Unsupervised morphological segmentation and clustering with document boundaries
Taesun Moon, Katrin Erk, and Jason Baldridge
Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 668–677, Singapore, 6-7 August 2009. (c) 2009 ACL and AFNLP
Katrin Erk, and Jason Baldridge Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 668–677, Singapore, 6-7 August 2009. (c) 2009 ACL and AFNLP --------------------------------------------------------------- OCT 18, 2016 Nagaoka University of Technology Natural Language Processing Lab
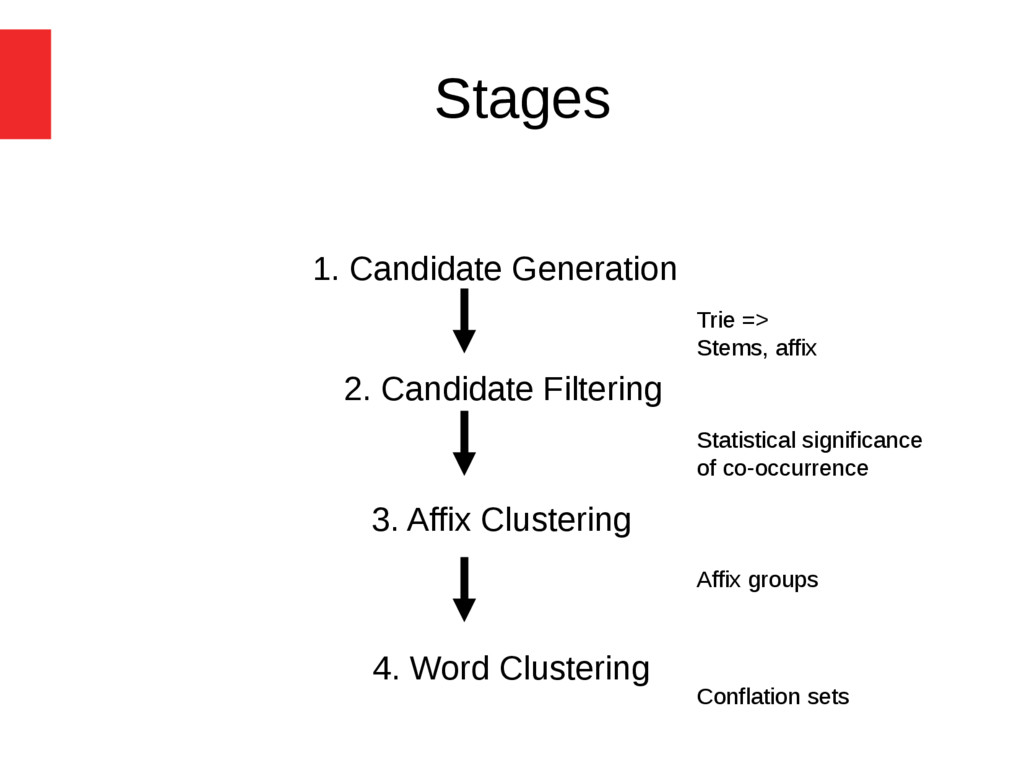
tuning Use of document boundary to constraint generation of candidate stems, affixes and clustering morphological variants method that works for under-resourced languages (where data-driven tuning is unlikely because data are scarce) Motivation
from text Segmentation of words Clustering of words Generation of OOV terms Approach (a) the filtering of affixes by significant co- occurrence (b) use of document boundaries when generating candidate stems and affixes and when clustering morphologically related words.
