Self-Supervised Learning with Swin Transformers 3 The Modern Mathematics of Deep Learning 4 Multiscale Vision Transformers 5 Diffusion Models Beat GANs on Image Synthesis 6 Neural Algorithmic Reasoning 7 Emerging Properties in Self-Supervised Vision Transformers 8 Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges 9 A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning 10 Contrastive Learning of Image Representations with Cross-Video Cycle-Consistency
StyleGAN Imagery 3. RepVGG: Making VGG-style ConvNets Great Again 4. Representation Learning for Networks in Biology and Medicine: Advancements, Challenges, and Opportunities 5. Cross-validation: what does it estimate and how well does it do it? 6. Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types 7. Why Do Local Methods Solve Nonconvex Problems? 8. Scaling Scaling Laws with Board Games 9. Vision Transformers for Dense Prediction 10. EfficientNetV2: Smaller Models and Faster Training)
Geodesics, and Gauges) この10年間、データサイエンスと機械学習の分野では、深層学習法に象徴される実験的な革命が起きて います。実際、コンピュータビジョン、囲碁、タンパク質の折り畳みなど、これまで手の届かないもの と考えられていた高次元の学習課題の多くが、適切な計算規模で実現可能となっている。驚くべきこと に、深層学習の本質は、2つの単純なアルゴリズム原理から構築されている。1つ目は、表現または特徴 の学習という概念で、これにより、適応された(多くの場合、階層的な)特徴が各タスクの適切な規則 性の概念を捉える。2つ目は、典型的なバックプロパゲーションとして実装される局所勾配降下法によ る学習である。 高次元で一般的な関数を学習することは呪われた推定問題であるが、関心のあるほと んどのタスクは一般的ではなく、物理的世界の基本的な低次元性と構造から生じる本質的な事前定義さ れた規則性を備えている。このテキストでは、広い範囲のアプリケーションに適用できる統一された幾 何学的原理によって、これらの規則性を明らかにすることを目的としています。 