Le transfert de style est une tâche à part entière : comprendre et extraire le style d'une œuvre d'art pour l'appliquer à une photo sans modifier son contenu sémantique (objets présents dans la scène).
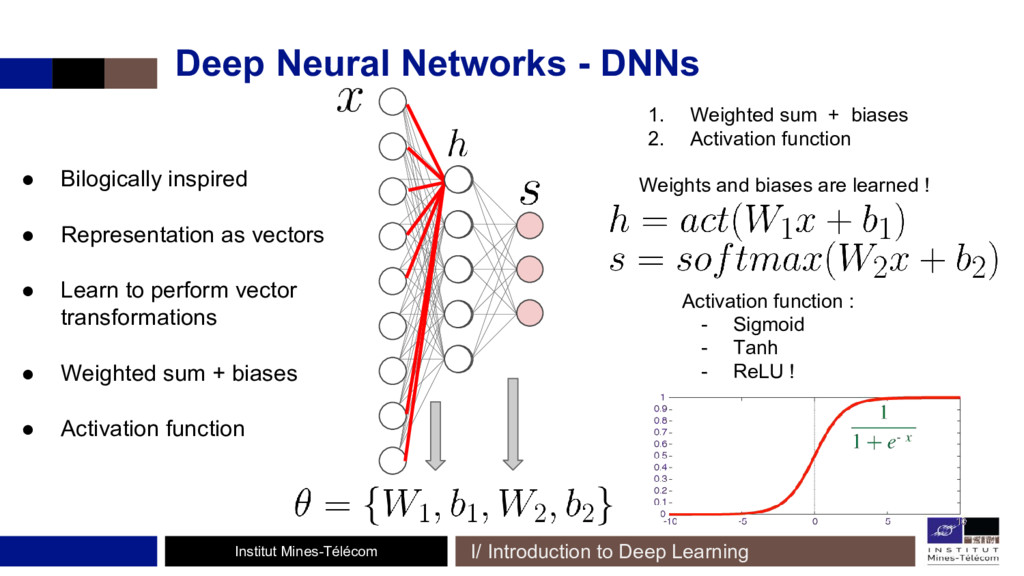
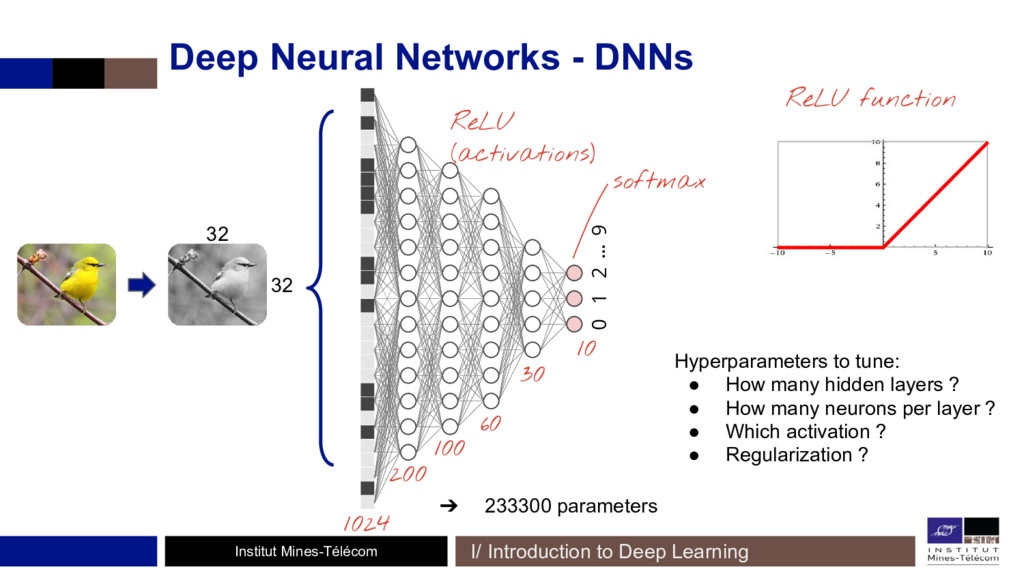
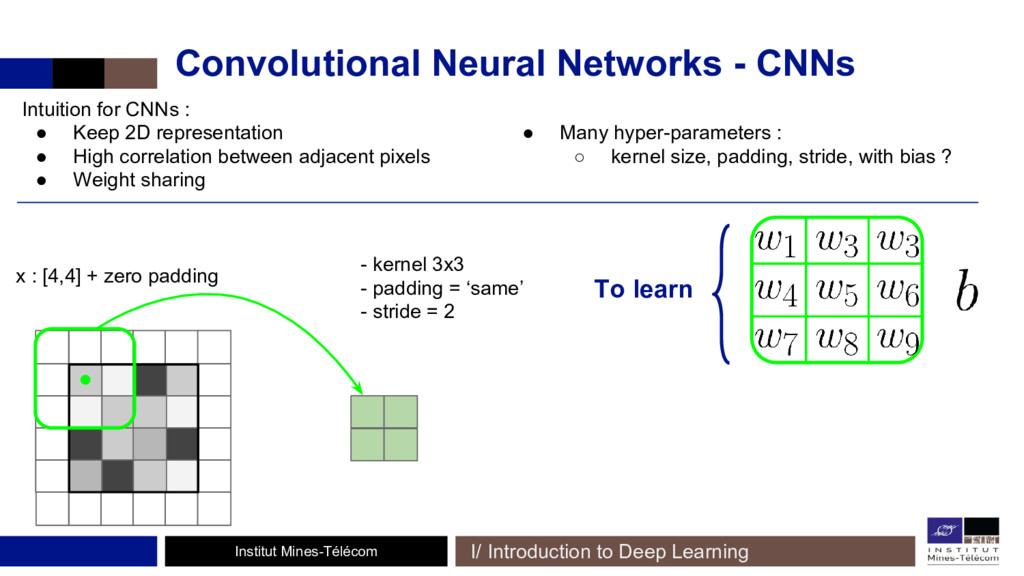
