Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
意味を表すベクトル表現を用いたテキスト分析
Search
Taichi Aida
September 08, 2025
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
意味を表すベクトル表現を用いたテキスト分析
Colab:
https://colab.research.google.com/drive/1tEbFhTL6SRO-9ZQoqW52vk98ck3Creva?usp=sharing
Taichi Aida
September 08, 2025
More Decks by Taichi Aida
See All by Taichi Aida
スウェーデン滞在報告
a1da4
0
35
PhD Defence: Considering Temporal and Contextual Information for Lexical Semantic Change Detection
a1da4
1
310
文献紹介:A Multidimensional Framework for Evaluating Lexical Semantic Change with Social Science Applications
a1da4
1
400
YANS2024:目指せ国際会議!「ネットワーキングの極意(国際会議編)」
a1da4
0
340
言語処理学会30周年記念事業留学支援交流会@YANS2024:「学生のための短期留学」
a1da4
1
460
新入生向けチュートリアル:文献のサーベイv2
a1da4
18
12k
文献紹介:Isotropic Representation Can Improve Zero-Shot Cross-Lingual Transfer on Multilingual Language Models
a1da4
0
250
文献紹介:WhitenedCSE: Whitening-based Contrastive Learning of Sentence Embeddings
a1da4
1
400
文献紹介:On the Transformation of Latent Space in Fine-Tuned NLP Models
a1da4
0
150
Other Decks in Research
See All in Research
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
170
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
860
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
890
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
110
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
220
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
LLM Compute Infrastructure Overview
karakurist
2
1.5k
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.5k
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
450
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
120
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
230
Featured
See All Featured
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Statistics for Hackers
jakevdp
799
230k
