Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jubatusのリアルタイム分散 レコメンデーション @TokyoWebmining
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yuya Unno
May 20, 2012
Technology
32
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jubatusのリアルタイム分散 レコメンデーション @TokyoWebmining
Yuya Unno
May 20, 2012
More Decks by Yuya Unno
See All by Yuya Unno
深層学習で切り拓くパーソナルロボットの未来 @東京大学 先端技術セミナー 工学最前線
unnonouno
0
29
深層学習時代の自然言語処理ビジネス @DLLAB 言語・音声ナイト
unnonouno
0
53
ベンチャー企業で言葉を扱うロボットの研究開発をする @東京大学 電子情報学特論I
unnonouno
0
50
PFNにおけるセミナー活動 @NLP2018 言語処理研究者・技術者の育成と未来への連携WS
unnonouno
0
20
進化するChainer @JSAI2017
unnonouno
0
30
予測型戦略を知るための機械学習チュートリアル @BigData Conference 2017 Spring
unnonouno
0
29
深層学習フレームワーク Chainerとその進化
unnonouno
0
31
深層学習による機械とのコミュニケーション @DeNA TechCon 2017
unnonouno
0
43
最先端NLP勉強会 “Learning Language Games through Interaction” @第8回最先端NLP勉強会
unnonouno
0
25
Other Decks in Technology
See All in Technology
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
130
シンガポールで登壇してきます
yama3133
0
120
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
Kaggleで成長するために意識したこと
prgckwb
2
330
穢れた技術選定について
watany
6
490
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
330
貴方はどのエンジニアリングを磨くのか
hatyibei
0
130
公式ドキュメントの歩き方etc
coco_se
0
100
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
0
140
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
1
380
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
Featured
See All Featured
What's in a price? How to price your products and services
michaelherold
247
13k
Facilitating Awesome Meetings
lara
57
7k
Being A Developer After 40
akosma
91
590k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Between Models and Reality
mayunak
4
370
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
930
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Transcript
Jubatusのリアルタイム分散 レコメンデーション 2012/05/20@TokyoWebmining 株式会社Preferred Infrastructure 海野 裕也 (@unnonouno)
⾃自⼰己紹介 l 海野 裕也 (@unnonouno) l unno/no/uno l ㈱Preferred Infrastructure 研究開発部
l 検索索・レコメンドエンジンSedueの開発など l 専⾨門 l ⾃自然⾔言語処理理 l テキストマイニング l Jubatusチームリーダー
今⽇日のお話 l Jubatusの紹介 l 分散レコメンデーションについて #TokyoNLPではなした内容とだいたい同じですm(_ _)m
Jubatusの紹介
Big Data ! l データはこれからも増加し続ける l 多いことより増えていくということが重要 l データ量量の変化に対応できるスケーラブルなシステムが求めら れる
l データの種類は多様化 l 定形データのみならず、⾮非定形データも増加 l テキスト、⾏行行動履履歴、⾳音声、映像、信号 l ⽣生成される分野も多様化 l PC、モバイル、センサー、⾞車車、⼯工場、EC、病院 5
データを活⽤用する STEP 1. ⼤大量量のデータを捨てずに蓄積できるようになってきた STEP 2. データを分析することで、現状の把握、理理解ができる STEP 3. 状況を理理解し、現状の改善、予測ができる
l 世の中的には、蓄積から把握、理理解に向かった段階 6 6 蓄積 理理解 予測 より深い解析へ 本の購買情報 を全て記録で きるように なった! この本が実際 に売れている のは意外にも 30代のおっさ ん達だ! この⼈人は30代 男性なので、 この本を買う のではない か?
Jubatus 7 リアルタイム ストリーム 分散並列列 深い解析 l NTT PF研とPreferred Infrastructureによる共同開発
10/27よりOSSで公開 http://jubat.us/
Jubatusの技術的な特徴 l オンライン学習をさらに分散化させる l そのための通信プロトコル、計算モデル、死活監視、学 習アルゴリズムなどの⾜足回りを提供する 分散かつオンラインの機械学習基盤
分散かつオンラインの機械学習 l 処理理が速い! l 処理理の完了了を待つ時間が少ない l 5分前のTV番組の影響を反映した広告推薦ができる l 5分前の交通量量から渋滞をさけた経路路を提案できる l
⼤大規模! l 処理理が間に合わなくなったらスケールアウト l ⽇日本全国からデータが集まる状態でも動かしたい l 機械学習の深い分析! l 単純なカウント以上の精度度を 9
他の技術との⽐比較 l ⼤大規模バッチ(Hadoop & Mahout) l 並列列分散+機械学習 l リアルタイム性を確保するのは難しい l
オンライン学習ライブラリ l リアルタイム+機械学習 l 並列列分散化させるのはかなり⼤大変 l ストリーム処理理基盤、CEP l 並列列分散+リアルタイム l 分散機械学習は難しい
今までにない技術、これからの技術 l 欲張り l 今までのトレンドを全部取り込む l 制約が多く、実験も実装も難しい l これからの技術 l
今すぐ実⽤用的になる部分、そうでない部分を含む l 最初の1⼈人になるなら今! l 新しい研究分野 l 研究テーマとしても⾯面⽩白い l 乗っかるなら今!
