N D E R , A S T E R I S ( J A N 2 0 1 4 ) O R G A N I Z E R O F S T L M A C H I N E L E A R N I N G A N D D O C K E R S T L S Y S T E M S E N G I N E E R I N G , H P C , B I G D A TA & C L O U D N E X T G E N E R AT I O N I N F R A S T R U C T U R E F O R D E V E L O P E R S
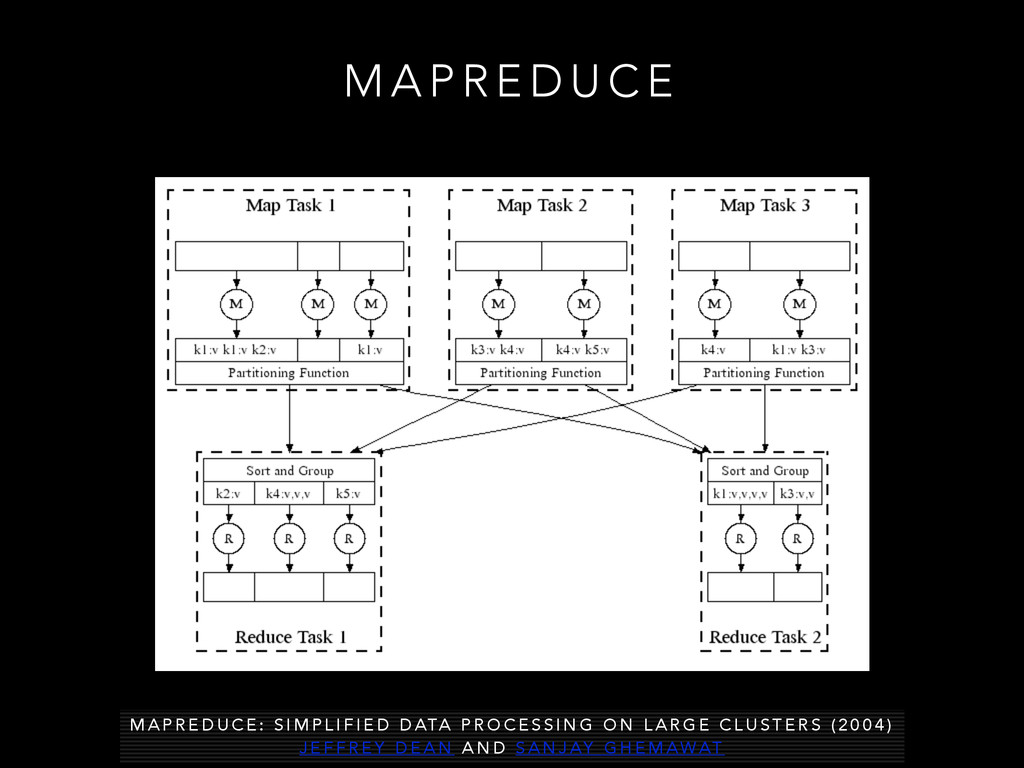
A P R E D U C E : S I M P L I F I E D D ATA P R O C E S S I N G O N L A R G E C L U S T E R S ( 2 0 0 4 ) J E F F R E Y D E A N A N D S A N J AY G H E M AWAT
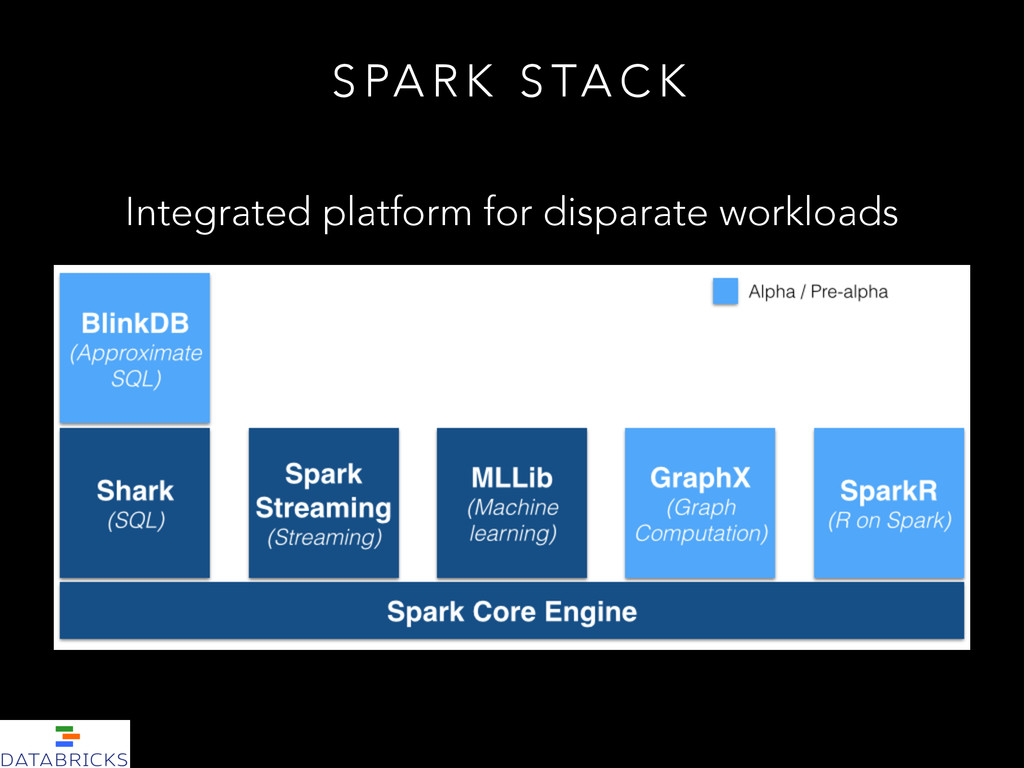
U R E S • Fast, fault-tolerant in-memory data structures (RDD) • Compatibility with Hadoop ecosystem • Rich, easy-to-use API supports Machine Learning, Graphs and Streaming • Interactive Shell
