Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介201904_Biomedical Document Retrieval for Cl...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
T.Tada
April 23, 2019
Technology
95
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介201904_Biomedical Document Retrieval for Clinical Decision Support System
T.Tada
April 23, 2019
More Decks by T.Tada
See All by T.Tada
文献紹介_202002_Is artificial data useful for biomedical Natural Language Processing algorithms?
tad
0
75
文献紹介_202001_A Novel System for Extractive Clinical Note Summarization using EHR Data
tad
0
190
文献紹介_201912_Publicly Available Clinical BERT Embeddings
tad
0
180
文献紹介_201911_EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
tad
0
230
文献紹介_201910_Do Neural NLP Models Know Numbers? Probing Numeracy in Embeddings
tad
0
110
文献紹介_201909_Sentence Mover’s Similarity_ Automatic Evaluation for Multi-Sentence Texts
tad
0
170
文献紹介_201908_Medical Word Embeddings for Spanish_ Development and Evaluation
tad
0
73
文献紹介_201907_Is Word Segmentation Necessary for Deep Learning of Chinese Representations
tad
0
120
文献紹介_201906_Predicting Annotation Difficulty to Improve Task Routing and Model Performance for Biomedical Information Extraction
tad
0
110
Other Decks in Technology
See All in Technology
AI 不只幫你寫 Code: 當專案從 300 暴增到 1500, 我們如何撐住 DevOps
