SECR 2018
Александр Сербул
Руководитель отдела контроля качества и внедрений, 1С-Битрикс
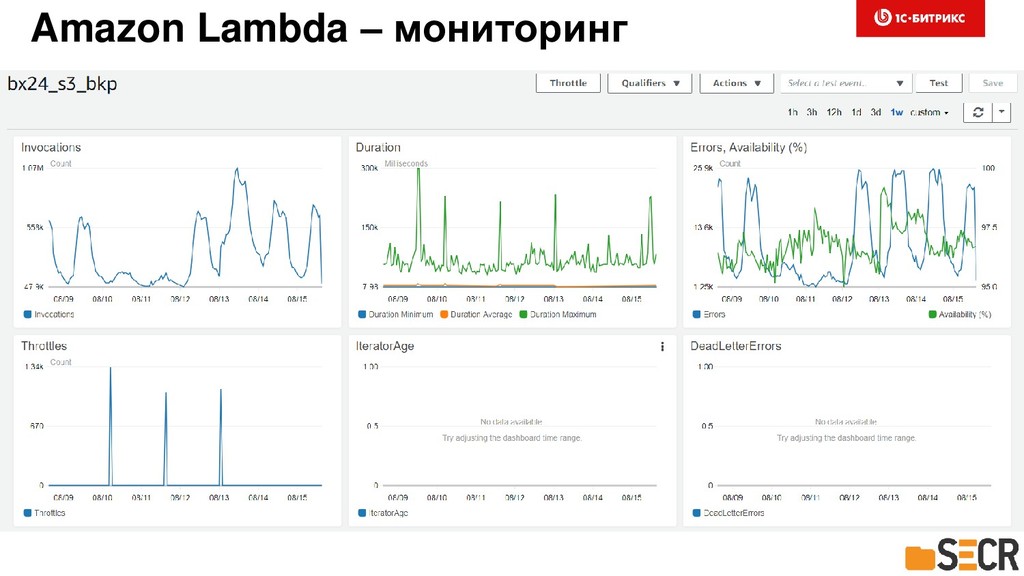
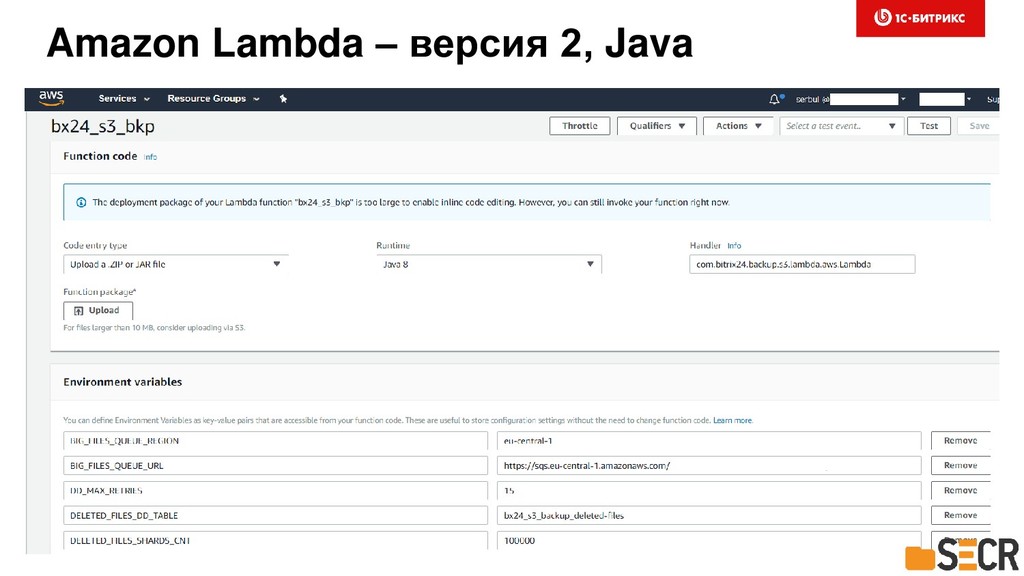
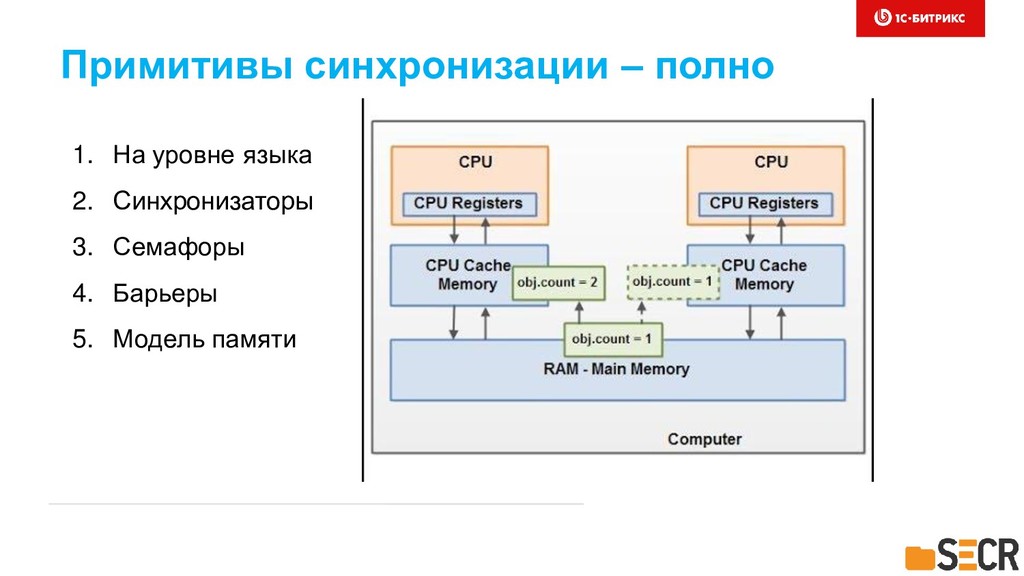
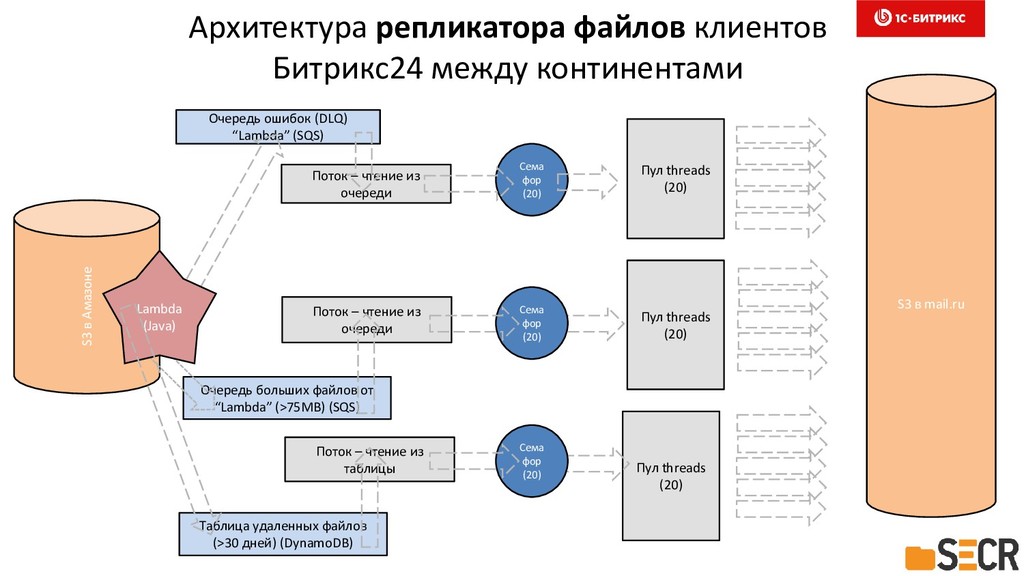
Расскажем, как мы проектировали, реализовали и запустили в эксплуатацию асинхронную репликацию данных клиентов Битрикс24 между континентами. Рассмотрим тонкости использования инфраструктуры очередей на базе Amazon SQS, NoSQL в DynamoDB и мониторинге системы для предотвращения потерь данных клиентов и минимизации рисков последствий отказов и аварий датацентров. Коснемся особенностей разработки многопоточных