が深まるとともに、「Unity ML-Agents Toolkit」の仕組みや使い方を知ることができます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
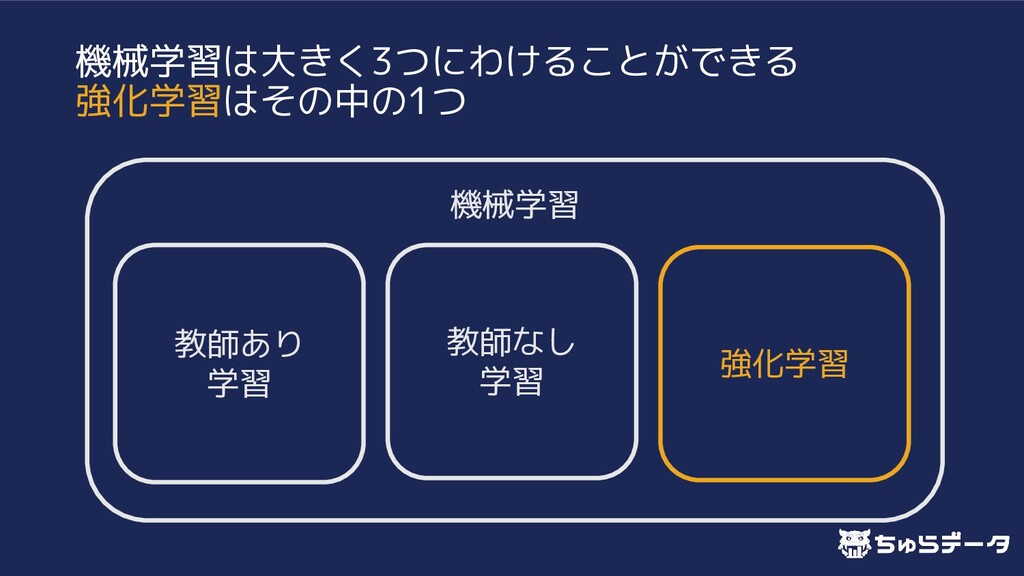{kind=link}
{kind=link}
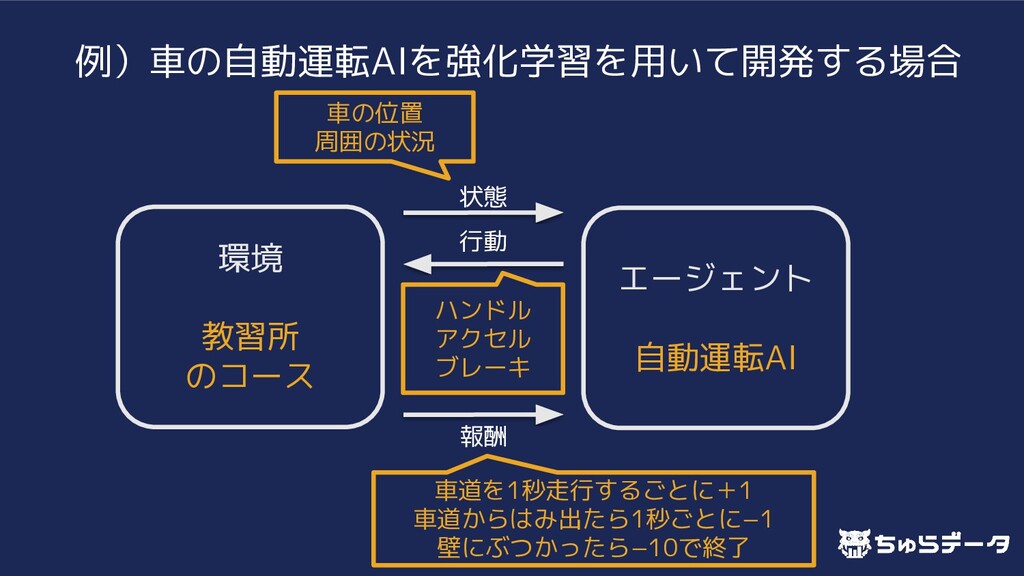{kind=link}