appleboy
0
280
初めてのDatabricks勉強会
taka_aki
2
180
秘密度ラベル初心者が第1歩でつまづかないための「設計・運用」ポイント
seafay
PRO
1
500
スタートアップにAmazon EKSは早すぎる? マルチプロダクト戦略を加速する Platform Engineeringの実践 / Is Amazon EKS Too Soon for Startups? Practical Platform Engineering to Accelerate a Multi-Product Strategy
elmodev09
1
1.9k
When Platform Engineering Meets GenAI
sucitw
0
200
自作お家AIエージェントスタックチャンFWで困っている所紹介
74th
0
130
螺旋型キャリアの生存戦略 / kinoko-conf2026
rakus_dev
1
1.2k
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
130
Hatena Engineer Seminar 37 jj1uzh
jj1uzh
0
150
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
370
AIをフル活用してオンコール機能のプロトタイプを2日で作った話 / Building an AI-Powered On-Call Prototype in Just Two Days
nari_ex
0
140
Flow 不死:AI 時代 DevOps 的不變本質
cheng_wei_chen
2
550
Featured
See All Featured
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
Designing Powerful Visuals for Engaging Learning
tmiket
1
430
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
850
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Test your architecture with Archunit
thirion
1
2.3k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Docker and Python
trallard
47
3.9k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
170
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
450
Transcript
- 文献紹介 2019/4/23 - Biomedical Document Retrieval for Clinical Decision