приложений на Java. Доклад будет полезен разработчикам высоконагруженных и многопоточных систем, работающих с большими объемами данных в жестких условиях обеспечения высокого уровня надежности и отказоустойчивости. Также информация будет полезной менеджерам, решающим профильные задачи сохранения и репликации данных в распределенных облачных проектах.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
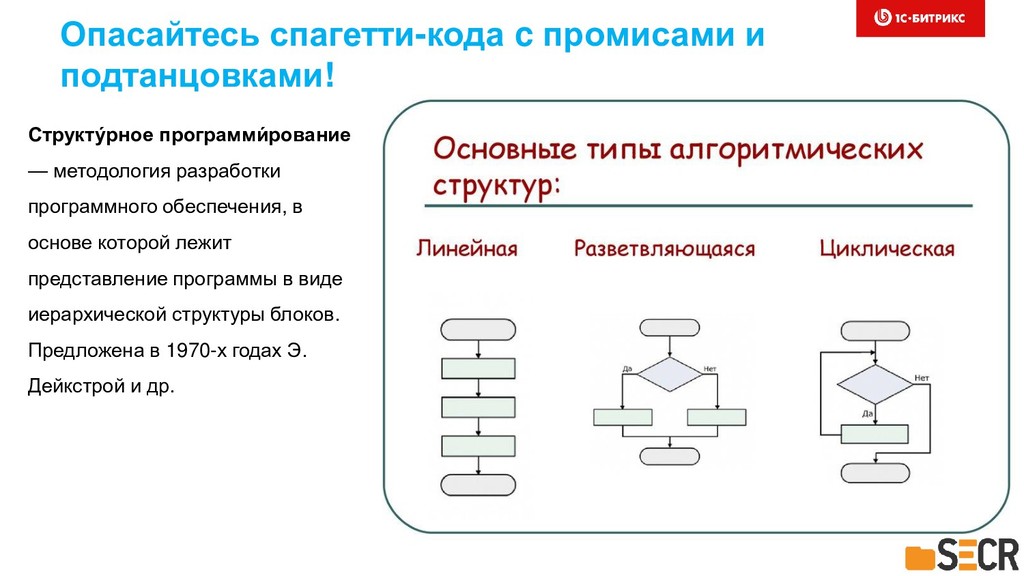{kind=link}
{kind=link}
![Спасибо за внимание! Вопросы? Александр Сербул @AlexSerbul Alexandr Serbul [email protected]](https://files.speakerdeck.com/presentations/571d1ed097d446f2965ef4924d5d58bb/slide_57.jpg){kind=link}