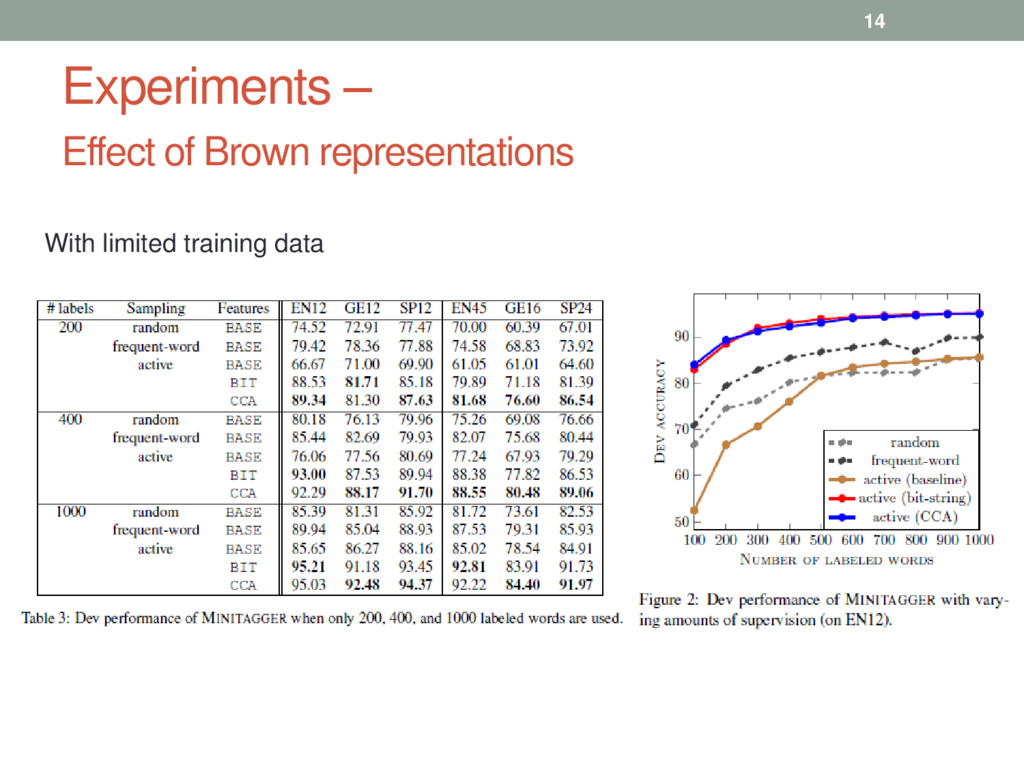
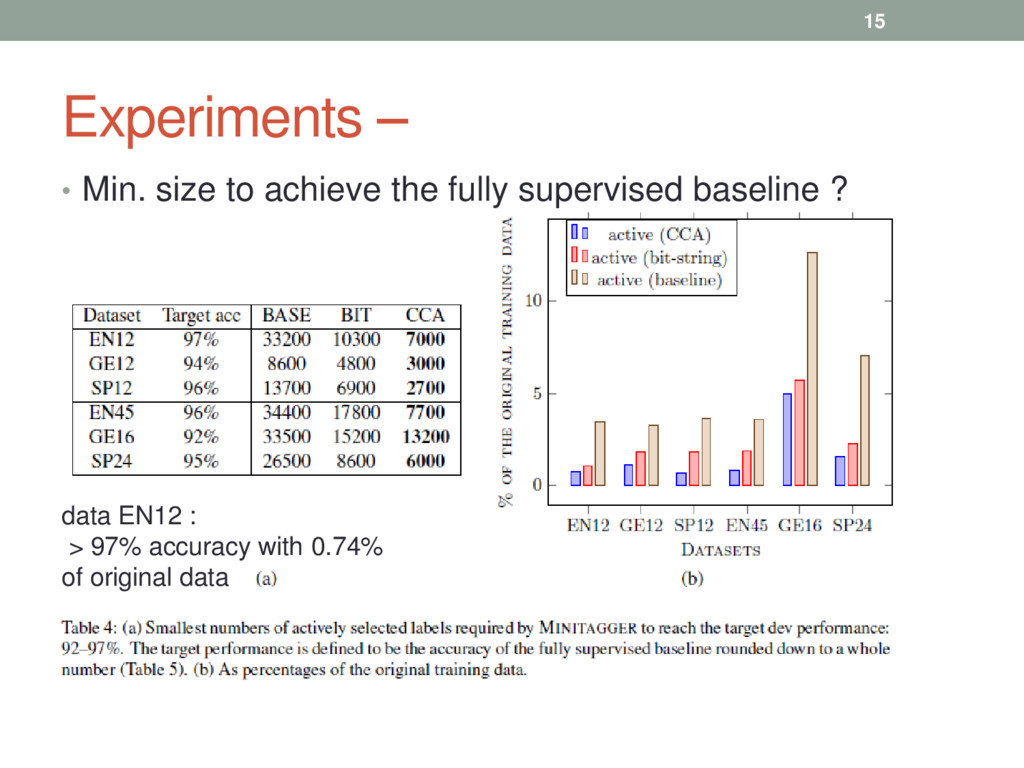
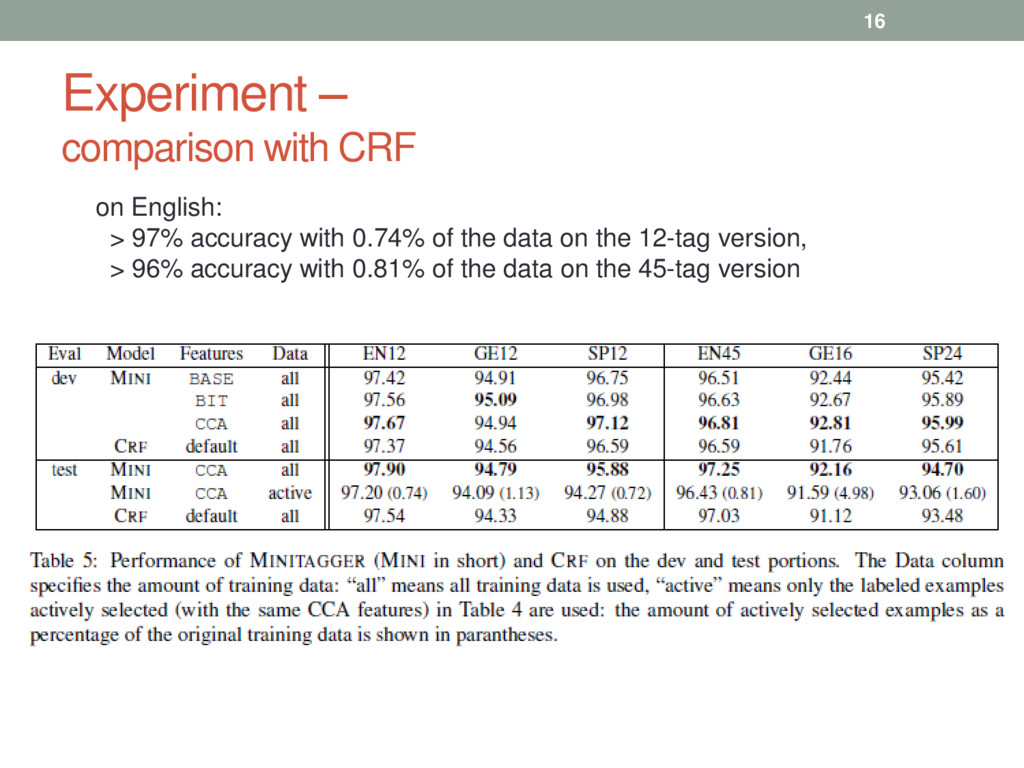
required to achieve state-of-the-art POS accuracy • Motivation • POS tags are almost deterministic • Brown et. al. word clustering method reveals the underlying POS tag information of words • Method - Discriminative classifier + active learning • Result • tagging accuracy of 93% with just 400 labeled words • tagging accuracy of 97.03% with just 0.74% of the original training data [English dataset] 3
