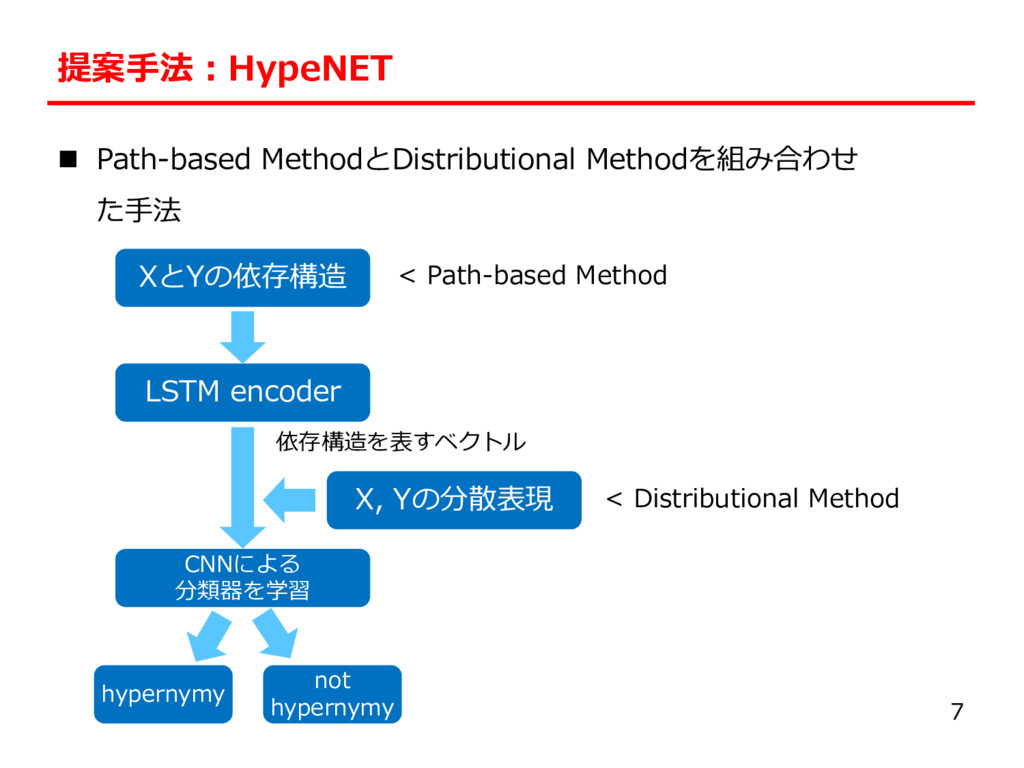
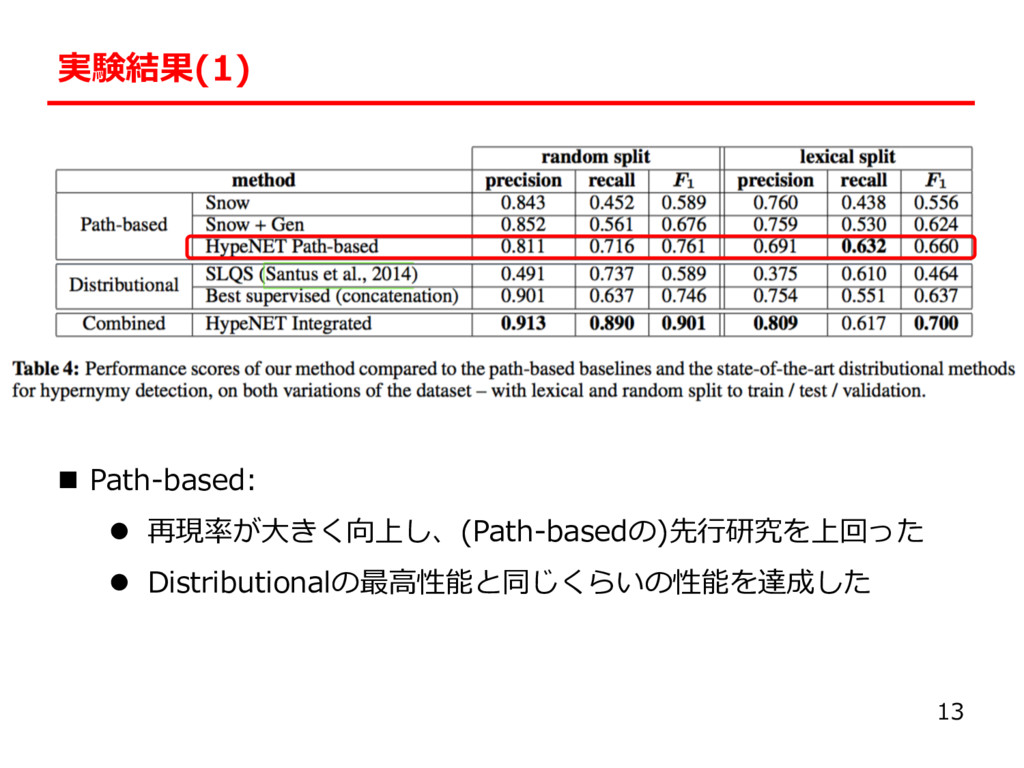
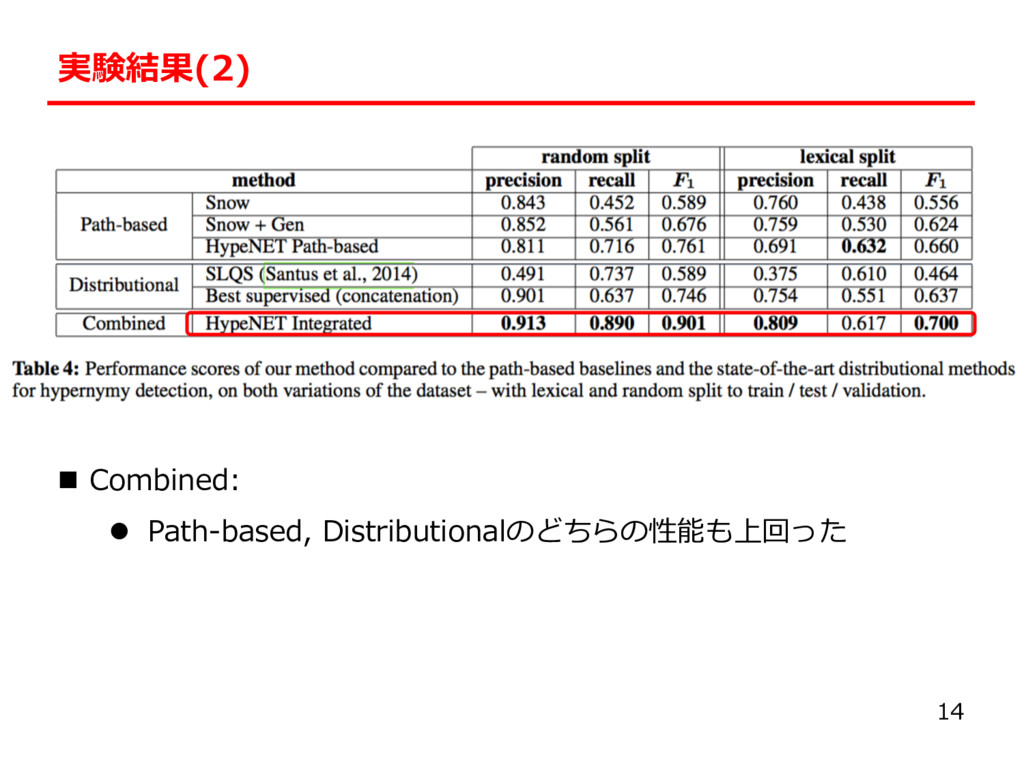
the Arctic regions?” l A: “Polar bears inhabit the Arctic regions.” l NG: “Indigenous people inhabit the Arctic regions.” l 知識: ◦(bears, animal) ×(people, animal) n 従来⼿法 l Path-based Method:依存構造を⽤いた⼿法 l Distributional Method:分散表現を⽤いた⼿法 3
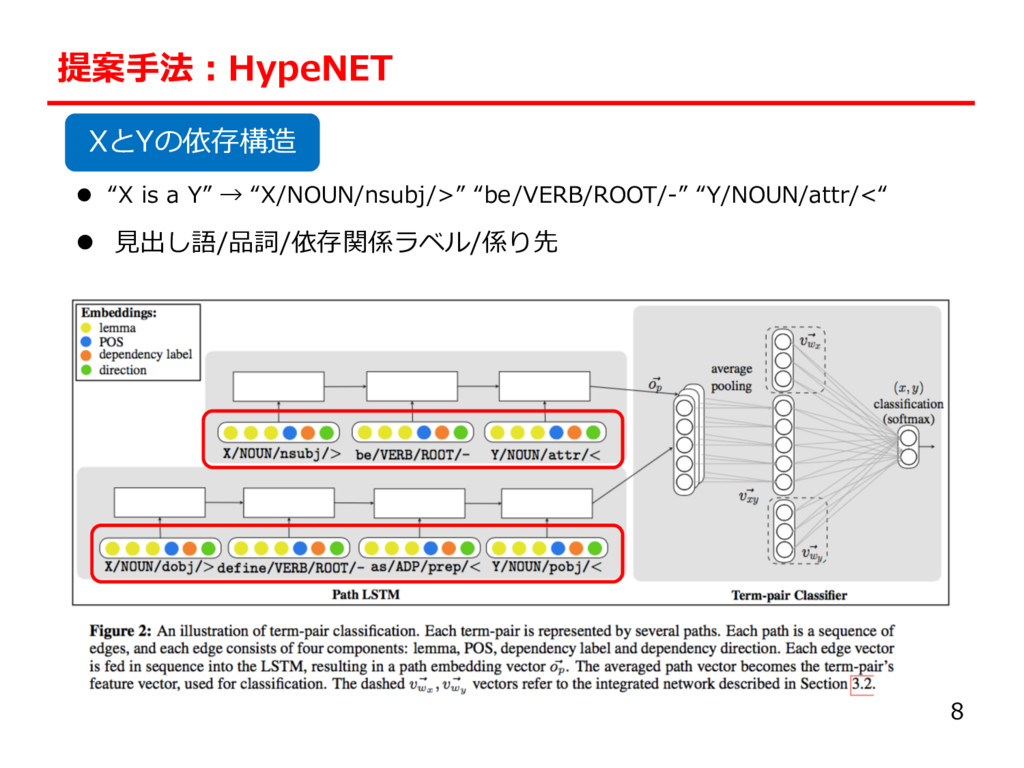
n PATTY [Nakashole et al., 2012]は単語の置換によって依存 構造の⼀般化を⾏なった “X corporation is a Y” → “X NOUN is a Y” “X is defined as Y” → “X is VERB as Y” Ø ⼀般化しすぎてもよくない (1) “X is defined as Y” ≈ “X is described as Y“ (2) “X is defined as Y” != “X is rejected as Y” 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![データセット 12 n 知識資源をもとに、コーパスから上位・下位関係を表す依存構造を 抽出[Snow et al., 2004] l 知識資源:WordNet,](https://files.speakerdeck.com/presentations/cde02f8317d148b0b74a8381b7d31de1/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}