Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Elasticsearch2系
Search
tsuyoshi nakamura
August 31, 2016
Technology
92
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Elasticsearch2系
Elasticsearch2系で日本語検索を試す
tsuyoshi nakamura
August 31, 2016
More Decks by tsuyoshi nakamura
See All by tsuyoshi nakamura
社内の勉強会で発表した_output_一部抜粋版_.pdf
tsuyoshi
0
510
PHPを少しでも早く_条件はあるよ_.pdf
tsuyoshi
0
87
スタートアップ6年目のレビュー文化.pdf
tsuyoshi
1
2k
PHPを少し深堀るよ.pdf
tsuyoshi
0
400
Reactive_Manifesto.pdf
tsuyoshi
0
92
About_Resilience.pdf
tsuyoshi
1
97
エンジニアの循環ってgood_or_bad_.pdf
tsuyoshi
0
1.3k
スタートアップしてからの失敗の数々
tsuyoshi
0
2.5k
スタートアップエンジニアの役割
tsuyoshi
0
550
Other Decks in Technology
See All in Technology
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
870
検索技術知識0のエンジニアが広告検索システムを内製化して運用するまで
lycorptech_jp
PRO
0
180
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
610
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
160
初めてのGitHub Actions / GitHub Actions at First
tooppoo
0
110
VPCセキュリティ対応の最新事情
nagisa53
2
350
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
380
組織にどうSREを根付かせるか?〜IVRyの場合〜
abnoumaru
0
190
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
290
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
310
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.5k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
500
Featured
See All Featured
Into the Great Unknown - MozCon
thekraken
41
2.6k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
480
For a Future-Friendly Web
brad_frost
183
10k
What's in a price? How to price your products and services
michaelherold
247
13k
Automating Front-end Workflow
addyosmani
1370
210k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
232
55k
A designer walks into a library…
pauljervisheath
211
24k
Designing Powerful Visuals for Engaging Learning
tmiket
1
470
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
We Have a Design System, Now What?
morganepeng
55
8.2k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Transcript
࣮ફElasticsearch(2.1.1) 2016-01-22 ࣾษڧձ Tsuyoshi Nakamura
全文検索エンジンとしては色々な歴史をたどってきました͕ɺࠓશจݕࡧΤϯδ ϯͱ͍͑”Elas'csearch”͕ྑ͍Έ͍ͨͳײ͡ͰɺAWSʹొ
Agenda • Install͔Βconfigઃఆ • Kuromoji • AnalysisϞδϡʔϧ • ओཁϞδϡʔϧ •
Demo • ௐࠪΓ͠
Install ʙ config • JavayumͰinstall • Elasticsearchެࣜͷrepositories͔ΒkeyΛinport. • Yumઃఆͯ͠yum installͰ࠷৽(2.1.1)͕ೖΔ
• ຊޠͷશจݕࡧʹඞཁͳpluginΛinstall Kuromoji plugin install bin/plugin install analysis-kuromoji ※https://www.elastic.co/guide/en/elasticsearch/plugins/master/analysis- kuromoji.html ※https://github.com/elastic/elasticsearch-analysis-kuromoji
