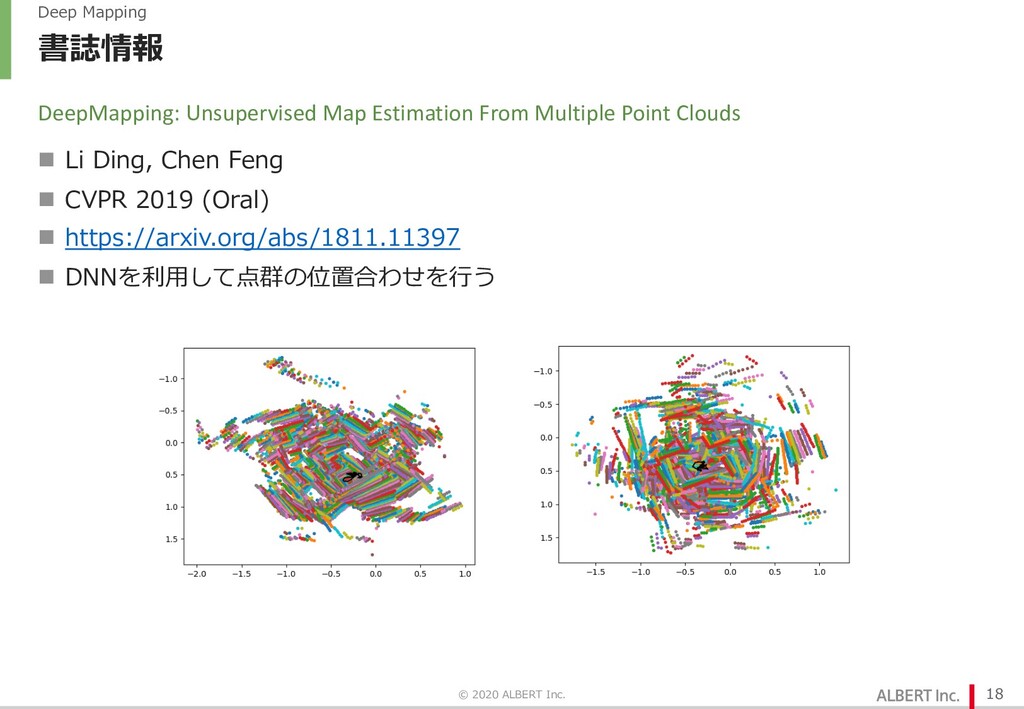
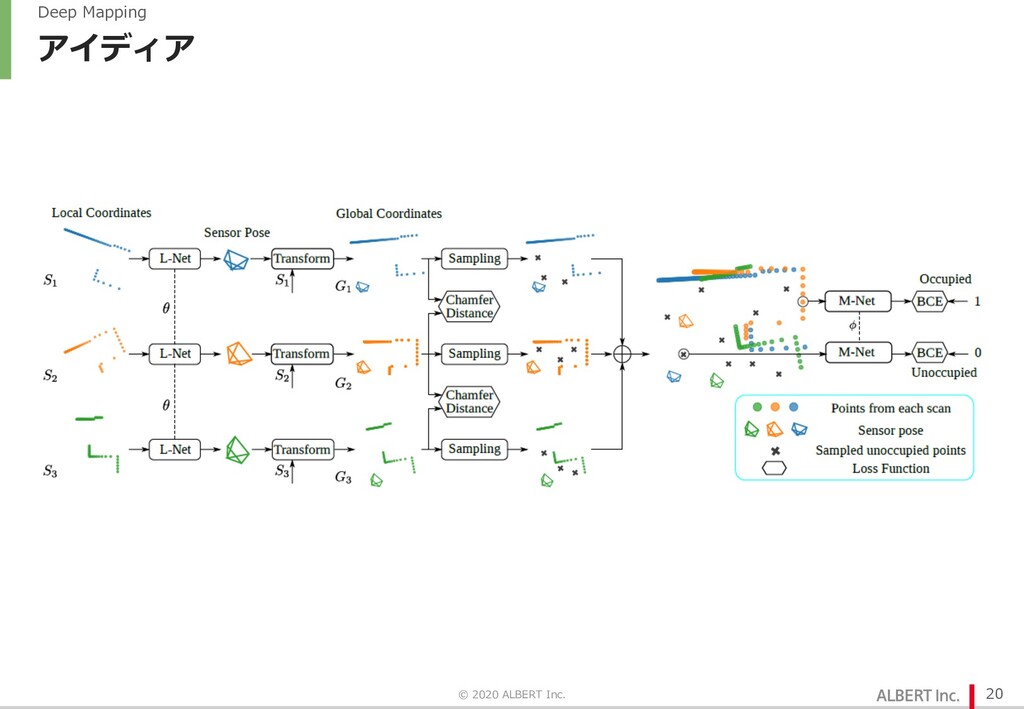
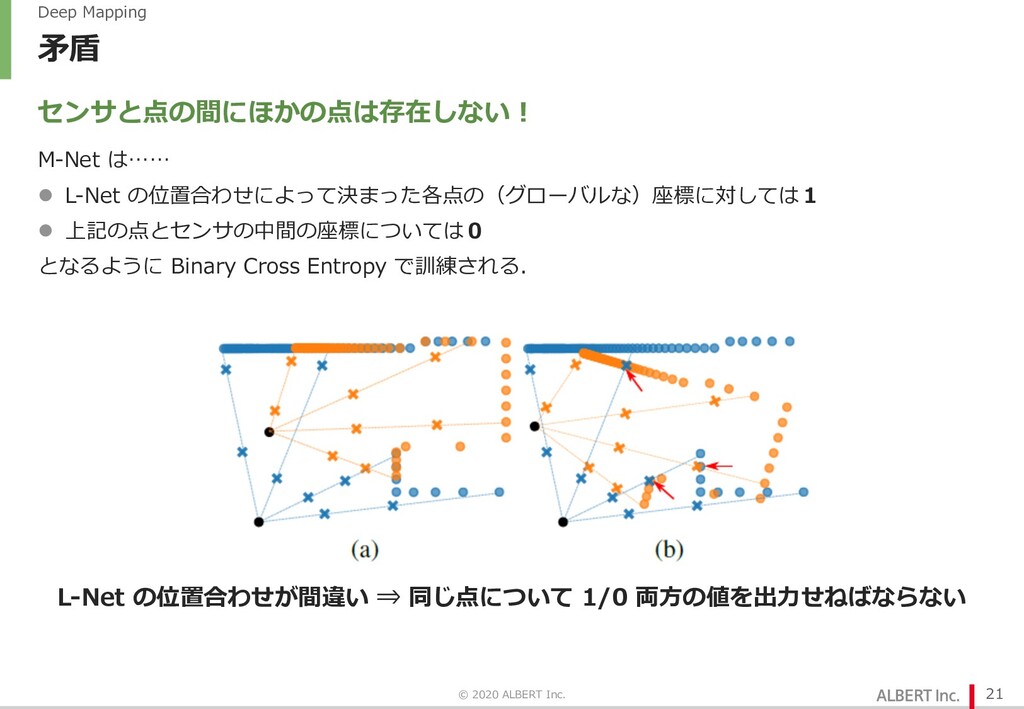
点群は D x 3 の配列として⼊⼒.D は点群ごとに異なるので global average pooling で辻褄合わせ l M-Net Ø L-Net の割り当てたセンサ位置をもとに、各点の位置をマップに書き込む Ø 座標に対してそこに点があるかどうかを学習.L-Net の位置合わせが間違っていると⽭盾(後述)が⽣じる Ø アーキテクチャは MLP. Ø 座標(3次元)を受け取り、そこに点があるかどうかを予測 © 2020 ALBERT Inc. 19 位置合わせが間違っていたら解けないはずの問題を解かせる M-Net が学習できる ⇒ L-Net の位置合わせは正しい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}