Large-scale Dictionary Construction via Pivot-based Statistical Machine Translation with Significance Pruning and Neural Network Features
Raj Dabre, Chenhui Chu, Fabien Cromieres, Toshiaki Nakazawa, Sadao Kurohashi
Graduate School of Informatics, Kyoto University
Japan Science and Technology Agency
Pruning and Neural Network Features Raj Dabre , Chenhui Chu , Fabien Cromieres , Toshiaki Nakazawa , Sadao Kurohashi Graduate School of Informatics, Kyoto University Japan Science and Technology Agency 29th Pacific Asia Conference on Language, Information and Computation pages 289 - 297 Shanghai, China, October 30 - November 1, 2015 1 Jan 13, 2016 – Nagaoka University of Technology – NLP Lab.
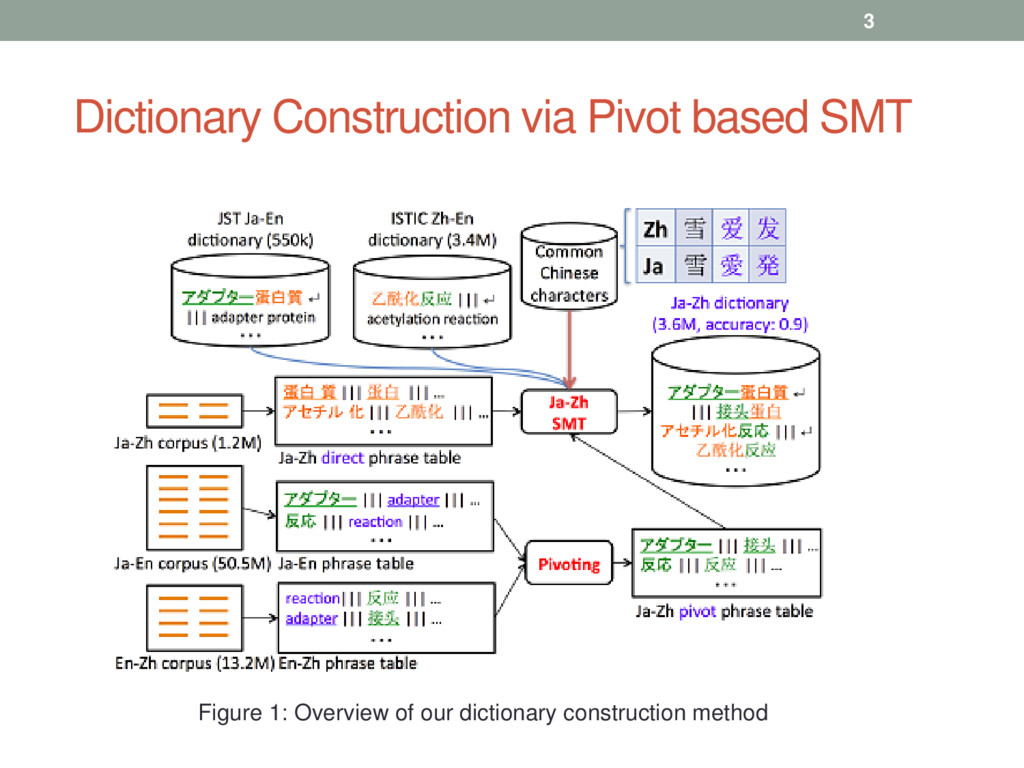
between languages source->pivot and pivot->target, pivot-based translation may be used to construct source->target term translation model for dictionaries. • Aim-constructing a large-scale Japanese-Chinese (Ja-Zh) scientific dictionary • Data (Ja-En) (49.1M sentences and 1.4M terms) (En-Zh) (8.7M sentences and 4.5M terms) • Method - a combination of SMT pivoting, statistical significance pruning and Chinese character features • Result – high quality large-scale dictionary with 3.6M Ja- Zh terms 2