Jubatusの挑戦 単なる機械学習ライブラリではなく、そこに必要なあらゆ る技術を検討 l オンライン分散学習 l ⾮非構造データ、特徴抽出 l 計算モデル l
分散システム l RPCの抽象化 メンバーも、機械学習、⾃自然⾔言語処理理、プログラミング⾔言 語、分散システムなどを得意とする
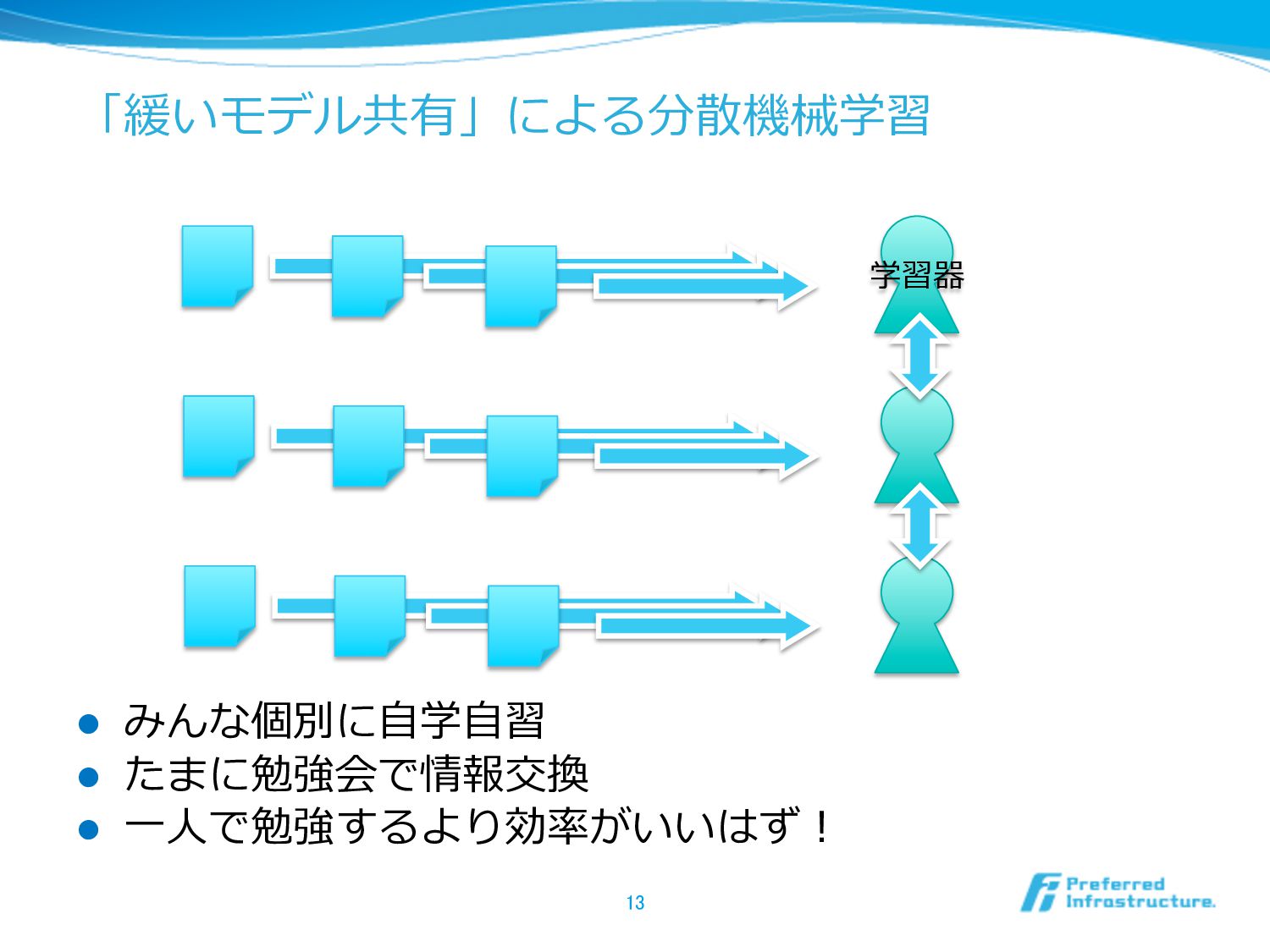
「緩いモデル共有」による分散機械学習 l みんな個別に⾃自学⾃自習 l たまに勉強会で情報交換 l ⼀一⼈人で勉強するより効率率率がいいはず! 13 学習器
3種類の処理理に分解 l UPDATE l データを受け取ってモデルを更更新(学習)する l ANALYZE l データを受け取って解析結果を返す l
MIX l 内部モデルを混ぜ合わせる l cf. MAP / REDUCE l 分散機械学習を3操作だけでどこまで記述できる か? 14
3つの処理理の例例:統計処理理の場合 l 平均値を計算する⽅方法を考えよう l 内部状態は今までの合計(sum)とデータの個数(count) l UPDATE l sum +=
x l count += 1 l ANALYZE l return (sum / count) l MIX l sum = sum1 + sum2 l count = count1 + count2 15
世の中の機械学習ライブラリの敷居はまだ⾼高い l libsvmフォーマット l +1 1:1 3:1 8:1 l 何よこれ? ←普通の⼈人の反応
l ⽣生データを扱えない l ハイパーパラメータ l 「Cはいくつにしましたか?」 l Cってなんだよ・・・ ←普通の⼈人の反応 l 複雑な設定 l 研究者向き、エンジニアが広く使えない 16
RDBやHadoopから学ぶべきこと l わからない l リレーショナル理理論論 l クエリオプティマイザ l トランザクション処理理 l
分散計算モデル l わかる l SQL l Map/Reduce l 「あとは裏裏でよろしくやってくれるんでしょ?」 17
Jubatus裏裏の⽬目標 l わからない l オンライン凸最適化 l 事後確率率率最⼤大化 l MCMC、変分ベイズ l
