Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介201902_Effectively Crowdsourcing Radiology ...
Search
T.Tada
February 19, 2019
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介201902_Effectively Crowdsourcing Radiology Report Annotations
T.Tada
February 19, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
Other Decks in Technology
See All in Technology
「軸足」は 固定しなくていい - 熱量と強みで描く、しなやかなキャリアの形
kakehashi
PRO
1
280
時期が悪い!それでもRaspberry Piを買って遊んで活用するには / 20260627-osc26do-rpi-jikigawarui
akkiesoft
1
890
「ビジネスがわかるエンジニア」とは何か?
ryooob
0
350
「勝手に広まる」人気 AI エージェントを爆速で作ろう!(AWS Summit Japan 2026講演資料)
minorun365
PRO
10
2.6k
螺旋型キャリアの生存戦略 / kinoko-conf2026
rakus_dev
1
1.2k
[チョークトーク資料]AWS DevOps Agent を使いこなす / AWS Dev Ops Agent Chalk Talk AWS Summit Japan 2026
kinunori
4
800
AIAU_UMEMOGU_ninomiya_slide
ninomiya_ii
0
280
感情と身体を置き去りにしない、エンジニアの生きのこり方 ──いまから、ここから「自分の状態」を扱うという選択
saorimurooka
0
360
そこにあるから地図ができる~位置を示す"モノ"を愉しむ~ - Interface 2026年6月号GPS特集オフ会 / interface_202606_GPS_offline
sakaik
1
110
Deep Data Security 機能解説
oracle4engineer
PRO
2
230
トークン最適化のためのユーザーストーリー分析 / User Story Analysis for Token Optimization
oomatomo
0
130
Flow 不死:AI 時代 DevOps 的不變本質
cheng_wei_chen
2
550
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
210
Building an army of robots
kneath
306
46k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
The SEO identity crisis: Don't let AI make you average
varn
0
500
GitHub's CSS Performance
jonrohan
1033
470k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Odyssey Design