Depuis 2015, des méthodes à bases de réseaux de neurones convolutifs (CNNs) se sont mis à surpasser les précédentes techniques. Des CNNs entraînés pour la classification d'images permettent de réaliser cette opération, en définissant une fonction de coût (ou d'erreur) spécifique à la reconnaissance du style et du contenu! Un réseau de neurones sert alors de support à l'entraînement d'autres réseaux.
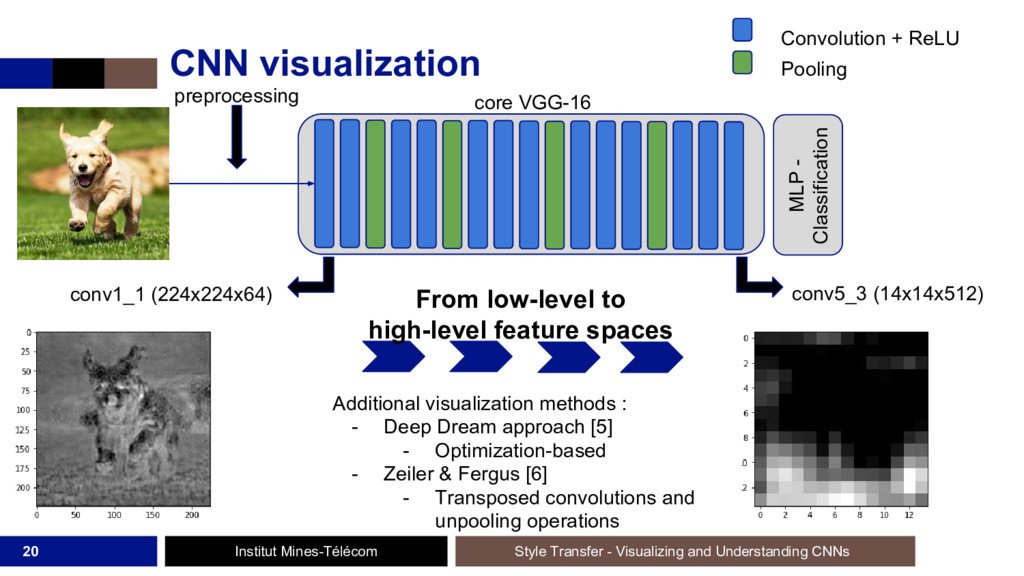