このような「幾何学 的統一」の試みは、フェリックス・クラインのエアランジェン・プログラムの精神に基づいており、2 つの目的を持っている。一方で、ニューラル・アーキテクチャに事前の物理的知識を組み込むための建 設的な手順を提供し、まだ発明されていない将来のアーキテクチャを構築するための原理的な方法を提 供しています。 。 http://arxiv.org/abs/2104.13478v2 1 Imperial College London / USI IDSIA / Twitter 2New York University 3Qualcomm AI Research. Qualcomm AI Research is an initiative of Qualcomm Technologies, Inc. 4DeepMind → 「幾何学的統一」の試み
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
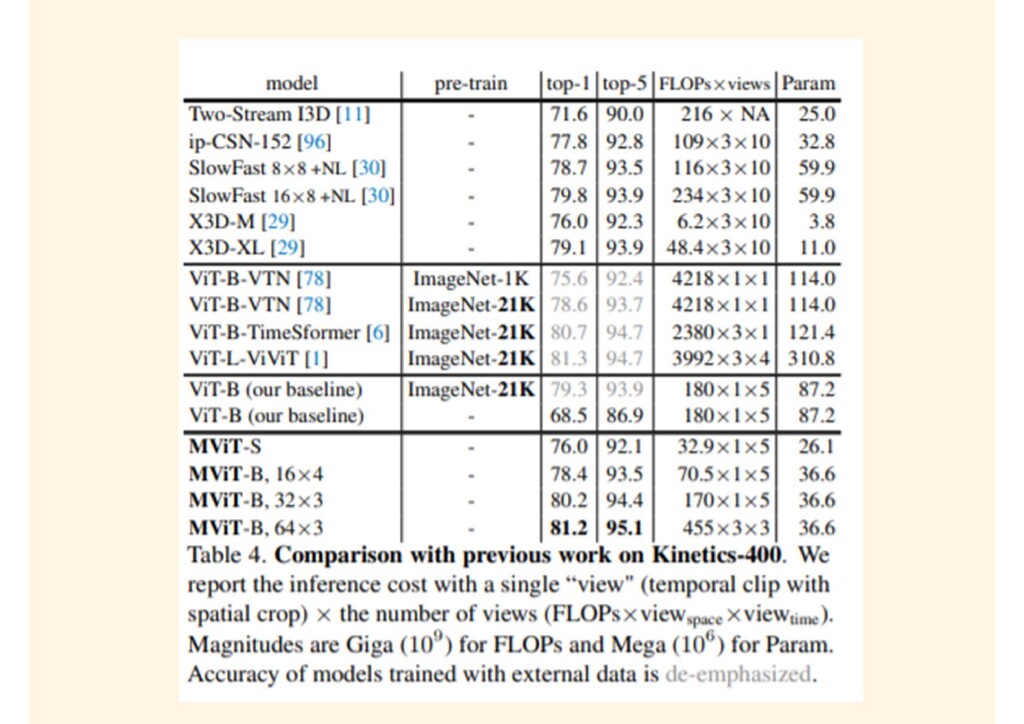{kind=link}
{kind=link}
{kind=link}