rkendrick25
PRO
2
710
Speed Design
sergeychernyshev
33
1.9k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.5k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Transcript
- 文献紹介 2019/2/19 - Effectively Crowdsourcing Radiology Report Annotations 長岡技術科学大学
自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
Abstract ・ラベリング作業に医療分野の知識が必要な場合、クラウドソーシングは有用か ・エキスパート注釈とクラウドソーシング注釈で訓練された同じモデルで比較 ・両手法で作成されたデータセットは同じくらい効果的であることがわかった ・クラウドソーシングによるラベルの一部を除外することで、モデルの精度が向上 3
Introduction ・多くのテキスト分類手法は、大量のラベル付きトレーニングデータが必要 →質の高いトレーニングデータを大量に収集することは、時間と費用がかかる ・アノテーションにドメイン知識を必要とする場合、クラウドソーシングはどれほど有用か ・放射線科レポートを正常または異常として分類するためのモデルに対する有用性 ・専門家とクラウドソーシングされたデータセットで分類モデルのパフォーマンスを比較 4
Methods and Data Collection ・Annotating radiology report reports ・Data collection
-Gold standard labels: expert annotations -Crowdsourced annotations -Weighting the workers’ votes ・Building a classification model 5
Methods and Data Collection -Annotating radiology report reports- Audiological and
Genetic Database(AudGenDB)(CHOP,06) 側頭骨の16,000以上の放射線画像 関連するテキストレポート を格納する医学研究データベース レポートにはラベルが付いていない 13の解剖学的構造(例えば、蝸牛、中耳のあぶみ骨など)のそれぞれに関して、 各報告を正常または異常として分類するモデルを構築することが目的 AudGenDBの放射線医学レポートから抽出された10,880のラベルなしの文章を使用 6
Methods and Data Collection ・Annotating radiology report reports ・Data collection
-Gold standard labels: expert annotations -Crowdsourced annotations -Weighting the workers’ votes ・Building a classification model 7
Methods and Data Collection -Data collection- Gold standard labels: expert annotations