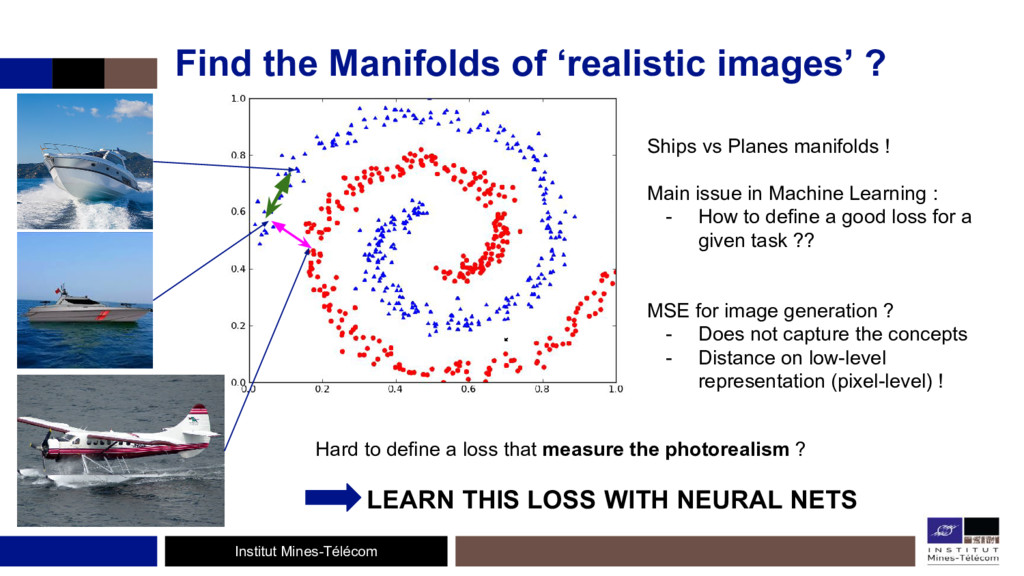
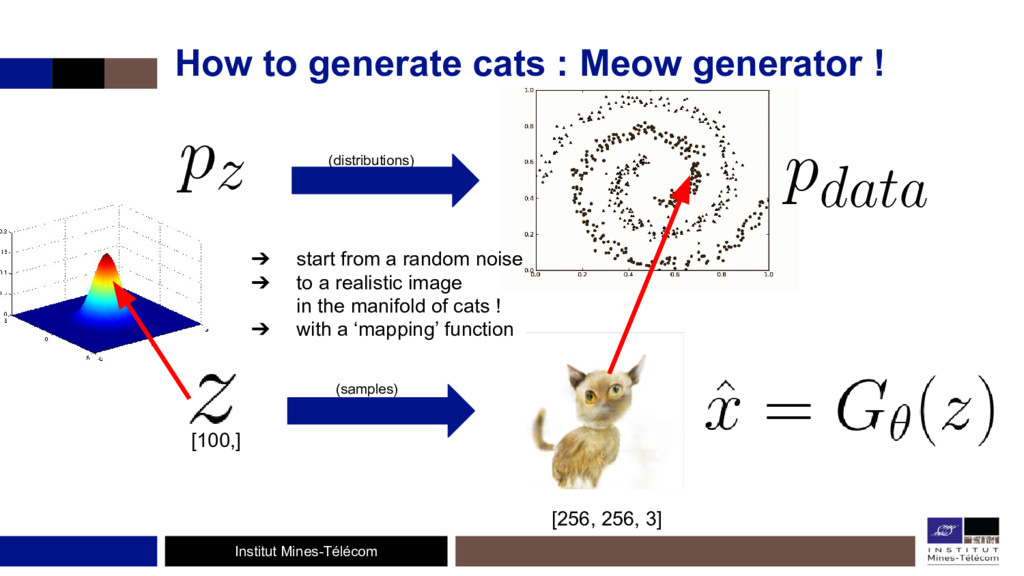
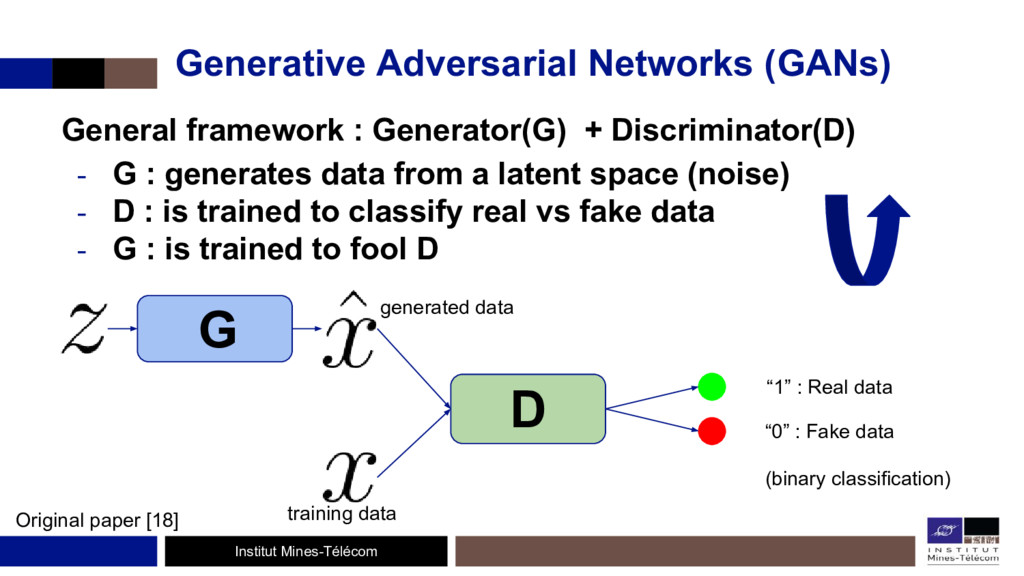
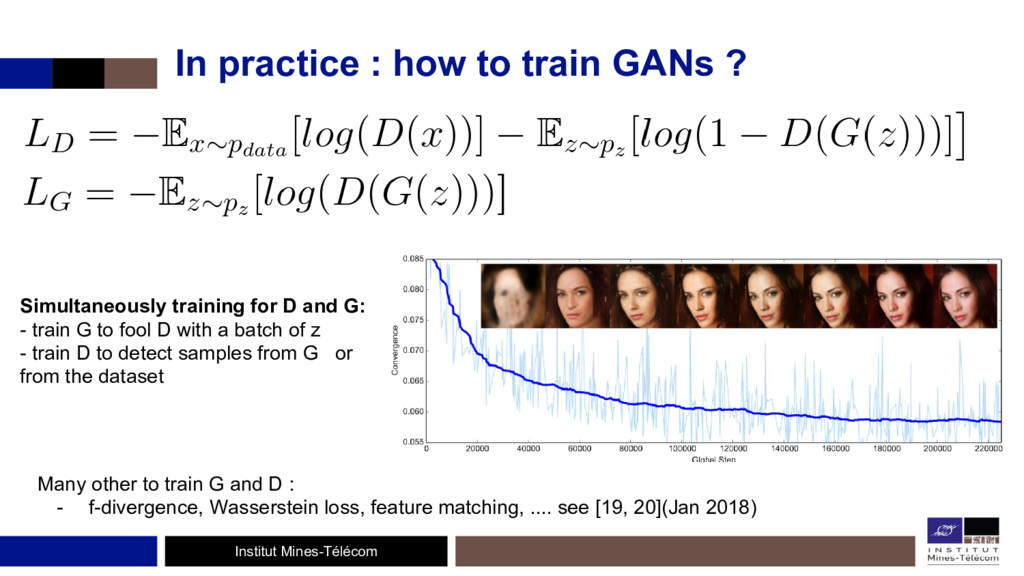
L'étude de ces algorithmes permet de bien comprendre les réseaux de neurones, de voir ce qu'il se passe à l'intérieur et de se défaire l'effet 'black-box' des CNNs. D'un autre côté, les Generative Adversarial Networks (GANs) forment un framework générique où deux réseaux de neurones, un générateur et un discriminateur, s'entraînent en même temps, de façon compétitive: le discriminateur cherchant à faire la différence entre des images réelles (provenant d'un dataset) et des images produites par le générateur, ce dernier voulant ensuite tromper le discriminateur.