Support System 長岡技術科学大学 自然言語処理研究室 多田太郎
About the paper 2 Authors: Conference:
Abstract ・臨床意思決定支援システム(CDSS)のため、生物医学文献の検索に焦点を当てる ・クエリ拡張の統計的アプローチとNLPアプローチ ・順序学習問題として生物医学文書検索をモデル化 3
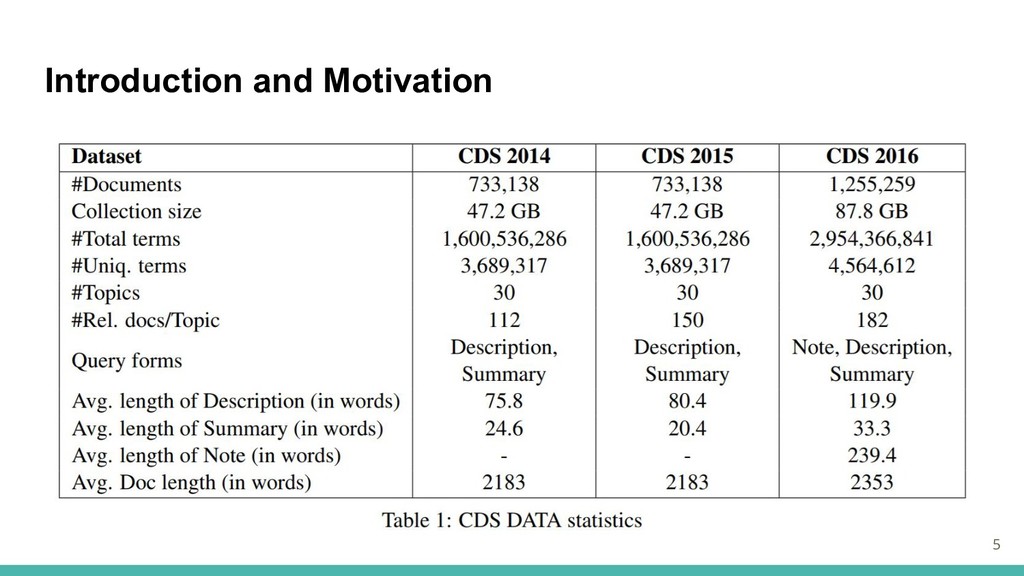
Introduction and Motivation ・毎年数千の生物医学分野の論文が発表されている ・これらは患者ケアのため、臨床決定支援システムのコレクションとして使用できる ・データセット:Clinical Decision Support(CDS)トラック PMC(PubMed Central)からの何百万もの全文生物医学論文を含む
患者の症例報告に関連する生物医学論文の検索に焦点を当てている 患者の病状、病歴、症状、実施された検査、治療などが記述 ・与えられたクエリ(症例報告)に関して、主な問題は利用可能なコレクションから関連する 文書を見つけランク付けすること 4
Introduction and Motivation 5
Query Reformulation for Biomedical Document Retrieval 統計的およびNLPベースのアプローチを提案 ・Automatic Query Expansion
With Pseudo Relevance Feedback & Relevance Feedback ・Feedback Document Discovery for Query Reformulation ・UMLS Concepts Based Query Reformulation 6
Query Reformulation for Biomedical Document Retrieval 統計的およびNLPベースのアプローチを提案 ・Automatic Query Expansion
With Pseudo Relevance Feedback & Relevance Feedback ・Feedback Document Discovery for Query Reformulation ・UMLS Concepts Based Query Reformulation 7
Automatic Query Expansion With Pseudo Relevance Feedback & Relevance Feedback
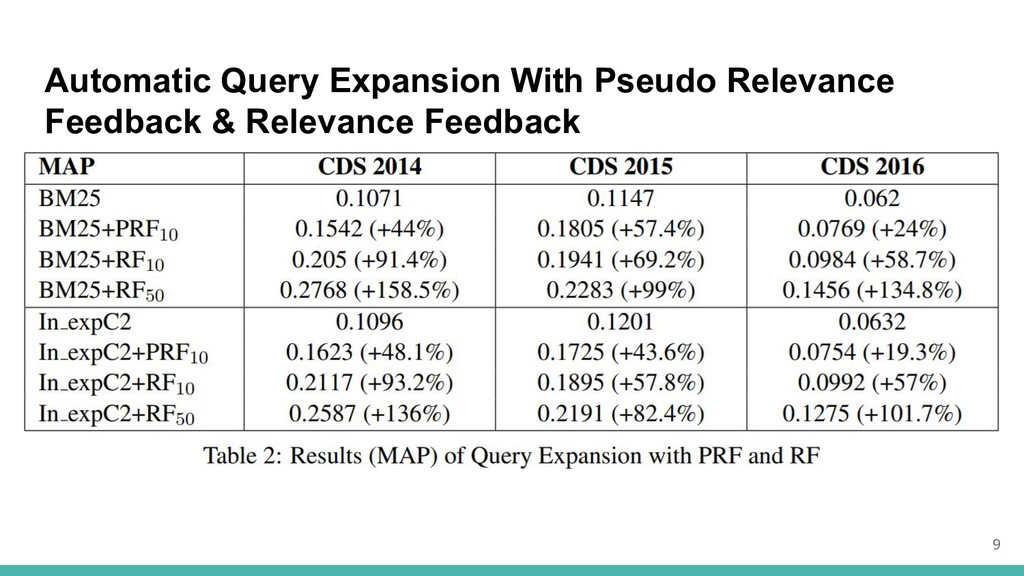
生物医学的ドメインに対するクエリ拡張ベースのアプローチは、クエリー拡張なしの検索と比 較してより良い結果(Sankhavara et al.,2014) ・関連性フィードバック(RF) 検索された上位の文書から人手により関連する文書を選択 ・擬似関連性フィードバック(PRF) 検索されたトップ文書に関連性があると仮定し、フィードバック文書として使用 Terrier IR Plateform 3(Ounis et al.,2005)で実装されたモデルを使用 8