・2人の専門家が、ランダムに選んだ340文に注釈を付与 -専門家らの注釈は、ほぼ一致 0.848(Fleiss Kappa / Krippendorffs Alpha) ・ゴールドスタンダードのデータセット -ラベルに一致した323文 -正常:165文(51.1%),異常:158(48.9%) 8
Methods and Data Collection -Data collection- Crowdsourced annotations- ・医療や放射線学の専門知識についてワーカーのスクリーニングを行わない ・以下の2点を各文に対して付与 -文が正常な観察か異常な観察か
-選択においての自信(非常に自信がある、多少自信がある、自信がない) ・各文少なくとも2人の作業者を設定 -文章ラベルが一致しなかった場合は、75%の一致率に達するまで注釈を収集し続けた -56人のユニークなワーカーにより717文を追加で収集 9
Methods and Data Collection ・以下2点をワーカーに提供 -「強調表示された文章を耳の特定の構成要素の正常または異常な観察を説明するもの として分類する」という簡単な指示 -正常および異常な文の例(ゴールドスタンダードの少なくとも1つの文を使用) 10 Methods
and Data Collection -Data collection- Crowdsourced annotations-
Methods and Data Collection ・ワーカーの個々の注釈を各センテンスの単一のクラウドソーシングラベルに統合 -各センテンスの注釈をワーカーの注釈の加重平均とする:Snowら(2008)を参考 ・ワーカーにより注釈へ重みを付け: -より正確なワーカーの注釈を高く評価 -より多くの文を分類したワーカーの注釈を評価 11
Methods and Data Collection -Data collection- Weighting the workers’ votes
Methods and Data Collection ・クラウドソースデータが同様に文分類モデルを訓練するのに有用であるか -bag-of-ngram を使用して簡単な文分類モデルを構築 ・各文を901次元の特徴ベクトルとする -900次元: データセットでの頻度が上位500のunigram、上位300のbigram、上位100のtrigram
-901次元目:センテンストークンの数。 文章が正常か異常かを予測するためにL2正規化ロジスティック回帰を使用 12 Methods and Data Collection -Data collection- Building a classification model
Results ・Labeling performance and analysis ・Votes of confidence ・Using annotations
to train a classifier -Experts vs The Crowd -Increasing training instances -Incorporating confidence thresholds 13
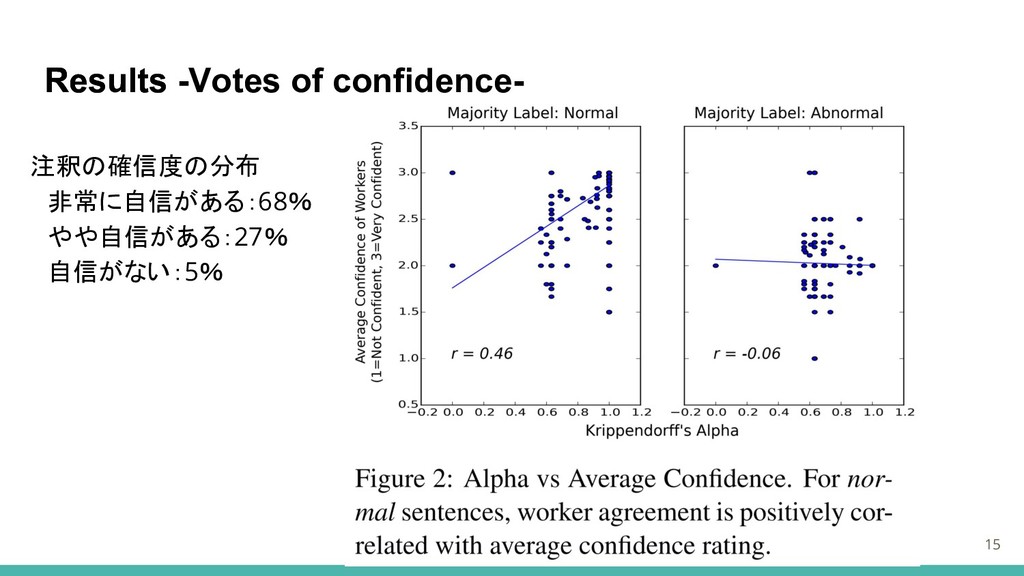
Results -Labeling performance and analysis- ・56人のユニークなワーカーはそれぞれ平均99.9文を分類(3〜462文) 平均的な分類の正確さは93.49%であり、これはワーカー間でも比較的一貫 平均を大幅に下回ったのは3人のみ ・2つの方法でクラウドソーシングされた注釈について調査 -Krippendorffs