such as verbs, nouns …etc. • POS tagging maybe performed through • Supervised, Unsupervised, Semi-supervised learning approaches • Fully supervised POS tagging is considered as a SOLVED problem • This is not the case for Unsupervised POS tagging • The previous works • complicated by varying assumptions and unclear evaluation metrics • not good enough to be practical ( accuracy is low) 4
like ‘set’ are ambiguous (verb ?, noun ?) • Some are deterministic – e.g. ‘the’ is always a determiner • Deterministic mapping f : w t • count (w,t) – count of word w , tagged as tag t • Accuracy based on this simple assumption • Coarse tags – 88.5% • Fine grained tags - 92.22% • Model - Restricted HMM , first order sequence structure 5
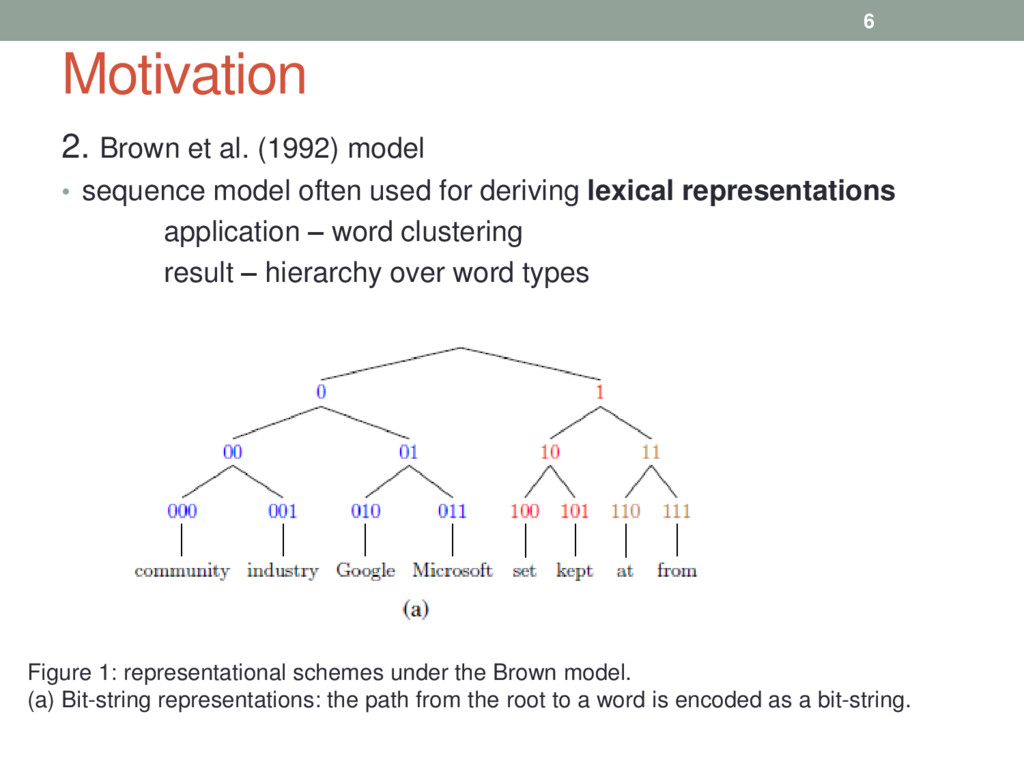
often used for deriving lexical representations application – word clustering result – hierarchy over word types 6 Figure 1: representational schemes under the Brown model. (a) Bit-string representations: the path from the root to a word is encoded as a bit-string.