特徴抽出、カーネルトリック l わかる l ⾃自動分類、推薦 l 「あとはよろしくやってくれるんでしょ?」 18 全ての⼈人に機械学習を!
⽣生データを突っ込めば動くようにしたい l Jubatusの⼊入⼒力力はキー・バリュー l 最初は任意のJSONだった l twitter APIの⽣生出⼒力力を⼊入⼒力力できるようにしたかった l あとは勝⼿手に適当に処理理してくれる
l ⾔言語判定して l 各キーが何を表すのか⾃自動で推定して l 勝⼿手に適切切な特徴抽出を選ばせる l というようなことができるようになるかも l 特徴抽出エンジンのプラグイン化 l 様々な特徴関数をダウンロードして⾃自由に組み合わせたい 19
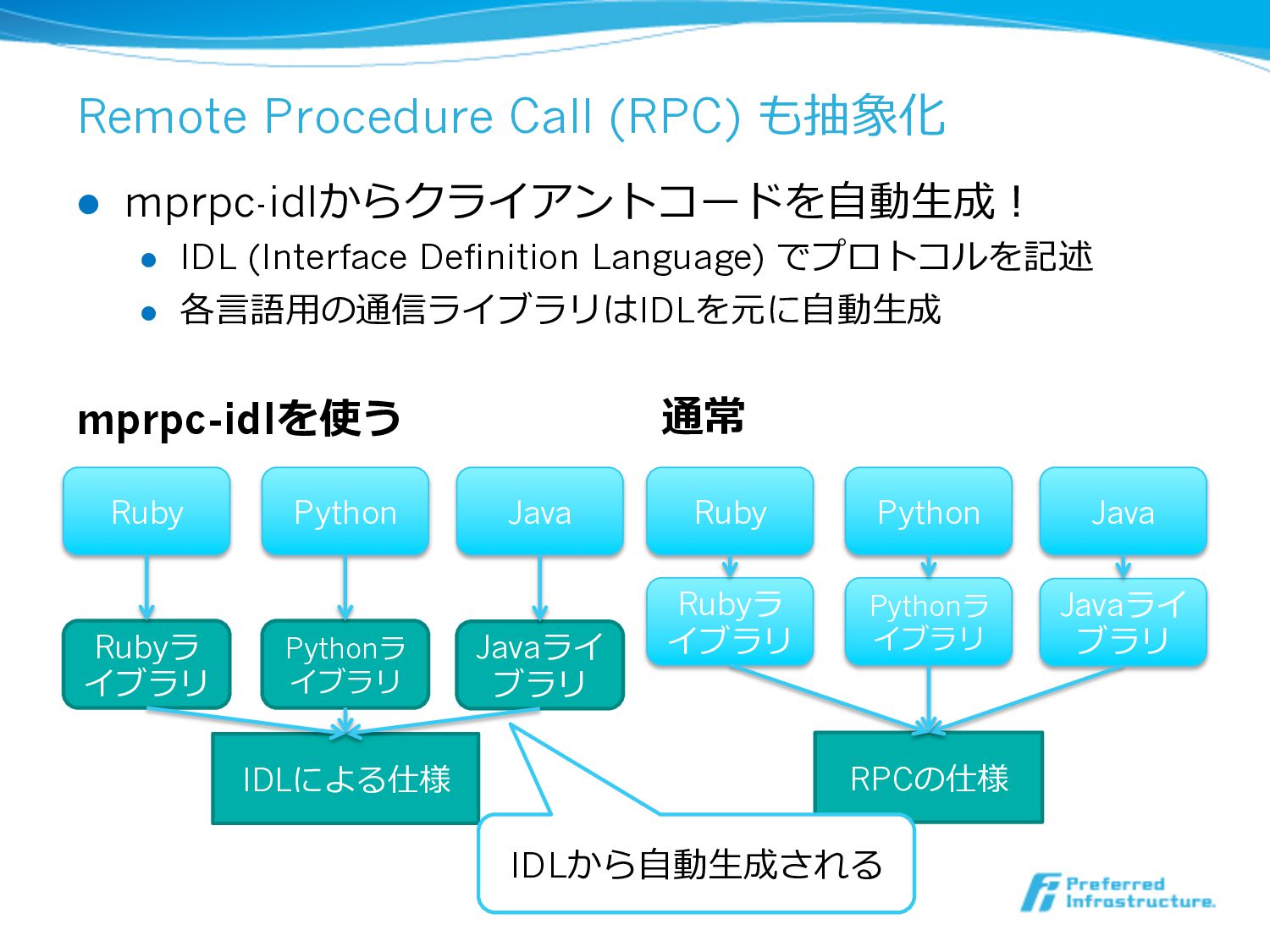
Remote Procedure Call (RPC) も抽象化 l mprpc-idlからクライアントコードを⾃自動⽣生成! l IDL (Interface
Definition Language) でプロトコルを記述 l 各⾔言語⽤用の通信ライブラリはIDLを元に⾃自動⽣生成 Ruby RPCの仕様 Rubyラ イブラリ Python Pythonラ イブラリ Java Javaライ ブラリ Ruby IDLによる仕様 Rubyラ イブラリ Python Pythonラ イブラリ Java Javaライ ブラリ mprpc-idlを使う 通常 IDLから⾃自動⽣生成される
新機能:分散レコメンド
レコメンデーションとは何か? l 記事や商品のおすすめ機能 l この記事に類似した記事はこの記事です l この商品を買った⼈人はこの商品も買っています l 技術的には「近傍探索索」を使っている
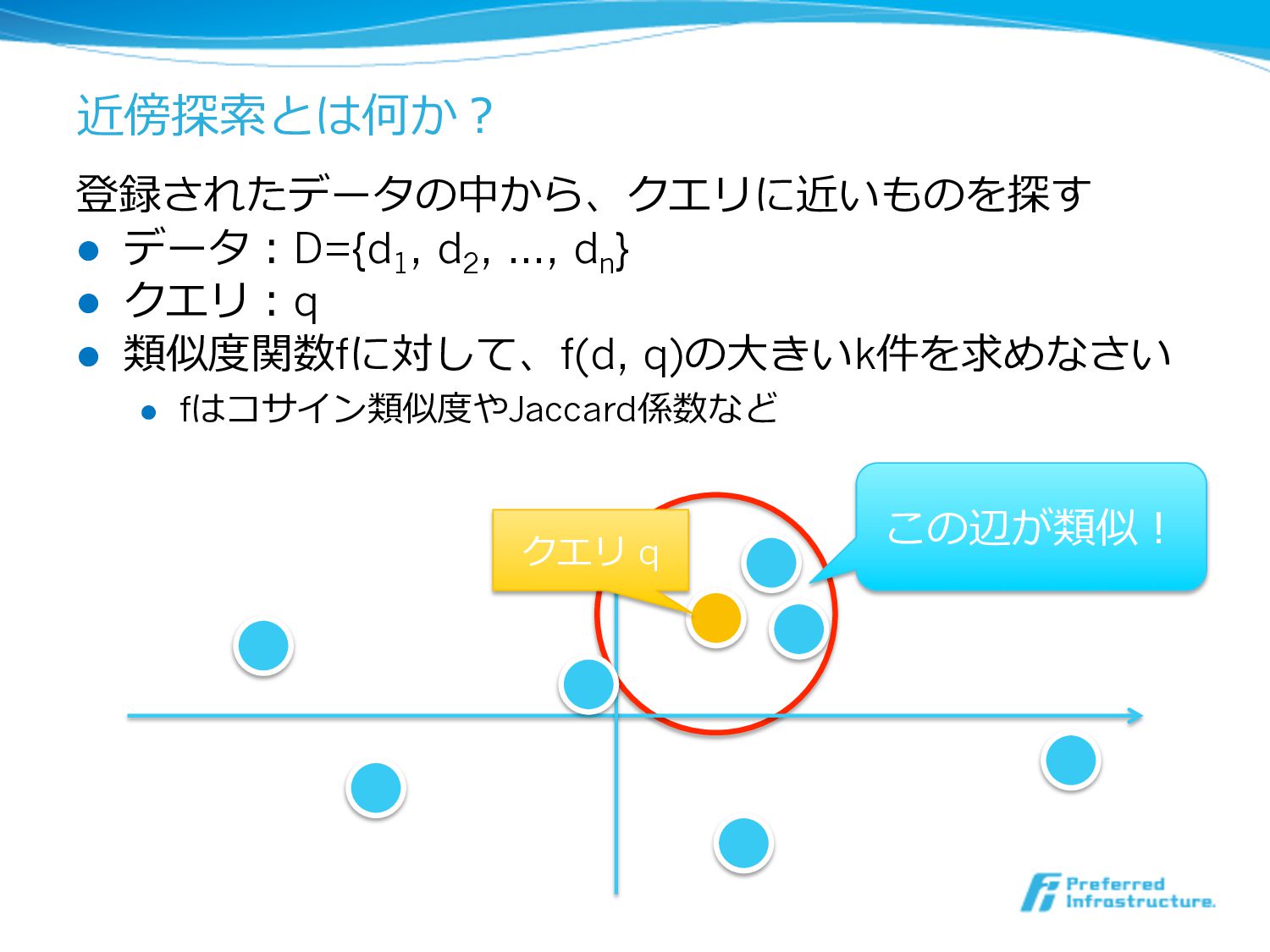
近傍探索索とは何か? 登録されたデータの中から、クエリに近いものを探す l データ:D={d 1 , d 2 , …,
d n } l クエリ:q l 類似度度関数fに対して、f(d, q)の⼤大きいk件を求めなさい l fはコサイン類似度度やJaccard係数など クエリ q この辺が類似!