Le discriminateur se comporte comme une fonction d'erreur 'entraînable' qui oblige le générateur à produire des images réalistes. Cette fonction de coût peut très bien s'ajouter à d'autres fonctions de coûts.
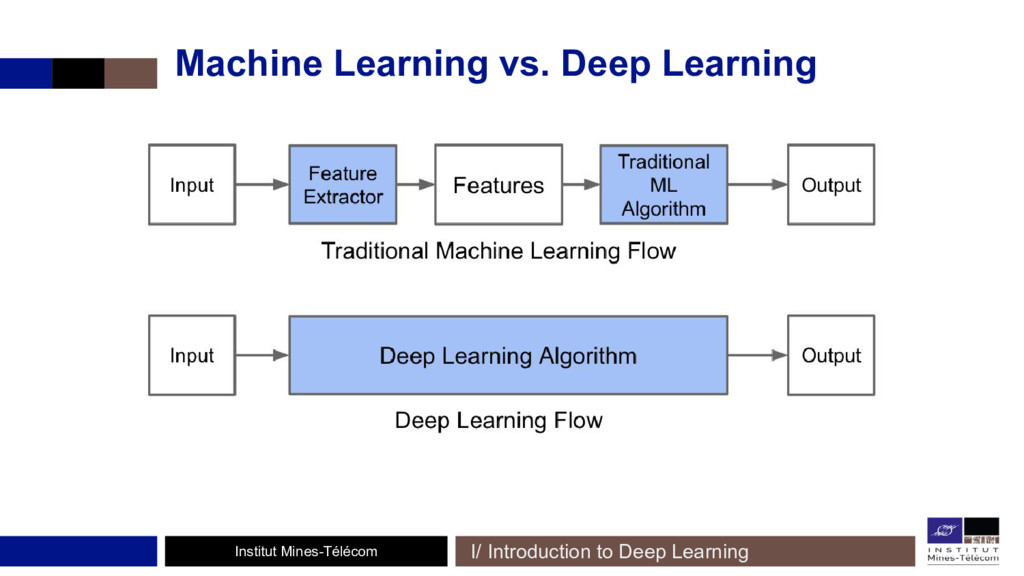
L'usage des GANs a permis d'obtenir de meilleurs résultats dans de nombreuses tâches où il est question de génération d'images: synthèse d'images, super-résolution, image-to-image translation, transfert de style, et beaucoup d'autres! Les GANs permettent aussi de faire du pré-apprentissage non-supervisé, pour obtenir de meilleurs résultats en classification d'images, même avec peu de données labellisées. En début de présentation, un rappel sera fait sur "Machine Learning vs Deep Learning" et les CNNs.
Bio : Julien Guillaumin est étudiant à Télécom Bretagne (Brest) en traitement d’images, Kaggler et MOOC friendly
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Institut Mines-Télécom Deep Network : VGG-16 [1] ▪ Simple :](https://files.speakerdeck.com/presentations/e172a83185494589b9478901fda85c64/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Institut Mines-Télécom Feed-forward method [10, 11] 33 Style Transfer -](https://files.speakerdeck.com/presentations/e172a83185494589b9478901fda85c64/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Institut Mines-Télécom Some “generative” tasks Source :https://phillipi.github.io/pix2pix/ Paper [17]](https://files.speakerdeck.com/presentations/e172a83185494589b9478901fda85c64/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Institut Mines-Télécom References (1/2) [1] : K. Simonyan, A. Zisserman](https://files.speakerdeck.com/presentations/e172a83185494589b9478901fda85c64/slide_61.jpg){kind=link}
![Institut Mines-Télécom References (2/2) [17] : P Isola et al](https://files.speakerdeck.com/presentations/e172a83185494589b9478901fda85c64/slide_62.jpg){kind=link}