recovered clusters under Brown model Words are represented as m dimensional vector where m = number of hidden states in model Real – values can represent ambiguity (b) Canonical Correlation Analysis (CCA) vector representations Assumption – Hidden states in Brown model can capture POS tags
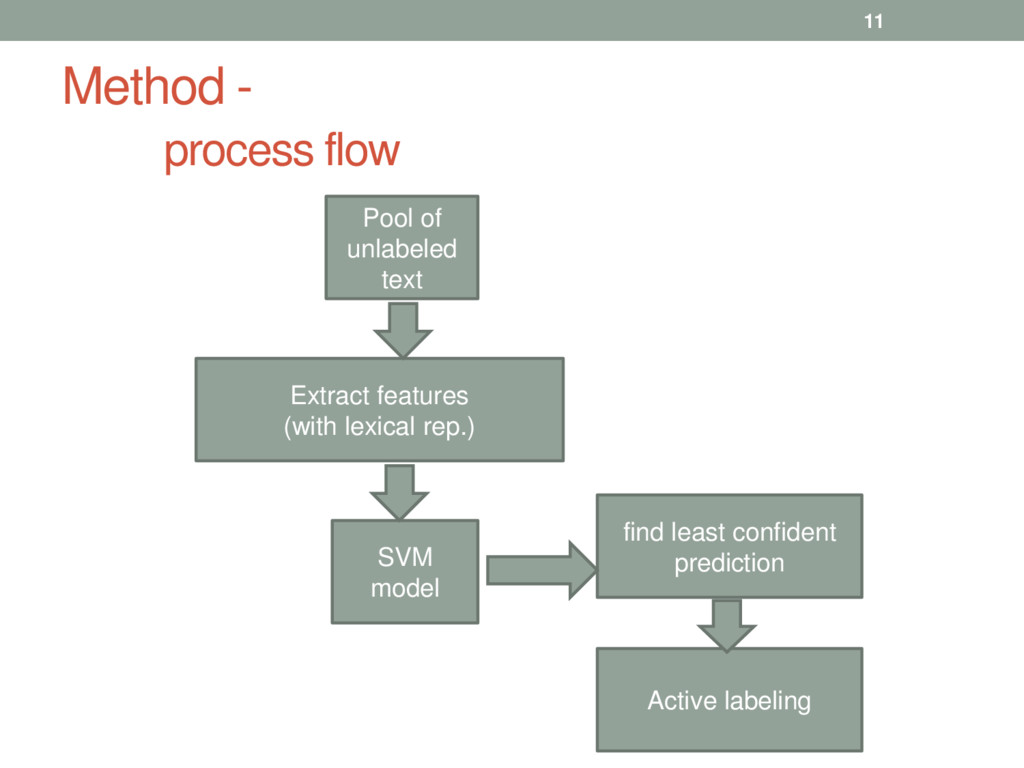
to map a word’s context to a POS tag e.g. SVM • allows learning from partially labeled sentences (active learning) • training and tagging can be very fast • features can be easily added 8
, xi , xi−2 , xi+2 • Prefixes and suffixes of Xi up to length 4 • Whether Xi is capitalized, numeric, or non alphanumeric (X,i) = sentence-position pair bit(X) = Brown bit string of X cca(X) = m-dim CCA embedding of X Baseline (BASE) • Spelling features of (x, i)
for candidate words for labeling • attempt to reduce the amount of training data • Active Learning • find the most informative words for labeling • Words with list confident predicted tag are selected for active labeling • Simple margin sampling • Random and frequent-word sampling • Random sampling: Select M words uniformly at random • Frequent-word sampling: Select random occurrences of the M most frequent word types
Datasets – universal treebank • Tagsets – (1) 45 tags (2) reduced to 12 tags • Derived Brown representation for following unlabeled data • English: 772 mi • German and Spanish: Google Ngram (German 64 bi, Sp. 83 bi) • Bit string derivation: Liang (2005), Stratos et al. (2014) • Word embedding : derived 50 dim. word embedding , CCA algorithm of Stratos et al. (2014) • Compared results with CRF 12
for deriving lexical representations, is particularly appropriate for capturing POS tags • reduced the amount of labeled data required for state-of- the-art POS tagging • Obtained an accurate POS tagger with less than 1% of the normally considered amount of training data 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Motivation 7 A variant of CCA [Stratos et al. (2014)]](https://files.speakerdeck.com/presentations/6556efa67a934a4598b2a03a46df2507/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}