Automatic Query Expansion With Pseudo Relevance Feedback & Relevance Feedback
9
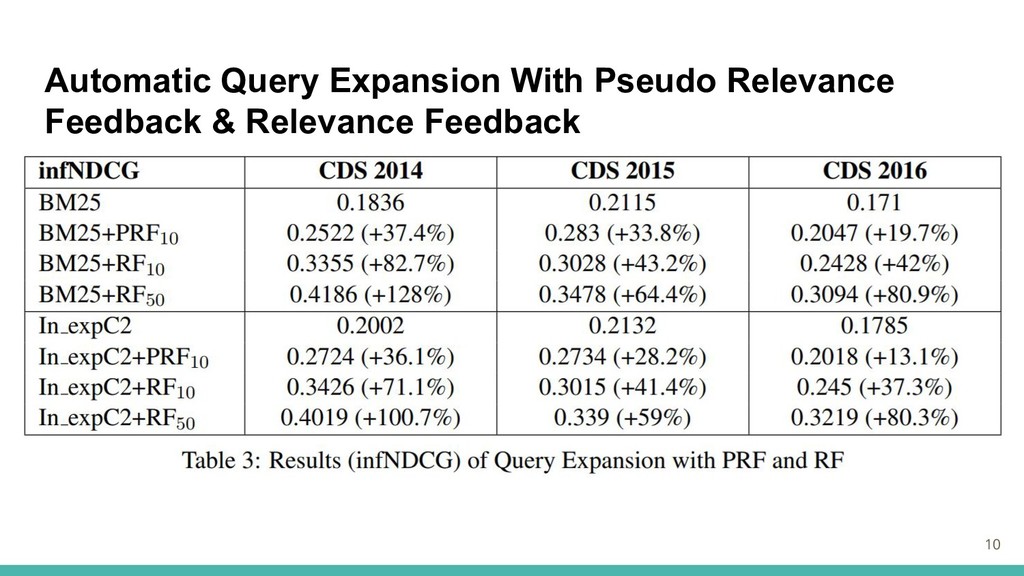
Automatic Query Expansion With Pseudo Relevance Feedback & Relevance Feedback
10
Query Reformulation for Biomedical Document Retrieval 統計的およびNLPベースのアプローチを提案 ・Automatic Query Expansion
With Pseudo Relevance Feedback & Relevance Feedback ・Feedback Document Discovery for Query Reformulation ・UMLS Concepts Based Query Reformulation 11
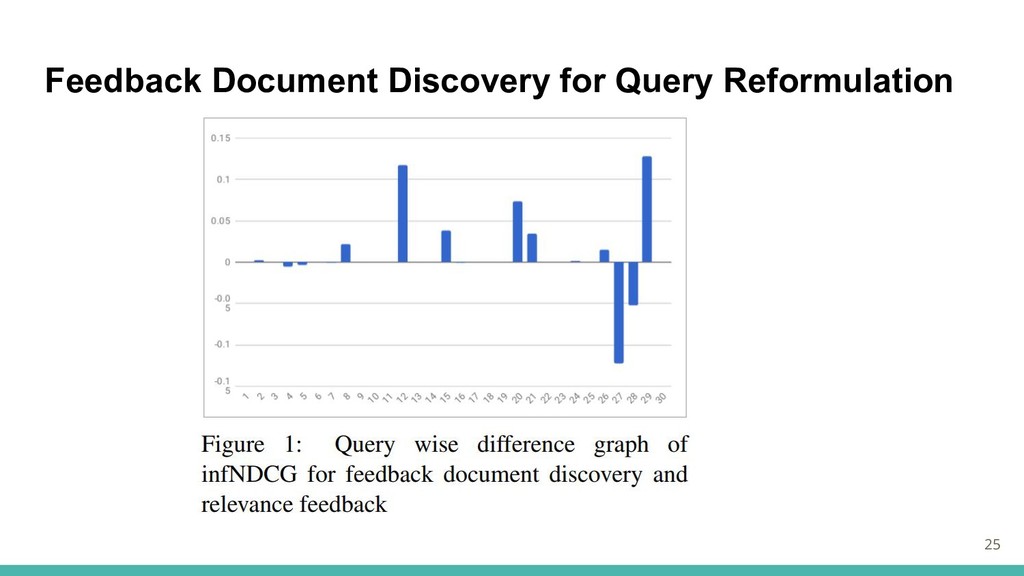
Feedback Document Discovery for Query Reformulation フィードバック文書発見ベースのクエリ拡張 →検索結果が上位の文書からクエリ拡張に関連する文書を識別することを学習 少量の人手の判断により、他のドキュメントの疑似判断を学ぶことが目的 以下2つの方法で実験
1. classification ベース(nearest neighbour,neural net) 2. classification + clustering ベース(上記+ k-means ) 12
Feedback Document Discovery for Query Reformulation フィードバック文書発見ベースのクエリ拡張 上位の検索された文書からクエリ拡張に関連する文書を識別することを学習 少量の人手の判断により、他のドキュメントの疑似判断を学ぶことが目的 1.
classification ベース 2. classification + clustering ベース 13 フィードバック文書の中に人手のアノテーションがある場合は、トレーニングデータとする 文書は以下で表される bag-of-words、TF-IDFスコア、人間アノテーションからのクラス 検索されたフィードバック文書について関連性を予測
Feedback Document Discovery for Query Reformulation フィードバック文書発見ベースのクエリ拡張 上位の検索された文書からクエリ拡張に関連する文書を識別することを学習 少量の人手の判断により、他のドキュメントの疑似判断を学ぶことが目的 1.
