We are probably past the hype curve on serverless technologies. All major cloud providers offer development support beyond just runtimes, and success stories of large applications designed and deployed according to serverless principles are arriving regularly. This talk conveys numbers based on interviews, surveys, web data and experiments: What are the painful limitations developers still have to work around? Which patterns are commonly implemented? And are 100ms microbilling periods the end of the game?
{kind=link}
{kind=link}
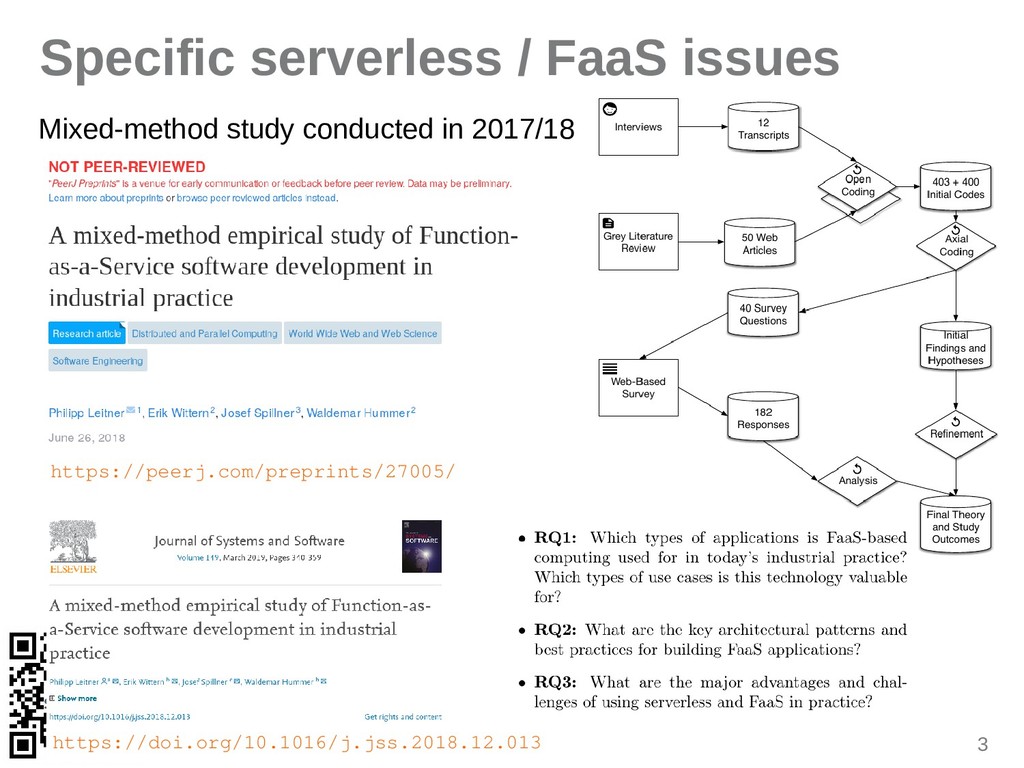{kind=link}
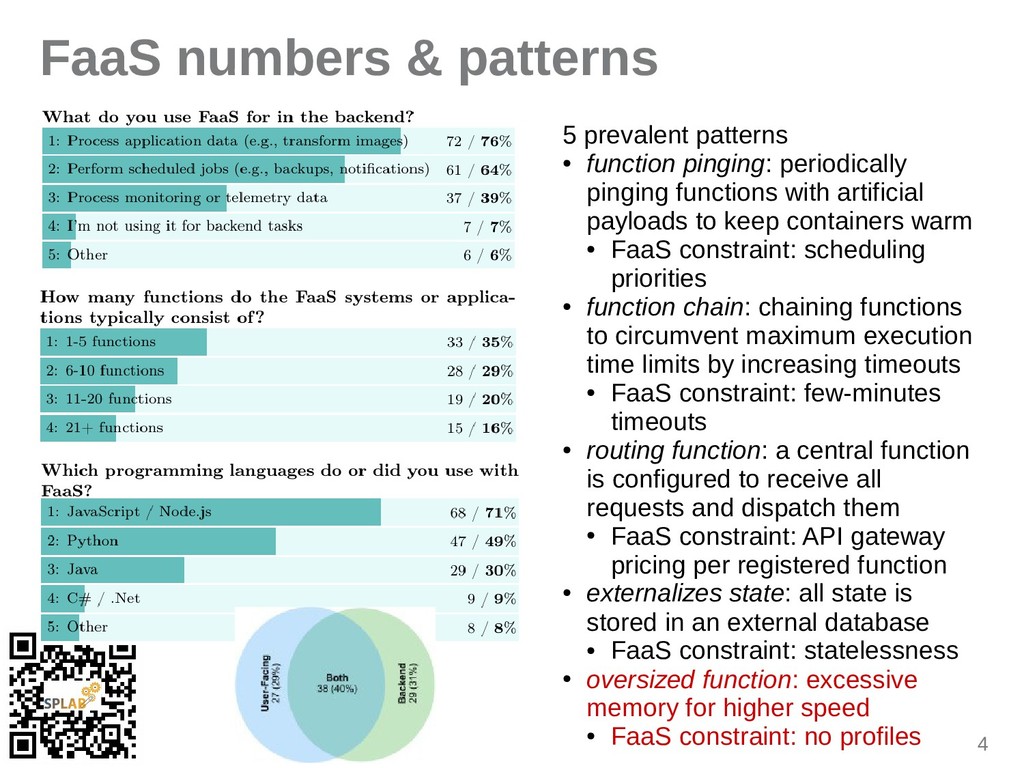{kind=link}