triangulation method • generates a source-target phrase table via all their shared pivot phrases in the source-pivot and pivot-target tables. • Formulae for inverse phrase translation probabilities ϕ(f|e) and direct lexical weightings lex(f|e) • a1 is the alignment between phrases f (source) and pi (pivot) • a2 is the alignment between pi and e (target) • a is the alignment between e and f. • prune all pairs with ϕ(f|e) less than 0.001 4
the phrase table is noisy (bad translation), the pivoted phrase table gives even noisier tables • Pruning is required for noisy/bad phrase table • Statistical significance pruning eliminates a large amount of noise (applied before pivoting) • p-value (significance value) of the phrase pair is computed and the pair is retained if this exceeds a threshold α+ε [Johnson et al., 2007] • Pruning all pairs lower than threshold may lead to an out- of-vocabulary (OOV) problem. In case of OOV , the top 5 phrase pairs are retained 5
for each phrase pair the following two features are computed • where char num, CC num and CCC num denote the number of characters, Chinese characters and Common Chinese characters in a phrase respectively. 6
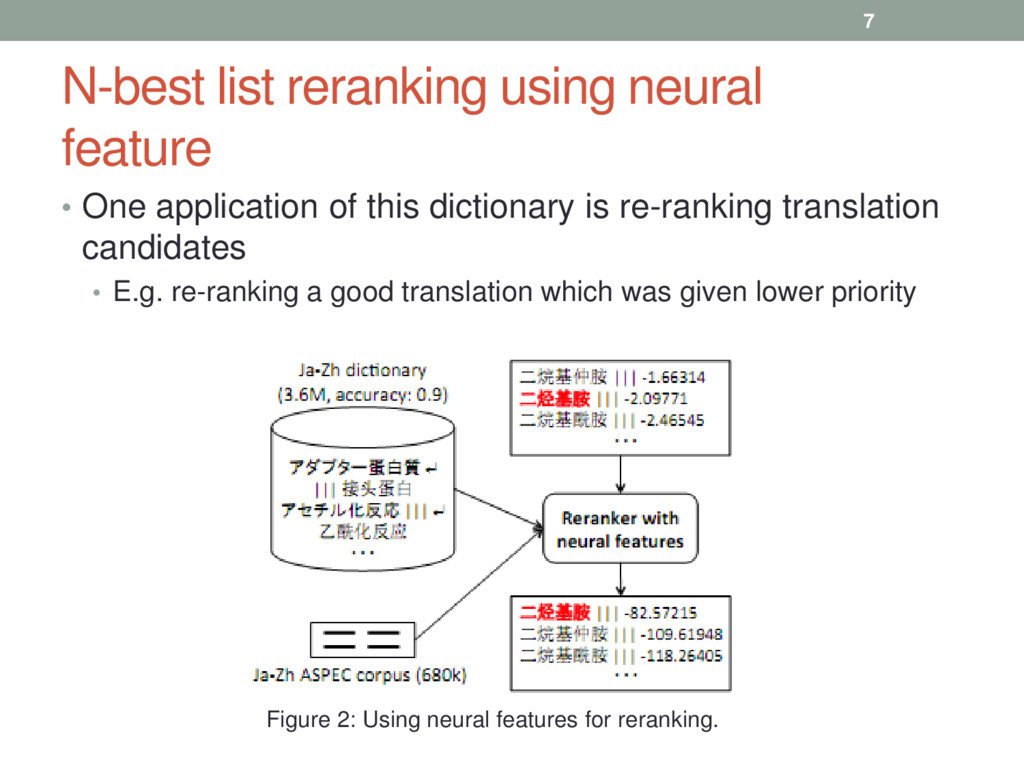
this dictionary is re-ranking translation candidates • E.g. re-ranking a good translation which was given lower priority 7 Figure 2: Using neural features for reranking.