classification ベース 2. classification + clustering ベース 14 1.classificationベースのアプローチと同様の方法で分類 2.関連性予測クラスを基にクラスタリング(K平均法: k=2) →関連するものからより関連性の低いドキュメントを除外する
Feedback Document Discovery for Query Reformulation CliNER tool (Boag et
al., 2015)を使用 トレーニング: ’discharge summaries’ とそれらの ’concept annotations’ 識別対象: CDS文書の’problem’, ’test’ and ’treatment’ 方法 1. 予測した上位50の文書とそれらの対応する関連文書を使用しトレーニング 2. 予測した上位200の文書から関連するものを使用しクエリ拡張 15
Feedback Document Discovery for Query Reformulation 16
Query Reformulation for Biomedical Document Retrieval 統計的およびNLPベースのアプローチを提案 ・Automatic Query Expansion
With Pseudo Relevance Feedback & Relevance Feedback ・Feedback Document Discovery for Query Reformulation ・UMLS Concepts Based Query Reformulation 17
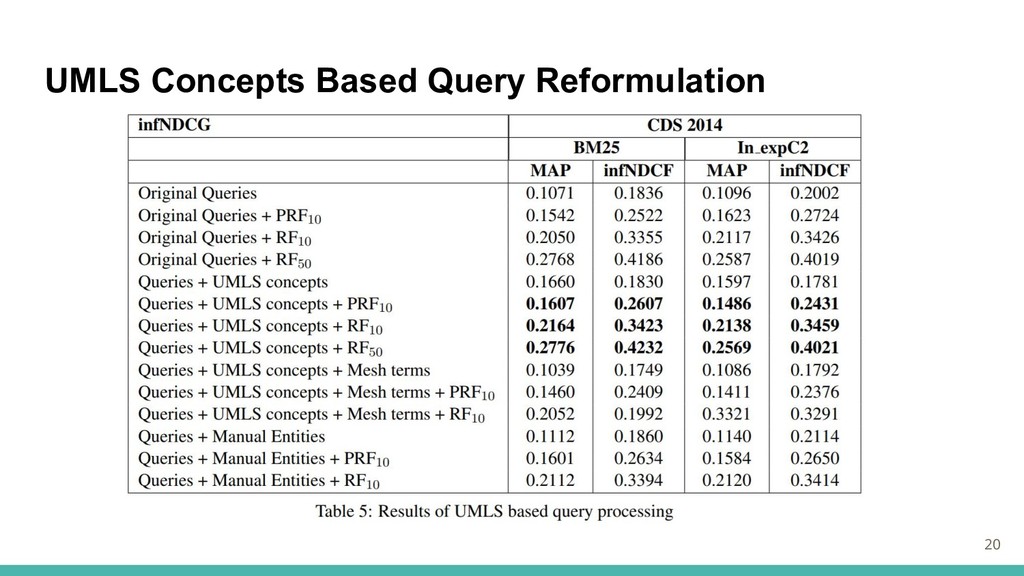
UMLS Concepts Based Query Reformulation ・医療分野の知識を、IRシステムにおけるクエリ拡張プロセスに組み込む ・医学言語システム(UMLS)(Bodenreider,2004年)医学分野のメタシソーラスを使用 →国立医学図書館(NLM)によって維持される →100以上の辞書、用語集、およびオントロジーを統合した包括的なリソース