何も考えずに近傍探索索しよう l 全データに対して類似度度を計算して上位を返せばOK input: x for d in all data:
score[d] = sim(x, d) sort score return top-K elements of score
近傍探索索の技術的課題 l 実⾏行行時間 l 単純な実装だと、データ点のサイズに⽐比例例した時間がかかる l 消費メモリ l すべてのオリジナルデータを保持するとデータが膨⼤大になる 上記2点と精度度とのトレードオフ
準備:よくある類似度度尺度度 l コサイン類似度度 l 2つのベクトルの余弦 l cos(θ(x, y)) = xTy
/ |x||y| l Jaccard係数 l 2つの集合の積集合と和集合のサイズの⽐比 l Jacc(X, Y) = |X∩Y|/|X∪Y| l ビットベクトル間の距離離と思うことができる
近傍探索索アルゴリズム l 転置インデックス l Locality Sensitive Hashing (simhash) l minhash
l アンカーグラフ
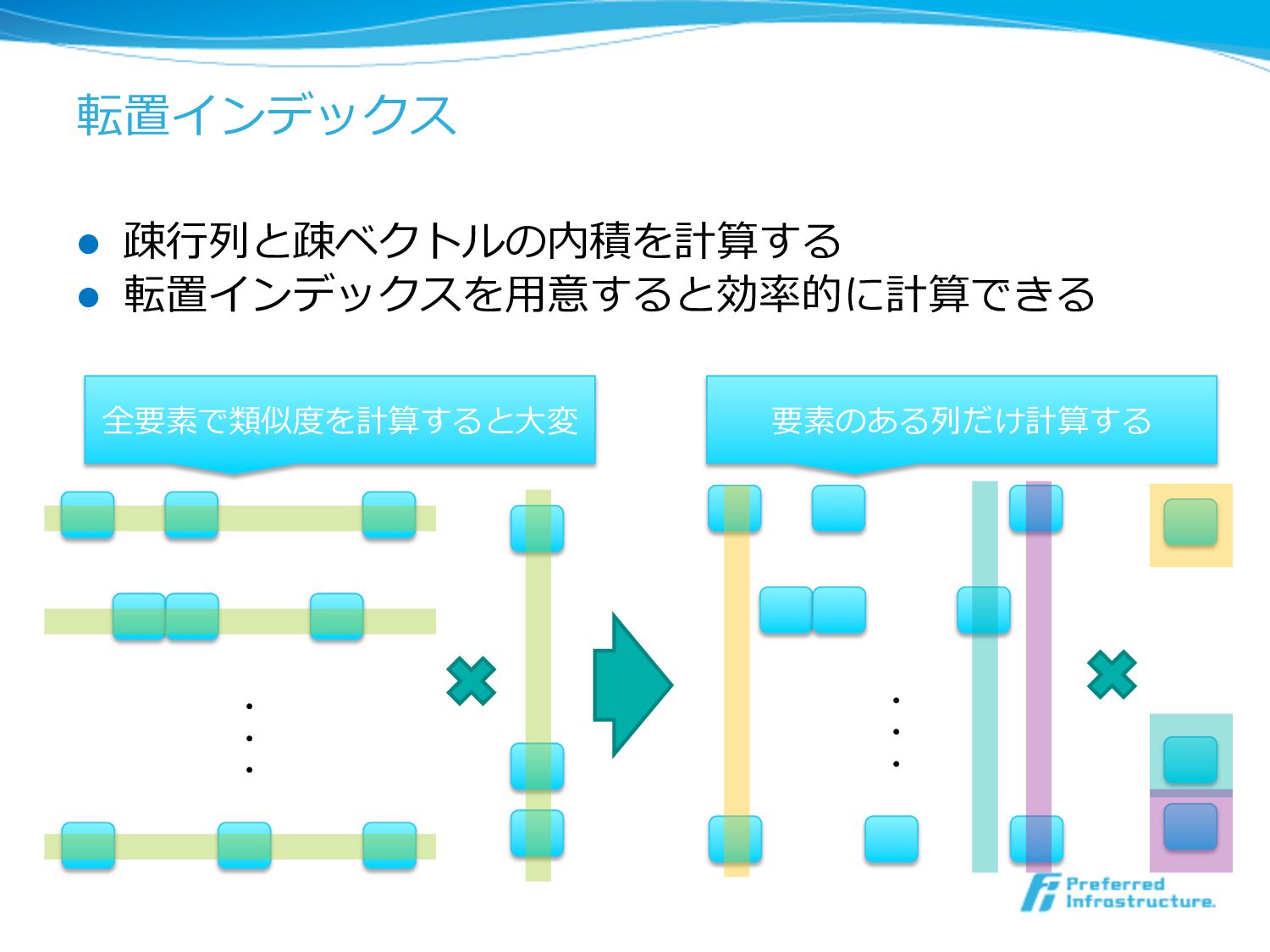
転置インデックス l 疎⾏行行列列と疎ベクトルの内積を計算する l 転置インデックスを⽤用意すると効率率率的に計算できる ・ ・ ・ ・ ・
・ 全要素で類似度度を計算すると⼤大変 要素のある列列だけ計算する
Locality Sensitive Hashing (LSH) l ランダムなベクトル r を作る l このときベクトルx,