Technical Leadership for Architectural Decision Making
baasie
3
440
エンジニアに許された特別な時間の終わり
watany
108
250k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Building Adaptive Systems
keathley
44
3.1k
Chasing Engaging Ingredients in Design
codingconduct
0
240
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Transcript
意味を表すベクトル表現を 用いたテキスト分析 相田太一 東京都立大学
自己紹介 - 氏名:相田太一(あいだたいち) - 所属: - 東京都立大学 客員研究員 - 研究テーマ:
- 単語の通時的な意味変化の検出・分析 (論文誌4+1本、国際会議9+1本、国内会議10本) 2
研究紹介:単語の通時的な意味変化の検出・分析 - 単語の意味は時間で変化することがある - Plane:平面🔲→平面🔲、飛行機✈ - Cell:独房👮→細胞🔬→携帯電話☎ - 適当:適切👍→いいかげん🙃 -
推し:推薦🙌→ファンであること📣 3
研究紹介:単語の通時的な意味変化の検出・分析 - 単語の意味は時間で変化することがある - どのように(自動で)検出するか? - 時期間で単語の意味を比較 - 2つの時期で同時に計算する [自然言語処理’23],
データ構築 [自然言語処理’24] - 広がりを考慮 [Findings of ACL’23], 入れ替え [Findings of EMNLP’23], 意味ラベルを使う [Findings of EMNLP’23], 意味に特化 [Findings of ACL’24] - どのように(自動で)分析するか? - 時期間で単語の意味の変わり方を調査 - 単語を絞った分析 [自然言語処理’23, デジタル・ヒューマニティーズ’25] - 網羅的な分析 [COLING’25], 意味変化に関連する特徴 [COLING’25] 4
研究紹介:単語の通時的な意味変化の検出・分析 - 単語の意味は時間で変化することがある - どのように(自動で)検出するか? - 時期間で単語の意味を比較 - 2つの時期で同時に計算する [自然言語処理’23],
データ構築 [自然言語処理’24] - 広がりを考慮 [Findings of ACL’23], 入れ替え検定 [Findings of EMNLP’23], 意味ラベルを使う [Findings of EMNLP’23], 意味に特化 [Findings of ACL’24] - どのように(自動で)分析するか? - 時期間で単語の意味の変わり方を調査 - 単語を絞った分析 [自然言語処理’23, デジタル・ヒューマニティーズ’25] - 網羅的な分析 [COLING’25], 意味変化に関連する特徴 [COLING’25] - 性能と解釈性のトレードオフに対処 [Findings of EMNLP’25] 5
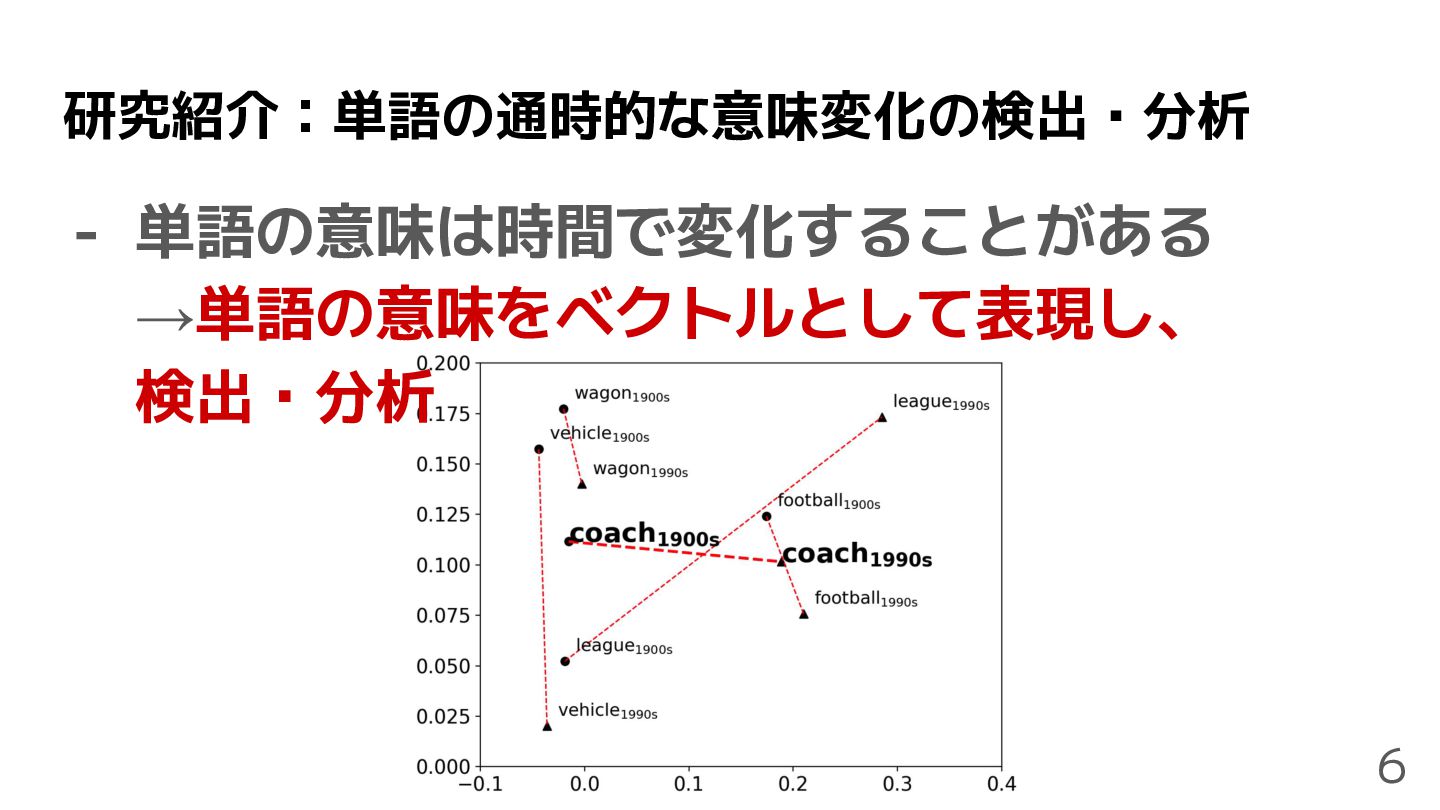
研究紹介:単語の通時的な意味変化の検出・分析 6 - 単語の意味は時間で変化することがある →単語の意味をベクトルとして表現し、 検出・分析
- ある単語の周辺単語を予測 できるように学習する(Skip-Gram) - 関係のない単語を用意して 「関連する周辺単語か?」 の分類問題にすると、高速に (Skip-Gram with Negative
Sampling; SGNS) 代表的な単語ベクトル:Skip-gram [Mikolov+13] 7
- Gensim で Python 用のプログラムが 用意されている 代表的な単語ベクトル:Skip-gram [Mikolov+13] 8 訓練済みの単語ベクトル
をダウンロードして使う 自分で単語ベクトルを 1から訓練する
代表的な単語ベクトル:Skip-gram [Mikolov+13] - Gensim で Python 用のプログラムが 用意されているが、調査対象のコーパスごと に下記の設定を調整する必要がある →もっと簡単に作ることはできないか?
