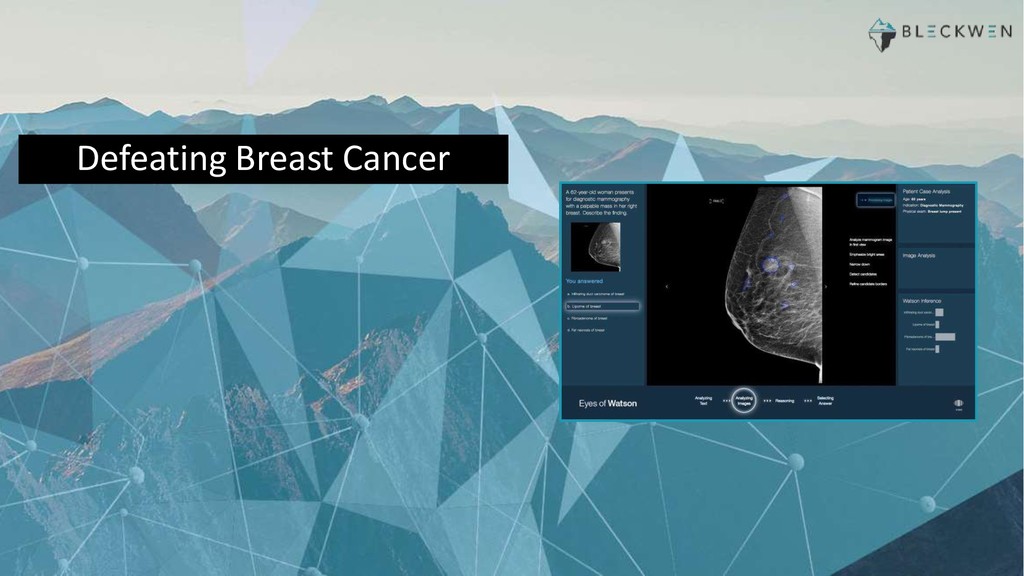
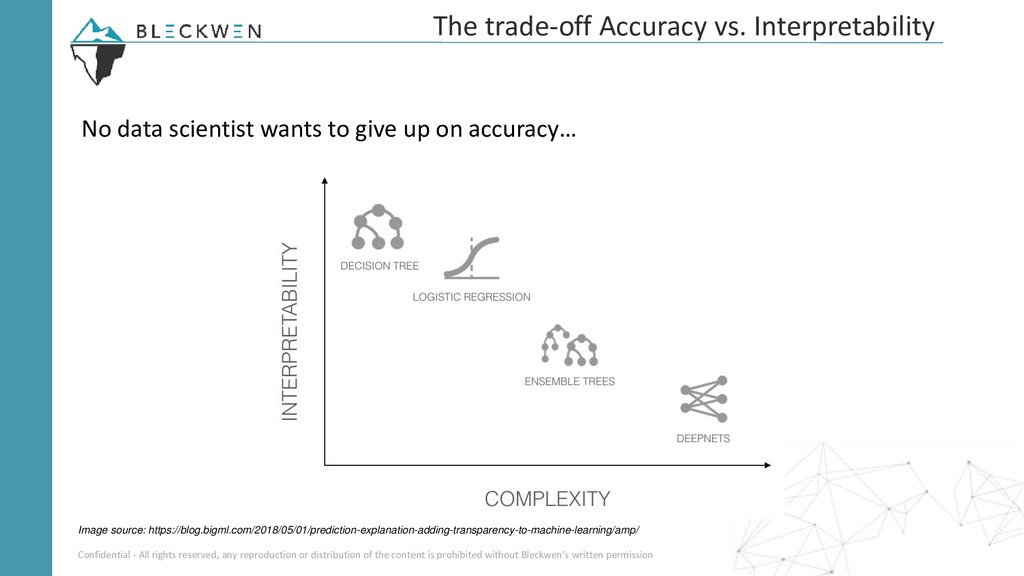
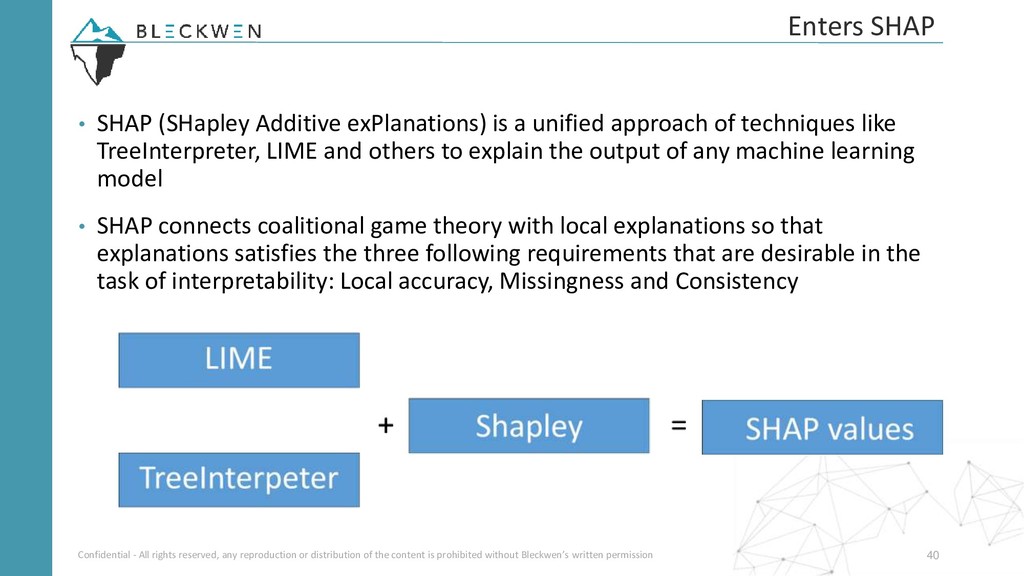
Les applications du machine learning dans certains secteurs réglementés (banque, assurance, médicale etc.) restent souvent cantonnées aux modèles linéaires ou à arbres compte tenu de leur capacité à produire des décisions relativement faciles à expliquer à un analyste métier. Récemment, des nouvelles techniques permettant d’expliquer les résultats produits par des modèles black-box ont vu le jour et attirent de plus en plus l’intérêt de la communauté data science et de l'industrie. En effet, il est désormais possible d’utiliser des modèles très performants comme XGBoost ou Deep learning sans sacrifier l’explication du modèle.
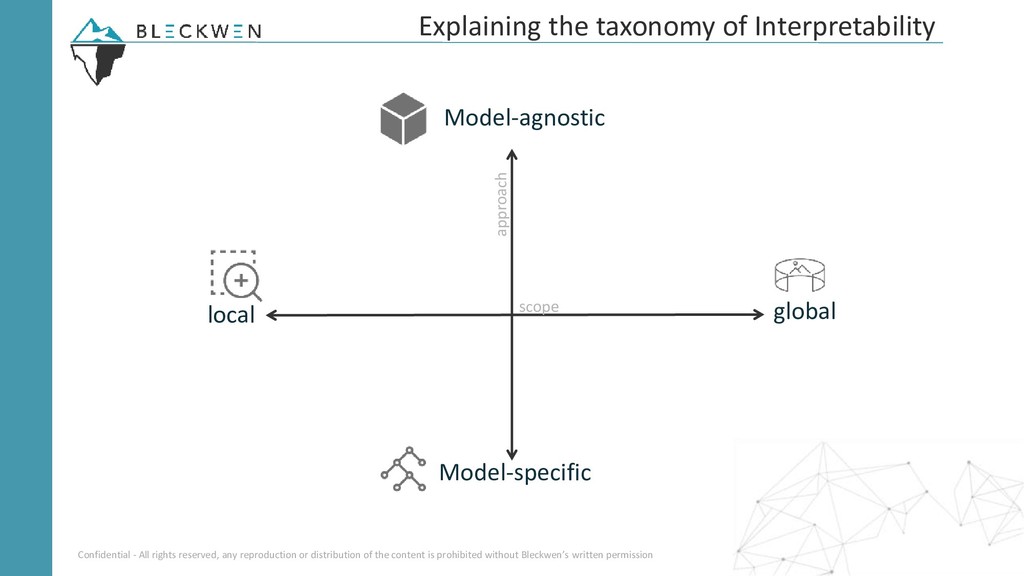
Leonardo Noleto, data scientist chez Bleckwen, nous fera découvrir le fleurissant et passionnant domaine de l'interprétabilité des modèles de machine learning. Il fera un tour d'horizon des différentes approches et des cas d'application. En dernière partie, il dressera une analyse comparative des frameworks Python les plus connus comme LIME et SHAP.
Bio :
Leonardo est Senior Data Scientist chez Bleckwen, FinTech créée en 2016 qui développe une solution de lutte contre la fraude financière avec du machine learning. Leonardo a plusieurs années d'expérience en développement logiciel et analyse des données et aime concevoir des applications plus "smart" avec le machine learning. Il a aussi co-fondé le meetup Toulouse Data Science et participe activement à des conférences data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}