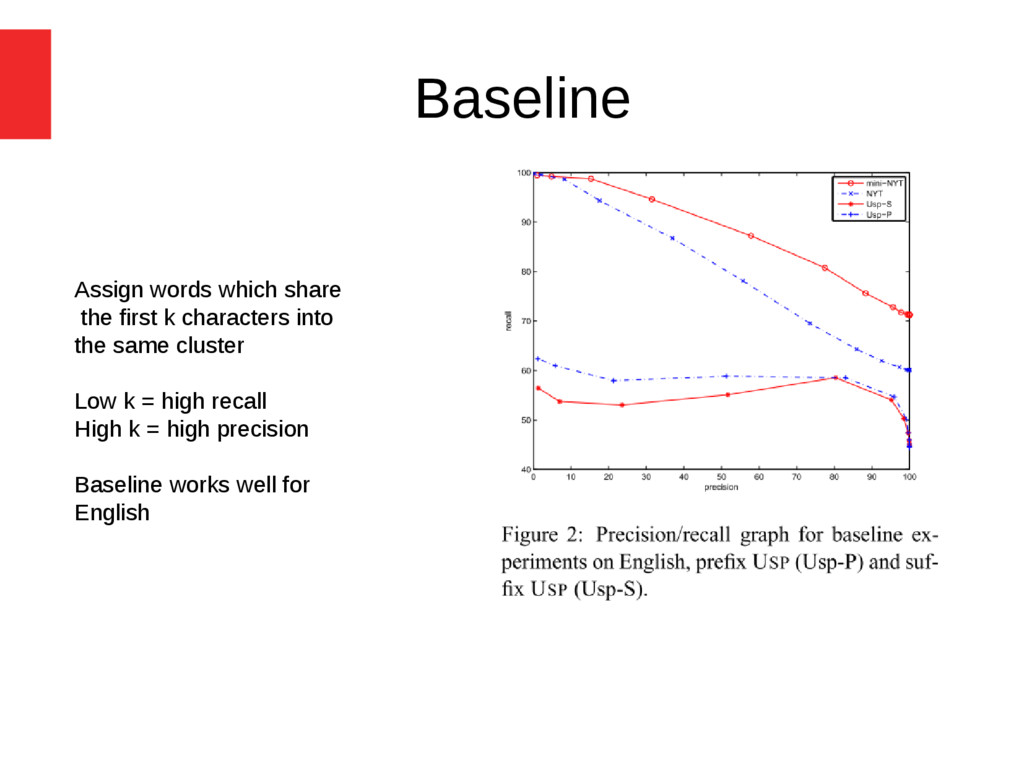
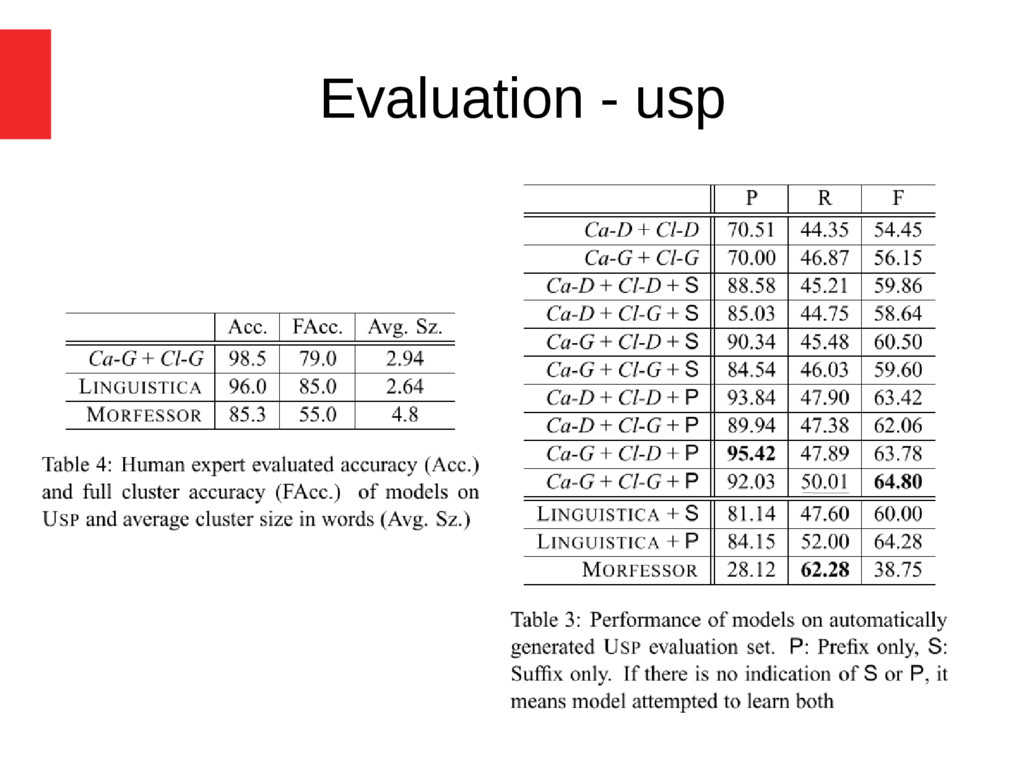
document are very similar in terms of orthography, then the two words are likely to be related morphologically (term-document statistical correlation) Languages - English and Uspanteko (Mayan language of Guatemala) Result - better results compared to Linguistica and Morfessor
constraint that should reduce noise (similar to Yarowsky 1995, WSD) e.g. “assuage”, “assume” “assu” [corpus] “assuming”, “assumed”, “assumes” [document] built separate trie for each document D (CandGen-D) or one global trie G for the entire corpus (CandGen-G) Similarly, Clust-D and Clust-G
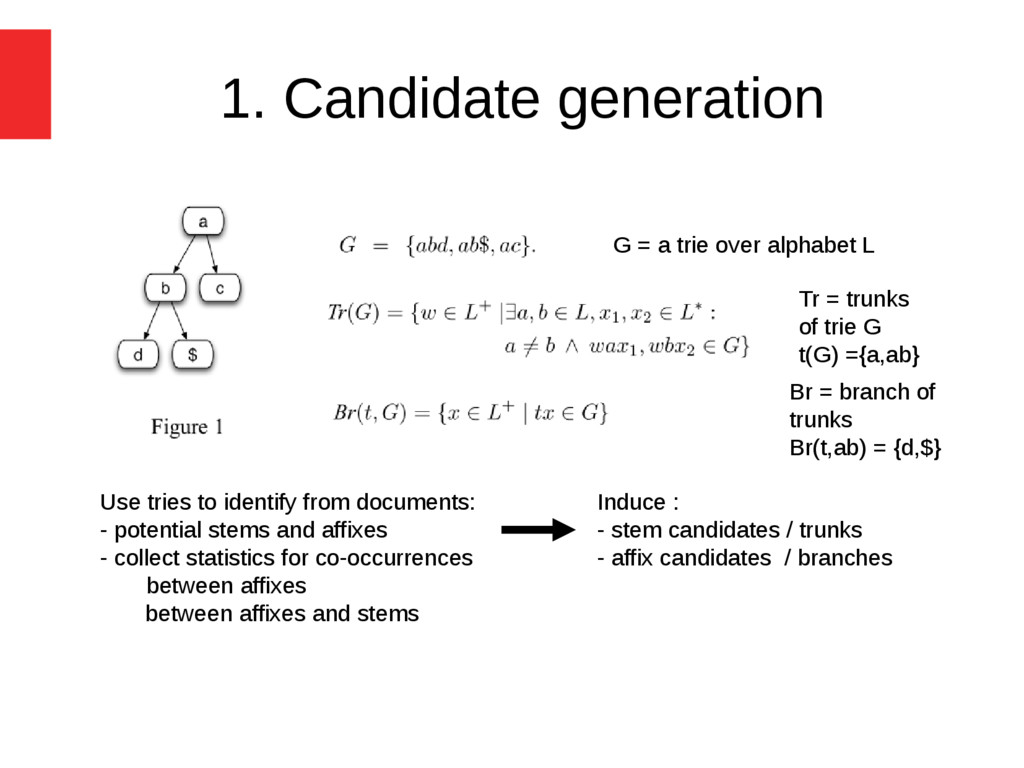