9
単語ベクトルの作り方(1/4) - 対象の単語集合(語彙)を決める - 例1:頻度 X 回以上出現する単語 - 例2:品詞が 名詞、動詞、形容詞、副詞
である単語 - +自分が調べたい単語(重要) - 調査対象コーパスの異なり語数が数千〜数万 →対象単語数が数百〜数千程度になる 10
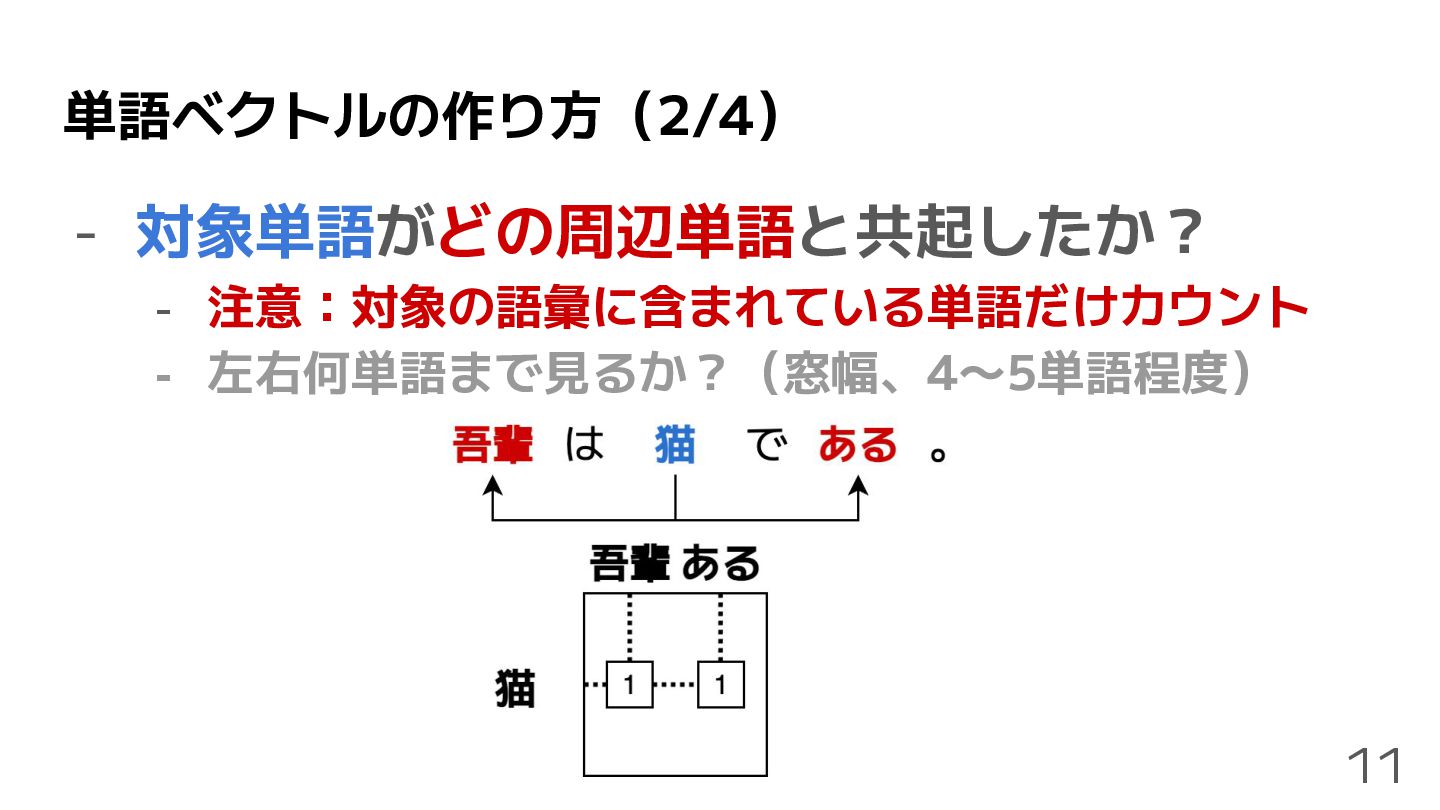
単語ベクトルの作り方(2/4) - 対象単語がどの周辺単語と共起したか? - 注意:対象の語彙に含まれている単語だけカウント - 左右何単語まで見るか?(窓幅、4〜5単語程度) 11
- 共起ベクトルだけで十分?→❌ - 高頻度の単語に支配されてしまい、意味的な関係性が 見えづらくなる(目的:意味を表すベクトルを得る) - 注意:分析したい単語と周辺単語が明確な場合を除く 単語ベクトルの作り方(3/4) 12
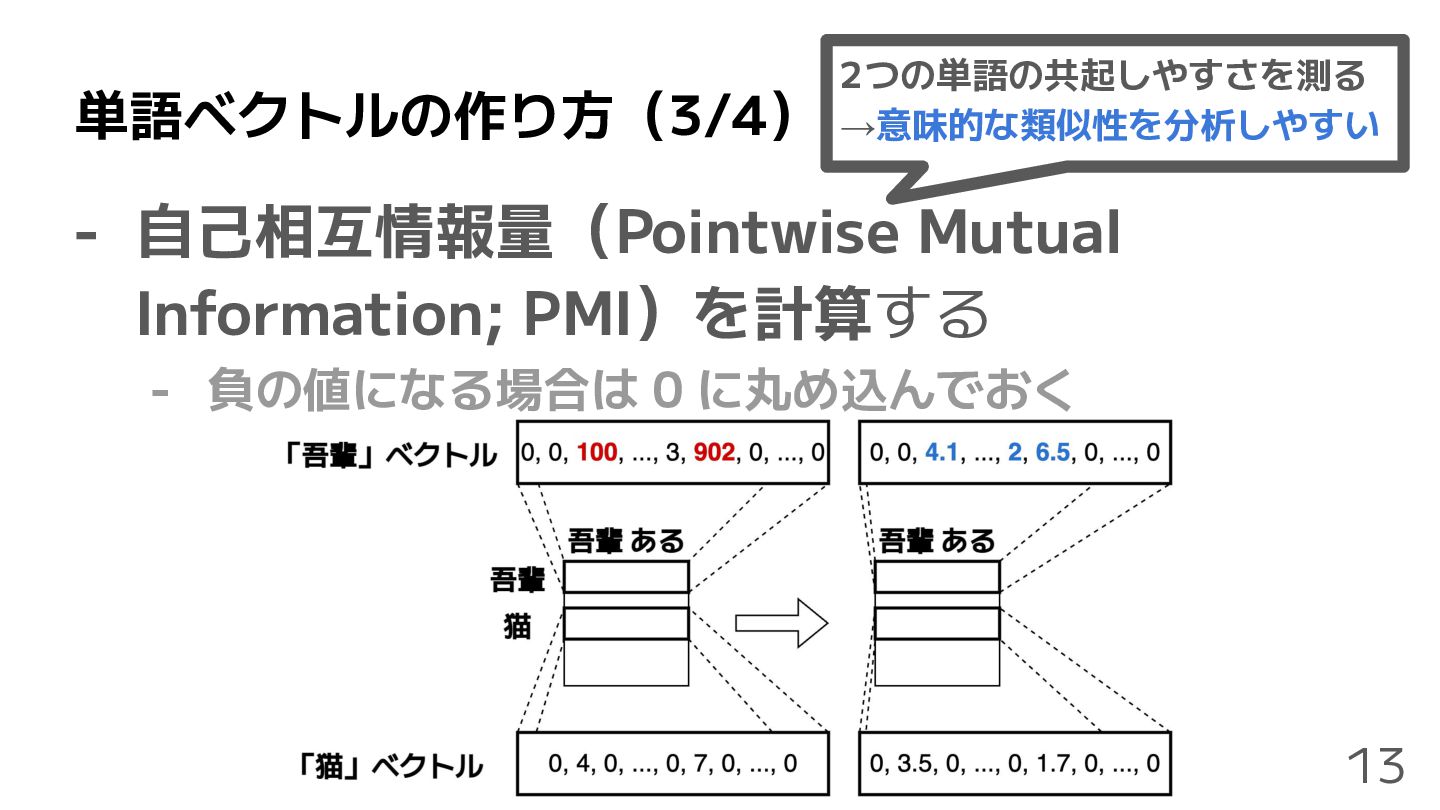
単語ベクトルの作り方(3/4) - 自己相互情報量(Pointwise Mutual Information; PMI)を計算する - 負の値になる場合は 0 に丸め込んでおく
13 2つの単語の共起しやすさを測る →意味的な類似性を分析しやすい
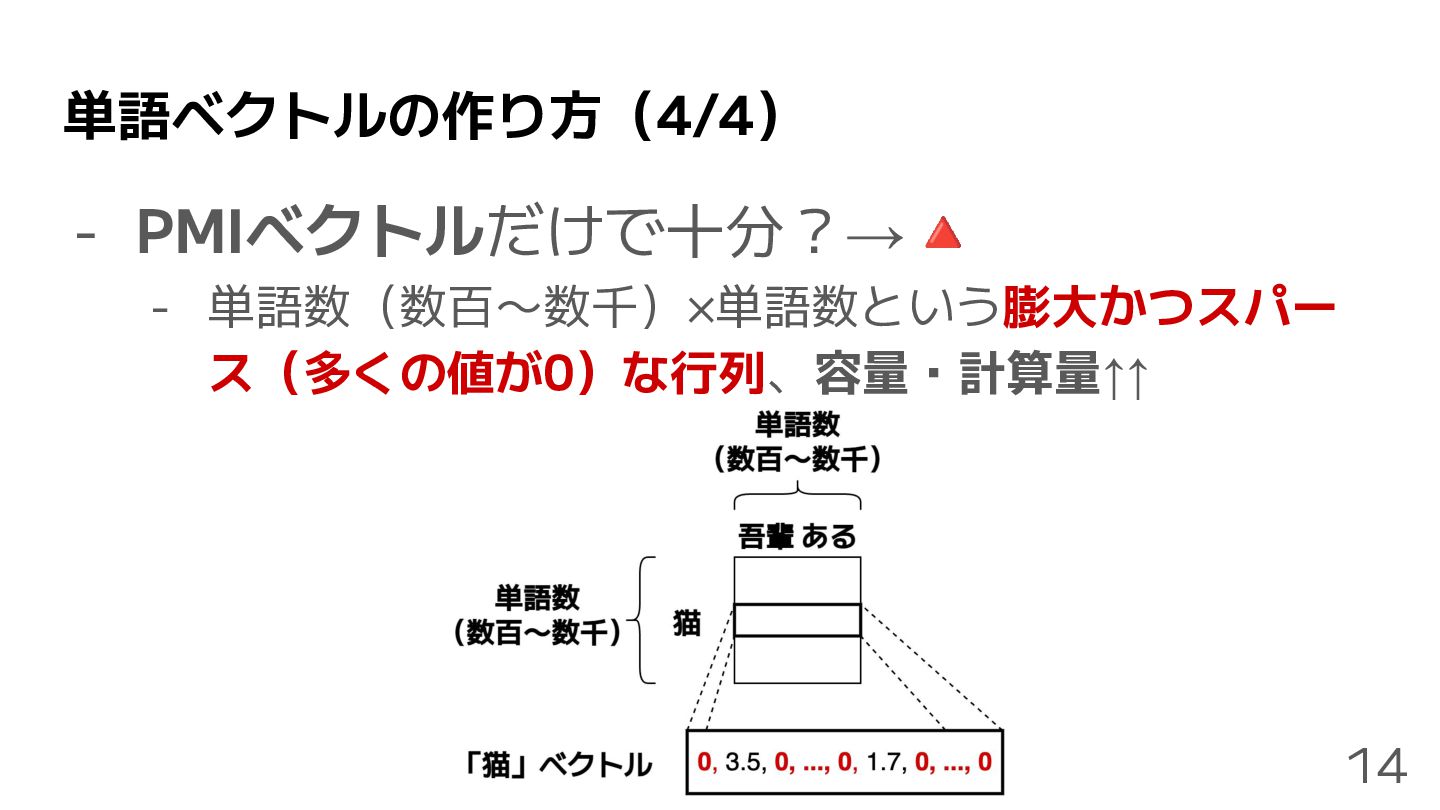
単語ベクトルの作り方(4/4) - PMIベクトルだけで十分?→🔺 - 単語数(数百〜数千)×単語数という膨大かつスパー ス(多くの値が0)な行列、容量・計算量↑↑ 14
単語ベクトルの作り方(4/4) - PMIベクトル行列を特異値分解 - コンパクトかつ密なベクトル行列が得られる - 代表的な単語ベクトル SGNS と等価に [Levy+14]
15 何次元まで削減する か?(次元数)
応用1:意味変化検出 [Aida+21、相田ほか23] - 意味変化=(意味を表す)ベクトルの変化 16 Code: [GitHub]
応用2:日本語学 [高橋ほか25] 17 - 和語動詞の書き分け(例:ナク)を調査
応用2:日本語学 [高橋ほか25] 18 - 和語動詞の書き分け(例:ナク)を調査 対象の単語に近い位置にある (意味が近い)単語も獲得可能 「鳴く」 :🦆 「泣く」
:😭
応用3:意味変化のパターン分類 [Kiyama+25] - ある単語について時期ごとにベクトルを獲得 →時期間でどれだけ似ているか?を算出 19 似てる 似ていない
応用3:意味変化のパターン分類 [Kiyama+25] - 単語の意味変化パターンを分類 (左:record、右:president) 20
