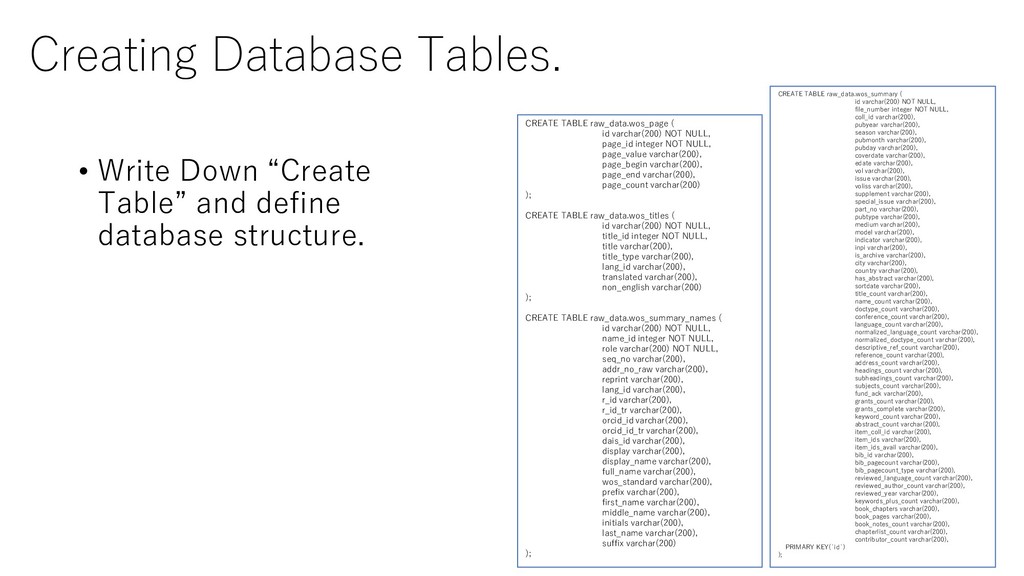
database structure. CREATE TABLE raw_data.wos_summary ( id varchar(200) NOT NULL, file_number integer NOT NULL, coll_id varchar(200), pubyear varchar(200), season varchar(200), pubmonth varchar(200), pubday varchar(200), coverdate varchar(200), edate varchar(200), vol varchar(200), issue varchar(200), voliss varchar(200), supplement varchar(200), special_issue varchar(200), part_no varchar(200), pubtype varchar(200), medium varchar(200), model varchar(200), indicator varchar(200), inpi varchar(200), is_archive varchar(200), city varchar(200), country varchar(200), has_abstract varchar(200), sortdate varchar(200), title_count varchar(200), name_count varchar(200), doctype_count varchar(200), conference_count varchar(200), language_count varchar(200), normalized_language_count varchar(200), normalized_doctype_count varchar(200), descriptive_ref_count varchar(200), reference_count varchar(200), address_count varchar(200), headings_count varchar(200), subheadings_count varchar(200), subjects_count varchar(200), fund_ack varchar(200), grants_count varchar(200), grants_complete varchar(200), keyword_count varchar(200), abstract_count varchar(200), item_coll_id varchar(200), item_ids varchar(200), item_ids_avail