{kind=link}
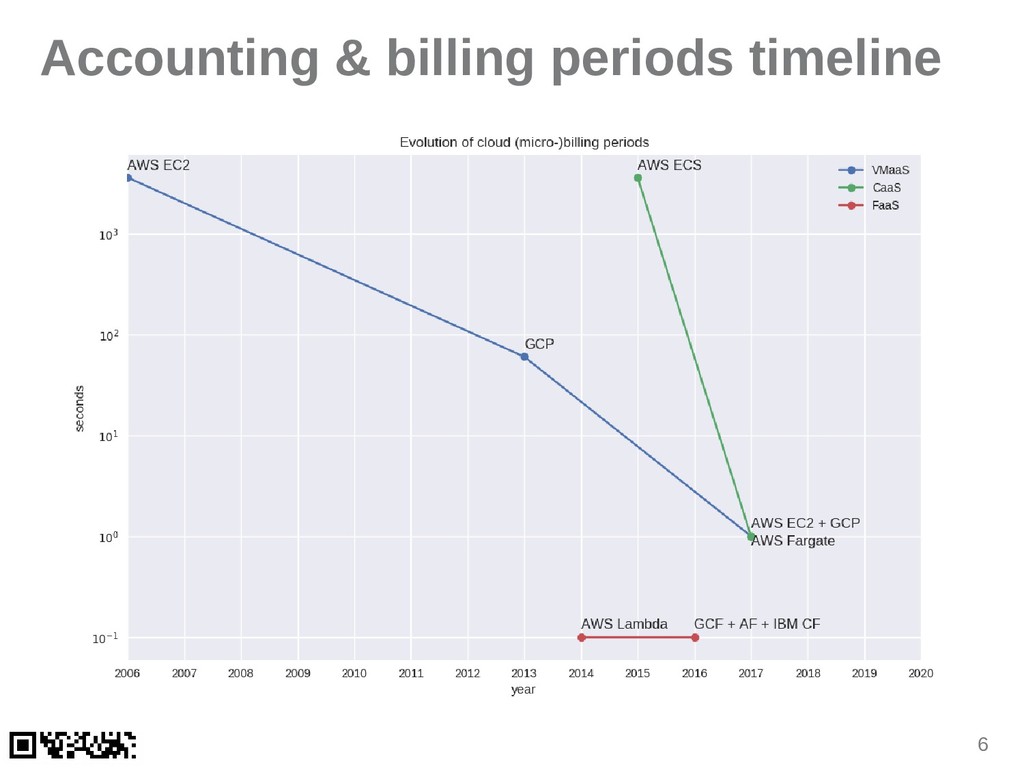{kind=link}
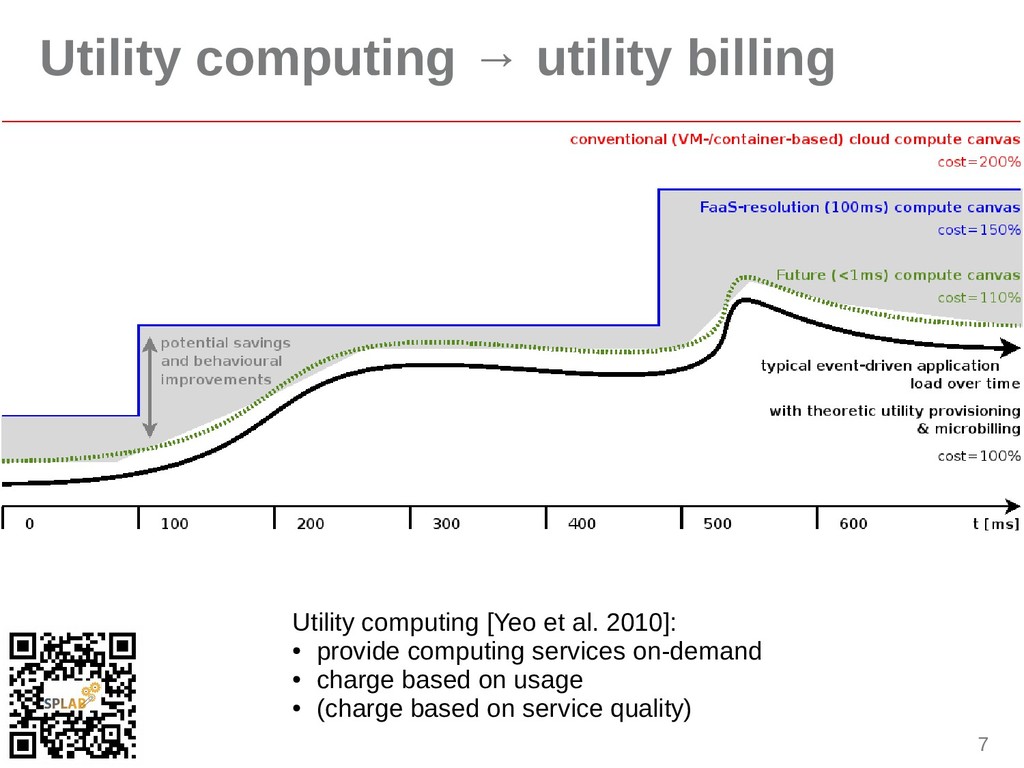{kind=link}
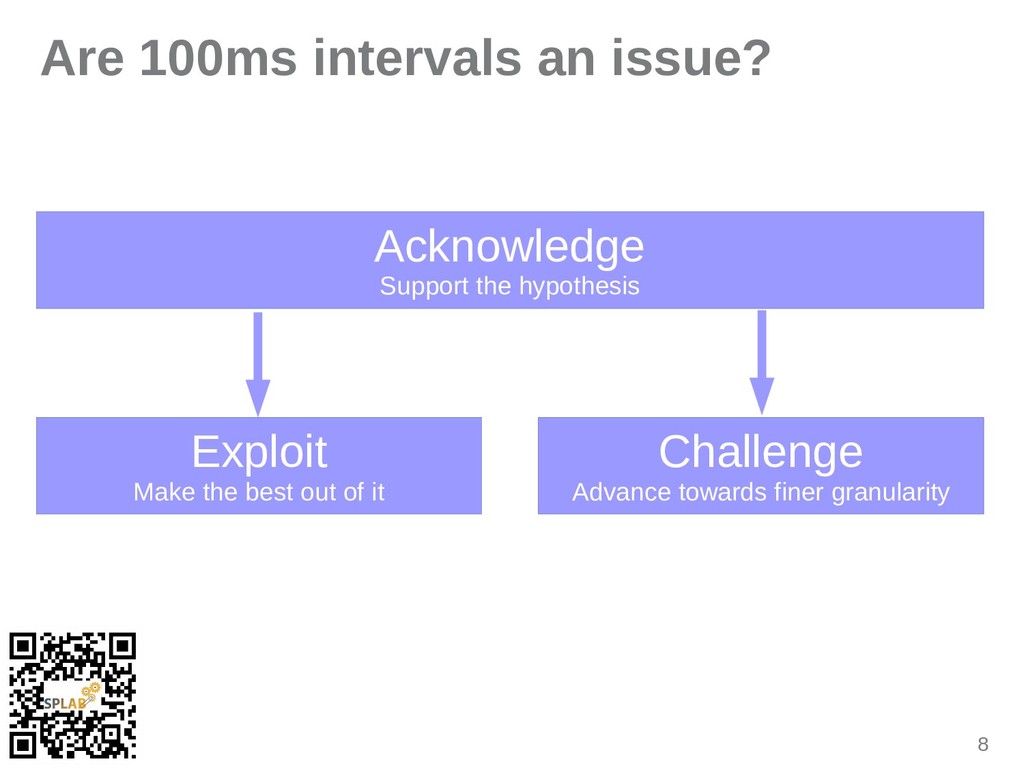