ハンズオン(Google Colab) - 意味を表すベクトル表現を用いたテキスト分 析.ipynb - 「0. 設定」 - 必要なパッケージの取得
- 使用するコーパスの読み込み・前処理 - 「1. 単語ベクトル」 - 共起→PMI→単語ベクトルの作成まで 21
文の意味を表すベクトル - これまで:文書から単語のベクトルを1つ得る - 例:SGNS ✅ 軽量、高速 ❌ 大雑把な表現(多義性があっても1つのベクトル) -
ここから:文(用例)からベクトルを得る - 例:BERT ❌ 容量が必要、少し遅い ✅ 用例単位の細かい表現(多義性も表現可能) 22
応用4:辞書 [Kobayashi+21, 小林ほか23] 23 - 各時期で単語(例:適当)の用例集合を取得
応用4:辞書 [Kobayashi+21, 小林ほか23] 24 - 各時期で単語(例:適当)の用例集合を取得 - 語義の比率を分析
応用4:辞書 [Kobayashi+21, 小林ほか23] 25 - 各時期で単語(例:適当)の用例集合を取得 - 語義の比率を分析 単語ベクトルでは 「年代ごとに1つの
ベクトル」だった
応用5:意味変化検出 [Aida+23] - 時期間で点の集合の平均(⭐)を比較 ✅ 古い時期での意味が新しい時期で損失(例:gay) ❌ 古い時期での意味が新たな時期でも保持される(例:cell) 26
応用5:意味変化検出 [Aida+23] - 単語の用例集合(例:Cell)の広がりを考慮 して、意味変化度合いを算出する方法を提案 27
文の意味を表すベクトル:BERT ✅ 用例単位でベクトルに ❌ モデルサイズが大きい →計算に時間がかかる、 計算資源も必要になる ❌ 現代語のデータに偏る →古い時代
/ 方言データは まだまだ難しい(かも) 28
文の意味を表すベクトル:BERT - どうしたら良いのか? - 解決策1:目的のデータで訓練 →膨大なテキストが必要 (おそらく目的データだけでは不十分) →膨大な計算資源も必要 29
文の意味を表すベクトル - どうしたら良いのか? - 解決策1:目的のデータで訓練 - 解決策2:単語ベクトルから文ベクトルに変換 30
単語ベクトル→文ベクトル [Arora+17] - 「文ベクトルは単語ベクトルの組み合わせで 表現できる」という話(詳細は論文) ❌ 単純な平均 ✅ 重みつき平均 31
単語ベクトル→文ベクトル [Arora+17] 1. 単語ベクトルを学習する 2. 重みを計算 3. 文ごとのベクトルを獲得する 4. 主成分分析(Principal
Component Analysis; PCA)で後処理 32
単語ベクトル→文ベクトル [Arora+17] 1. 単語ベクトルを学習する a. 本資料の前半でOK b. 相田のコードを使っても良い [GitHub] 33
