in each language at the part-of- speech level differ in systematic ways • by considering multiple language simultaneously, ambiguity can be reduced in each language 2
languages • The structure of each language becomes more apparent • Model – hierarchical Bayesian model for jointly predicting bilingual sequences part-of-speech tags • Evaluation - on six pairs of languages • Result - significant performance gains over a state-of-the- art monolingual baseline 3
ambiguity inherent in part-of-speech tag assignments differ across languages • At the lexical level, • An ambiguous word in one language may correspond to an unambiguous word in the other language. • For example, • English - “can” - auxiliary verb / noun / verb • Serbian - each POS is expressed with a distinct lexical item • At the structural level • English - articles (a, an, the ) greatly reduces the ambiguity of the succeeding tag. • Serbian - a language without articles 4
tags parallel text in two languages • Parameters are learned using an untagged bilingual parallel text • the model is applied to a held-out monolingual test set 5
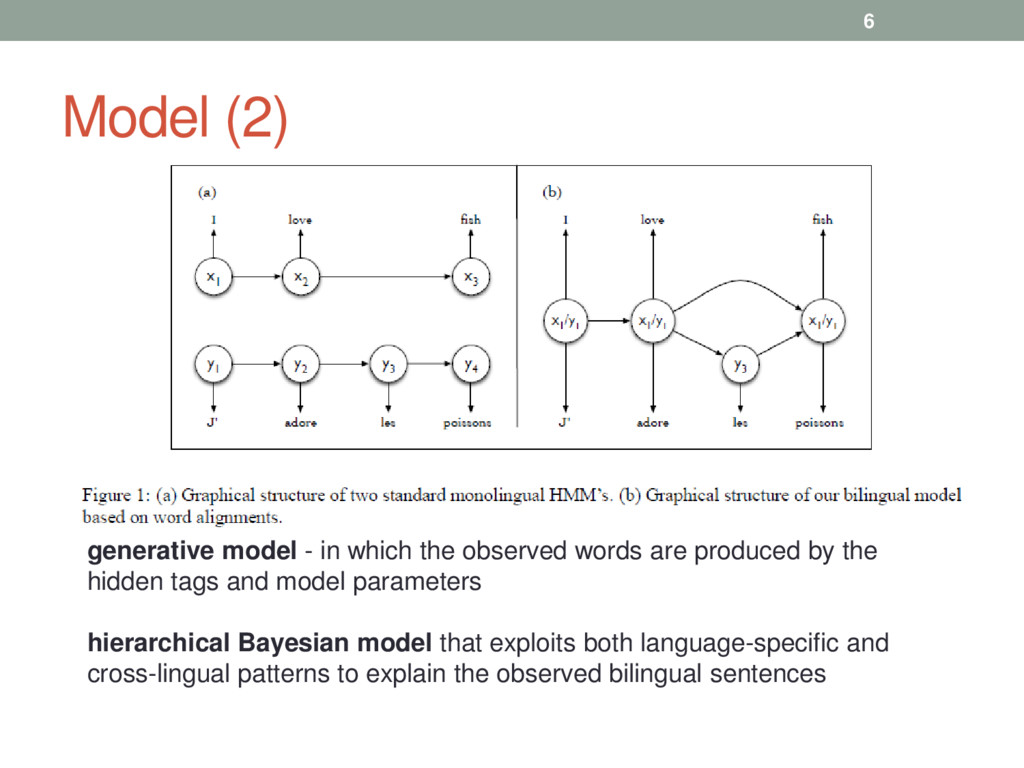
words are produced by the hidden tags and model parameters hierarchical Bayesian model that exploits both language-specific and cross-lingual patterns to explain the observed bilingual sentences
share similar semantic or syntactic function, the associated tags will be statistically correlated • word pairs - allow cross-lingual information to be shared via joint tagging decisions • Word alignment – machine translation to identify these aligned words • model treats aligned-words as observed data • for unaligned parts of the sentence, the tag and word selections are identical to monolingual HMM’s. 7
and T′, and two vocabularies W and W′, one of each for each language (L and L′ ) • Probabilities are drawn from symmetric Dirichlet priors 1. draw emission and transition distribution for language L 2. draw emission and transition distribution for language L′ 3. draw a bilingual coupling distribution over tag pairs T × T′ 4. For each language (a) Draw an alignment (b) Draw a bilingual sequence of part-of-speech tags (x1, ..., xm), (y1, ..., yn) (c) For each part-of-speech tag xi in the first language, emit a word from W (d) For each part-of-speech tag yj in the second language, emit a word from W ′ 8
sets of transition parameters ∅ and ∅′, - conditional probability of a bilingual tag sequence (x1, ...xm), (y1, ..., yn) are factored into transition probabilities for unaligned tags, and joint probabilities over aligned tag pairs - The distribution over aligned tag pairs is defined as a product of each language’s transition probability and the coupling probability: - – multilingual anchor Z = normalization constant
conditional distributions 10 n(xi) is the number of occurrences of the tag xi in x−i, n(xi, ei) is the number of occurrences of the tag-word pair (xi, ei) in (x−i, e−i) Wxi is the number of word types in the vocabulary W that can take tag xi.