{kind=link}
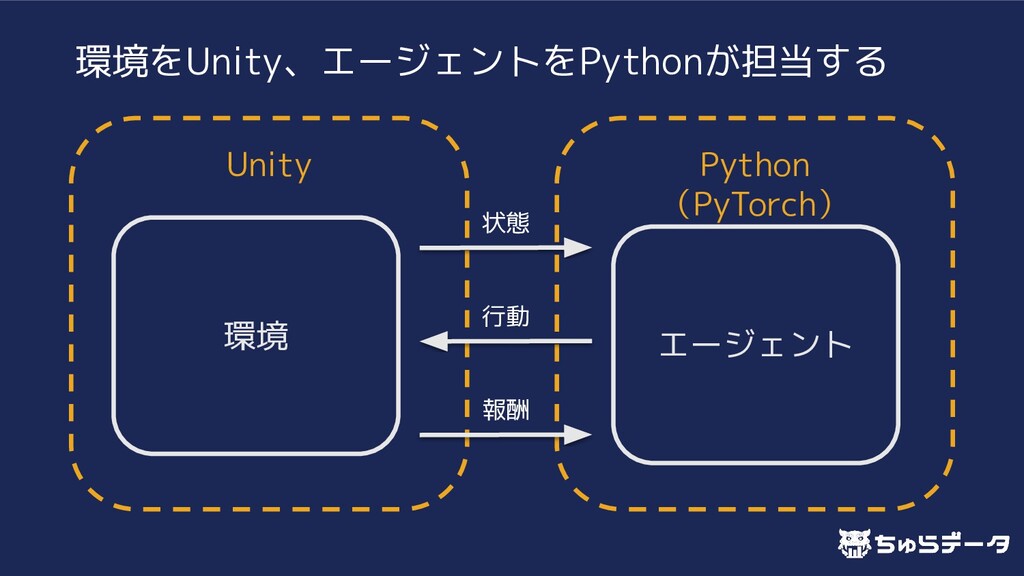{kind=link}
{kind=link}
{kind=link}
{kind=link}
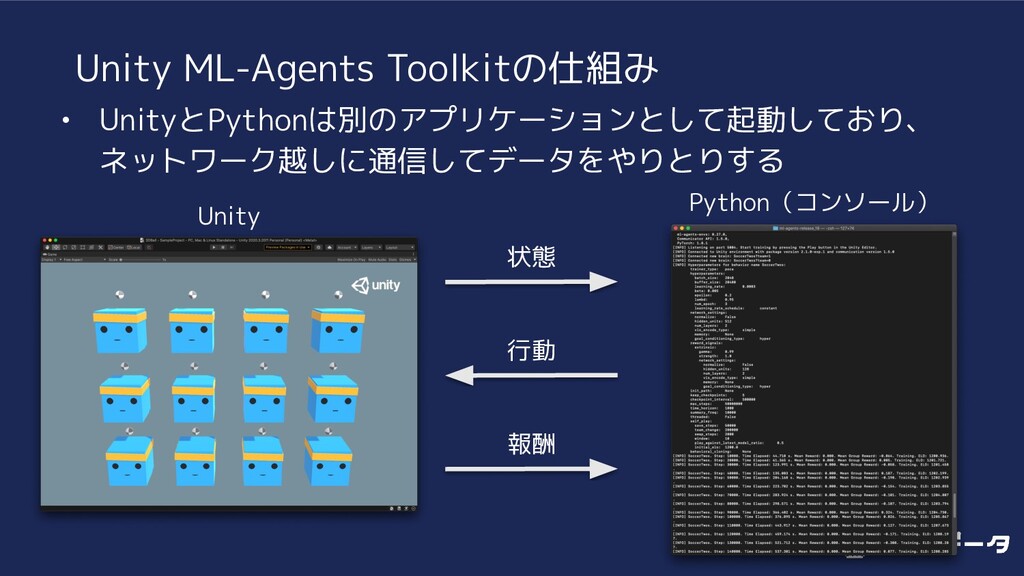{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}