varchar(200), bib_id varchar(200), bib_pagecount varchar(200), bib_pagecount_type varchar(200), reviewed_language_count varchar(200), reviewed_author_count varchar(200), reviewed_year varchar(200), keywords_plus_count varchar(200), book_chapters varchar(200), book_pages varchar(200), book_notes_count varchar(200), chapterlist_count varchar(200), contributor_count varchar(200), PRIMARY KEY(`id`) ); CREATE TABLE raw_data.wos_page ( id varchar(200) NOT NULL, page_id integer NOT NULL, page_value varchar(200), page_begin varchar(200), page_end varchar(200), page_count varchar(200) ); CREATE TABLE raw_data.wos_titles ( id varchar(200) NOT NULL, title_id integer NOT NULL, title varchar(200), title_type varchar(200), lang_id varchar(200), translated varchar(200), non_english varchar(200) ); CREATE TABLE raw_data.wos_summary_names ( id varchar(200) NOT NULL, name_id integer NOT NULL, role varchar(200) NOT NULL, seq_no varchar(200), addr_no_raw varchar(200), reprint varchar(200), lang_id varchar(200), r_id varchar(200), r_id_tr varchar(200), orcid_id varchar(200), orcid_id_tr varchar(200), dais_id varchar(200), display varchar(200), display_name varchar(200), full_name varchar(200), wos_standard varchar(200), prefix varchar(200), first_name varchar(200), middle_name varchar(200), initials varchar(200), last_name varchar(200), suffix varchar(200) );