yに対してxTrとyTrの正負が⼀一致する 確率率率はおよそ cos(θ(x, y)) l ランダムベクトルをk個に増やして正負の⼀一致率率率を数え れば、だいたいコサイン距離離になる l ベクトルxに対して、ランダムベクトル{r 1 , …, r k }との内 積の正負を計算 H(x) = {sign(xTr 1 ), …, sign(xTr k )} l signは正なら1、負なら0を返す関数 l H(x)だけ保存すればよいので1データ当たりkビット
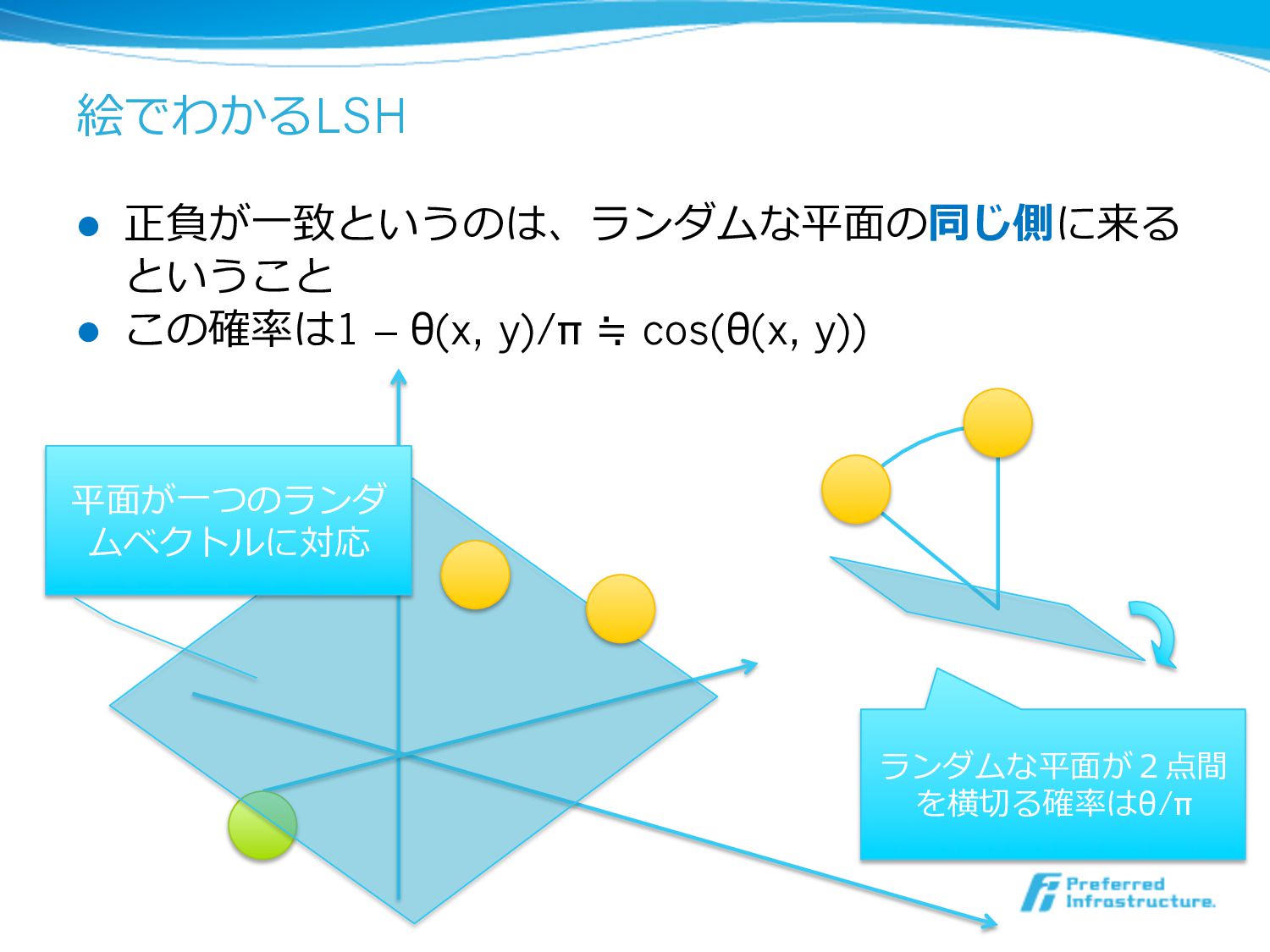
絵でわかるLSH l 正負が⼀一致というのは、ランダムな平⾯面の同じ側に来る ということ l この確率率率は1 – θ(x, y)/π ≒
cos(θ(x, y)) 平⾯面が⼀一つのランダ ムベクトルに対応 ランダムな平⾯面が2点間 を横切切る確率率率はθ/π
Jaccard係数 l 集合の類似度度を図る関数 l 値を0, 1しか取らないベクトルだと思えばOK l Jacc(X, Y) =
|X∩Y| / |X∪Y| 例例 l X = {1, 2, 4, 6, 7} l Y = {1, 3, 5, 6} l X∩Y = {1, 6} l X∪Y = {1, 2, 3, 4, 5, 6, 7} l Jacc(X, Y) = 2/7
minhash l X = { x 1 , x 2
, …, x n } l Xは集合なので、感覚的には⾮非ゼロ要素のインデックスのこと l H(X) = { h(x 1 ), …, h(x n ) } l m(X) = argmin(H(X)) l m(X) = m(Y)となる確率率率はJacc(X, Y)に⼀一致 l