2. 重みを計算 a. パラメータ a と単語の出現確率 p(w) からなる b. 頻出する単語(p(w)↑)は重みが小さく、
レアな単語(p(w)↓)は重みが大きくなる 単語ベクトル→文ベクトル [Arora+17] 34
単語ベクトル→文ベクトル [Arora+17] 3. 文ごとのベクトルを獲得する a. 単語ベクトルの重みつき平均で獲得 b. 語彙にない単語は無視して良い 35
単語ベクトル→文ベクトル [Arora+17] 4. 主成分分析(Principal Component Analysis; PCA)で後処理 a. 上位の主成分は頻度関連(=不要?) [Mu+18]
b. 文ベクトル集合に対して PCA で Top1 の主成分を獲得 ベクトル集合から差し引く 36
ハンズオン(Google Colab) - 意味を表すベクトル表現を用いたテキスト分 析.ipynb - 「0. 設定」 - 「1.
単語ベクトル」 - 「2. 文ベクトル」 37
文の意味を表すベクトル - どうしたら良いのか? ❌ 解決策1:目的のデータで訓練 ✅ 解決策2:単語ベクトルから文ベクトルに変換 →単語ベクトルさえあればOK(軽量、高速) 38
文の意味を表すベクトル - どうしたら良いのか? ❌ 解決策1:目的のデータで訓練 ✅ 解決策2:単語ベクトルから文ベクトルに変換 🤔 解決策3:OpenAI のベクトルを使う
[近藤 2023]→高性能だが、従量課金制なので注意 39 1M トークン あたりの価格 [OpenAI]
文の意味を表すベクトル - どうしたら良いのか? ❌ 解決策1:目的のデータで訓練 ✅ 解決策2:単語ベクトルから文ベクトルに変換 🤔 解決策3:OpenAI のベクトルを使う
[近藤 2023]→高性能だが、従量課金制なので注意 40 1M トークン あたりの価格 [OpenAI] 一見すると安いかも...? →実験が1回で完了することは少ない! (ベクトルの保存ミス・設計変更...) →本チュートリアルなら、自分で対象 コーパス特化の文ベクトルを作れる・ 自由に調整できる👍
発展:頑張ると良いところ、工夫するところ - まずは「そのまま使う」でOKだが、こだわる と更なる向上も [Levy+15] - 前処理:Lemmatise、Subsampling [GitHub] - 学習時:語彙の選定、窓幅、次元サイズ
- 後処理:ベクトルの長さを1にする、中心化、白色化 [Yokoi+24] →「統計的テキストモデル」 41
おわりに - 理論:単語の意味を表現する→単語ベクトル - 文書から1つの単語ベクトルを獲得 - 文(用例)から1つの単語ベクトルを獲得 - 実践:Colab で手を動かす