{kind=link}
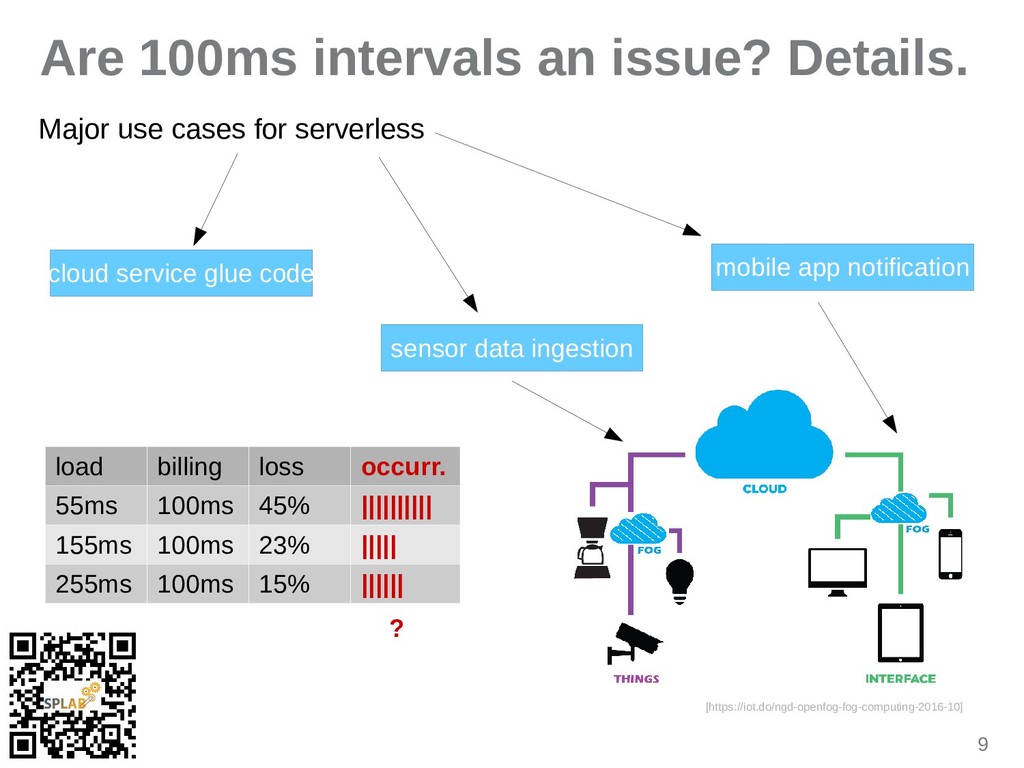{kind=link}
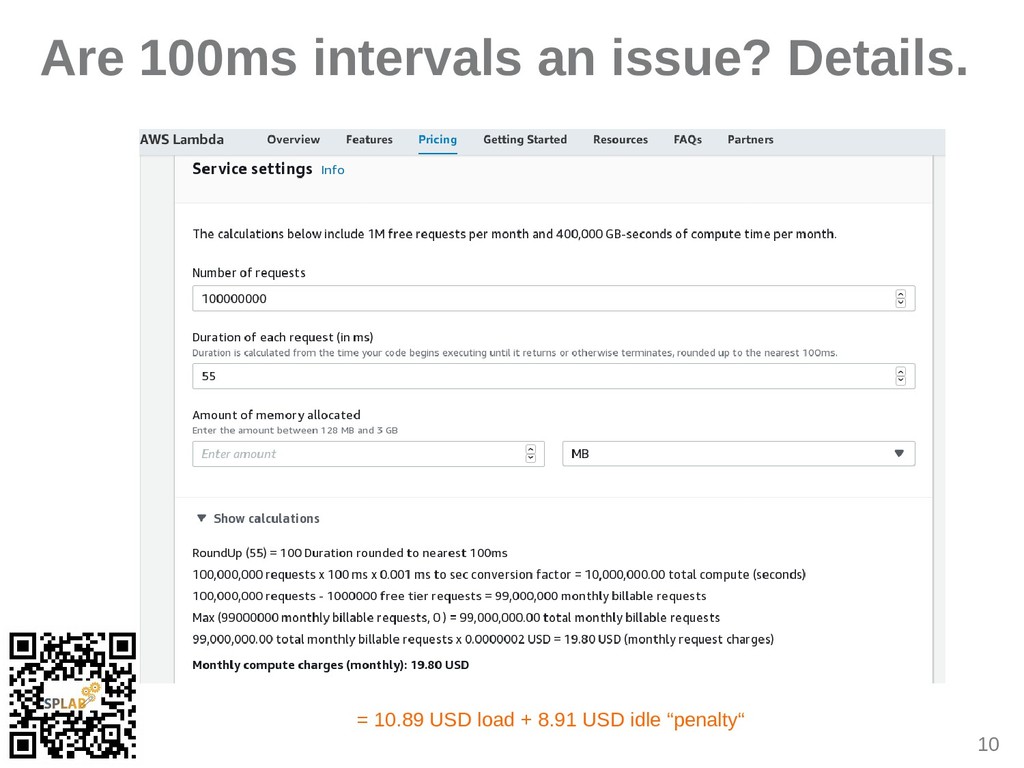{kind=link}
{kind=link}
{kind=link}
