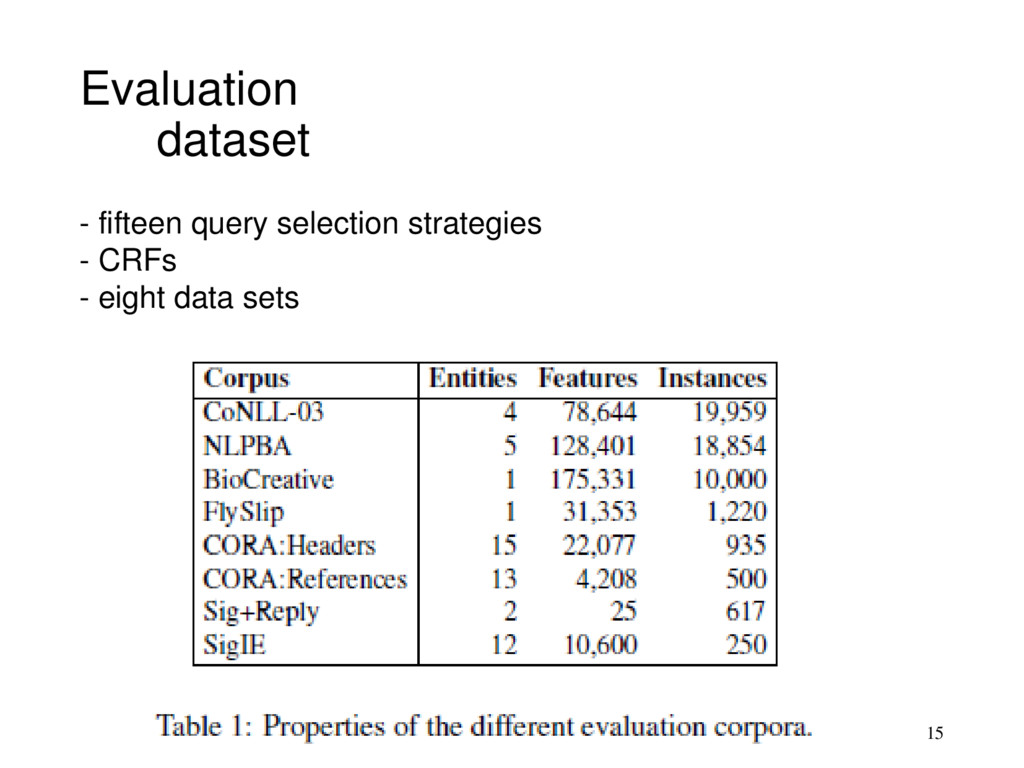
training labels can be expensive Active learning select instances to label and add to a training set Examples: Part-of-speech tagging, information extraction, document segmentation More attention of Active Learning has been given to classification tasks Linear chain CRFs (conditional random fields) are used for experiments of sequence labeling 3
pool U Labeled examples L query strategy φ(x) - determine how informative each instance is X∗ - the most informative instance according to some φ(x) 4
instance that a model is most uncertain on how to label Least confidence (LC) y * - viterbi parse, theta – parameters other methods are based on entropy 6
entropy of the model’s posteriors over its labeling P(yt =m) - marginal probability that m is the label at position t in the sequence, T- sequence length 1/T – normalizing querying long sequences 1.2 Total token entropy (TTE) [ proposed ] query long distance if more information exists 7
the entropy of the label sequence y as a whole possible labelings grows exponentially with the length of x 1.4 N-best SE N = {y1 , . . . , yN }, the set of the N most likely parses 8
. . . ,(C)} represent C different hypotheses - The most informative query: the instance over which the committee is in most disagreement about how to label 2.1 Vote Entropy (VE) where V (yt,m) is the number of “votes” label m receives from all the committee member’s Viterbi labelings at sequence position t - Other variants: (2.2) Sequence VE [proposed], (2.3) Kullback- Leibler (KL) divergence, (2.4) Sequence KL [proposed] 9
would provide the greatest change to the current model if we knew its label gradient of the log likelihood with respect to the model parameters the new gradient that would be obtained by adding the training tuple (x, y) to L 10
