This informal roundtable meeting discussed skills necessary for the next generation of geneticists to be successful. My focus was on Big genetics and Big data.
to millions of samples) – Large experimental crosses – Popula+on studies • BIG Mul+dimensional Data (Gb to Pb of data) – DNA/RNA/Methyla+on Sequencing – Shotgun Proteomics – Metabolomics – Large-‐scale phenotyping • BIG Complexity – Dealing with (and exploi+ng) high gene+c diversity – Computa+onal challenges (must use cloud or hpc resources) – Analy+cal/Sta+s+cal challenges – Mul+ple tes+ng problem – What is significant?
• R sta+s+cal language • Python or Perl • Bash/Linux • Visualiza+on Basic Sta+s+cs for BIG data • Distribu+ons, variance, significance, normaliza+on, transforma+on • Mul+ple tes+ng problem • Linear regression, mixed models, residuals, principle components analysis/singular value decomposi+on
trying to publish) BS. • Understand what a distribu(on is and how to plot/characterize one: Normal/Gaussian, Poisson, NB • What assump+ons about distribu+on variance are made by specific significance tests (e.g. two-‐tailed Student’s T-‐test)? – Are you comparing two groups (treated/ untreated) or a popula+on? • How do you adjust significance thresholds to correct for mul+ple tests?
![BIG Steve Munger [email protected] Slides are posted on https://speakerdeck.com/stevemunger Genetics](https://files.speakerdeck.com/presentations/1125c80063a60132bfad4eebfcde5415/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
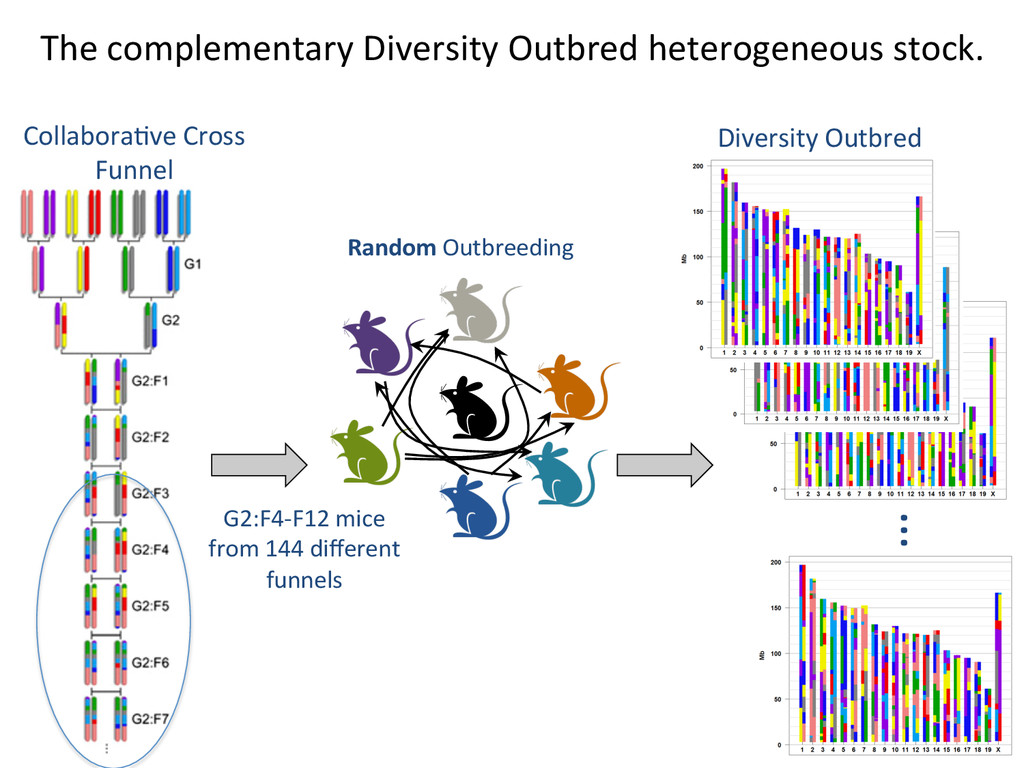{kind=link}
{kind=link}
{kind=link}
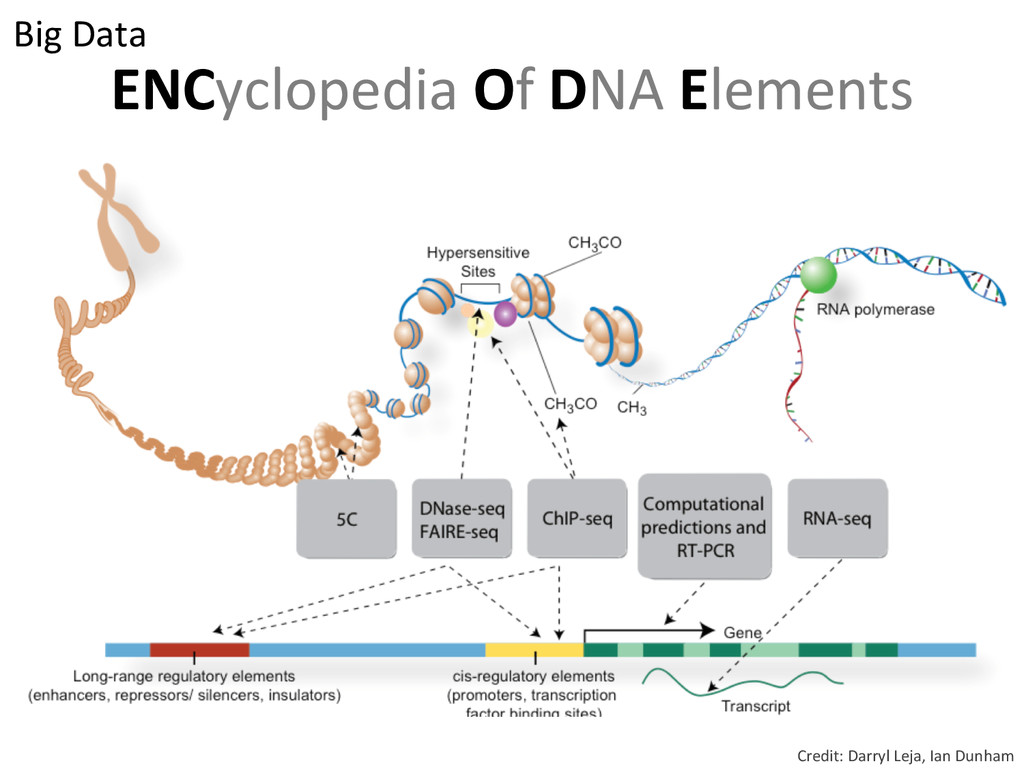{kind=link}
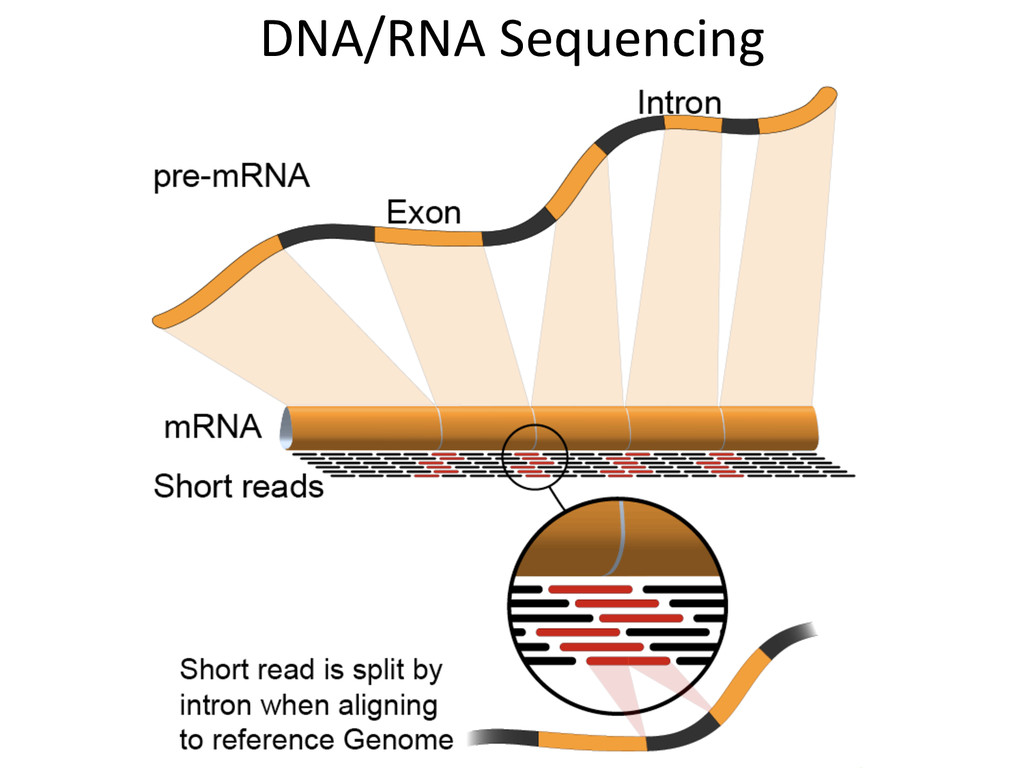{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}