18
UMLS Concepts Based Query Reformulation 次の3つのQuery Reformulation実験を行う 1. クエリテキストからUMLSの概念を識別し、クエリと共に使用 2. MeSH(Medical Subject
Heading)の用語も識別し、クエリで使用 →MeSHはUMLSの階層的に構成された語彙 3. 手動で識別し、クエリと共に使用 19
UMLS Concepts Based Query Reformulation 20
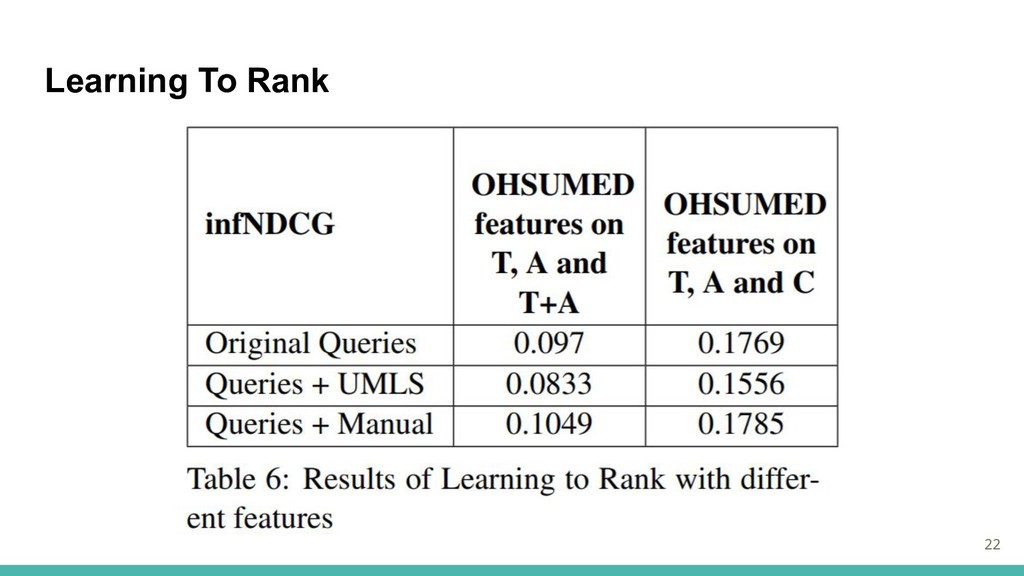
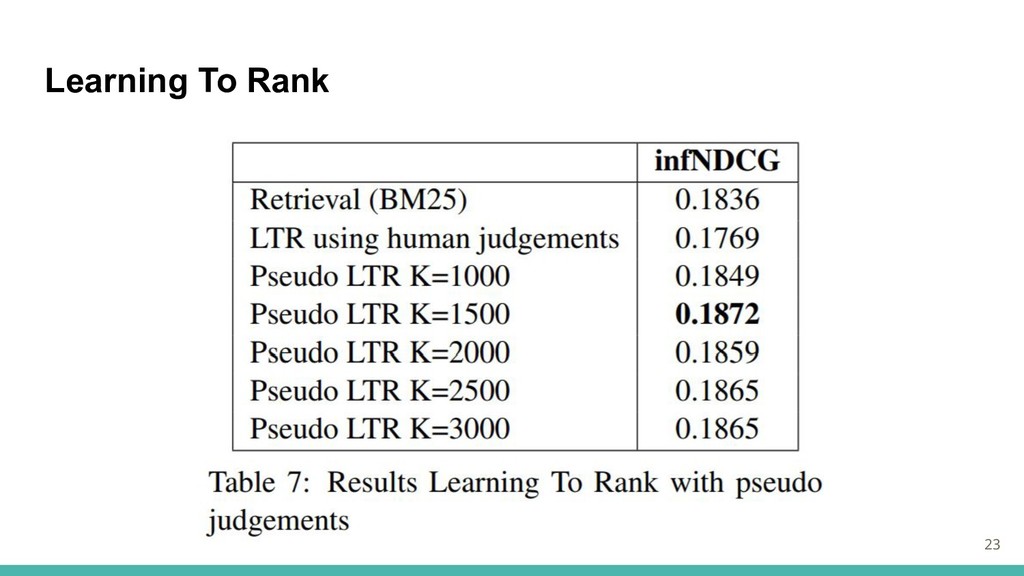
Learning To Rank ・OHSUMED LETOR(Qin et al.,2010)を参考にLTRフレームワークを適用 →クエリとそれに対するドキュメントを関連度と共にトレーニング ・文書プールが大きいため、各クエリごとに上位25の文書(BM25による)を特徴抽出に使用 ・オリジナルのクエリ、UMLSによるクエリ、手動で識別された医療概念によるクエリで実験
・手作業の必要性を克服するために、擬似的な特徴を使った実験も行う →k個のトレーニング文書 上位k / 2の文書を関連性あり、下位k / 2個の文書が関連性なし 21
Learning To Rank 22
Learning To Rank 23
Conclusion ・臨床意思決定支援システムのための生物医学文献検索の基礎となる研究を提示 ・生物医学文書検索でのクエリ拡張に基づく情報検索フレームワークの有用性を示した ・標準的なIRフレームワークPRFとRFは、臨床意思決定支援システムで十分に機能する ・UMLSのコンセプトを使った検索のための初期フレームワークも結果の改善を示した 24
Feedback Document Discovery for Query Reformulation 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}