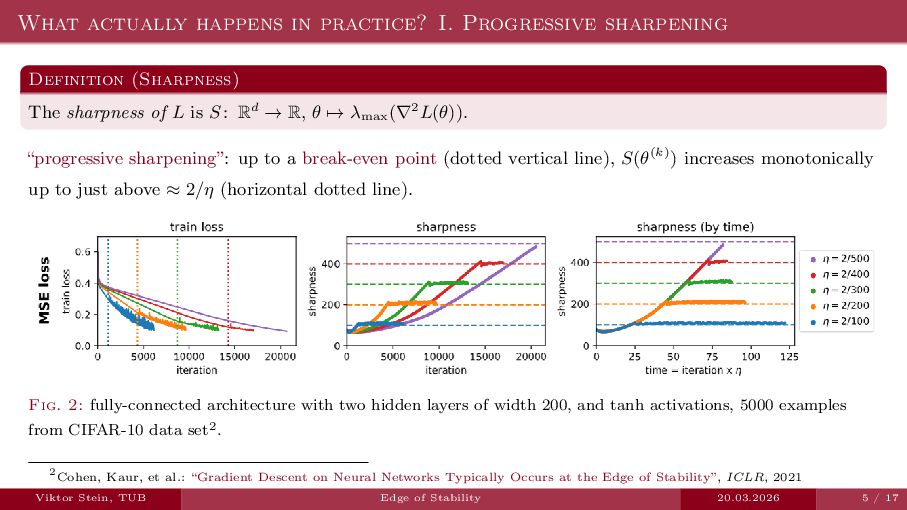
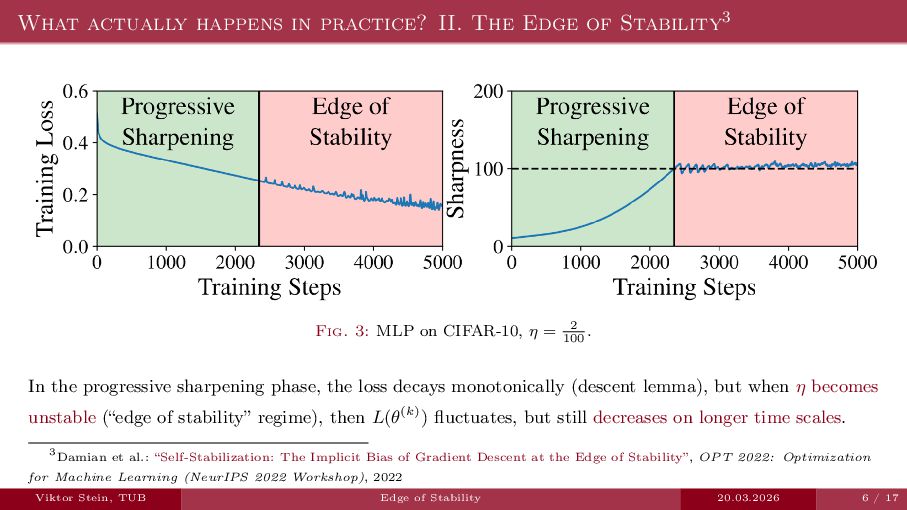
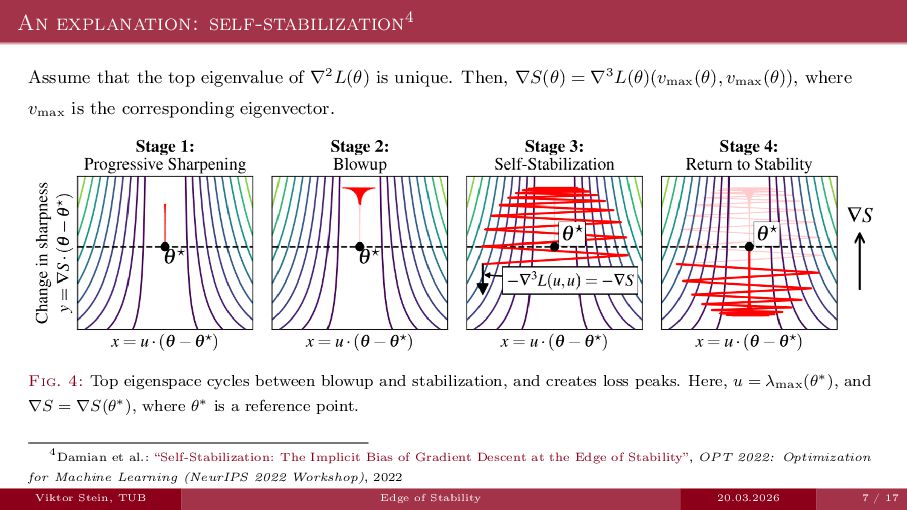
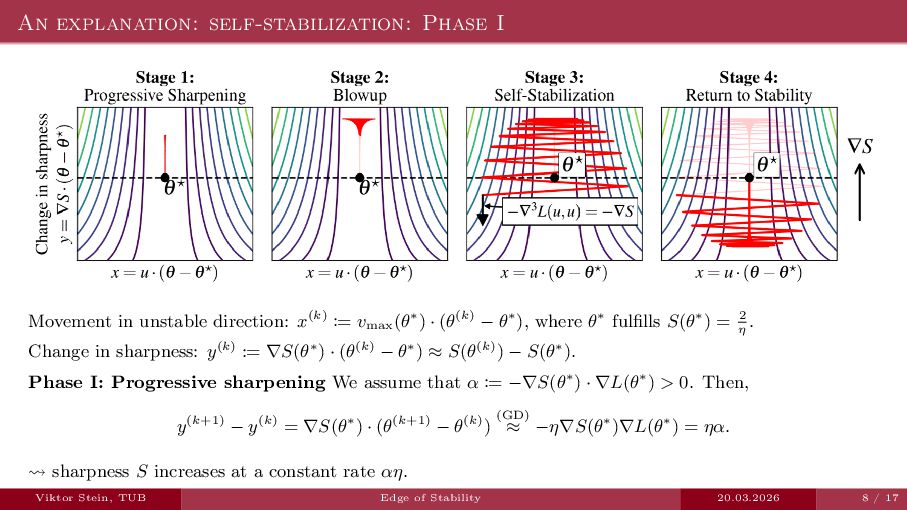
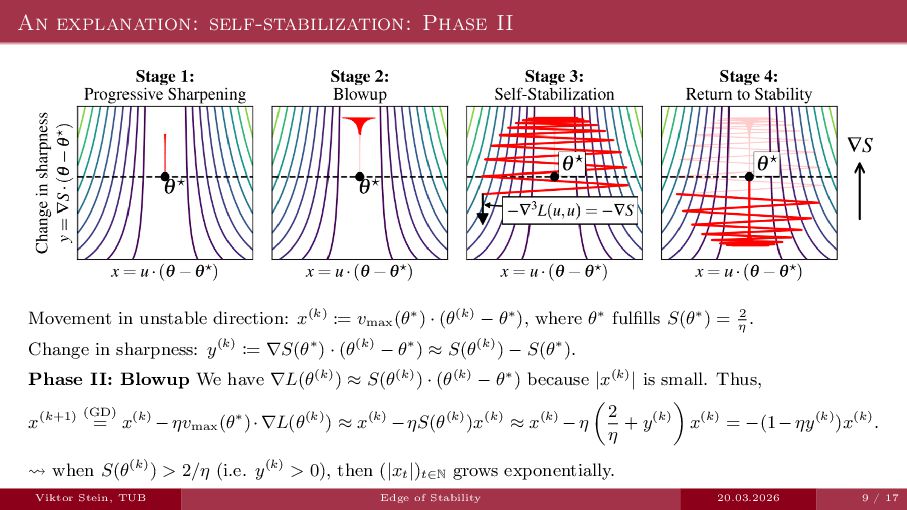
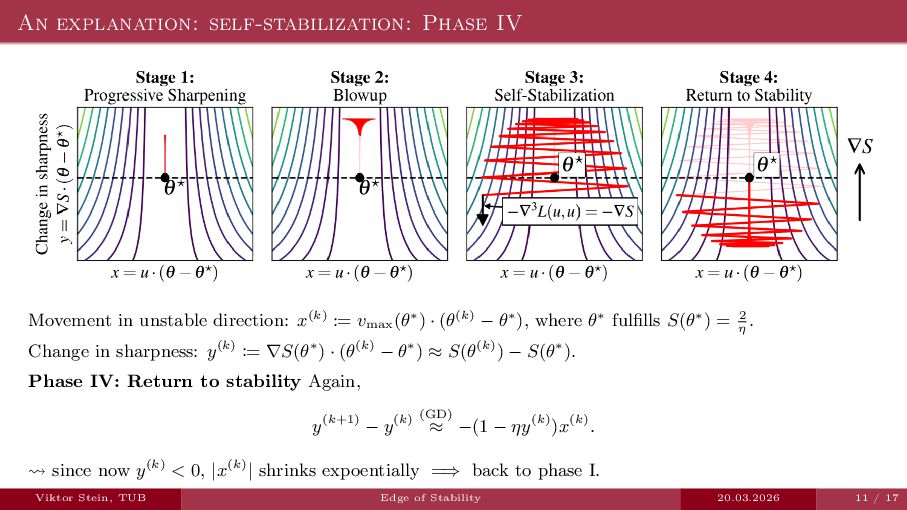