created dictionary is quite noisy • Neural networks are effective in regulating noise • Character level BLEU as well as word level BLEU are used as re-ranking metrics. • 1. For each input term in the test set: (a) Obtain neural translation scores for each translation candidate and append to features (b) (b) Perform the linear combination of the learned weights and the features to get a model score • 2. Sort the n-best list for the test set using the calculated model scores • SVM classification was also used for reranking with similar procedures 8
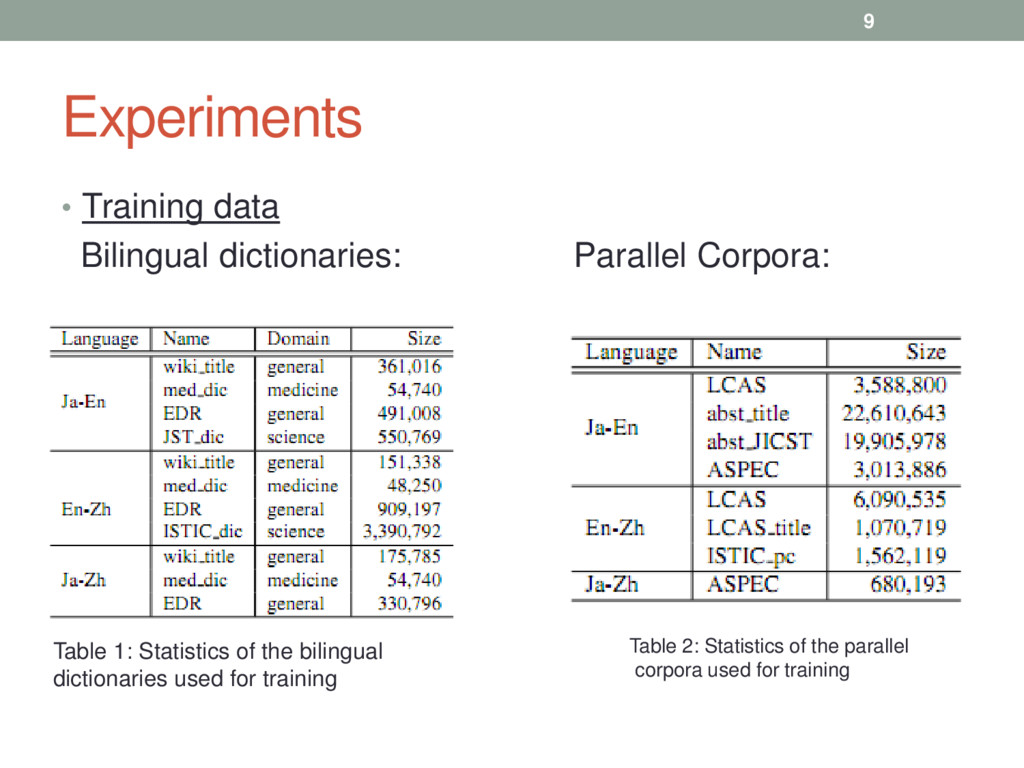
reference translations in the Ja-Zh Iwanami biology dictionary (5,890 pairs) and the Ja-Zh life science dictionary (4,075 pairs) • Half of the data was used for tuning and the other half for testing Settings: • Segmentation - Shen et al. (2014) and JUMAN • Decoding – Moses • Training - a 5-gram language model using the SRILM toolkit 10
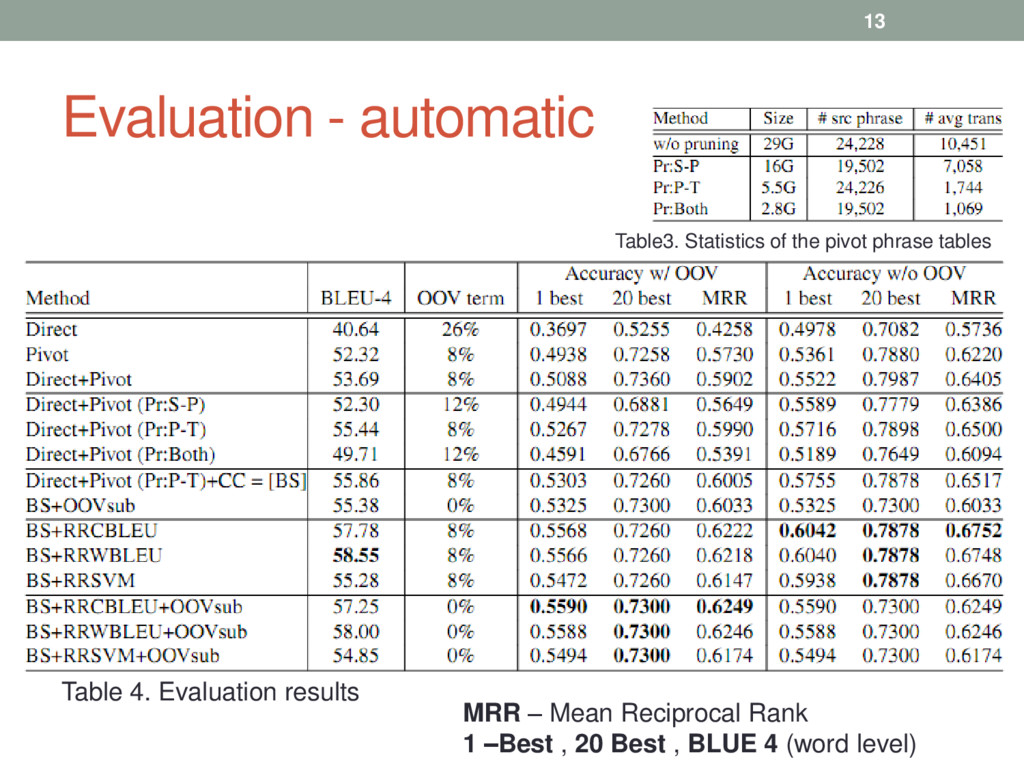
to train a direct Ja-Zh model. • Pivot: Use the Ja-En and En-Zh data for training Ja-En and En-Zh models, and construct a pivot Ja-Zh model using the phrase table triangulation method. • Direct+Pivot: Combine the direct and pivot Ja-Zh models using MDP (Multiple Decoding Path) of Moses toolkit. • Significance pruning • Direct+Pivot (Pr:S-P):Pivoting after pruning the source-pivot table. • Direct+Pivot (Pr:P-T):Pivoting after pruning the pivot-target table. • Direct+Pivot (Pr:Both):Pivoting after pruning both the source-pivot and pivot-target tables. • (Pr:P-T) + CC (Chinese Character) = BS, Best Setting 11
+ Ja-Zh ASPEC corpus 1. BS+RRCBLEU: Using Character BLEU to ReRank the n-best list. 2. BS+RRWBLEU: Using Word BLEU to ReRank the n- best list. 3. BS+RRSVM: Using SVM to ReRank the n-best list. Similar experiments with OOVsub 1. …. +OOVsub: substituting the OOVs (after pruning) with the character level translations 12
incorrect according to automatic evaluation method • 75% of them were actually correct translations • actual 1 best accuracy is about 90%. • Undervalued because they were absent in the test data Evaluating the Large Scale Dictionary (3.6M entries) • 4 Ja-Zh bilingual speakers evaluated 100 randomly selected term pairs • Results indicate that 1 best accuracy is about 90%, which is consistent with the manual evaluation results on the test set.
Method - pivot-based SMT with significance pruning, Chinese character knowledge and bilingual neural network language model - based features re-ranking • Result – fairly high quality dictionary ( 90% of the terms are correctly translated) • Future plan - improving dictionary by learning a better neural bilingual language model through iterative re-rank process 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}