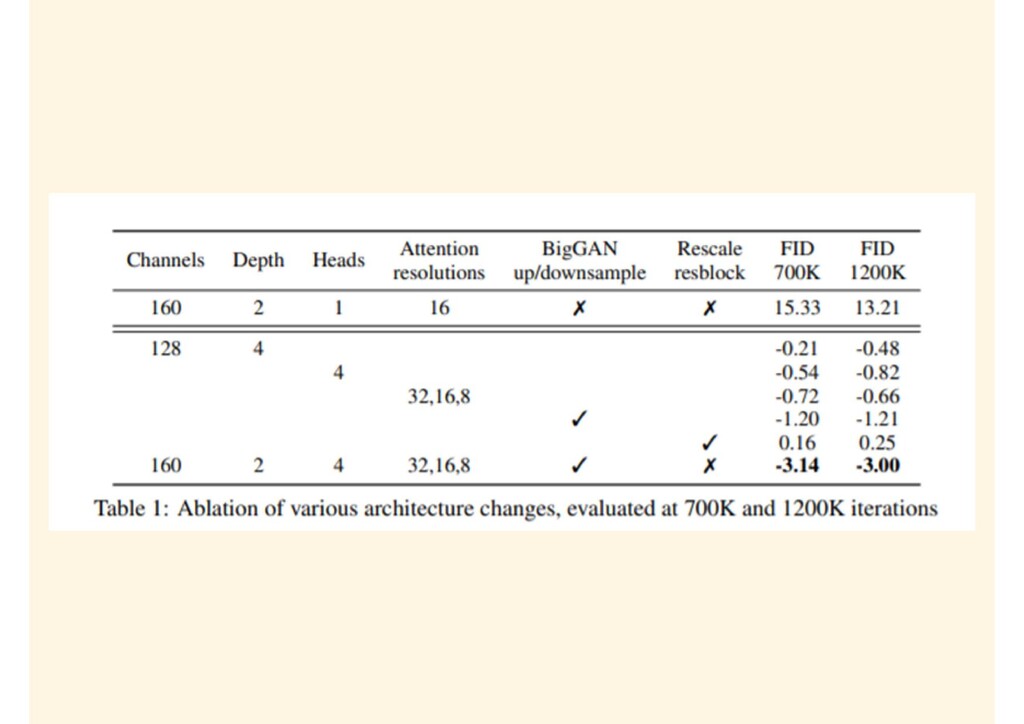{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
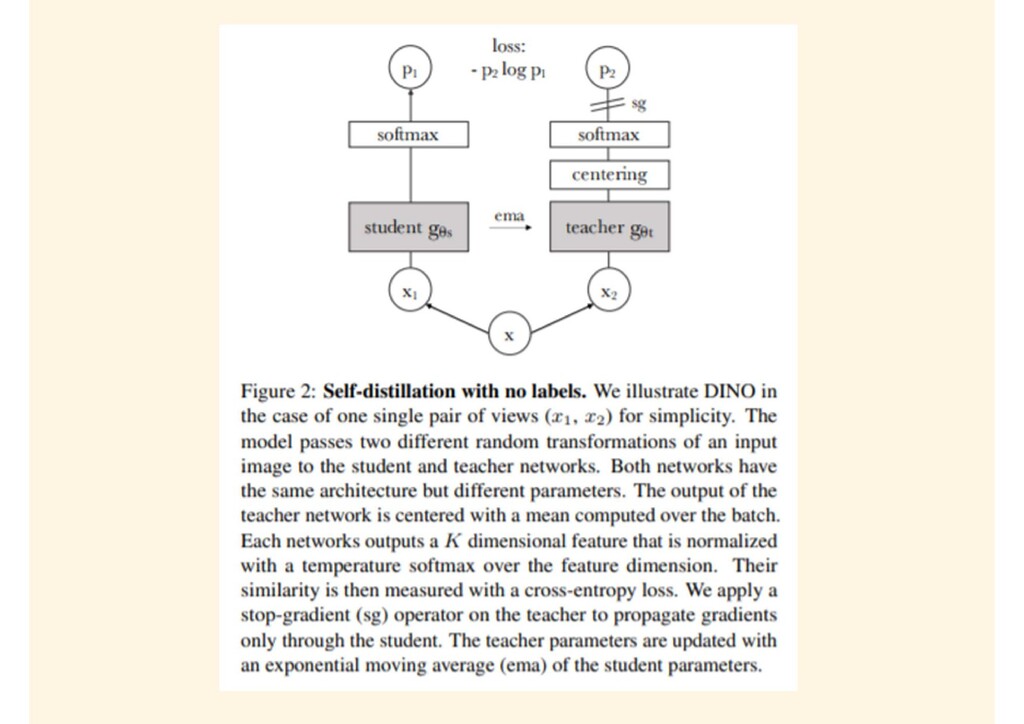{kind=link}
{kind=link}
{kind=link}
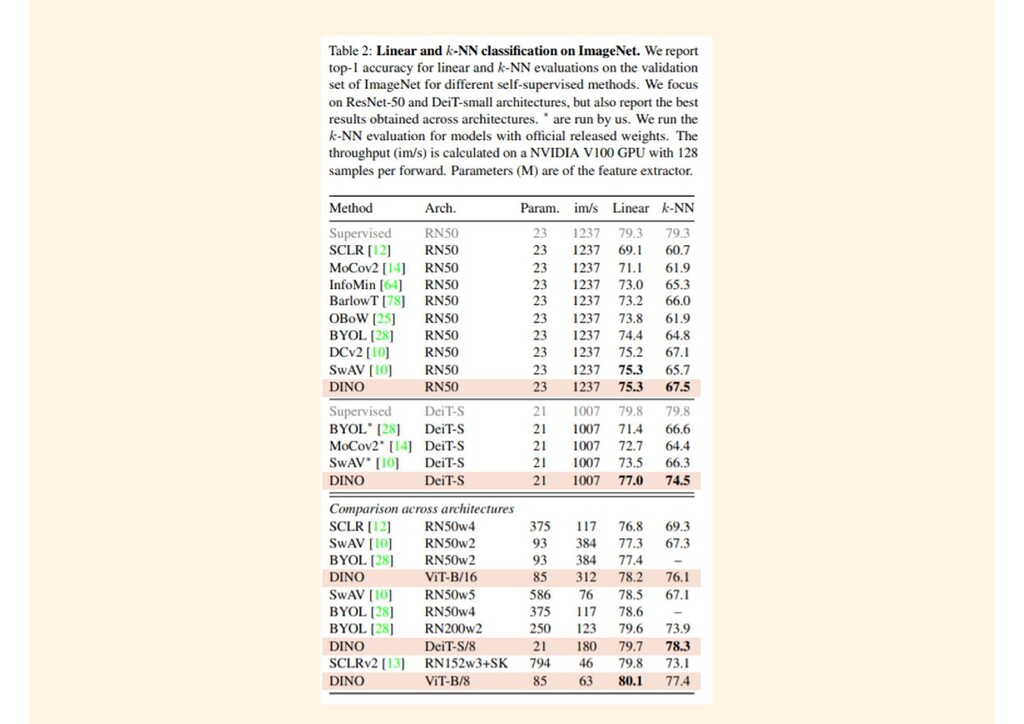{kind=link}
{kind=link}
{kind=link}
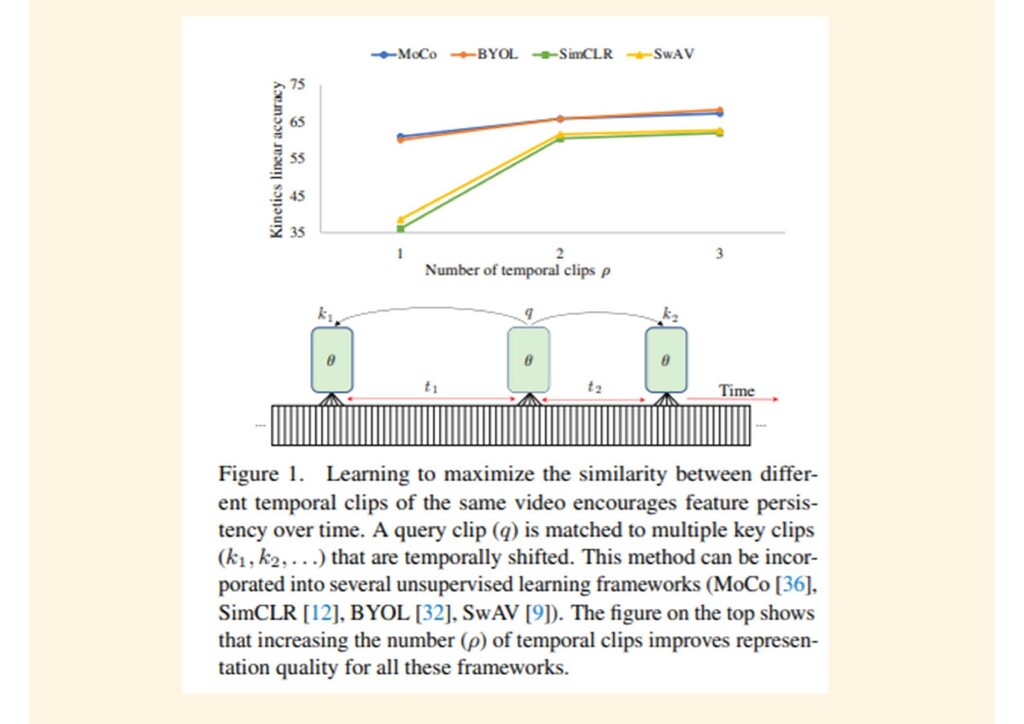{kind=link}
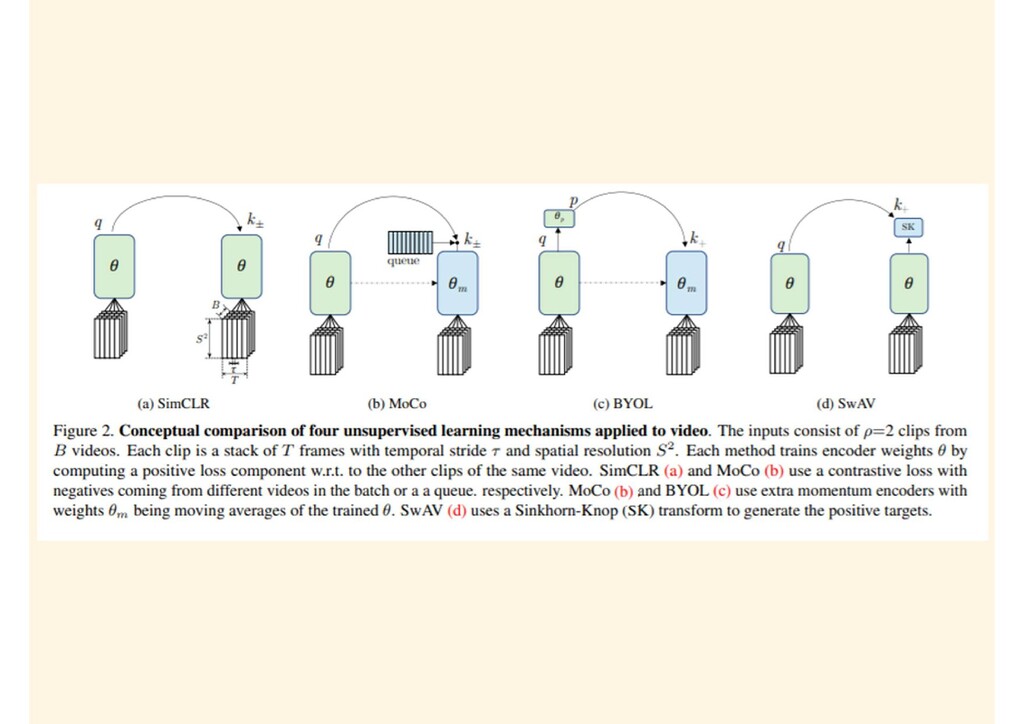{kind=link}
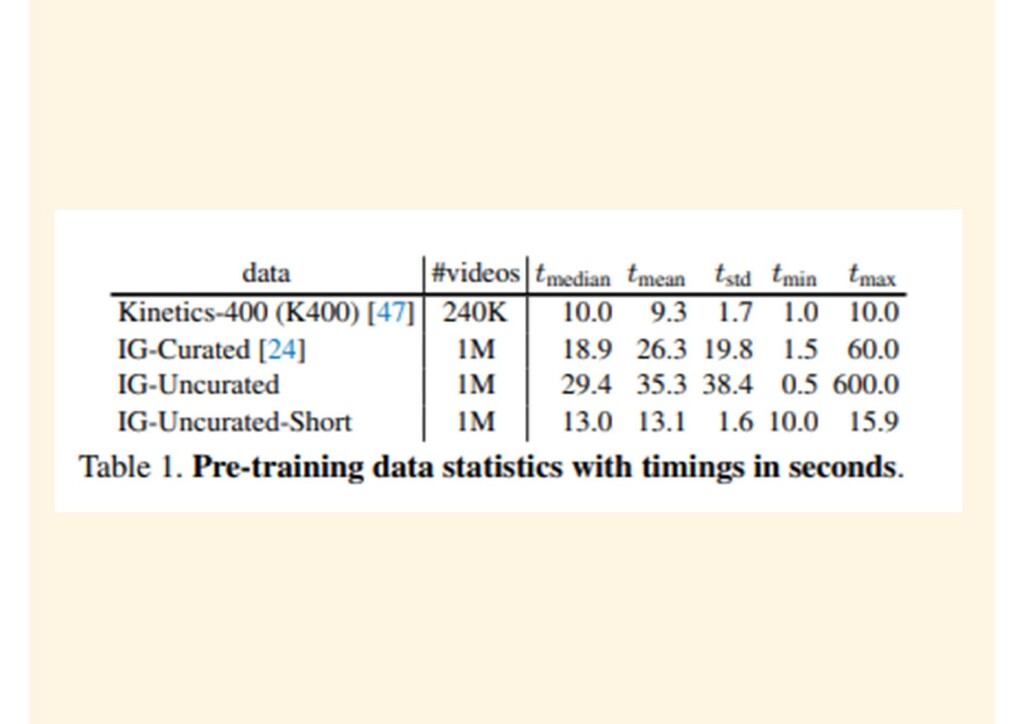{kind=link}
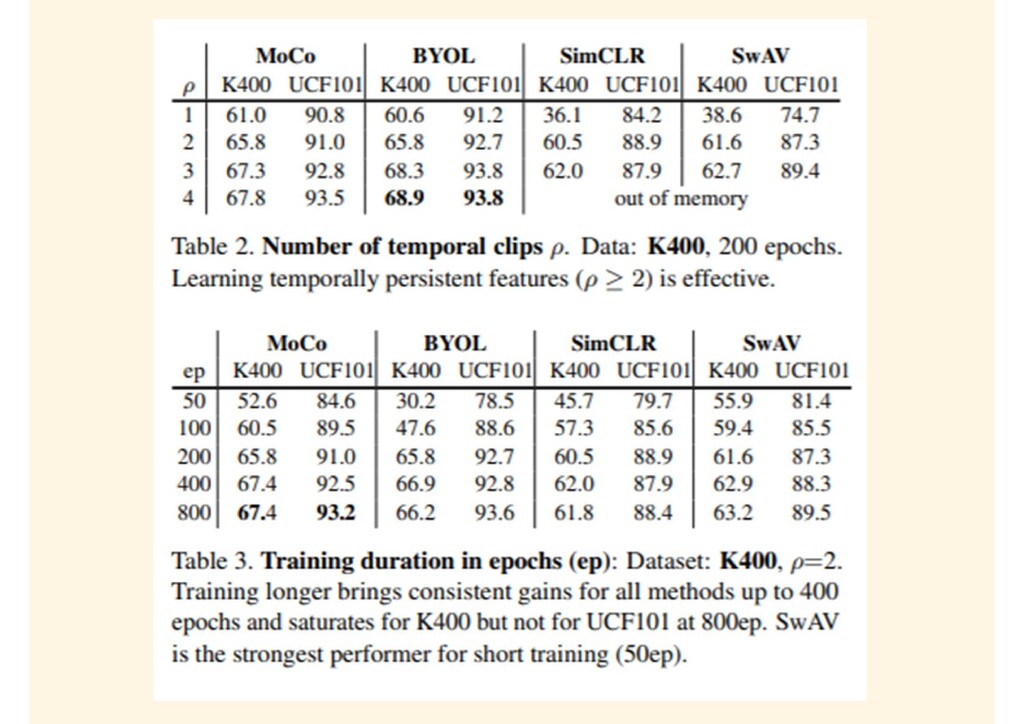{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}