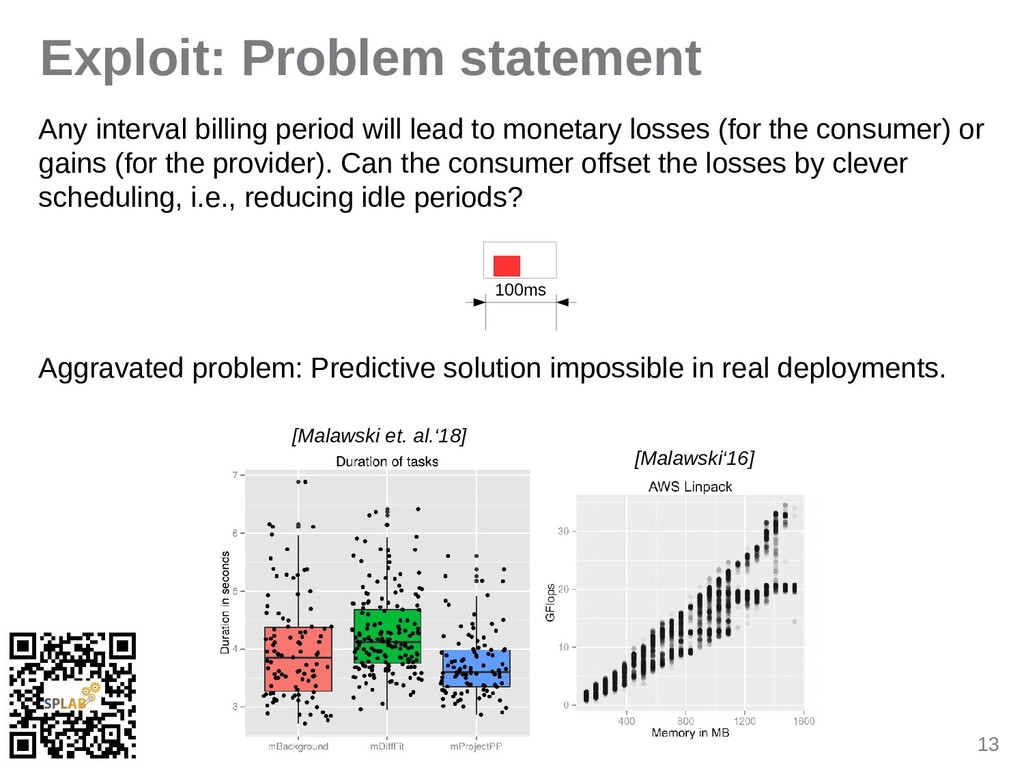{kind=link}
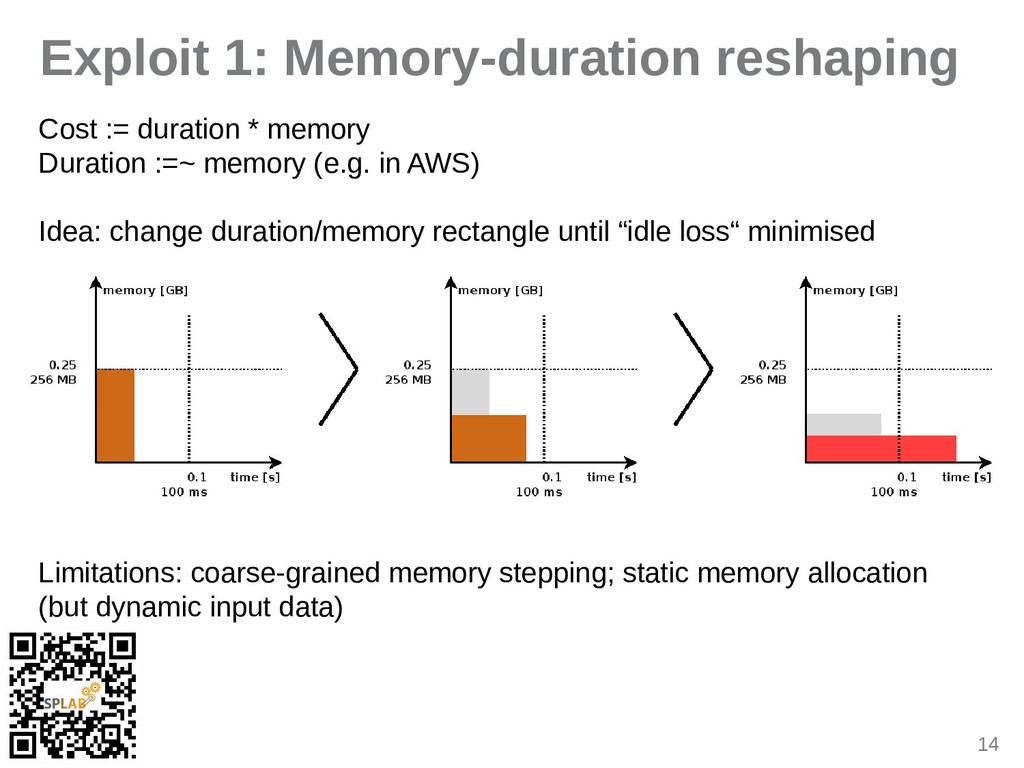{kind=link}
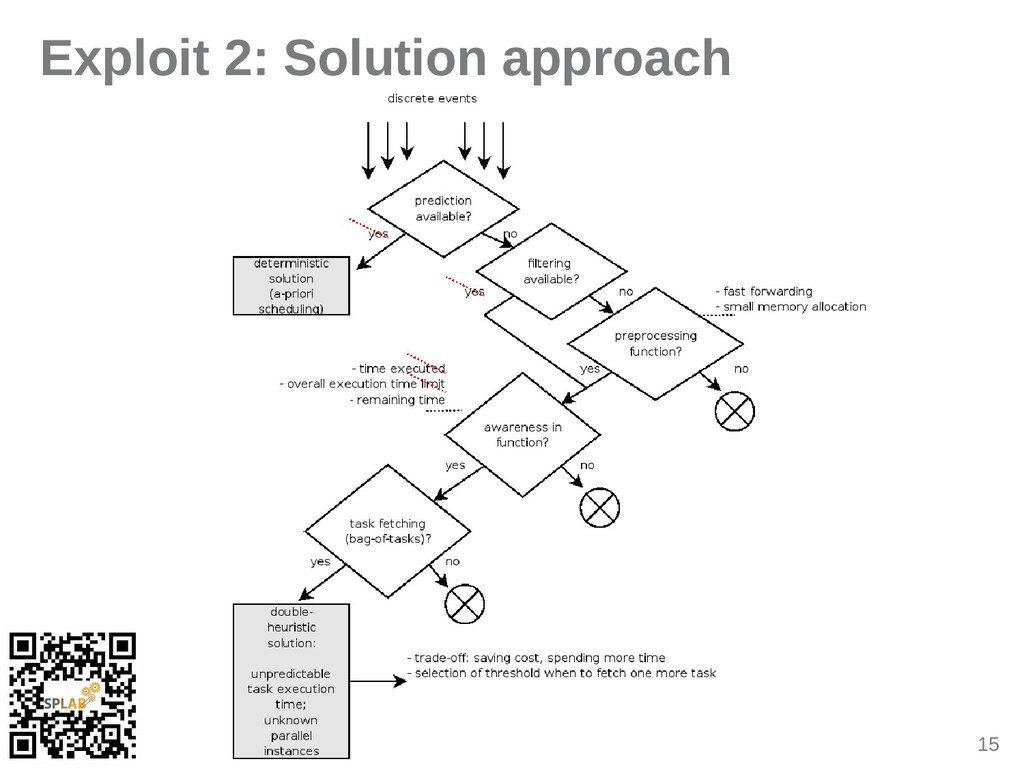{kind=link}