![経済学のための実践的データ分析 6. データを解析するまでに必要な Web スクレイピングやデータの作成 やデータベース設計などの話 28教室 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/2d4d16af5dc643b596df1a196dbe6a16/slide_0.jpg){kind=link}
{kind=link}
![今日の内容 (人力や Web スクレイピングや RPA で)データを集めてきて処理をするまでの 長く険しい道 [座学、実習] • データといっても、そのほとんどは実のところ定型化されてい](https://files.speakerdeck.com/presentations/2d4d16af5dc643b596df1a196dbe6a16/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
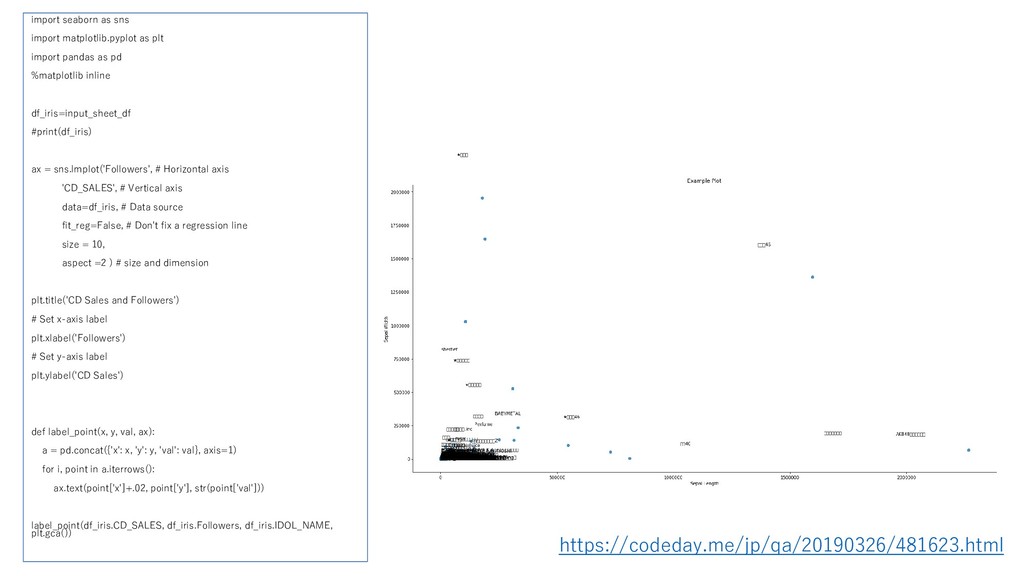
![equation_df=pd.concat([cd, followers], axis=1) sns.heatmap(equation_df, vmax=5000) filtered = cd[(cd >= 0)](https://files.speakerdeck.com/presentations/2d4d16af5dc643b596df1a196dbe6a16/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
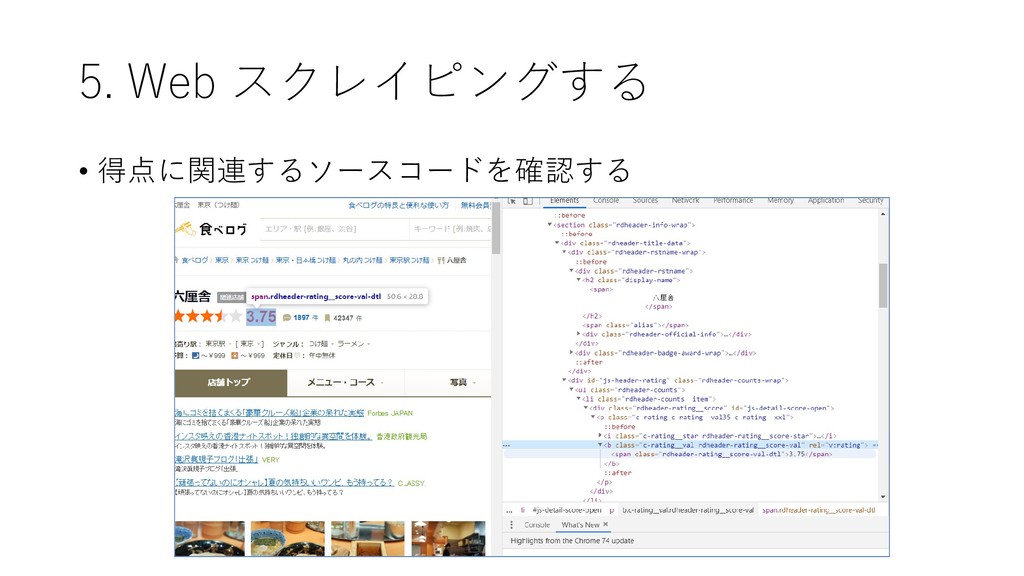{kind=link}
{kind=link}
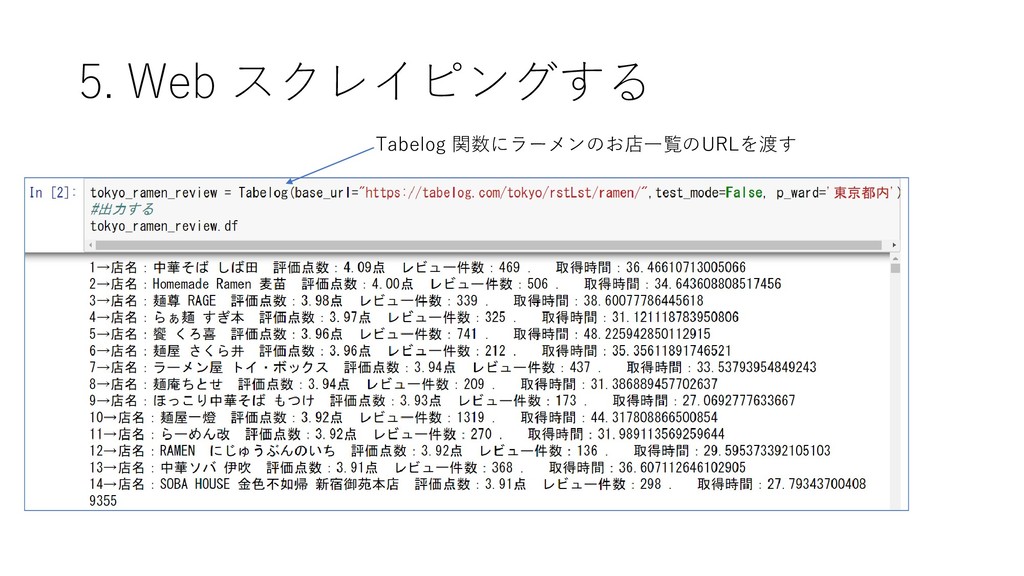{kind=link}
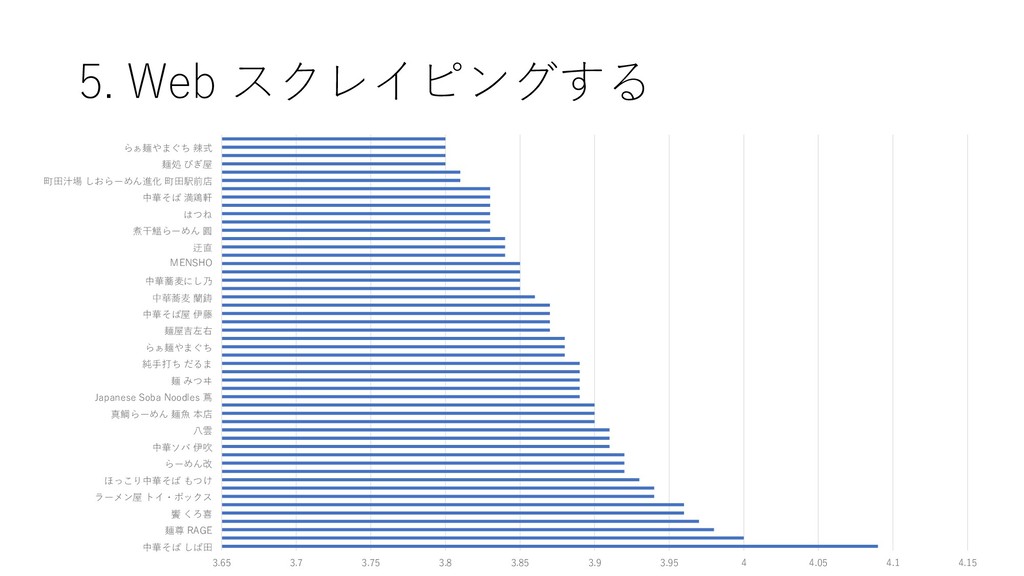{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![次回: データベースを用いた分析(2) 論文 データベース [座学、実習] • Clarivate Analytics 社が提供する Web](https://files.speakerdeck.com/presentations/2d4d16af5dc643b596df1a196dbe6a16/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/2d4d16af5dc643b596df1a196dbe6a16/slide_91.jpg){kind=link}