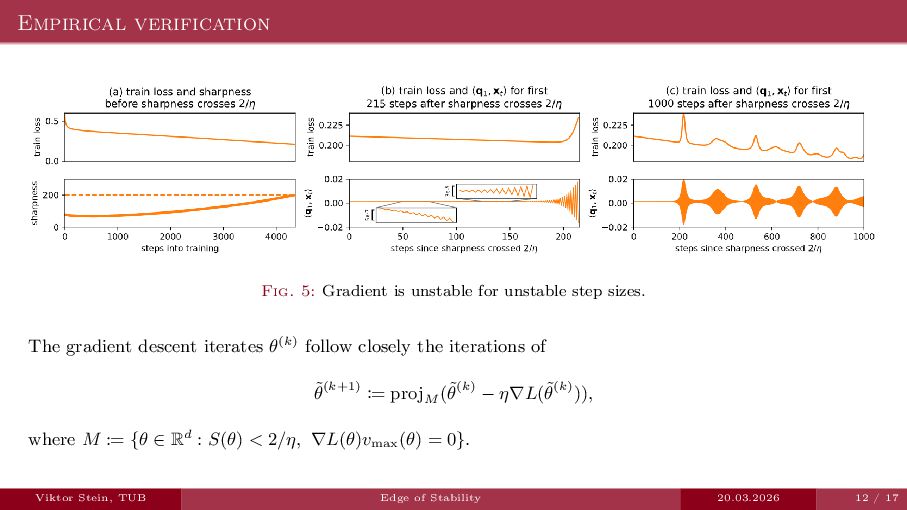
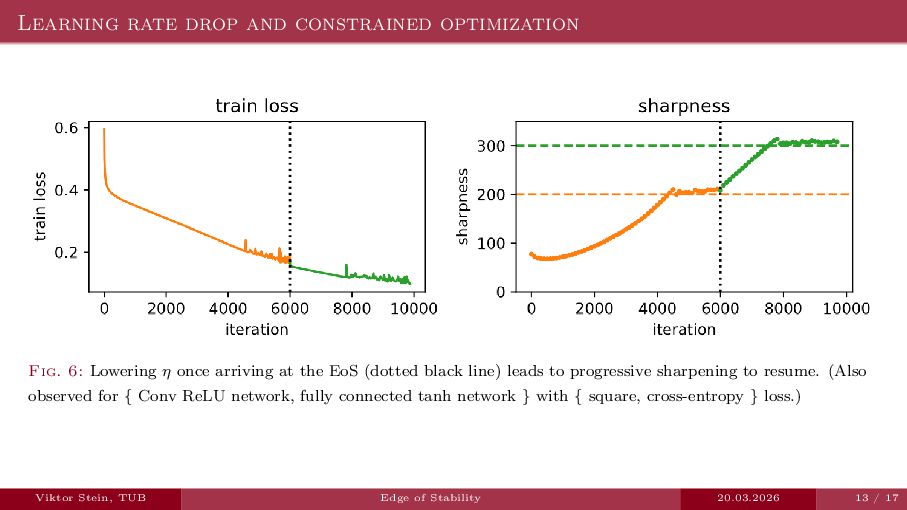
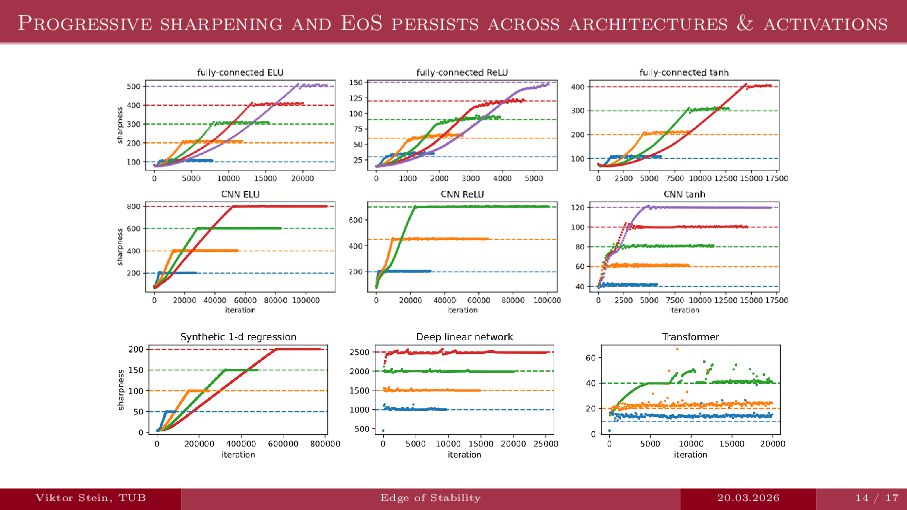
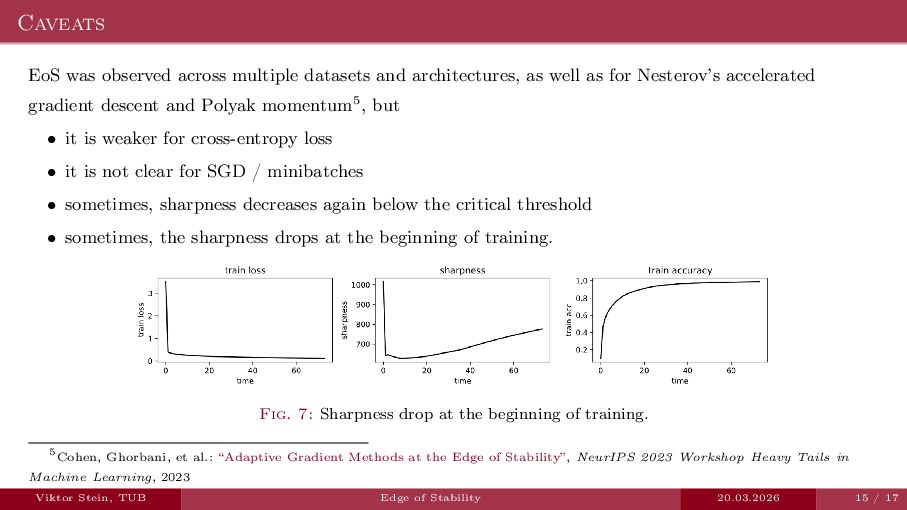
An expository talk about neural network training (progressive sharpening, edge of stability, self-stabilization) based on the two papers "Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability" by Damian et al., and "Gradient descent on neural networks typically occurs at the edge of stability" by Cohen et la.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Bibliography [1] D. Kingma and J. Ba, “Adam: A method](https://files.speakerdeck.com/presentations/7ca82ee2d7a144f6bc712bc6a8c4dfe4/slide_26.jpg){kind=link}