potential stems and affixes - collect statistics for co-occurrences between affixes between affixes and stems G = a trie over alphabet L Tr = trunks of trie G t(G) ={a,ab} Br = branch of trunks Br(t,ab) = {d,$} Induce : - stem candidates / trunks - affix candidates / branches
(stage-1) produce noise Statistical correlation between branches (affixes) b 1 and b 2 with X2 test pairwise comparison is used for filtering (rather than global inference) p < 0.05, X2 test significance Any affix candidates not statistically correlated with other affix in the set of affix candidates is discarded
(1) they occurred in the same trie G, (2) they have a trunk s in common that is a stem in Stem(G) (3) their affixes under stem s are members in a common valid affix cluster
88K types and 9M tokens MINI-NYT = is a subset of NYT with 190 articles, 15K types and 187K tokens. Test CELEX inflectional data Uspanteko text Training 29 distinct texts, 7K types, and 50K tokens Test Documentation data, manually
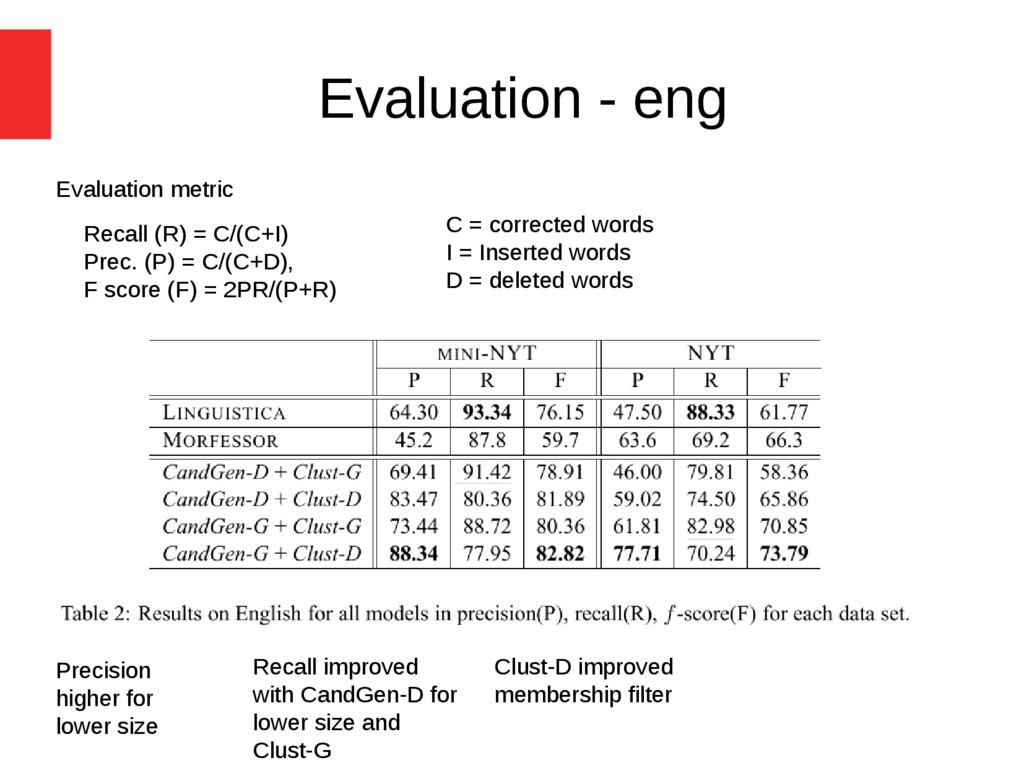
= Inserted words D = deleted words Recall (R) = C/(C+I) Prec. (P) = C/(C+D), F score (F) = 2PR/(P+R) Precision higher for lower size Recall improved with CandGen-D for lower size and Clust-G Clust-D improved membership filter
and correlation tests are used for filtering stems and affixes promising for under-resourced languages result shows good improvement over existing methods Future direction: textual distance to estimate likelihood of morphological relatedness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}