- 細かい部分が見えてくる(パラメータ探索、保存) - 数式を覚える << それぞれの良いところを把握する - 発展:更なる改善へ - 前処理、学習時、後処理 それぞれで存在 - 「統計的テキストモデル」 42
{kind=link}
{kind=link}
{kind=link}
![研究紹介:単語の通時的な意味変化の検出・分析 - 単語の意味は時間で変化することがある - どのように(自動で)検出するか? - 時期間で単語の意味を比較 - 2つの時期で同時に計算する [自然言語処理’23],](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_3.jpg){kind=link}
![研究紹介:単語の通時的な意味変化の検出・分析 - 単語の意味は時間で変化することがある - どのように(自動で)検出するか? - 時期間で単語の意味を比較 - 2つの時期で同時に計算する [自然言語処理’23],](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![- Gensim で Python 用のプログラムが 用意されている 代表的な単語ベクトル:Skip-gram [Mikolov+13] 8 訓練済みの単語ベクトル](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_7.jpg){kind=link}
![代表的な単語ベクトル:Skip-gram [Mikolov+13] - Gensim で Python 用のプログラムが 用意されているが、調査対象のコーパスごと に下記の設定を調整する必要がある →もっと簡単に作ることはできないか?](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![単語ベクトルの作り方(4/4) - PMIベクトル行列を特異値分解 - コンパクトかつ密なベクトル行列が得られる - 代表的な単語ベクトル SGNS と等価に [Levy+14]](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_14.jpg){kind=link}
![応用1:意味変化検出 [Aida+21、相田ほか23] - 意味変化=(意味を表す)ベクトルの変化 16 Code: [GitHub]](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_15.jpg){kind=link}
