Peter A. Chew, Steve J. Verzi, Travis L. Bauer and Jonathan T. McClain
Sandia National Laboratories
P. O. Box 5800 Albuquerque, NM 87185, USA
Proceedings of the Workshop on Multilingual Language Resources and Interoperability, pages 68–74, Sydney, July 2006.
( c) 2006 Association for Computational Linguistic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
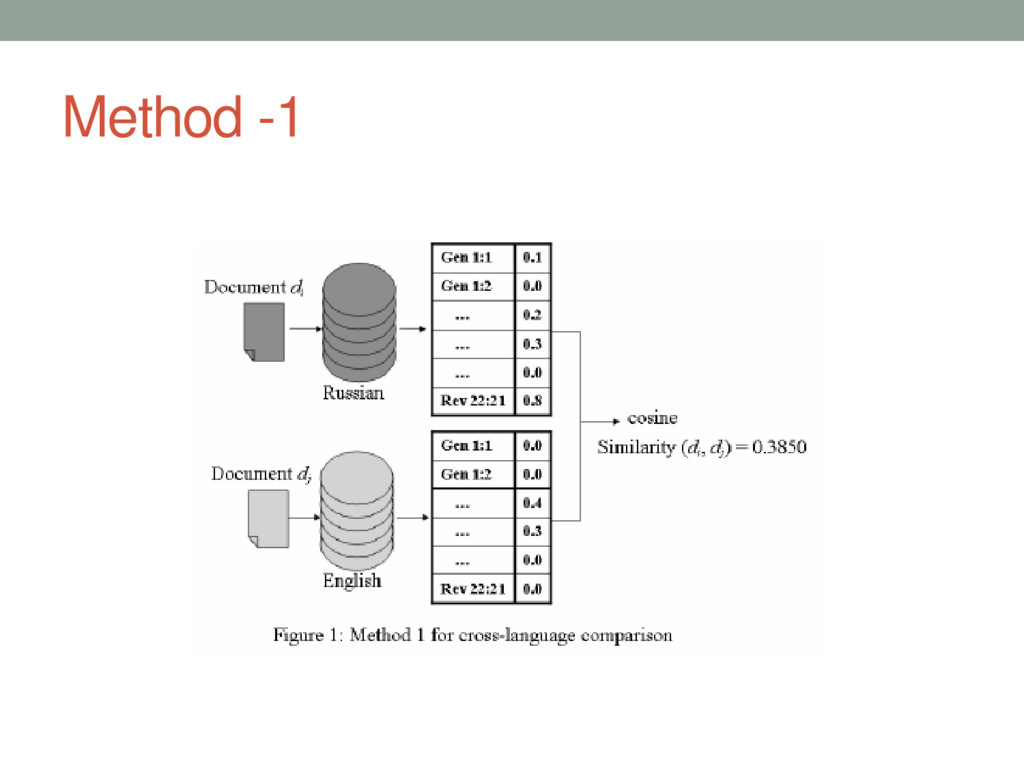{kind=link}
{kind=link}
{kind=link}
{kind=link}
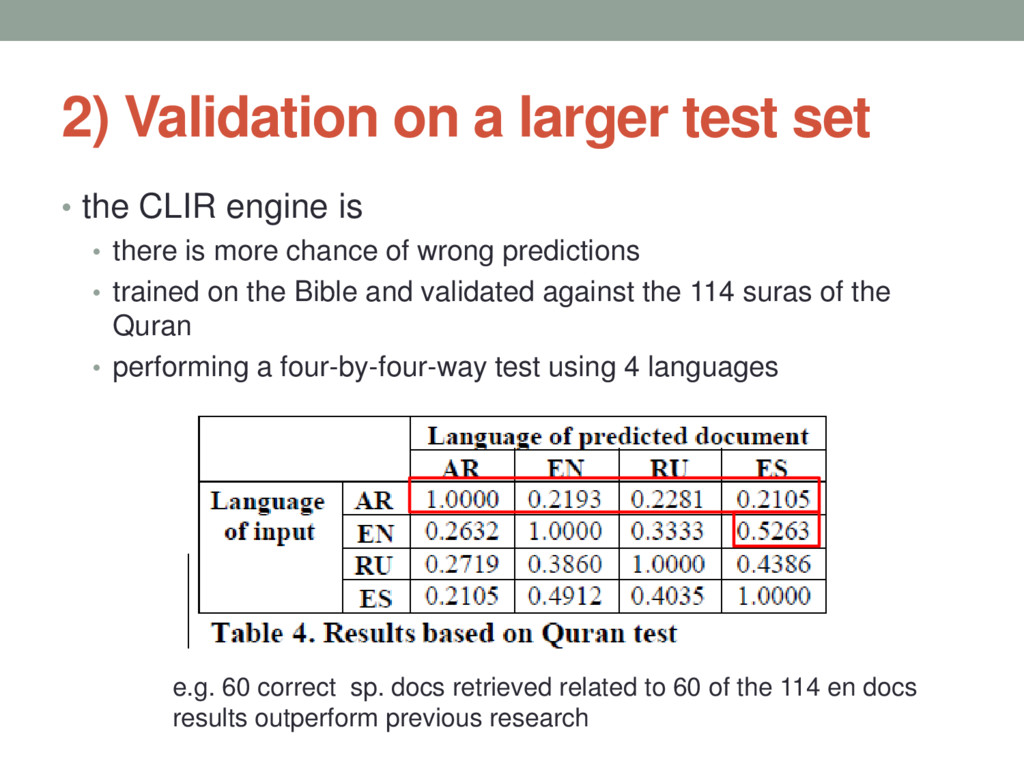{kind=link}
{kind=link}