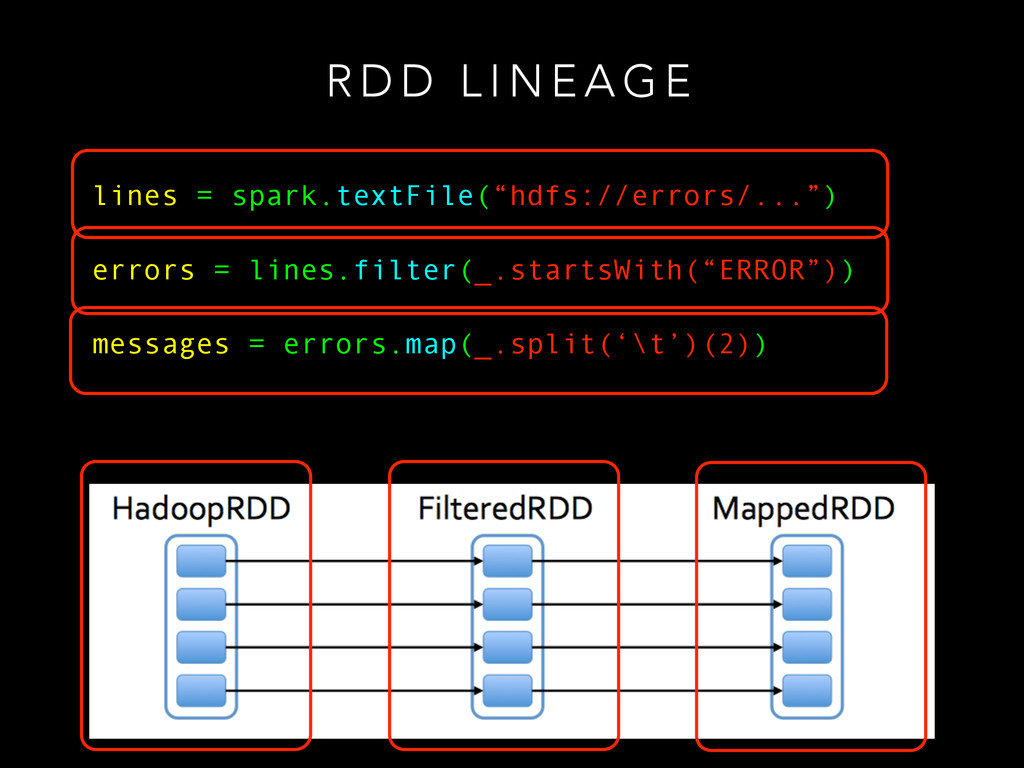
I S T R I B U T E D D ATA S E T • Immutable in-memory collections • Fast recovery on failure • Control caching and persistence to memory/disk • Can partition to avoid shuffles
P P O R T • Spark is written in • Uses Scala collections & Akka Actors • Java, Python native support (Python support can lag), lambda support in Java8/Spark 1.0 • R Bindings through SparkR • Functional programming paradigm
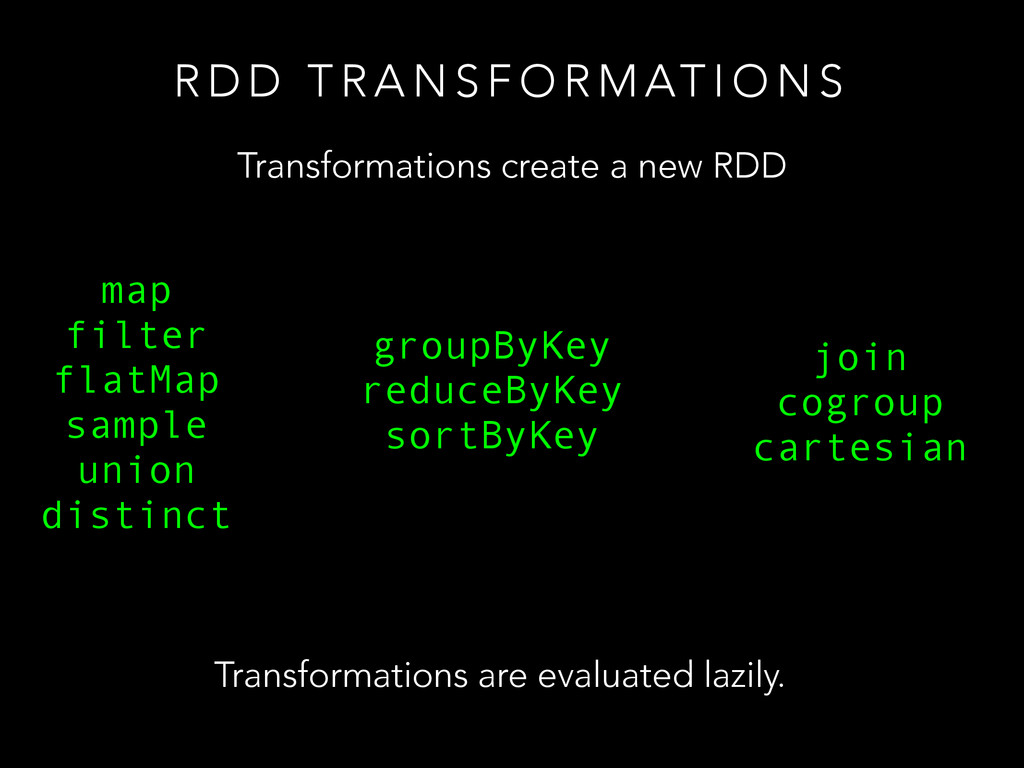
R M AT I O N S Transformations create a new RDD map filter flatMap sample union distinct groupByKey reduceByKey sortByKey join cogroup cartesian Transformations are evaluated lazily.