![応用2:日本語学 [高橋ほか25] 17 - 和語動詞の書き分け(例:ナク)を調査](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_16.jpg){kind=link}
![応用2:日本語学 [高橋ほか25] 18 - 和語動詞の書き分け(例:ナク)を調査 対象の単語に近い位置にある (意味が近い)単語も獲得可能 「鳴く」 :🦆 「泣く」](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_17.jpg){kind=link}
![応用3:意味変化のパターン分類 [Kiyama+25] - ある単語について時期ごとにベクトルを獲得 →時期間でどれだけ似ているか?を算出 19 似てる 似ていない](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_18.jpg){kind=link}
![応用3:意味変化のパターン分類 [Kiyama+25] - 単語の意味変化パターンを分類 (左:record、右:president) 20](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
![応用4:辞書 [Kobayashi+21, 小林ほか23] 23 - 各時期で単語(例:適当)の用例集合を取得](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_22.jpg){kind=link}
![応用4:辞書 [Kobayashi+21, 小林ほか23] 24 - 各時期で単語(例:適当)の用例集合を取得 - 語義の比率を分析](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_23.jpg){kind=link}
![応用4:辞書 [Kobayashi+21, 小林ほか23] 25 - 各時期で単語(例:適当)の用例集合を取得 - 語義の比率を分析 単語ベクトルでは 「年代ごとに1つの](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_24.jpg){kind=link}
![応用5:意味変化検出 [Aida+23] - 時期間で点の集合の平均(⭐)を比較 ✅ 古い時期での意味が新しい時期で損失(例:gay) ❌ 古い時期での意味が新たな時期でも保持される(例:cell) 26](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_25.jpg){kind=link}