ハッシュ関数を複数⽤用意したとき、m(X)=m(Y)となる回数を数 えるとJacc(X, Y)に収束する l m(X)の最下位ビットだけ保持すると、衝突の危険が⾼高 まる代わりにハッシュ関数を増やせる [Li+10a, Li+10b]
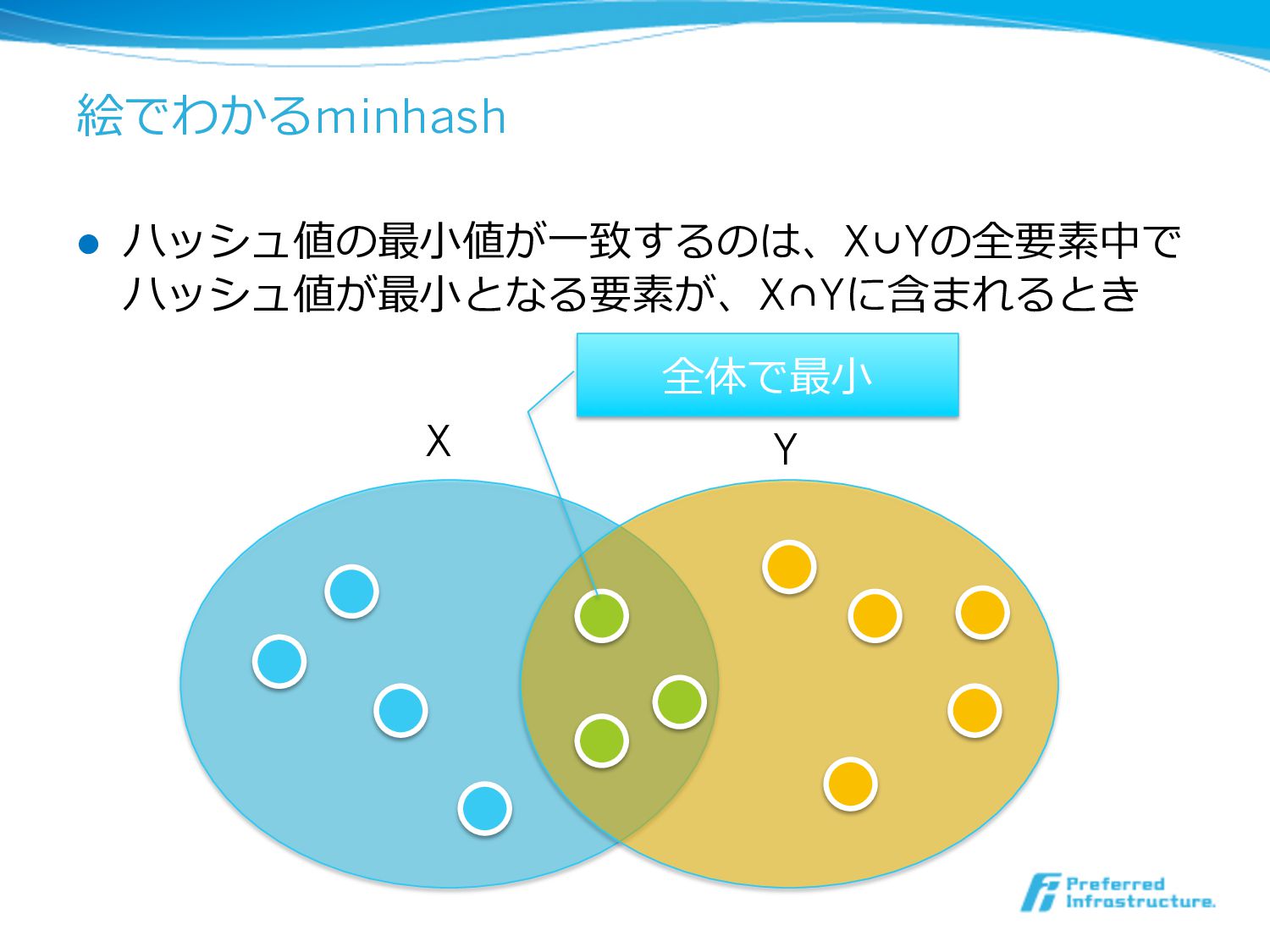
絵でわかるminhash l ハッシュ値の最⼩小値が⼀一致するのは、X∪Yの全要素中で ハッシュ値が最⼩小となる要素が、X∩Yに含まれるとき X Y 全体で最⼩小
重み付きJaccard係数 l 各集合の要素のidfのような重みをつける l wJacc(X, Y) = Σ i∈X∩Y w
i / Σ i∈X∪Y w i l w i が常に1なら先と同じ 例例 l X = {1, 2, 4, 6, 7} l Y = {1, 3, 5, 6} l w = (2, 3, 1, 4, 5, 2, 3) l X∩Y = {1, 6} l X∪Y = {1, 2, 3, 4, 5, 6, 7} l wJacc(X, Y) = (2+2)/(2+3+1+4+5+2+3)=4/20
重み付きJaccard版minhash [Chum+08] l X = { x 1 , x
2 , …, x n } l H(X) = {h(x 1 )/w 1 , …, h(x n )/w n } l 論論⽂文中では-log(h(x))としている l 差分はw i で割っているところ l 感覚的にはw i が⼤大きければ、ハッシュ値が⼩小さくなりやすいの で、選ばれる確率率率が⼤大きくなる l m(X) = argmin(H(X)) l m(X) = m(Y)となる確率率率はwJacc(X, Y)に⼀一致