sampling and QBC and EGL are prone to querying outliers • e.g. least certain instance outlies on the classification boundary, but is not “representative” of other instances in the distribution 11
by its average similarity to all other sequences in U, • parameter β that controls the relative importance of the density term • sequence entropy SE measures the “base” informativeness 12
based on Fisher information [ Zhang and Oles (2000)] • Fisher information T() represents the overall uncertainty about the estimated model parameters 14
learning) • naively querying the longest sequence in terms of tokens • Features • includes words, orthographic patterns, part-of-speech, lexicons, etc. • N-best approximation, N = 15 • QBC methods, # committee C = 3 • For information density, B = 1 (i.e., the information and density terms have equal weight) • Initialized L, five random labeled instances to • 150 queries are selected from U in batches of size B =5 • five folds cross-validation 16
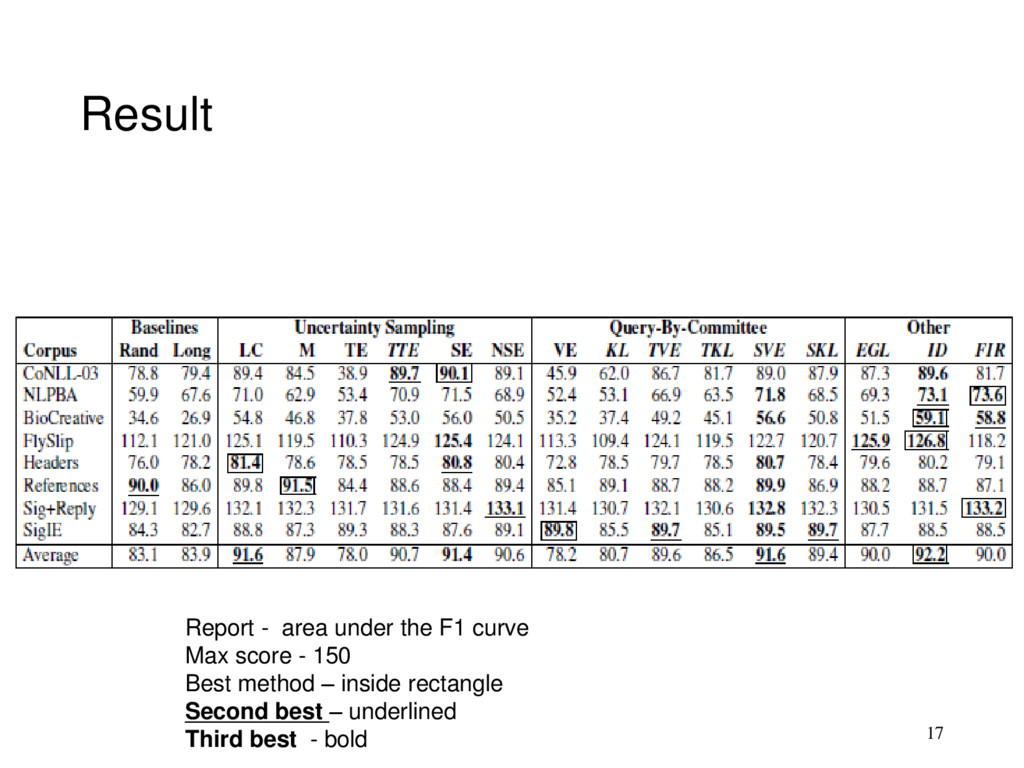
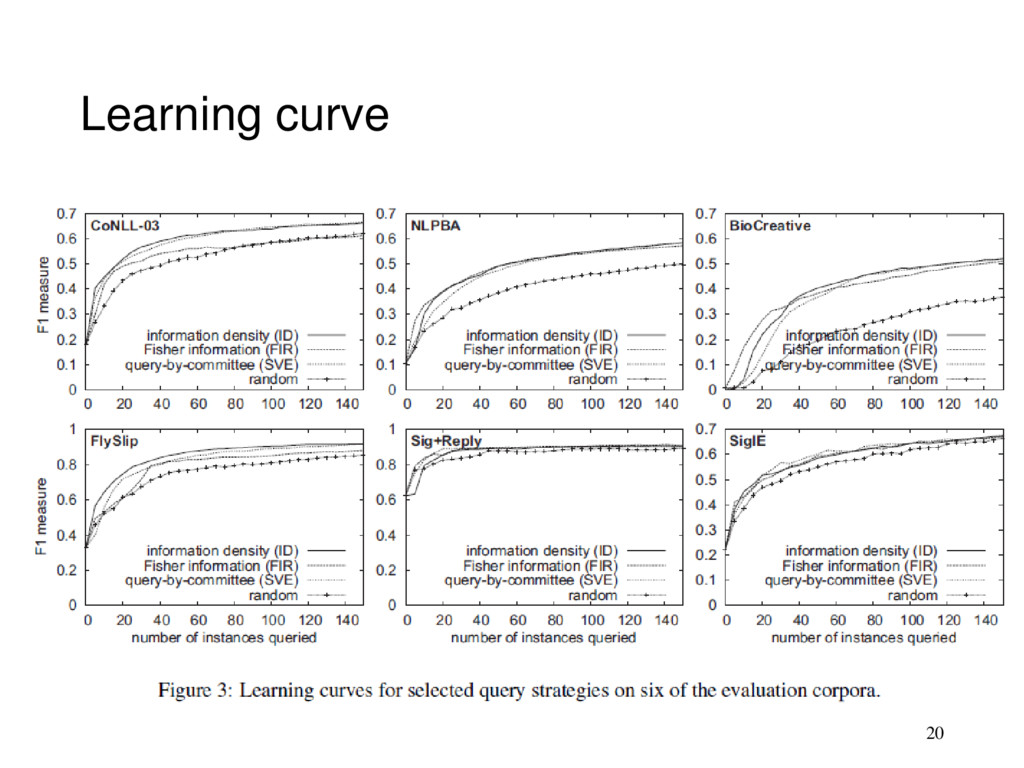
Information density (ID) performs well (for the most part) • Effective on large corpora, does not perform poorly, has highest AUC 2. based on informativeness measurement type • among uncertainty sampling • Sequence entropy (SE) and Least confidence (LC) perform best • among QBC • Sequence vote entropy (SVE) is the best • The 3 measure are best for use as base information measures with Information density (ID) 18
•proposed several novel strategies to address some of previous work shortcomings •conducted large-scale empirical evaluation and showed the methods that advance in active learning •The methods include information density (recommended) sequence vote entropy, and Fisher information. 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}