Actions Return a value reduce collect count countByKey countByValue countApprox ! foreach saveAsSequenceFile saveAsTextFile first take(n) takeSample toArray Invoking an Action will cause all previous Transformations to be evaluated.
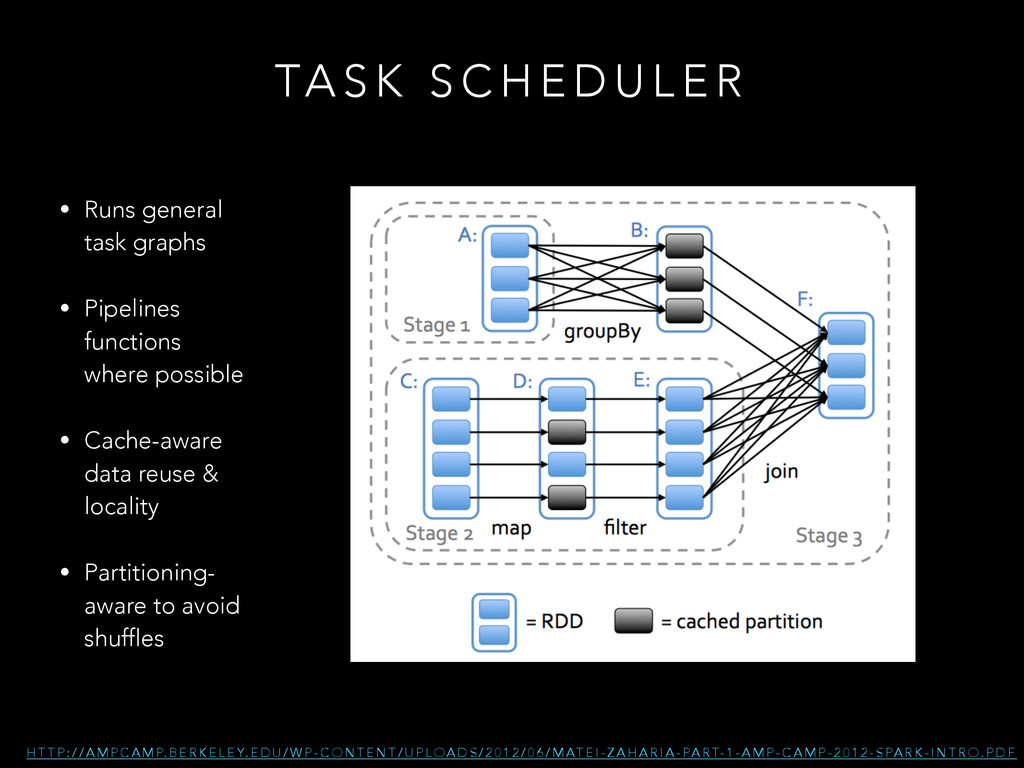
E R H T T P : / / A M P C A M P. B E R K E L E Y. E D U / W P - C O N T E N T / U P L O A D S / 2 0 1 2 / 0 6 / M AT E I - Z A H A R I A - PA R T- 1 - A M P - C A M P - 2 0 1 2 - S PA R K - I N T R O . P D F • Runs general task graphs ! • Pipelines functions where possible • Cache-aware data reuse & locality ! • Partitioning- aware to avoid shuffles
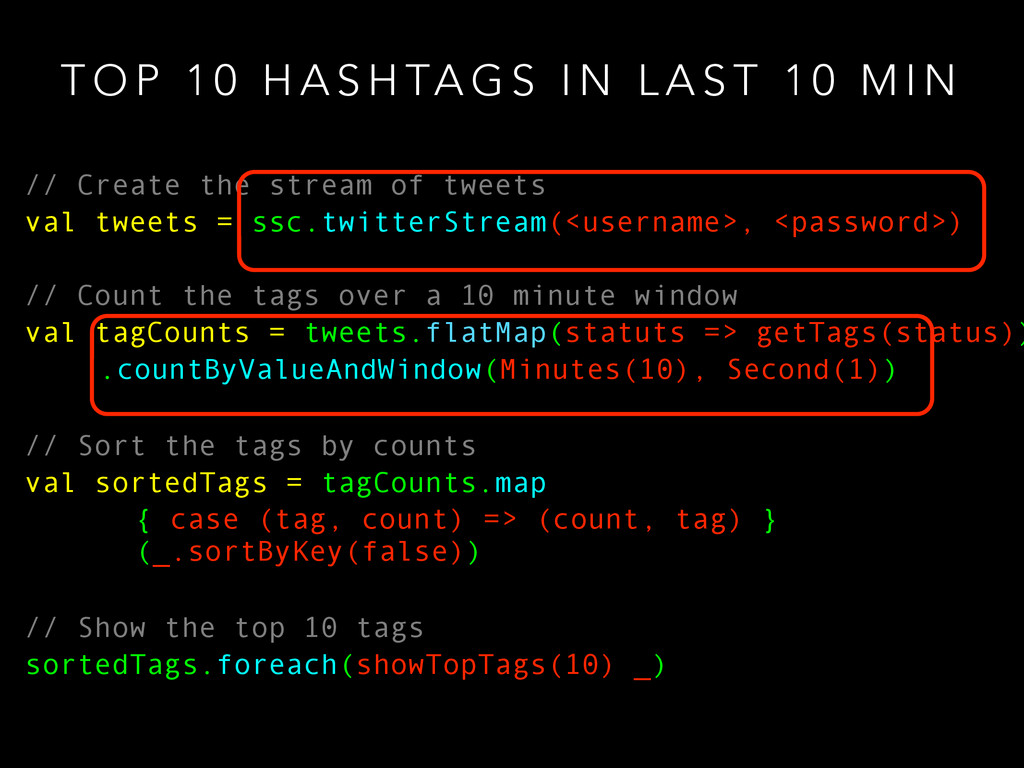
G S I N L A S T 1 0 M I N // Create the stream of tweets val tweets = ssc.twitterStream(<username>, <password>) // Count the tags over a 10 minute window val tagCounts = tweets.flatMap(statuts => getTags(status)) .countByValueAndWindow(Minutes(10), Second(1)) // Sort the tags by counts val sortedTags = tagCounts.map { case (tag, count) => (count, tag) } (_.sortByKey(false)) // Show the top 10 tags sortedTags.foreach(showTopTags(10) _)
jblas & gfortran. Python supports NumPy. • Growing number of algorithms: SVM, ALS, Naive Bayes, K-Means, Linear & Logistic Regression. (SVD/PCA, CART, L-BGFS coming in 1.x) M L L I B
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![T H A N K S ! [email protected] @stevendborrelli](https://files.speakerdeck.com/presentations/774f74a0ca22013177971a6d5d688b8e/slide_33.jpg){kind=link}