アンカーグラフ [Liu+11] l 予めアンカーを定めておく l 各データは近いアンカーだけ覚える l アンカーはハブ空港のようなもの l まず類似アンカーを探して、その周辺だけ探せばOK
アンカー
それぞれのアルゴリズムをオンライン化・・・でき るか? Jubatusのポイントはオンライン学習! 近傍探索索のオンライン化とは? l データ集合Dに新しいデータdを追加・変更更できる l 追加したら、直ちにL(d, q)の⼩小さいdを求められる
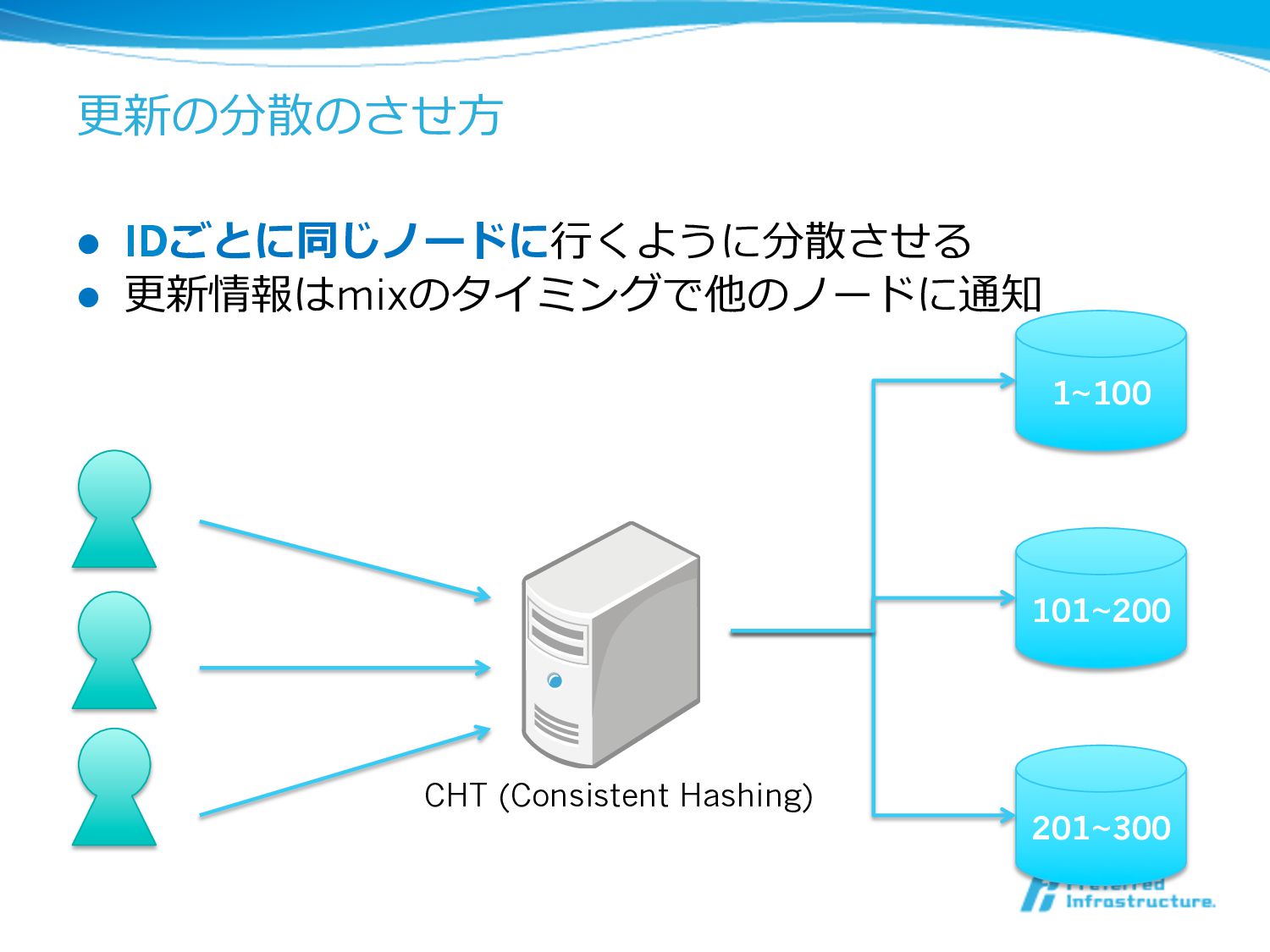
更更新の分散のさせ⽅方 l IDごとに同じノードに⾏行行くように分散させる l 更更新情報はmixのタイミングで他のノードに通知 1~100 101~200 201~300 CHT (Consistent
Hashing)
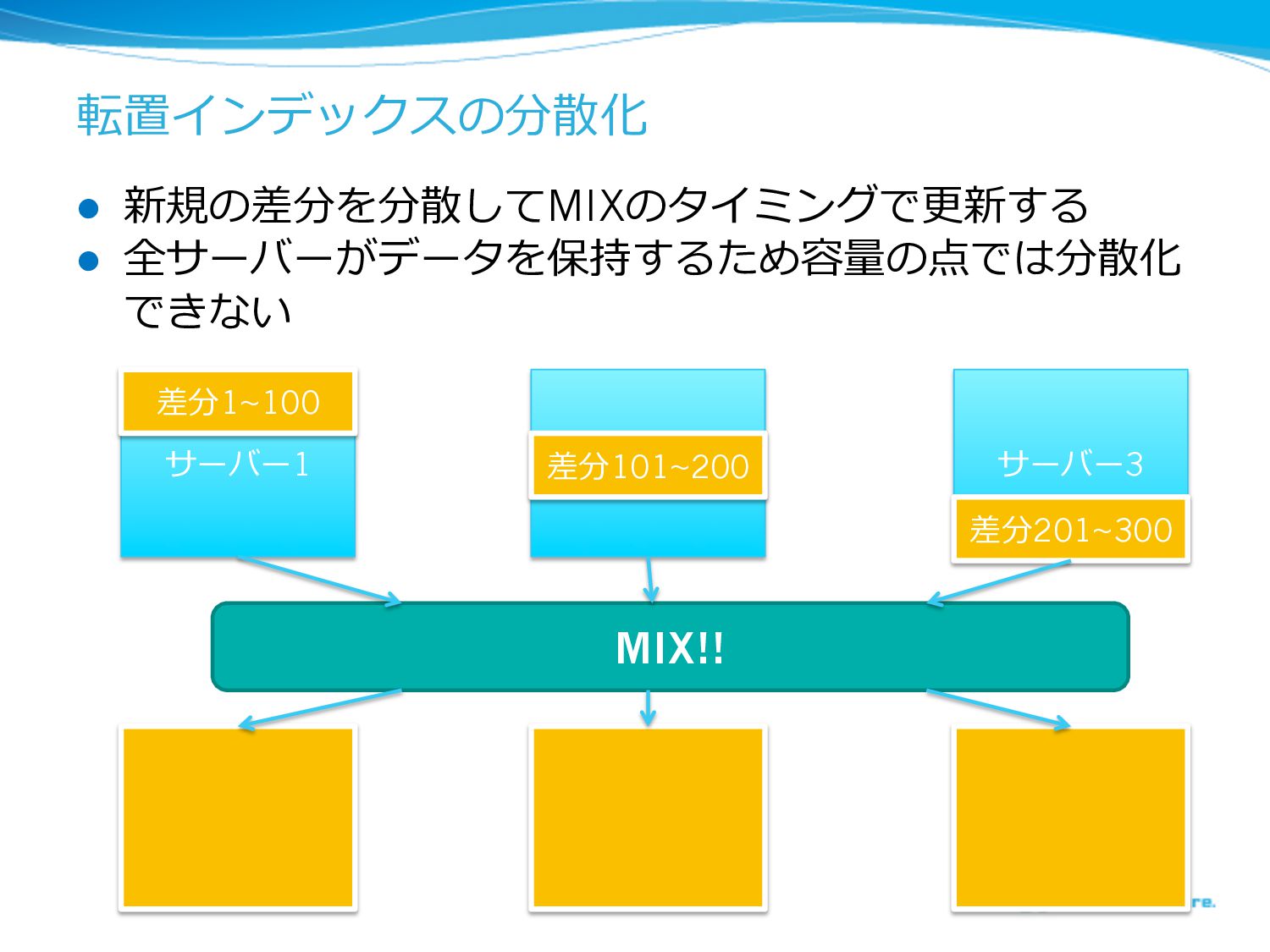
転置インデックスの分散化 l 新規の差分を分散してMIXのタイミングで更更新する l 全サーバーがデータを保持するため容量量の点では分散化 できない サーバー1 サバー2 サーバー3 差分1~100
差分101~200 差分201~300 MIX!!
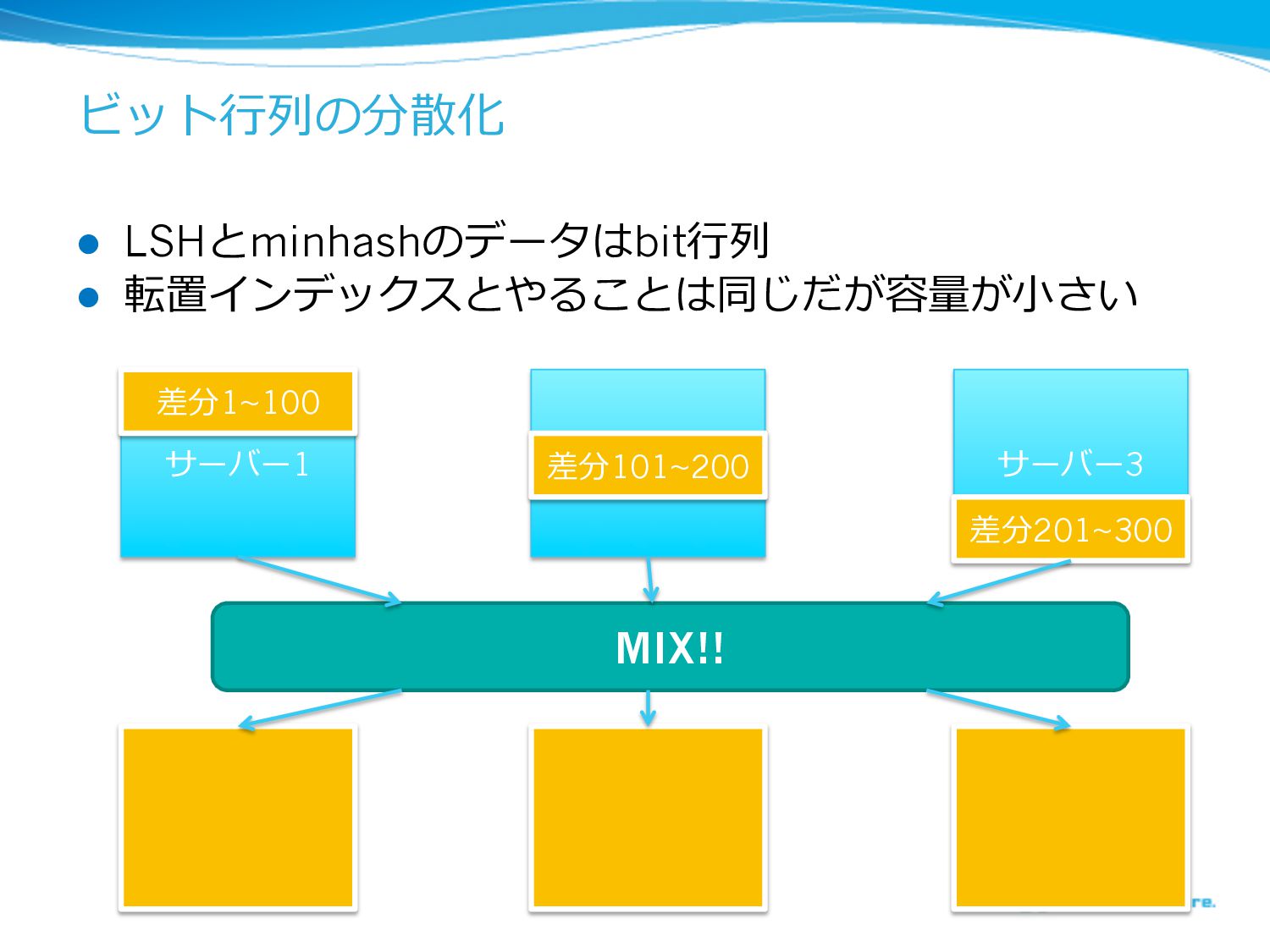
ビット⾏行行列列の分散化 l LSHとminhashのデータはbit⾏行行列列 l 転置インデックスとやることは同じだが容量量が⼩小さい サーバー1 サバー2 サーバー3 差分1~100 差分101~200
差分201~300 MIX!!
