Language Technology Lab DTAL, University of Cambridge 会議: Proceedings of the 15th Workshop on Biomedical Natural Language Processing, pages 166–174,2016 Association for Computational Linguistics
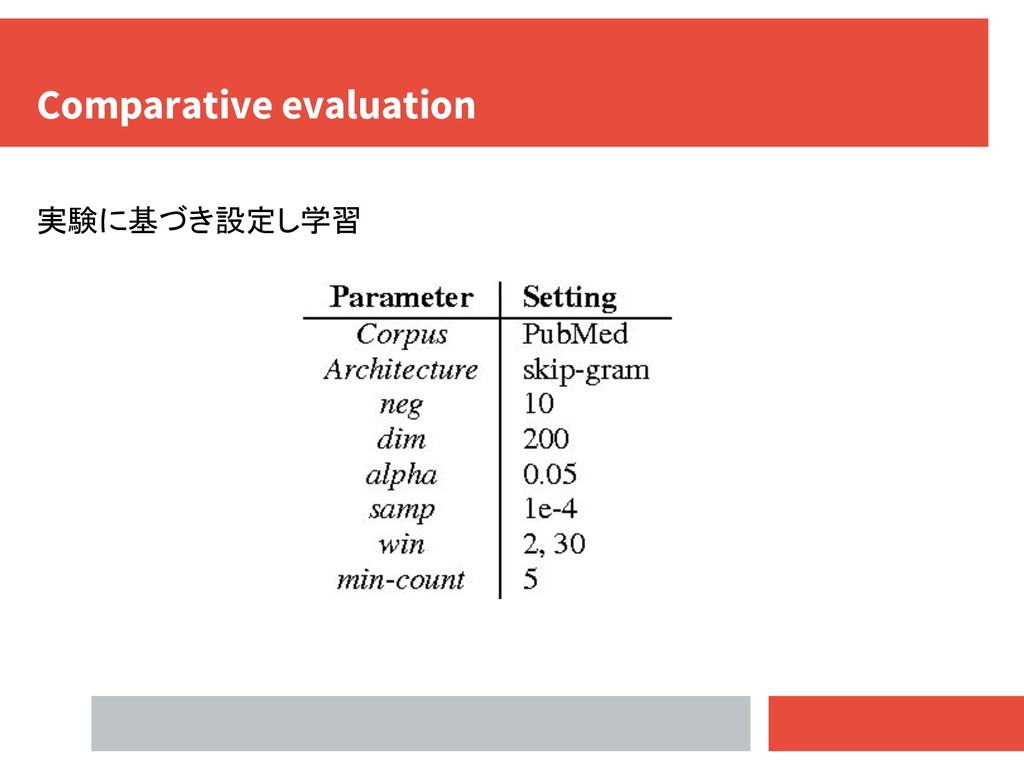
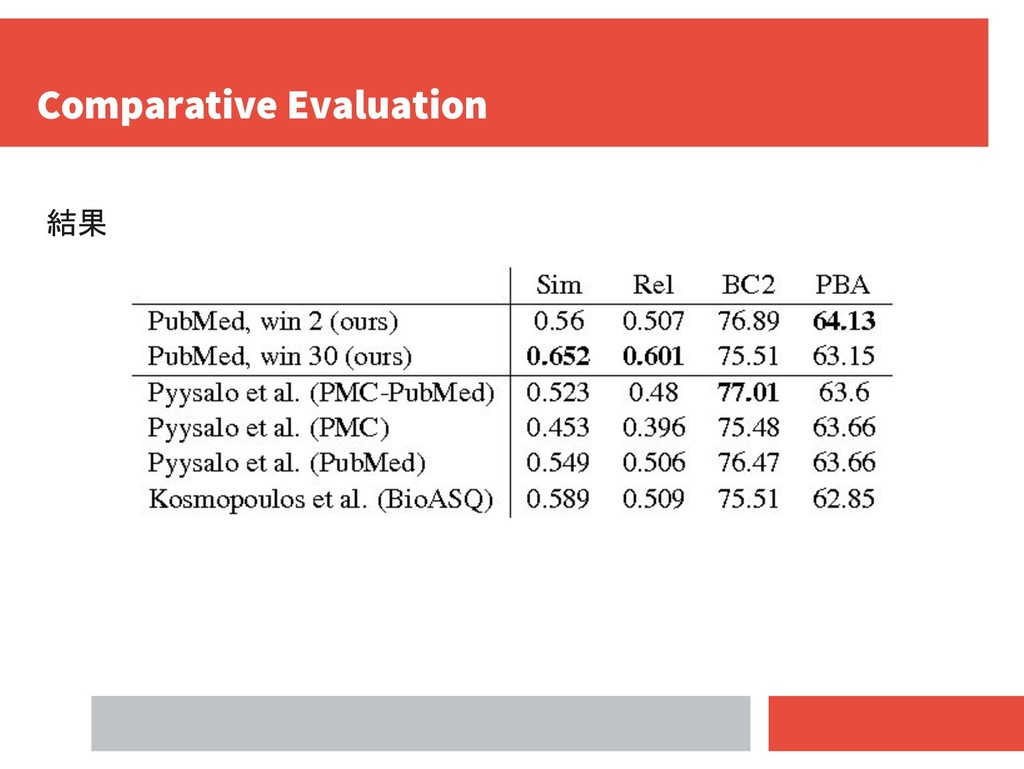
UMNSRS-Rel : 587 word pairs (Pakhomov et al.,2010) 外部評価 the BioCreative II Gene Mention task corpus (BC2) (Smith et al.,2008) the JNLPBA corpus (PBA) (Kim et al.,2004) Biomedical 固有名に手作業でアノテーションしたPubMedからの約2万文
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}