Alpha→0.743 -カッパスコアを確認 →0.758 (文ごとに2つのラベルをランダムに100回サンプリングした平均) 専門家注釈者間の一致よりは低いが実質的に一致を示している(Landis and Koch、1977) 14
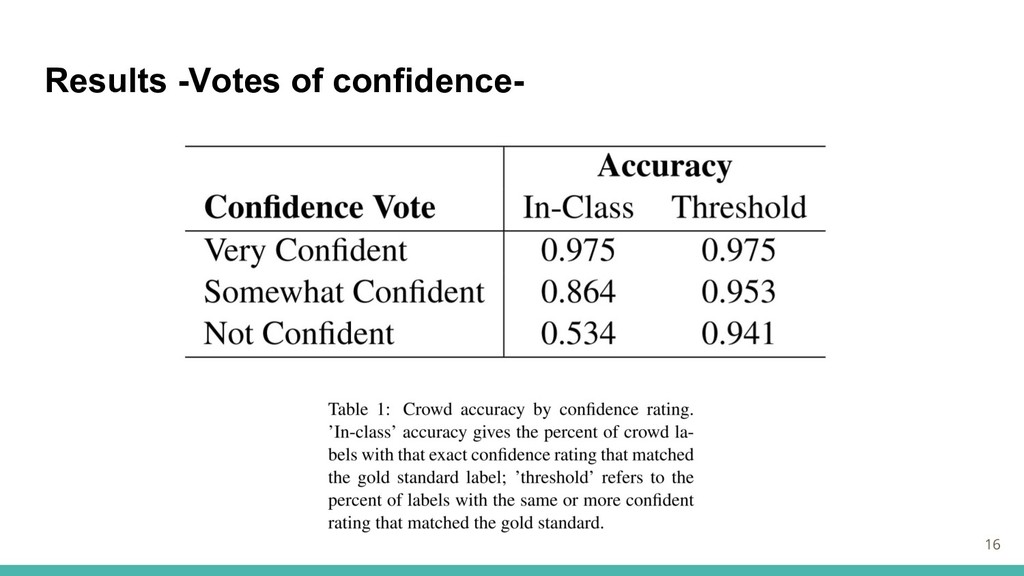
Results 15 Results -Votes of confidence- 注釈の確信度の分布 非常に自信がある:68% やや自信がある:27% 自信がない:5%
Results -Votes of confidence- 16
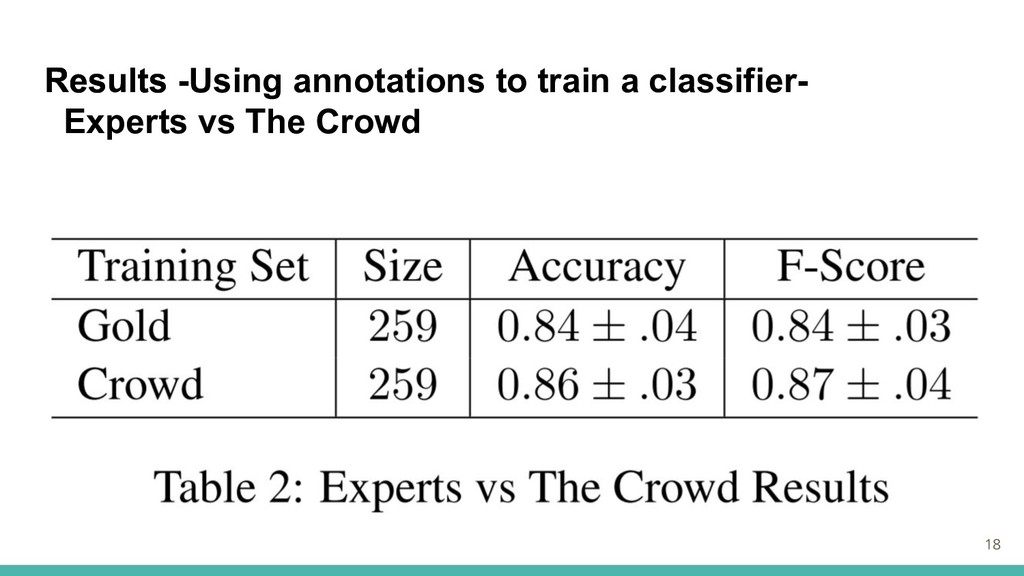
Results -Using annotations to train a classifier- Experts vs The
Crowd ・2つの方法で分類モデルをトレーニング。 -ゴールドスタンダードラベルのみを使用 -クラウドソーシングラベルのみを使用 各分類器は同数のトレーニングインスタンスを使用 ・ゴールドスタンダードデータセットを用いて5-fold cross validationで実験 -各検証に対して、等しいサイズのクラウドソースデータからトレーニングセットをランダム にサブサンプリング(約260)し、ゴールドスタンダードデータの検証部分に対して評価 17
Results 18 Results -Using annotations to train a classifier- Experts
vs The Crowd
Results -Using annotations to train a classifier- Increasing training instances
・クラウドワーカーの注釈の数を増やすことで分類モデルの精度を向上できるか ・各サイズごとに、トレーニングセットをランダムにサブサンプリング ・ゴールドスタンダードデータセット全体に対して評価 19
Results 20 Results -Using annotations to train a classifier- Increasing
training instances
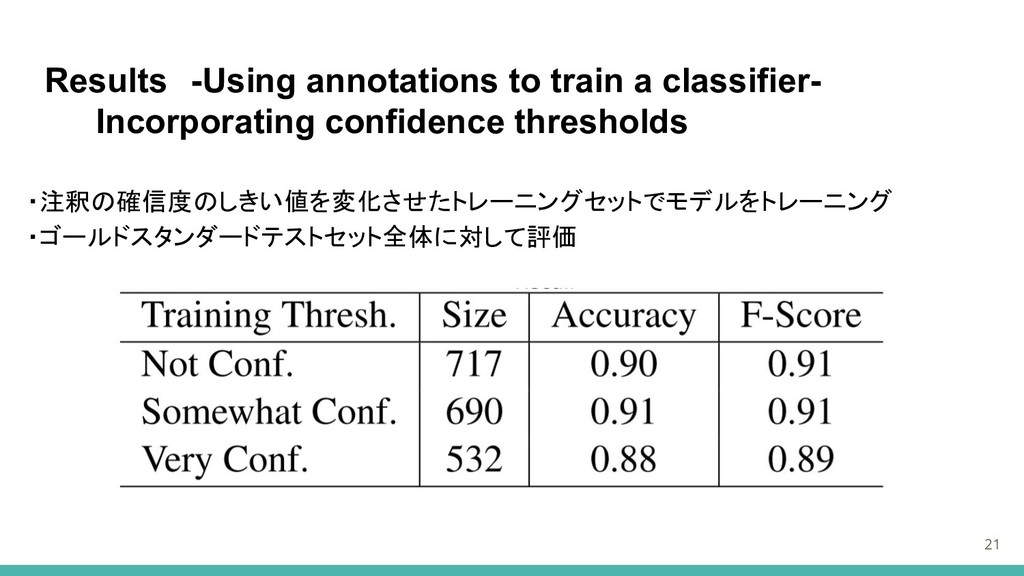
Results -Using annotations to train a classifier- Incorporating confidence thresholds
・注釈の確信度のしきい値を変化させたトレーニングセットでモデルをトレーニング ・ゴールドスタンダードテストセット全体に対して評価 21
Discussion / Conclusion ・クラウドソーシングを使用して特定の分野の知識を必要とするタスクの文ラベルを生成する ことが可能であることを示した ・クラウドソーシングの注釈に重みをつけてラベルを適用することによって、文分類子を訓練 する際に専門家のアノテーターによって生成されたものと同じくらい効果的である訓練データ セットを生成することができた ・個々のワーカーの確信度を取り入れることによって、データを追加収集することなく分類器 の精度をさらに向上させることができた
22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}