アンカーグラフの分散化? l 類似アンカーの情報しか残ってないため、データの⼀一部 を更更新するのが困難 l オリジナルデータを持っておけばよい? l 実装・デバッグはかなり激しい l うまく⾏行行っているのかどうかわかりにくい
現在の実装 l 転置インデックスとLSHが公開されている l minhashは特許問題で調整中 l アンカーグラフはうまく分散させるに⾄至らず
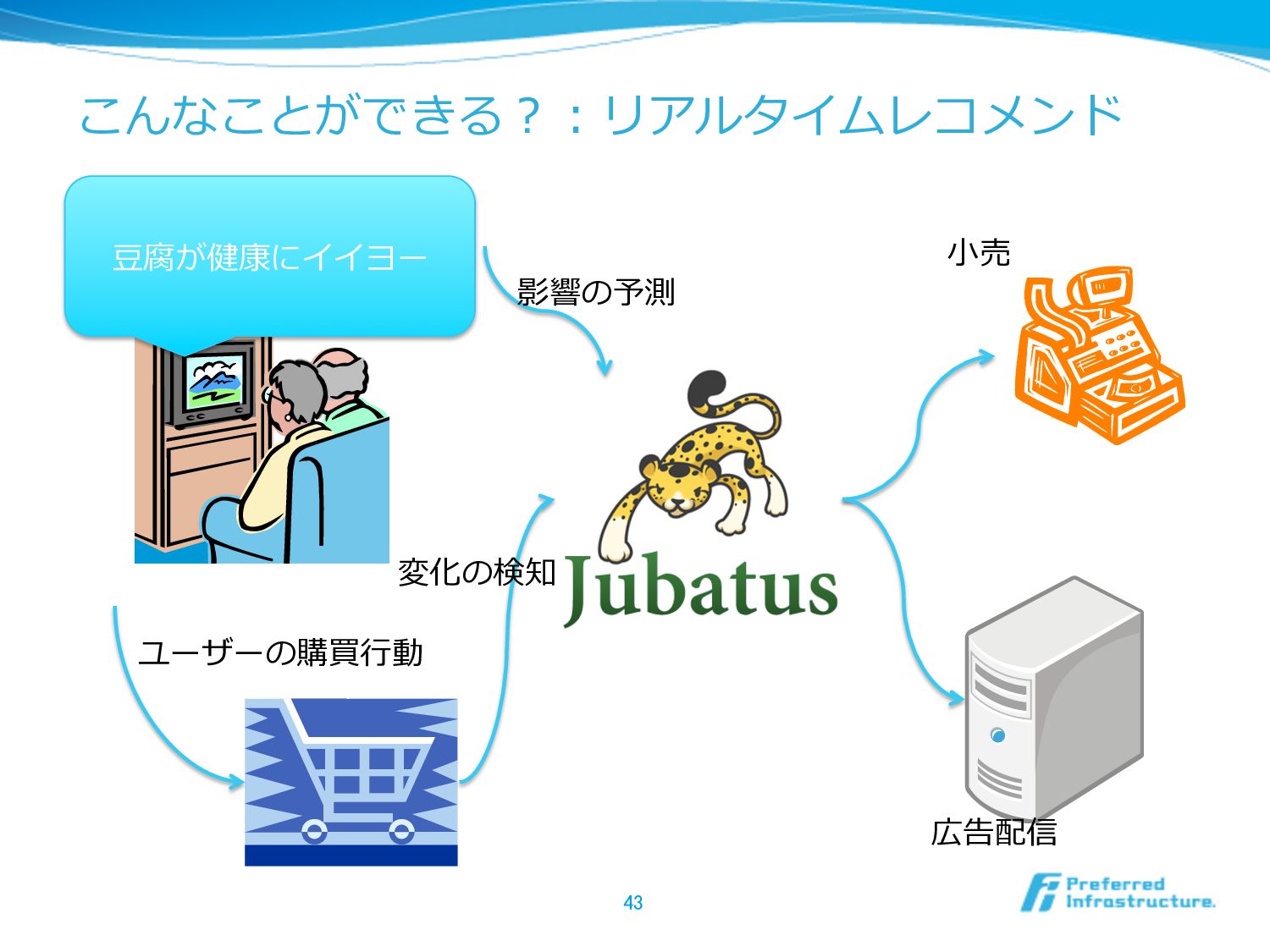
こんなことができる?:リアルタイムレコメンド 43 ⾖豆腐が健康にイイヨー ユーザーの購買⾏行行動 変化の検知 ⼩小売 広告配信 影響の予測
まとめ l Jubatusは総合格闘技 l MIX操作による緩い同期計算モデル l ⾮非構造データを扱うための特徴抽出 l IDLからのクライアントコード⾃自動⽣生成 l
レコメンドの4⼿手法 l 転置インデックス l Locality Sensitive Hashing (simhash) l minhash l アンカーグラフ l 現在は前者2つを公開
参考⽂文献 l [Chum+08] Ondrej Chum, James Philbin, Andrew Zisserman. Near
Duplicate Image Detection: min-Hash and tf-idf Weighting. BMVC 2008. l [Li+10a] Ping Li, Arnd Christian Konig. b-Bit Minwise Hashing. WWW 2008. l [Li+10b] Ping Li, Arnd Christian Konig, Wenhao Gui. b-Bit Minwise Hashing for Estimating Three-Way Similarities. NIPS 2008. l [Liu+11] Wei Liu, Jun Wang, Sanjiv Kumar, Shin-Fu Chang. Hashing with Graphs. ICML 2011.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![重み付きJaccard版minhash [Chum+08] l X = { x 1 , x](https://files.speakerdeck.com/presentations/c8a7f61e2148464b8799092fe000e352/slide_34.jpg){kind=link}
![アンカーグラフ [Liu+11] l 予めアンカーを定めておく l 各データは近いアンカーだけ覚える l アンカーはハブ空港のようなもの l まず類似アンカーを探して、その周辺だけ探せばOK](https://files.speakerdeck.com/presentations/c8a7f61e2148464b8799092fe000e352/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考⽂文献 l [Chum+08] Ondrej Chum, James Philbin, Andrew Zisserman. Near](https://files.speakerdeck.com/presentations/c8a7f61e2148464b8799092fe000e352/slide_44.jpg){kind=link}