Kuromoji • ͷ໊લʢΫϩϞδʁʣʁ༶ࢬͷࠇจࣈʁ • ͔Βͳ͍͚Ͳઈศར • Solr͍ͬͯͨ࣌͡ຊޠ༻ͷࣙॻʢMecabΒChasenΒʣΛࣗͰ ೖΕͯɺɺɺͱ৭ʑͱ໘͚ͩͬͨͨ
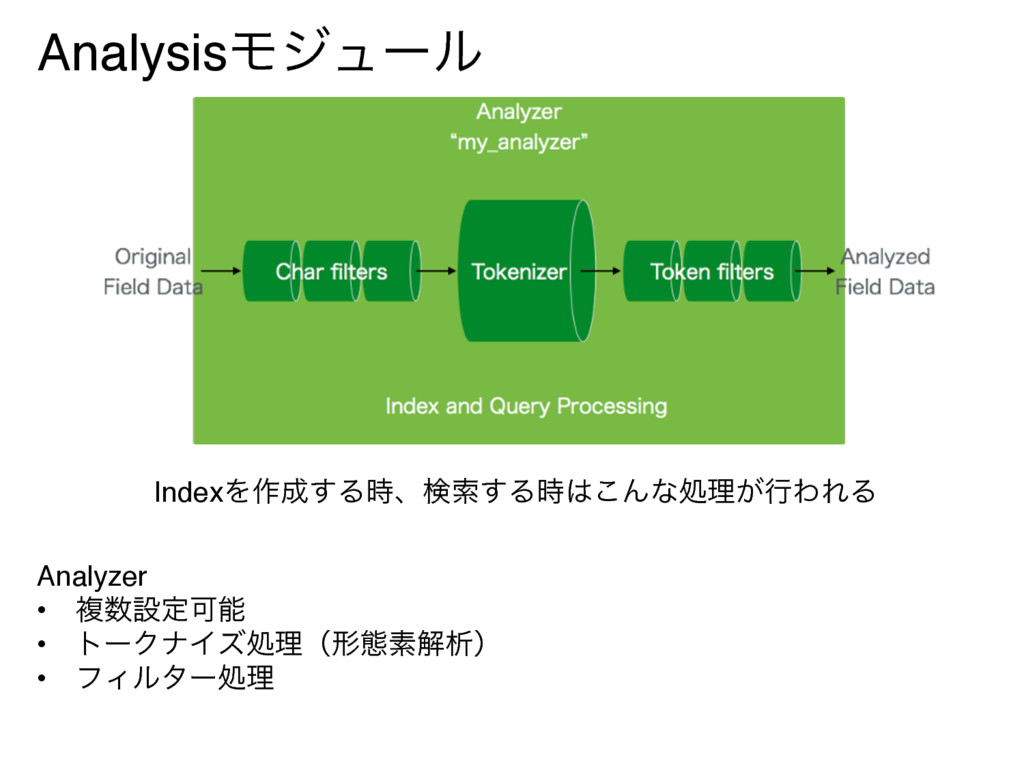
AnalysisϞδϡʔϧ Analyzer • ෳઃఆՄೳ • τʔΫφΠζॲཧʢܗଶૉղੳʣ • ϑΟϧλʔॲཧ IndexΛ࡞͢Δ࣌ɺݕࡧ͢Δ࣌͜Μͳॲཧ͕ߦΘΕΔ
AnalysisϞδϡʔϧ Tokenizer • τʔΫφΠζํࣜΛઃఆ • KuromojiΛͬͯτʔΫφΠζ͢Δͱ͔ • ngramࣜʹτʔΫφΠζ͢Δͱ͔ Token Filters
• τʔΫφΠζॲཧޙͷτʔΫϯʹରͯ͠ՃॲཧΛ͢Δ • શ֯ӳࣈΛ֯ʹ͠ɼ֯ΧλΧφΛશ֯ʹ͢ͱ͔ Char Filters • τʔΫφΠζॲཧલͷจࣈʹରͯ͠ՃॲཧΛ͢Δ • ه߸ͩͬͨΓɺʮʑʯͩͬͨΓΛআڈ͢Δ࣌ʹ͏
ओཁϞδϡʔϧ Ngram Tkenizer • N-άϥϜͰτʔΫφΠζɻElasticsearchʹ͋Δ cjk_width Token Filter • ֯શ֯Λ౷Ұ͢ΔϑΟϧλɻElasticsearchʹ͋Δ
Lowercase Token Filter • ӳࣈͷେจࣈখจࣈΛ౷Ұ͢ΔϑΟϧλɻElasticsearchʹ͋Δ Synonym Token Filter • ಉٛޠΛ݁ͼ͚ͭΔϑΟϧλɻElasticsearchʹ͋Δ Stop Token Filter • ҙͷϫʔυΛআڈ͢ΔϑΟϧλɻElasticsearchʹ͋Δ HTML Strip Char Filter • HTMLλάΛআڈ͢ΔϑΟϧλɻElasticsearchʹ͋Δ
ࠓճ࡞ͬͨconfig(elasticsearch.yml) # ---------------------------------- Index ----------------------------------- index : analysis : analyzer
: ja : type : custom tokenizer : ja_tokenizer char_filter : [ html_strip, kuromoji_iteration_mark ] filter : [ lowercase, cjk_width, katakana_stemmer, kuromoji_part_of_speech ] ja_ngram : type : custom tokenizer : ngram_ja_tokenizer char_filter : [html_strip] filter : [ cjk_width, lowercase ] tokenizer : ja_tokenizer : type : kuromoji_tokenizer mode : search user_dictionary : /etc/elasticsearch/userdict_ja.txt ngram_ja_tokenizer : type : nGram min_gram : 2 max_gram : 3 token_chars : [letter, digit] filter : katakana_stemmer : type : kuromoji_stemmer
ࠓճ࡞ͬͨindex mapping { "order": 0, "template": "projects01-*", "settings": { "index":
{ "number_of_shards": "1", "number_of_replicas": "0" } }, "mappings": { "project": { "_source": { "enabled": false }, "_all": { "analyzer": "ja", "enabled": true }, "properties": { "update_time": { "format": "YYYY-MM-dd HH:mm:ss", "type": "date" }, "project_id": { "index": "not_analyzed", "type": "string" }, "detail": { "analyzer": "ja", "type": "string" }, "suggest": { "search_analyzer": "ja", "analyzer": "ja", "type": "completion" }, "detail_ngram": { "analyzer": "ja_ngram", "type": "string" }, "title": { "analyzer": "ja", "type": "string" }, "title_ngram": { "analyzer": "ja_ngram", "type": "string" } } } }, "aliases": { }
Demo
Demo • Elasticsearchͷཧπʔϧ(kopf)ΛݟΔ • ͍Ζ͍Ζػೳ͋Δɻ • Mappingͱ͔͜͜Ͱొͨ͠ • ศརɺ͔͍͍ͬ͜ •
IndexΛ࡞ͬͯΈΔ • ݕࡧͯ͠ΈΔ • αδΣετػೳ(completion)͔ͭͬͯΈΔ
·ͩௐ͕ࠪඞཁͳՕॴ • Indexͷӡ༻ɺߋ৽ϑϩʔ • Pyhon curator • Score • ಉ͡ݕࡧͰݱࡏਐߦ͍ͯ͠ΔPJΛݕࡧ݁Ռͷ্ҐΈ͍ͨͳཁ݅
͕ग़͖ͯͦ͏ • SlowΫΤϦͱ͔ͷᮢ • ES_HEAP_SIZEɺεϫοϓ • clusterɺshardɺreplica • IndexͷόοΫΞοϓɺϦετΞ • Pyhonͷtoolɺ_snapshotɺόΠφϦόοΫΞοϓ • Facet? AggregationsͰ͍͚Δʁ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}