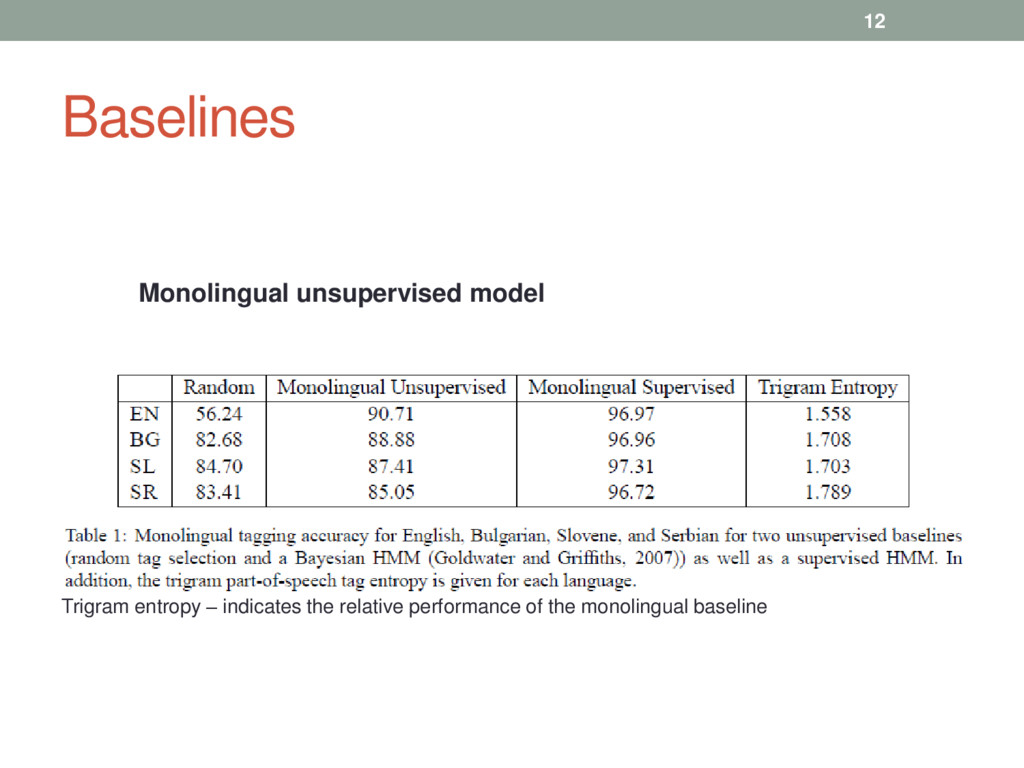
a set of possible tags for each word type), • when only incomplete dictionaries are available • model is trained using untagged text • Parallel data - Orwell’s novel “Nineteen Eighty Four” • Original – English • Translation - Bulgarian, Serbian and Slovene • Training data – random ¾ • Test data – ¼ • Word-alignment - GIZA++ 11
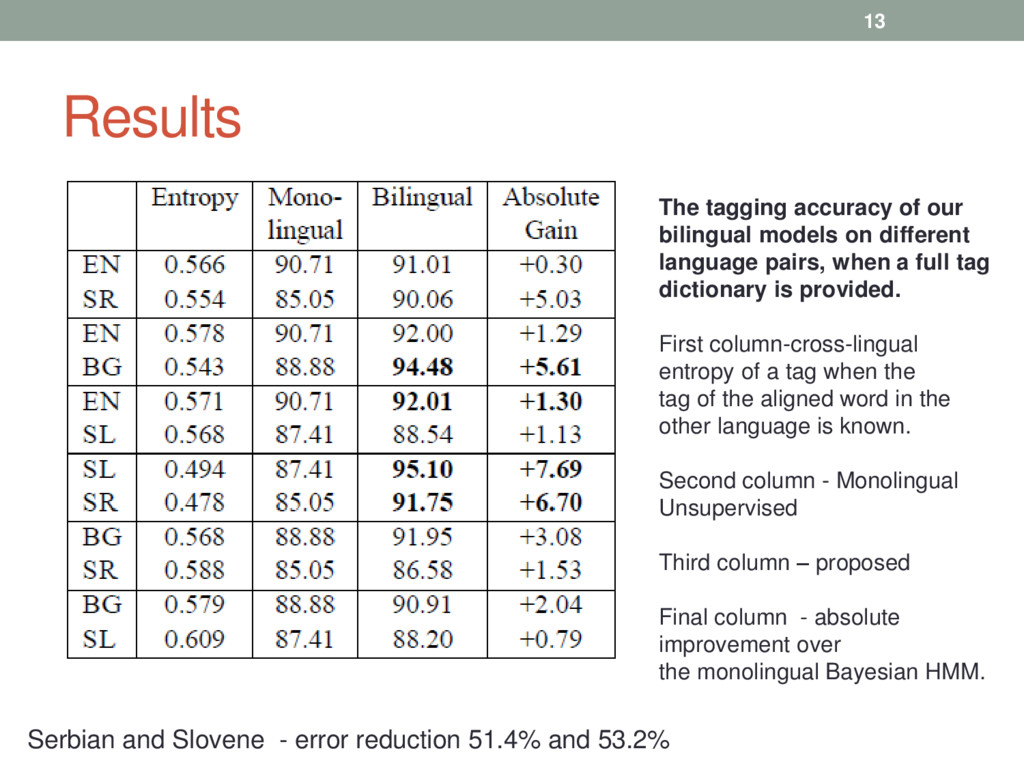
different language pairs, when a full tag dictionary is provided. First column-cross-lingual entropy of a tag when the tag of the aligned word in the other language is known. Second column - Monolingual Unsupervised Third column – proposed Final column - absolute improvement over the monolingual Bayesian HMM. Serbian and Slovene - error reduction 51.4% and 53.2%
part-of-speech tagging • by combining cues from multiple languages, the structure of each becomes more apparent • built model that learns language-specific features while capturing cross-lingual patterns in tag distribution • evaluation shows significant performance gains over a state-of-the-art monolingual baseline. 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}