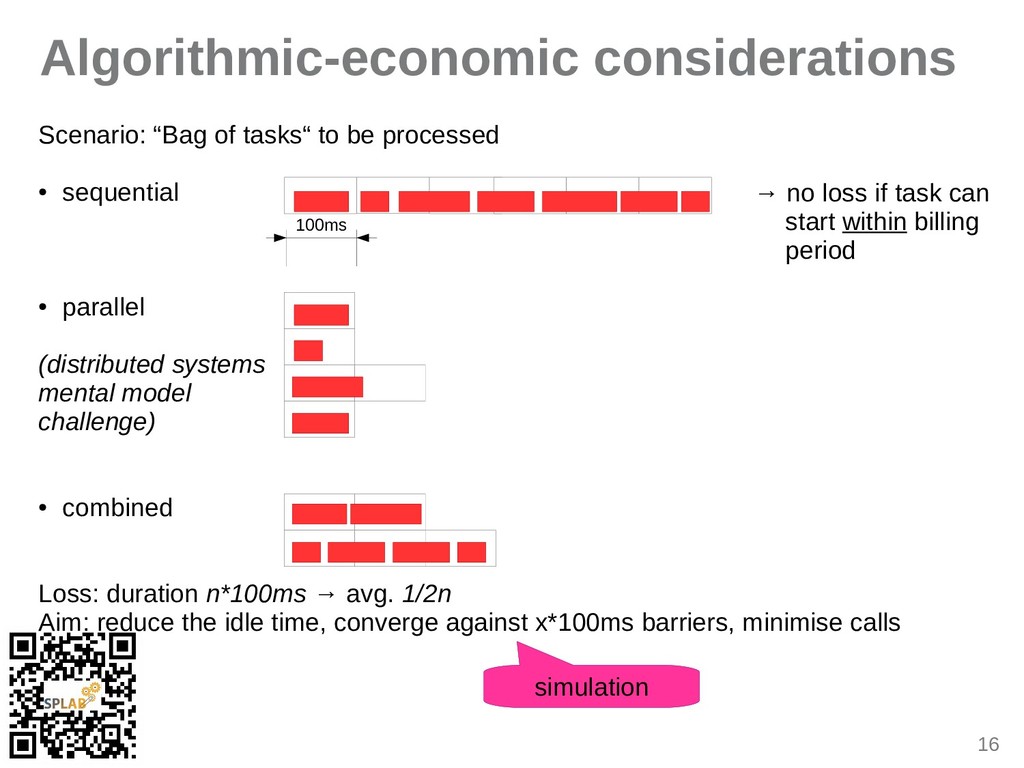{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
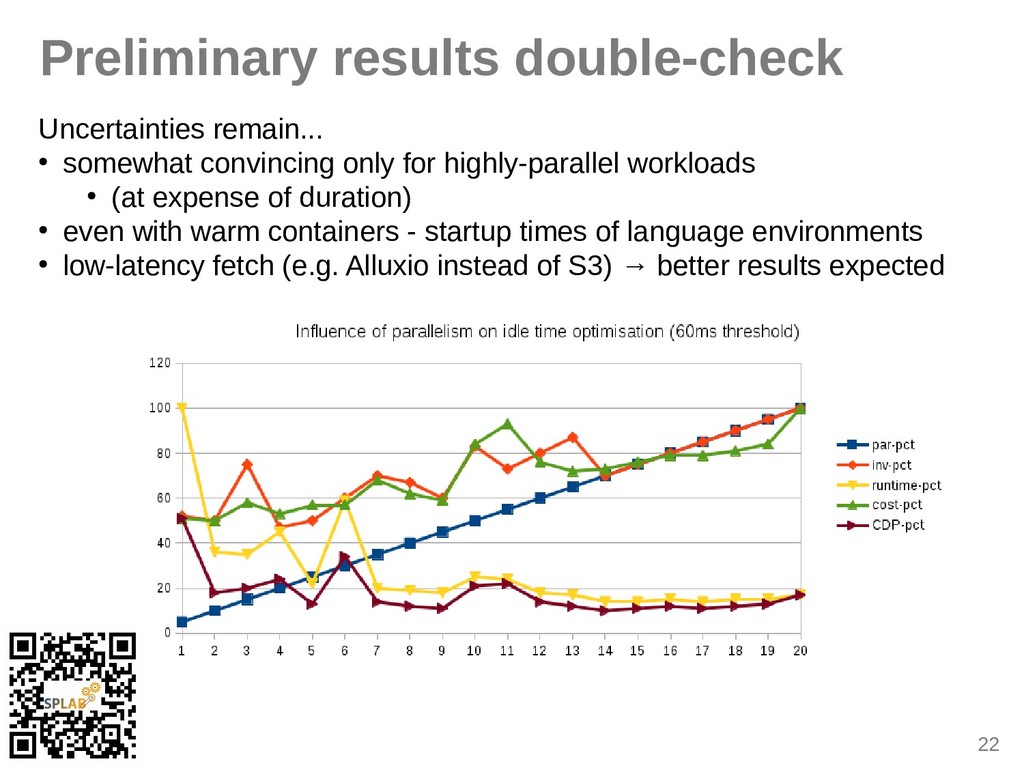{kind=link}
{kind=link}