to Human Activity Understanding in Videos, CVPR 2020 Tutorial, https://bryanyzhu.github.io/videomodeling.github.io/slide/talk1_activity_understanding_slide.pdf [2] Korbar et al, SCSampler: Sampling salient clips from video for efficient action recognition, ICCV 2019 [3] Wang et al, Temporal segment networks: Towards good practices for deep action recognition, ECCV 2016 [4] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In Proc. CVPR, 2017 [5] Piergiovanni et al, Representation flow for action recognition, CVPR 2019 [6] Kay et al, The Kinetics Human Action Video Dataset, 2017 [7] Epstein et al, Oops! Predicting Unintentional Action in Video, CVPR 2020 [8] Girdhar and Ramanan, CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning, ICLR 2020 [9] Qiu et al, Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks, ICCV 2017 [10] Tran et al, “A closer look at spatiotemporal convolutions for action recognition”, CVPR 2018 [11] Xie et al, Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification, ECCV 2018 [12] Lin et al, TSM: Temporal shift module for efficient video understanding, ICCV 2019 [13] Wang et al, Non-local Neural Networks, CVPR 2018 [14] Huang et al, What Makes a Video a Video: Analyzing Temporal Information in Video Understanding Models and Datasets, CVPR 2018 [15] Wu et al, Compressed Video Action Recognition, CVPR 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Optical Flowの利⽤ © 2020 ALBERT Inc. 15 [4] J. Carreira](https://files.speakerdeck.com/presentations/3040794c0ba9488baf4b3aabd38f3ba1/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景・物体バイアスの少ないタスク © 2020 ALBERT Inc. 20 [6] Kay et al,](https://files.speakerdeck.com/presentations/3040794c0ba9488baf4b3aabd38f3ba1/slide_19.jpg){kind=link}
{kind=link}
![効率的なネットワーク︓P3D, R(2+1)D, S3D n P3D [9], R(2+1)D [10], S3D [11]](https://files.speakerdeck.com/presentations/3040794c0ba9488baf4b3aabd38f3ba1/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
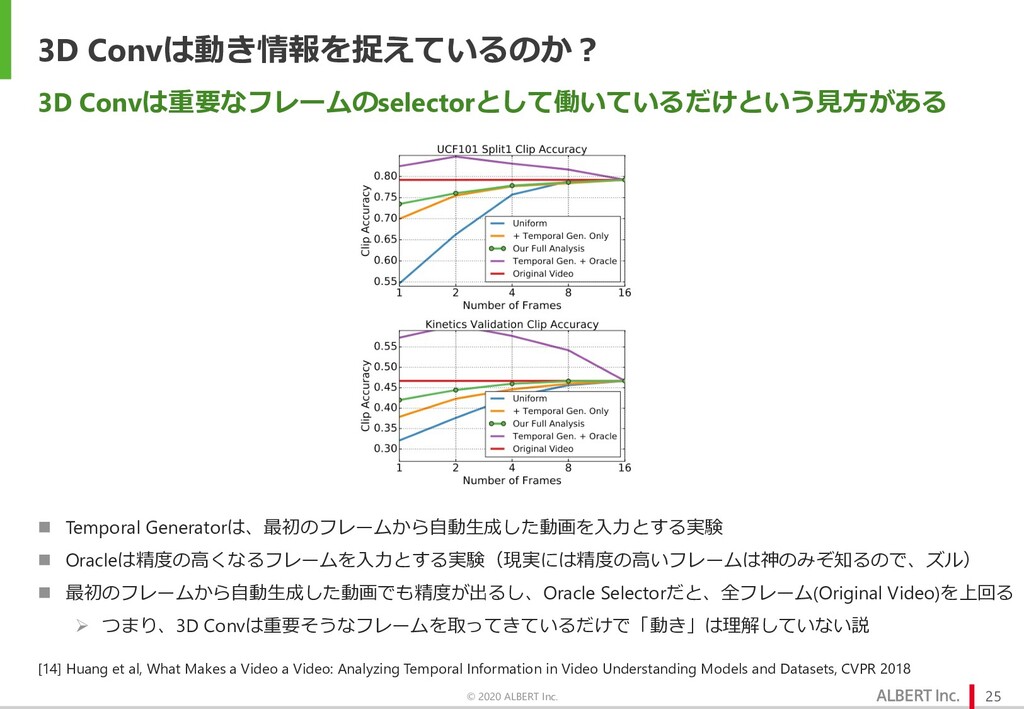{kind=link}
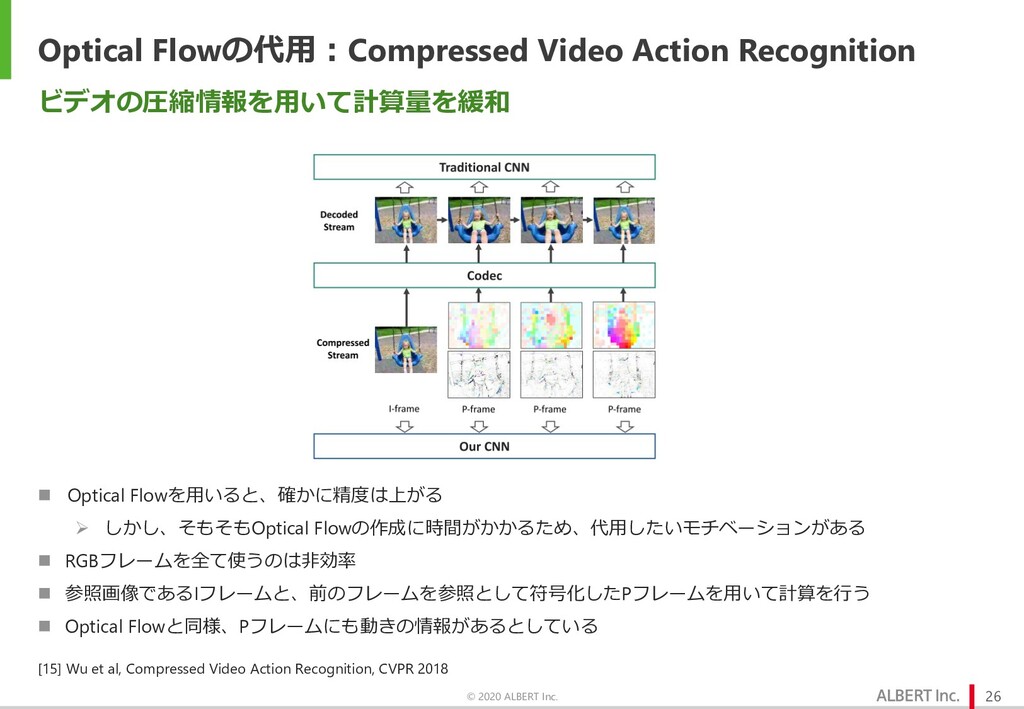{kind=link}
{kind=link}
{kind=link}
![参考⽂献 © 2020 ALBERT Inc. 29 [1] Yuanjun Xiong, Introduction](https://files.speakerdeck.com/presentations/3040794c0ba9488baf4b3aabd38f3ba1/slide_28.jpg){kind=link}
{kind=link}