![応用5:意味変化検出 [Aida+23] - 単語の用例集合(例:Cell)の広がりを考慮 して、意味変化度合いを算出する方法を提案 27](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![単語ベクトル→文ベクトル [Arora+17] - 「文ベクトルは単語ベクトルの組み合わせで 表現できる」という話(詳細は論文) ❌ 単純な平均 ✅ 重みつき平均 31](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_30.jpg){kind=link}
![単語ベクトル→文ベクトル [Arora+17] 1. 単語ベクトルを学習する 2. 重みを計算 3. 文ごとのベクトルを獲得する 4. 主成分分析(Principal](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_31.jpg){kind=link}
![単語ベクトル→文ベクトル [Arora+17] 1. 単語ベクトルを学習する a. 本資料の前半でOK b. 相田のコードを使っても良い [GitHub] 33](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_32.jpg){kind=link}
{kind=link}
![単語ベクトル→文ベクトル [Arora+17] 3. 文ごとのベクトルを獲得する a. 単語ベクトルの重みつき平均で獲得 b. 語彙にない単語は無視して良い 35](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_34.jpg){kind=link}
![単語ベクトル→文ベクトル [Arora+17] 4. 主成分分析(Principal Component Analysis; PCA)で後処理 a. 上位の主成分は頻度関連(=不要?) [Mu+18]](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![発展:頑張ると良いところ、工夫するところ - まずは「そのまま使う」でOKだが、こだわる と更なる向上も [Levy+15] - 前処理:Lemmatise、Subsampling [GitHub] - 学習時:語彙の選定、窓幅、次元サイズ](https://files.speakerdeck.com/presentations/d5dadfb597ac49c89ba1845416661dc8/slide_40.jpg){kind=link}
{kind=link}