Adrien Lardilleux and Yves Lepage
GREYC, University of Caen Basse-Normandie, France
International Conference RANLP, 2009
Borovets, Bulgaria, pages 214–218
terms to extract high quality multi-word alignments • Method – random sampling of perfect alignments from numerous sub-corpora • Results – competetive with GIZA++ in quality with lower processing time and higher coverage 2
address the issues of quality • Some other issues worth exploring are • Simultaneous multi-lingual alignment • Scaling up, coverage and processing time • Integration with real applications 3
high frequency terms have higher significance • Avoiding indefinite data increment - safe alignment of low frequency words • Convert high frequency terms to low frequency by decreasing data (as opposed to increasing data) increase data Low frequency High frequency High frequency Low frequency increase data 4
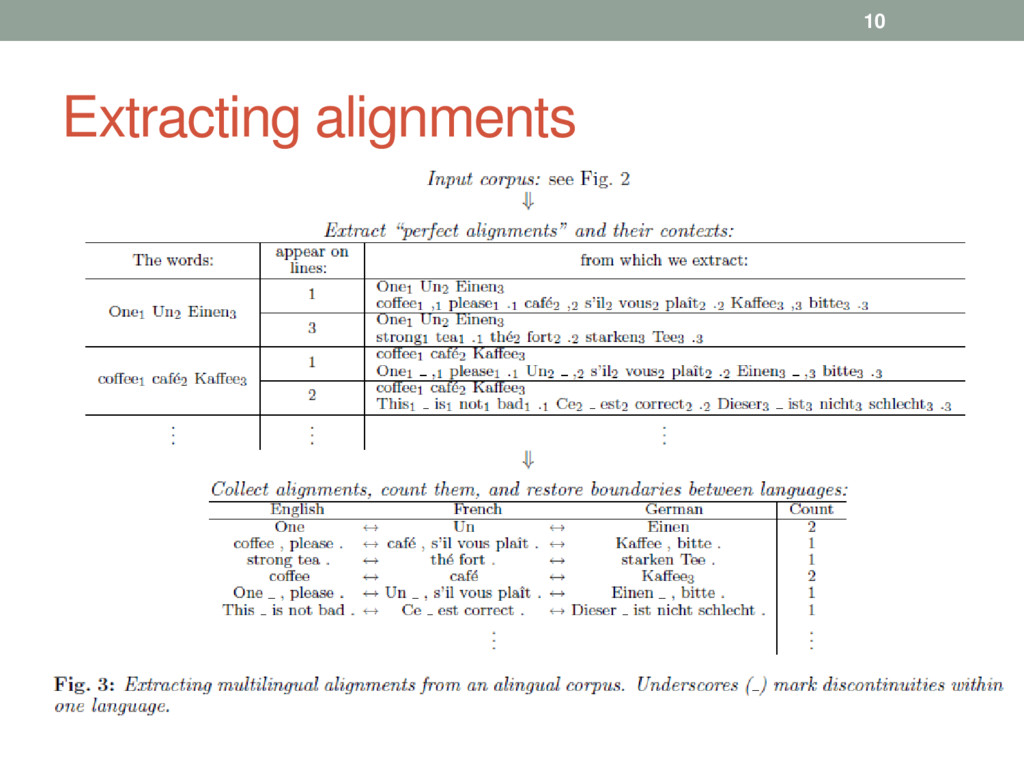
found only once in their corpus • Represent ~ 50% of the vocabularies • Hapax are aligned using an assumption of lexical equivalence • By filtering inputs sentences • High frequency terms are converted to low frequency terms • The terms reduced to hapaxes form translation pairs • Perfect alignments can be extracted 5
particular sentence is chosen is k/n; • the probability that this sentence is not chosen is 1 − k/n; • the probability that none of the k sentences is chosen is (1 − k/n) ^ k; • the probability that none of these k sentences is ever chosen is (1 − k/n) ^ kx. • Hence, the number of random subcorpora of size k to create by sampling yields • (1 <= k <= n) , n = size of alingual corpus, k = size of subcorpora, x = number of subcorpora, t = threshold for choosing a sentence 8
created by removing input data • Sampling is random, the size of sub-corpora to process is given by • To ensure coverage, alignments are extracted from numerous sub corpora • at least x random sub-corpora of size k • Processing a sub corpora is faster and parallel processing is possible, 9
language and all the other remaining languages. • Si – sequence of words of language i • S1---SL (1<= i <= L) – sequence of words of target languages 11
• evaluates how each source word translates into the target words it links to. • Each language becomes the source in turn, and the rest of the alignment is assimilated to the target. • The lexical weights generated are as many as the languages, the weight their product • The sampling-based approach does not only link words but also sequence of words 13
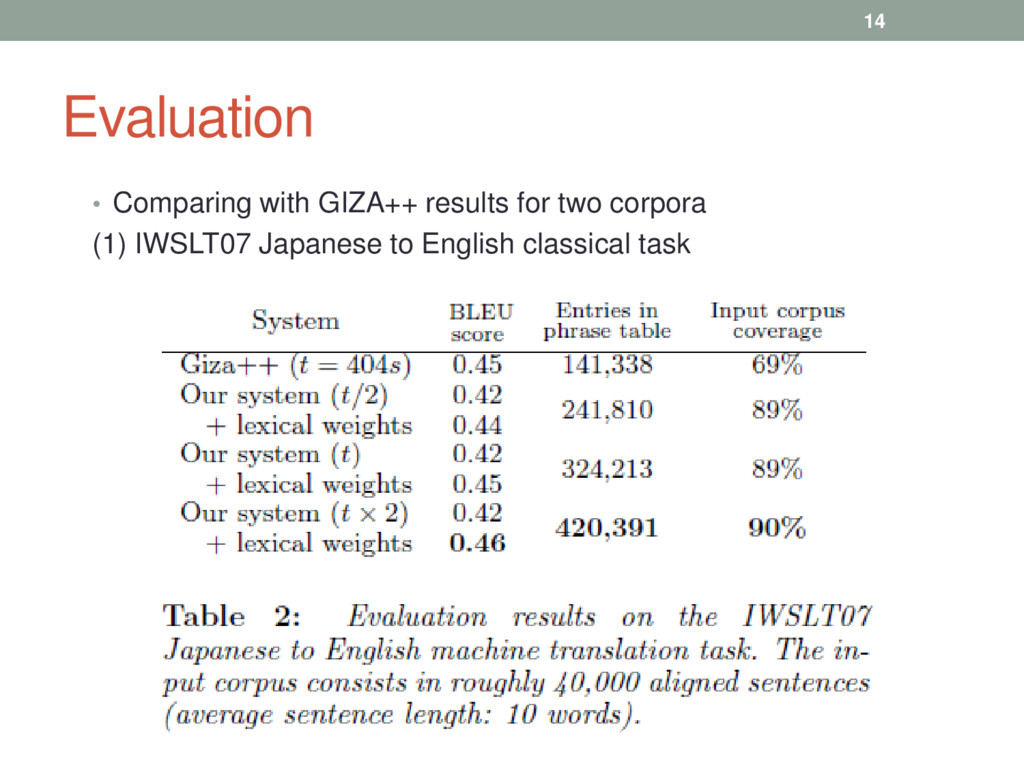
be aligned simultaneously from parallel corpora. • The algorithm relies on the use of low frequency terms • The sample-based approach produces high quality translation. • The method can match the accuracy of Giza++ while having a much higher coverage of input data, and being by far simpler 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}